[Перевод] Работа с графикой на языке Rust

Всем привет! Меня зовут Саша и я backend разработчик. Нет, не на rust. Но раст мой любимый язык и недавно я задался целью портировать движок онлайн игры, написанный на C++. Первый месяц ушел на то, чтобы разобраться с бинарными ассетами, их чтением и управлением. Но статья будет не об этом, а о WGPU.
Что такое WGPU?
WGPU это реализация спецификации WebGPU на языке rust, целью которой является предоставить более безопасный и удобный доступ к функционалу видео карты из браузера (замена webgl).Во многом, API перекликается с таковым у Vulkan API, предоставляя также возможность трансляции в другие backend-ы (DirectX, Metal, Vulkan, OpenGL).
Я решил разобраться в теме рендеринга 3D сцен, поэтому решил записать цикл уроков по этой теме. Во многом это будет перевод официального туториала по wgpu + мои комментарии.
Приступим!
Я поделил исходный материал на условные уроки и первым из них будет урок по созданию окна. Так как они не очень большие, в этой статье я объединил 3 урока.
Как правило, любая игра начинается с окна, именно в нем в дальнейшем можно отрисовывать результаты работы видеокарты.
Сделайте новый проект с помощью cargo:
cargo new rust_wgpu_tutorial --binЯ буду использовать следующие зависимости:
[dependencies]
winit = "0.26"
env_logger = "0.9"
log = "0.4"
wgpu = "0.13"Теперь сам код:
use winit::{
event::*,
event_loop::{ControlFlow, EventLoop},
window::WindowBuilder,
};
fn main() {
env_logger::init();
let event_loop = EventLoop::new();
let window = WindowBuilder::new().build(&event_loop).unwrap();
event_loop.run(move |event, _, control_flow| match event {
Event::WindowEvent {
ref event,
window_id,
} if window_id == window.id() => match event {
WindowEvent::CloseRequested | WindowEvent::KeyboardInput {
input:
KeyboardInput {
state: ElementState::Pressed,
virtual_keycode: Some(VirtualKeyCode::Escape),
..
},
..
} => *control_flow = ControlFlow::Exit,
_ => {}
},
_ => {}
});
}Помимо самого окна я добавил еще логгер, чтобы в дальнейшем видеть детализацию ошибок wgpu, если они произойдут. Если вы работали с растом, то этот код не вызывает много вопросов, кроме разве что конструкции внутри match. Там говорится следующее: для всех событий в event_loop, отбери только те, которые относятся к текущему окну. Если событие WindowEvent::CloseRequested, либо WindowEvent::KeyboardInput, тогда происходит деструктуризация структуры KeyboardInput. Если поле virtual_keycode внутри равно Some(VirtualKeyCode::Escape), тогда установи событие ControlFlow::Exit (закрой окно). Напоминает продвинутый pattern-matching в haskell. Вот за что я люблю rust.
Отлично, окно отображается! Сделаем небольшой рефакторинг, добавив файл state.rs в папку src, со следующим содержимым:
use winit::window::Window;
use winit::{
event::*,
};
pub struct State {
surface: wgpu::Surface,
device: wgpu::Device,
queue: wgpu::Queue,
config: wgpu::SurfaceConfiguration,
size: winit::dpi::PhysicalSize,
}
impl State {
pub async fn new(window: &Window) -> Self {
todo!()
}
pub fn resize(&mut self, new_size: winit::dpi::PhysicalSize) {
todo!()
}
pub fn input(&mut self, event: &WindowEvent) -> bool {
todo!()
}
pub fn update(&mut self) {
todo!()
}
pub fn render(&mut self) -> Result<(), wgpu::SurfaceError> {
todo!()
}
} Начнем реализацию с метода new:
async fn new(window: &Window) -> Self {
let size = window.inner_size();
// instance - объект для работы с wgpu
// Backends::all => OpenGL + Vulkan + Metal + DX12 + Browser WebGPU
let instance = wgpu::Instance::new(wgpu::Backends::all());
let surface = unsafe { instance.create_surface(window) };
let adapter = instance.request_adapter(
&wgpu::RequestAdapterOptions {
power_preference: wgpu::PowerPreference::LowPower,
compatible_surface: Some(&surface),
force_fallback_adapter: false,
},
).await.unwrap();
}Instance и Adapter
Для работы с видеокартой нам понадобиться Adapter и Surface, которые можно создать через методы instance. Мне нравится, что прежде чем работать с видеокартой, нужно создать instance, а не работать с глобальным изменяемым состоянием, как это делается в OpenGL, например.
При выборе адаптера, мы руководствуемся следующими опциями:
power_preferenceв этом свойстве можно задать приоритет выбора GPU. При выбореLowPower, wgpu выберет интегрированную видеокарту.compatible_surfaceпроверяем совместимость адаптера с созданным окном.force_fallback_adapterесли этот флаг установлен вtrue, wgpu выберет адаптер, который с больше долей вероятности будет работать на любом железе, предпочтение будет отдано интегрированной карте
Surface
Surface это область окна (как canvas в html), которая будет использоваться для отрисовки. Чтобы получить surface, окно должно реализовать HasRawWindowHandle из пакета raw-window-handle. В нашем случае, winit подходит под эти требования.
Device & Queue
Как и в случае с instance, мы работаем не с глобальными объектами, а сами создаем нужные структуры. Чтобы создать device и queue, я добавил следующим код:
let (device, queue) = adapter.request_device(
&wgpu::DeviceDescriptor {
features: wgpu::Features::empty(),
limits: wgpu::Limits::default(),
label: None,
},
None, // Trace path
).await.unwrap();Мы можем указать конкретные возможности видеокарты, которые хотим использовать в свойстве features. Чтобы задать пороговые значения для свойств, используется поле limits. Например, там есть свойства max_vertex_attributes или max_vertex_buffer_array_stride. Посмотреть список всех свойств можно здесь.
Указание этих свойств может быть полезно, чтобы расширить спектр поддерживаемых GPU.
Последнее, что нужно добавить в метод State::new, это создание конфига:
let config = wgpu::SurfaceConfiguration {
usage: wgpu::TextureUsages::RENDER_ATTACHMENT,
format: surface.get_supported_formats(&adapter)[0],
width: size.width,
height: size.height,
present_mode: wgpu::PresentMode::Fifo,
};
surface.configure(&device, &config);
// Формируем структуру State
Self {
surface,
device,
queue,
config,
size
}Посмотрим подробнее на поля конфига:
usageпоказывает, в каком режиме должна работать видеокарта.formatопределяет, в каком формате будут храниться текстурыSurfaceTextures. У разных дисплеев могут быть свои требования, поэтому здесь выбирается первый подходящий формат.present_modeопределяет, как будет синхронизироватьсяSurfaceс экраном.wgpu::PresentMode::FifoозначаетVSYNC.
Осталось создать структуру State в методе main:
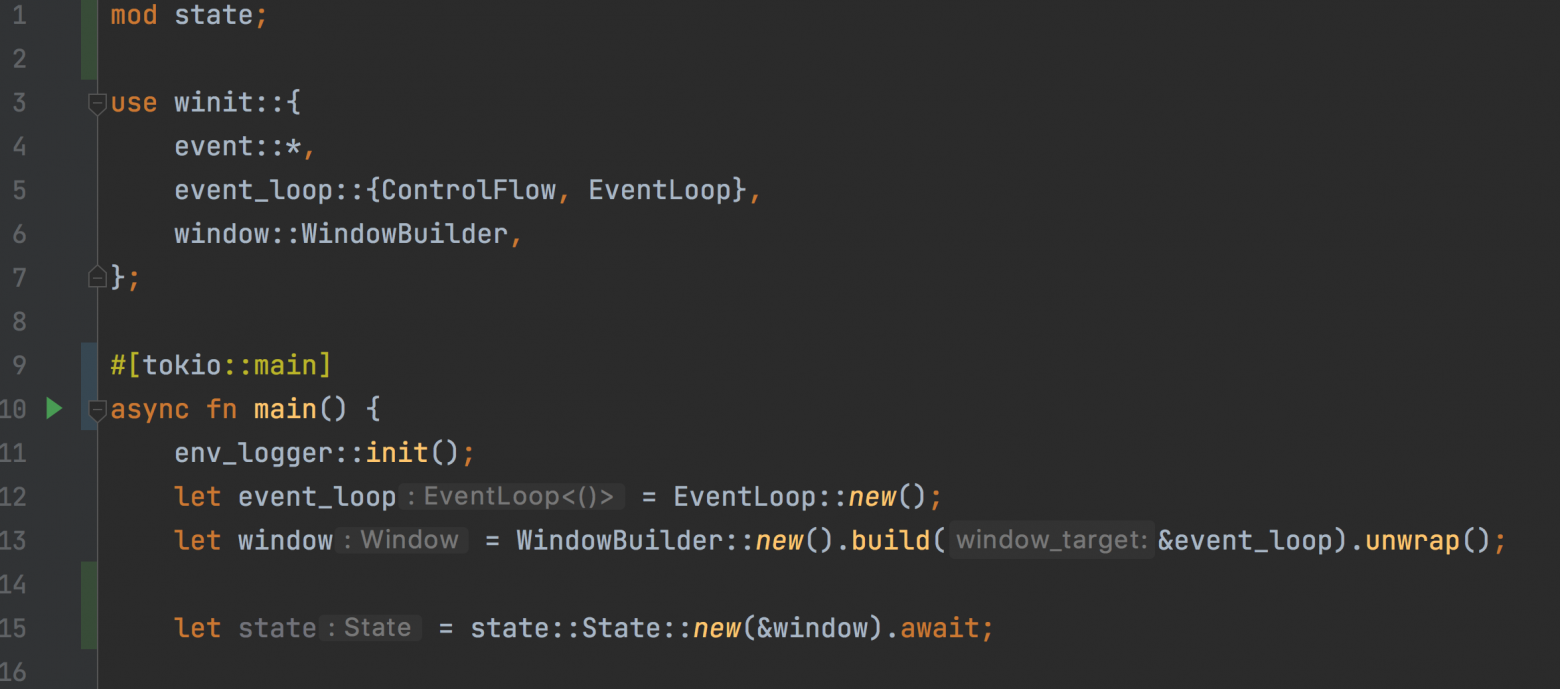 Создаем State
Создаем State
Тк метод State::new асинхронный, вызвать его мало, нужно еще дождаться его выполнения, для чего используется .await. Чтобы этот код работал, нужен Executor. Я воспользуюсь tokio, указав его в зависимостях:
tokio = { version = "1", features = ["full"] }
Метод main тоже нужно сделать асинхронным и пометить аннотацией:
#[tokio::main].
Теперь все работает!
resize
Продолжим нашу работу, реализовав метод resize, который будет вызываться при изменении размеров окна.
fn resize(&mut self, new_size: winit::dpi::PhysicalSize) {
if new_size.width > 0 && new_size.height > 0 {
self.size = new_size;
self.config.width = new_size.width;
self.config.height = new_size.height;
self.surface.configure(&self.device, &self.config);
}
} main.rs:
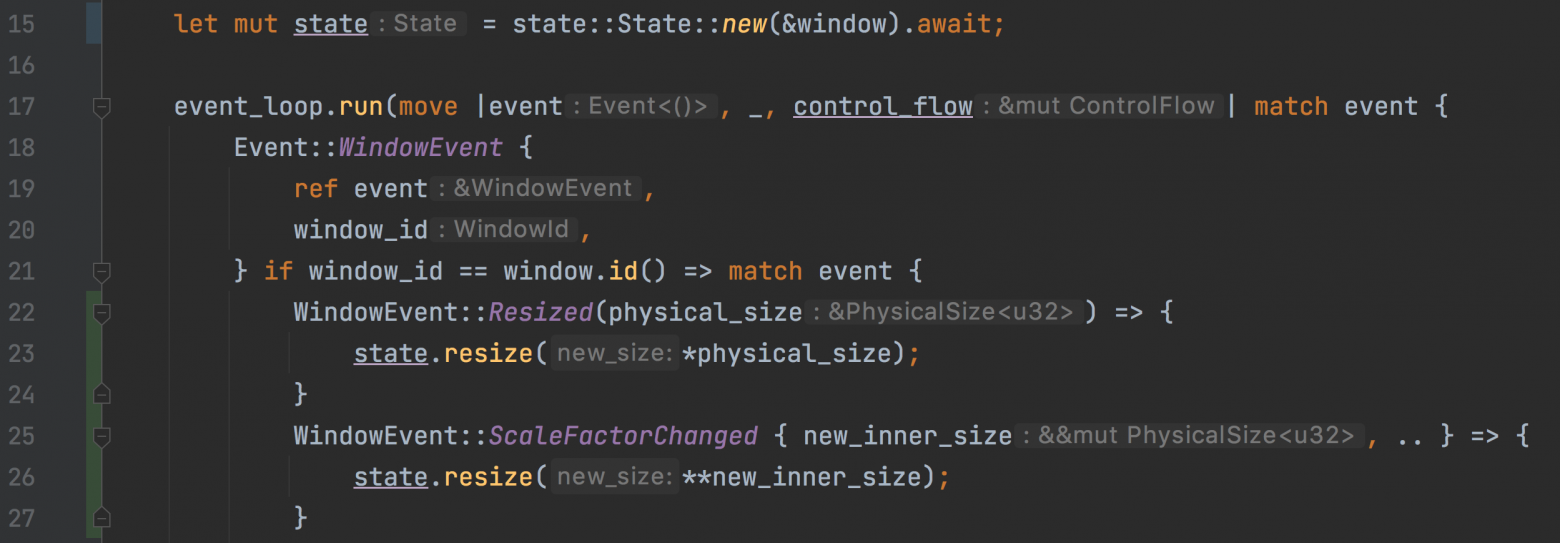 Обработка события Resized & ScaleFactorChanged
Обработка события Resized & ScaleFactorChanged
Так гораздо удобнее!
Мне сильно не хватает возможности перетаскивания окна, поэтому добавил обработку события Moved:
WindowEvent::Moved(_) => {
window.request_redraw();
}render
Сделаем заливку цветом. Для этого нужно добавить несколько строк в метод State::render.
let output = self.surface.get_current_texture()?;Сначала мы получаем SurfaceTexture (результат работы строки выше, фрейм), чтобы потом отрисовывать туда наш фон.
let view = output.texture.create_view(&wgpu::TextureViewDescriptor::default());create_view возвращает TextureView, то, куда будем рендерить.
let mut encoder = self.device.create_command_encoder(&wgpu::CommandEncoderDescriptor {
label: Some("Render Encoder"),
});Нам также понадобиться CommandEncoder, чтобы подготовить команды, который будет выполнять GPU.
Теперь самый большой кусок:
encoder.begin_render_pass(&wgpu::RenderPassDescriptor {
label: Some("Render Pass"),
color_attachments: &[Some(wgpu::RenderPassColorAttachment {
view: &view,
resolve_target: None,
ops: wgpu::Operations {
load: wgpu::LoadOp::Clear(wgpu::Color {
r: 0.1,
g: 0.2,
b: 0.3,
a: 1.0,
}),
store: true,
},
})],
depth_stencil_attachment: None,
});Подготавливаем RenderPass, который содержит в себе методы для рисования. В данном примере мы сделаем заливку экрана в синий цвет.
Поле color_attachments.view указывает, куда отрисовывать изображение (переменная view).
color_attachments.ops.load определяем, что делать с изображением из предыдущего кадра.
В данном примере мы очищаем экран и делаем заливку синим цветом.
И последние строки в методе render:
self.queue.submit(std::iter::once(encoder.finish()));
output.present();
Ok(())Отправляем RenderPass на выполнение и отрисовываем результат на экран.
Здесь все, но нужно еще обработать два новых события в главном цикле:
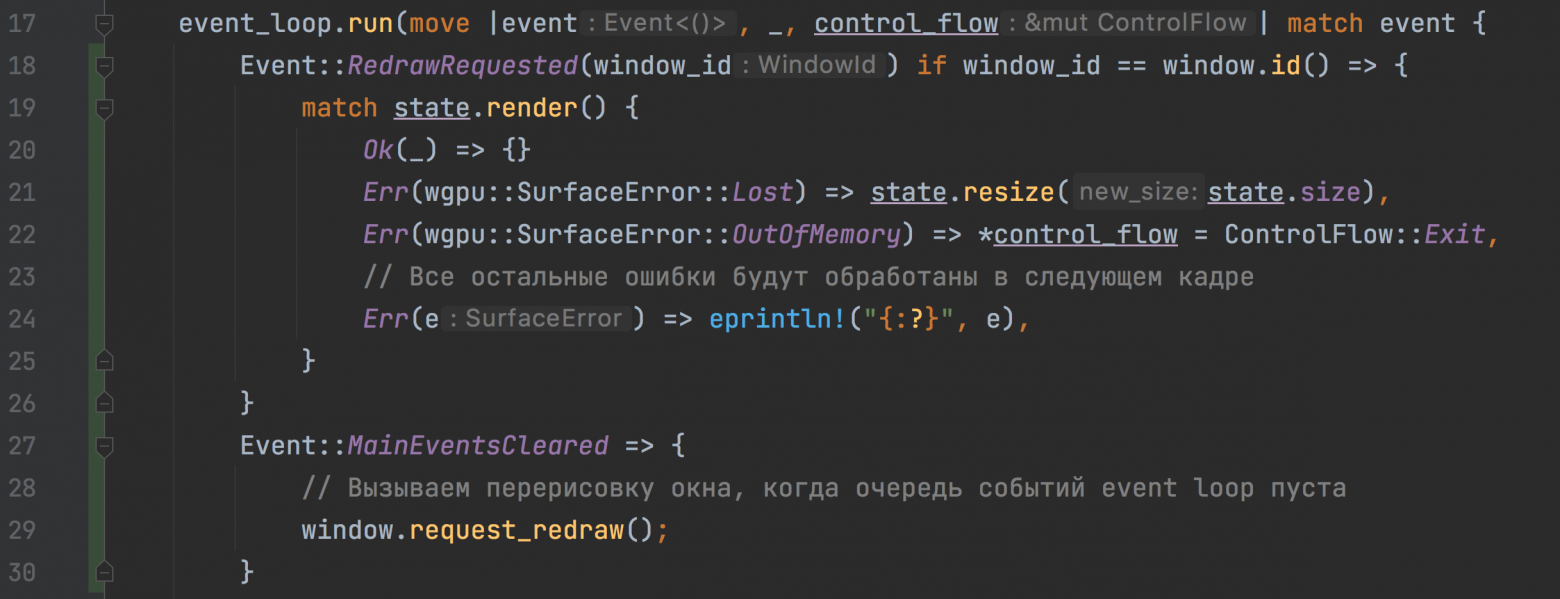 Обработка событий RedrawRequested и MainEventsCleared
Обработка событий RedrawRequested и MainEventsCleared
Вот, что должно получиться:
 Синее окно
Синее окно
Задание
Добавить в метод input обработчик событий движения мышки и менять цвет заливки в соответствии с полученными координатами. (Вам понадобиться WindowEvent::CursorMoved)
Ссылка на код урока
Урок 2
The Pipeline. Графический конвейер
Если вы работали с OpenGL, то наверняка знаете про шейдеры. Конвейер объединяет все операции, которые видеокарта будет делать с входными данными (в том числе и шейдеры) в одном месте.
Шейдер — это мини программы, которые выполняются на видеокарте. Выделяют три типа шейдеров: вершинный, фрагментный и вычислительный. Есть и геометрические шейдеры, но их мы не будем рассматривать в этом уроке.
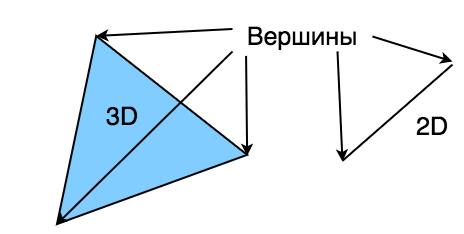
Vertex (вершина) — это точка в 3D пространстве (или 2D). Вершины объединяются в группы по 3 или 2, формируя треугольники или отрезки. С помощью треугольников можно сделать модель любой сложности, начиная от куба и заканчивая человеком.
Вершинный шейдер используется для управления вершинами, например сдвиг или масштабирование.
Затем вершины преобразуются во фрагменты. Каждый пиксель в итоговом изображении имеет фрагмент, для управления цветом.
WGSL
Существует несколько языков для написания шейдеров: GLSL, HLSL, MSL, SPIR-V, которые используются соответственно в OpenGL, DirectX, Metal, Vulkan. Но в стандарте WebGPU определили новый язык чтобы управлять ими всеми для унификации. WGSL можно конвертировать во все описанные языки шейдеров.
Напишем наш первый шейдер!
// Вершинный шейдер
struct VertexOutput {
@builtin(position) clip_position: vec4, // 1
};
@vertex // 2
fn vs_main(
@builtin(vertex_index) in_vertex_index: u32, // 3
) -> VertexOutput {
var out: VertexOutput; // 4
let x = f32(1 - i32(in_vertex_index)) * 0.5; // 5
let y = f32(i32(in_vertex_index & 1u) * 2 - 1) * 0.5;
out.clip_position = vec4(x, y, 0.0, 1.0); // 6
return out;
} Довольно сильно напоминает rust, не находите?
Структура
VertexOutputопределяет выходное значение шейдера. Пока что в нем будет только одно полеclip_position, помеченное аннотацией@builtin(position). Тк шейдер имеет входные и выходные параметры (результат вычисления), мы должны указать явным образом, какое именно поле в структуреVertexOutputпредставляет итоговые координаты (position), с помощью аннотации. В OpenGL для этого используетсяgl_Position.Точка входа в программу шейдеров WGSL помечена аннотацией
@vertex. В WGSL вершинный и фрагментный шейдер могут находиться в одном файле, что является несомненным плюсом.На входе в функцию задается один параметр
in_vertex_index, который задается в конфигурацииpipeline. Аннотация@builtin(vertex_index)задает назначение аргумента. Это демонстрационный пример, далее будет использоваться другая аннотация. В реальных шейдерах чаще задаются непосредственно вершины, но в данном примере мы будем их вычислять динамически, опираясь только наin_vertex_index.Внутри мы видим объявление переменной с типом
VertexOutput, которая будет возвращаться из функции.При вычислении координат
xиyиспользуются функцииf32&i32, они выполняют роль приведения (cast) типов. Так же, как и в расте, в WGSL есть изменяемыйvarпеременные и не изменяемыеlet.Присваивание полей структуры делается аналогичны, задаем значение
out.clip_positionи возвращаемout.
В данном примере мы можем задать выходное значение напрямую, без структуры VertexOutput:
@vertex
fn vs_main(
@builtin(vertex_index) in_vertex_index: u32
) -> @builtin(position) vec4 {
// ...
} Пока что я оставлю эту структуру, тк позже добавлю туда еще полей.
Фрагметный шейдер
@fragment
fn fs_main(in: VertexOutput) -> @location(0) vec4 {
return vec4(0.3, 0.2, 0.1, 1.0);
} Здесь мы задаем выходной цвет заливки пространства внутри вершин (треугольников) в коричневый. По аналогии с VertexOutput, @location(0) задает индекс выходного фрагментного буфера, только там использовалось именованное поле position, а здесь используются числовые индексы. Позже добавим структуру.
Новый State
Настало время обновить структуру State!
Добавим pipeline:
pub struct State {
surface: wgpu::Surface,
device: wgpu::Device,
queue: wgpu::Queue,
mouse_x: Option,
mouse_y: Option,
config: wgpu::SurfaceConfiguration,
pub(crate) size: winit::dpi::PhysicalSize,
// NEW!
render_pipeline: wgpu::RenderPipeline,
} Перейдем к методу State::new:
let shader = device.create_shader_module(wgpu::include_wgsl!("shader.wgsl"));Макрос include_wgsl! читает указанный файл и преобразует его в ShaderModuleDescriptor.
Создадим render_layout:
let render_pipeline_layout =
device.create_pipeline_layout(&wgpu::PipelineLayoutDescriptor {
label: Some("Render Pipeline Layout"),
bind_group_layouts: &[],
push_constant_ranges: &[],
});Пока что здесь ничего интересного, позже мы подробнее рассмотрим, что может быть внутри bind_group_layouts.
let render_pipeline = device.create_render_pipeline(&wgpu::RenderPipelineDescriptor {
label: Some("Render Pipeline"),
layout: Some(&render_pipeline_layout),
vertex: wgpu::VertexState { // 1
module: &shader,
entry_point: "vs_main", // 2.
buffers: &[], // 3.
},
fragment: Some(wgpu::FragmentState { // 4.
module: &shader,
entry_point: "fs_main", // 5
targets: &[Some(wgpu::ColorTargetState { // 6.
format: config.format,
blend: Some(wgpu::BlendState::REPLACE),
write_mask: wgpu::ColorWrites::ALL,
})],
}),
// ...Ранее я говорил, что WGSL умеет хранить разные типы шейдеров в одном файле. Именно здесь задаются точки входа для вершинного и фрагментных шейдеров. Рассмотрим, что еще здесь происходит:
Структура вершинного шейдера
Точка входа вершинного шейдера
Буфер, который будет отправлен на обработку в вершинный шейдер. Обычно, здесь находяться вершины, но в данном примере вершины вычисляются прямо в шейдере (
xиy), поэтому здесь буфер пустой.Структура фрагментного шейдера
Точка входа фрагментного шейдера
ColorTargetStateуказывает, какой цветовой буфер использовать. Сейчас мы берем значение изsurface.ColorWrites::ALLговорит использовать все цвета: красный, синий, зеленый и альфа канал.BlendState::REPLACEзадает поведение при смешевании, мы указываем, что новый цвет должен перезаписать старый.
// ...
primitive: wgpu::PrimitiveState {
topology: wgpu::PrimitiveTopology::TriangleList, // 1.
strip_index_format: None,
front_face: wgpu::FrontFace::Ccw, // 2.
cull_mode: Some(wgpu::Face::Back),
polygon_mode: wgpu::PolygonMode::Fill,
unclipped_depth: false,
conservative: false,
},
// ...Здесь мы задаем как преобразовывать входной буфер из вершин в треугольники.
depth_stencil: None, // 1.
multisample: wgpu::MultisampleState {
count: 1, // 2.
mask: !0, // 3.
alpha_to_coverage_enabled: false, // 4.
},
multiview: None, // 5.
});Пока мы не будем использовать
depth_stencilВеличина сглаживания
Определяет, какие выборки будут активны. Значение
!0значит «все». Подробнее про сглаживания читайте здесьПока что не будем это использовать
Это свойство используется для рендеринга в массивы текстур, не наш случай
Self {
surface,
device,
queue,
config,
size,
// NEW!
render_pipeline,
}Теперь у нас есть пайплайн!
Render
Если сейчас запустить программу, ничего не измениться, потому что рендеринг остался старый и в нем не используется новый пайплайн. Сейчас мы это исправим!
Добавьте следующий код в метод State::render:
Сохраним результат вызова
begin_render_passвrender_passСвязываем
render_passиrender_pipelineВызываем отрисовку
Обратите внимание, я обрамил код в еще одни фигурные скобки. Это нужно, чтобы обойти ограничение на наличие двух изменяемых ссылок в одной области видимости. Без них код не скомпилируется.
Должен получиться такой треугольник:

Домашнее задание
Добавьте второй пайплайн, который будет вычислять цвет во фрагментном шейдере исходя из позиции в вершинном шейдере (VertexOutput). Сделайте переключение между пайплайнами по нажатии на кнопку space.
Ссылка на код урока
Урок 3
Загрузка вершин в GPU
В этом уроке мы будем работать с вершинным и индексным буфером.
Что такое буфер?
Под буфером имеется в виду любой последовательный массив данных, как например тип Vec в расте. Обычно в буфере храниться массив простых структур, но также там могут быть и сложные структуры данных (граф, например), при условии, что они будут иметь плоскую (последовательную) структуру. Мы будем часто использовать буферы. Начнем изучение с вершинного и индексного буфера.
Вершинный буфер
В прошлом уроке мы динамически вычисляли вершины прямо в шейдере, поэтому обошлись без вершинного буфера. Но это не лучшая практика, тк теряется возможность переиспользования шейдера и установки других вершин без перезапуска программы. Сейчас мы перепишем код, чтобы вершинный буфер формировался на стороне программы и потом отправим его в шейдер.
Прежде всего, нужно объявить структуру в файле state, которая будет описывать вершины:
#[repr(C)]
#[derive(Copy, Clone, Debug, bytemuck::Pod, bytemuck::Zeroable)]
struct Vertex {
position: [f32; 3],
color: [f32; 3],
}Эта структура описывать вершину в трехмерных координатах, ее положение (x, y, z) и цвет (red, green, blue). Обратите внимание на аннотацию #[repr(C)], она говорит компилятору использовать правила выравнивания из языка С. Если ее убрать, будет достаточно трудно найти ошибку. Как правило, все структуры, которые будут отправляться в GPU, должны быть помечены #[repr(C)].
Еще я добавил bytemuck в Cargo.toml:
bytemuck = { version = "1.4", features = ["derive"] }Теперь можно сделать сами вершины:
const VERTICES: &[Vertex] = &[
Vertex { position: [0.0, 0.5, 0.0], color: [1.0, 0.0, 0.0] },
Vertex { position: [-0.5, -0.5, 0.0], color: [0.0, 1.0, 0.0] },
Vertex { position: [0.5, -0.5, 0.0], color: [0.0, 0.0, 1.0] },
];Вершины здесь указаны против часовой стрелки: верхний угол, нижний левый и правый левый. В прошлом уроке мы указывали, что вершины должны располагаться в буфере именно в таком порядке, тогда они будут на переднем плане.
Указатель на буфер будет храниться в структуре State:
struct State {
// ...
render_pipeline: wgpu::RenderPipeline,
// NEW!
vertex_buffer: wgpu::Buffer,
// ...
}Создаем буфер:
let vertex_buffer = device.create_buffer_init(
&wgpu::util::BufferInitDescriptor {
label: Some("Vertex Buffer"),
contents: bytemuck::cast_slice(VERTICES),
usage: wgpu::BufferUsages::VERTEX,
}
);Чтобы у вас появился метод create_buffer_init, нужно импортировать трейт use wgpu::util::DeviceExt. Для contents я использую приведение типа через bytemuck, именно для этого Vertex был помечен bytemuck::Pod & bytemuck::Zeroable. Аннотация Pod это аббревиатура, которая расшифровывается «Plain Old Data», которая включает преобразование структуры в &[u8]. Zeroable значит, что мы можем безопасно использовать std::mem::zeroed() на структуре.
И в конце добавляем:
Self {
surface,
device,
queue,
config,
size,
render_pipeline,
// NEW!
vertex_buffer,
}Отправка буфера в GPU
Я сделал буфер, но пока что он не используется в render_pipeline. Чтобы его задействовать, нужно создать разметку данных (VertexBufferLayout), потому что данные в буфере передаются в GPU в сыром виде, без типизации. То-есть, мы не сможем понять, где в буфере будут находиться position, а где color.
VertexBufferLayout определяет представление (layout) данных буфера в памяти:
impl Vertex {
fn description<'a>() -> wgpu::VertexBufferLayout<'a> {
wgpu::VertexBufferLayout {
array_stride: std::mem::size_of::() as wgpu::BufferAddress, // 1
step_mode: wgpu::VertexStepMode::Vertex, // 2
attributes: &[ // 3
wgpu::VertexAttribute {
offset: 0, // 4
shader_location: 0, // 5
format: wgpu::VertexFormat::Float32x3, // 6
},
wgpu::VertexAttribute {
offset: std::mem::size_of::<[f32; 3]>() as wgpu::BufferAddress,
shader_location: 1,
format: wgpu::VertexFormat::Float32x3,
}
]
}
}
} array_strideопределяет размер структурыVertexвместе с выравниванием. В нашем случае размер будет примерно 24 байта.step_modeзадает режим индексации. Помните входной аргумент в вершинном шейдере@builtin(vertex_index) in_vertex_index: u32? От заданного параметраVertexStepModeзависит, с какими индексами будет вызываться вершинный шейдер.Vertexрежим работы по-умолчанию, кроме него есть ещеInstance, мы рассмотрим, как с ним работать позже.attributesнужен для описания полей структурыVertex. В нашем случае структура имеет два поля: позицию и цвет. Соответственно, вatrributesмы имеем две записи для позиции и цвета.offsetзадает смещение относительноarray_strideдля каждого поля в структуреVertex. Первое поле —positionимеет смещение 0 (тк перед ним ничего нет). Для вычисления смещения следующего поля, нужно прибавить к нулю размерposition, то-естьstd::mem::sizeof::<[f32; 3]>()или 4×3 = 12 байт.shader_locationзадает индекс дляlocation, через который можно будет обращаться к полюposition, например так@location(0) position: vec3.formatзадает тип параметра (поля) структуры. В данном случае,positonимеет тип[f32; 3], ему соответсвует типvec3в шейдере, а в полеformatмы указываемVertexFormat::Float32x3.
Вот так это выглядит (взял картинку из оригинальной статьи):

Теперь мы можем задать описание нашего буфера в render_pipeline:
let render_pipeline = device.create_render_pipeline(&wgpu::RenderPipelineDescriptor {
// ...
vertex: wgpu::VertexState {
// ...
buffers: &[
Vertex::description(),
],
},
// ...
});И отправить буфер в render_pass:
render_pass.set_vertex_buffer(0, self.vertex_buffer.slice(..));set_vertex_buffer принимает два аргумента, первый — это слот, в который попадет буфер, второй сам буфер. При необходимости, мы можем отправлять данные порционно, но в данном случае я отправляю весь буфер.
Мне нужно отрисовать сейчас три вершины, поэтому я вызываю
render_pass.draw(0..3, 0..1);Но для большей гибкости, здесь лучше использовать переменную величину, которая будет соответствовать реальному размеру текущего буфера:
render_pass.draw(0..VERTICES.len() as u32, 0..1);Если сейчас запустить программу, ничего не измениться, потому что нужно обновить шейдеры:
// Вершинный шейдер
struct VertexInput {
@location(0) position: vec3,
@location(1) color: vec3,
};
struct VertexOutput {
@builtin(position) clip_position: vec4,
@location(0) color: vec3,
};
@vertex
fn vs_main(
model: VertexInput,
) -> VertexOutput {
var out: VertexOutput;
out.color = model.color;
out.clip_position = vec4(model.position, 1.0);
return out;
}
// Фрагментный шейдер
@fragment
fn fs_main(in: VertexOutput) -> @location(0) vec4 {
return vec4(in.color, 1.0);
} Теперь готово:

Индексный буфер
В них нет строгой необходимости, но они могут сократить количество используемое вершинным буфером памяти для больших моделей. Рассмотрим такую фигуру (картинка из оригинальной статьи):

В ней 5 вершин и три треугольника. Вершинный буфер для нее будет выглядеть следующим образом:
const VERTICES: &[Vertex] = &[
Vertex { position: [-0.0868241, 0.49240386, 0.0], color: [0.5, 0.0, 0.5] }, // A
Vertex { position: [-0.49513406, 0.06958647, 0.0], color: [0.5, 0.0, 0.5] }, // B
Vertex { position: [0.44147372, 0.2347359, 0.0], color: [0.5, 0.0, 0.5] }, // E
Vertex { position: [-0.49513406, 0.06958647, 0.0], color: [0.5, 0.0, 0.5] }, // B
Vertex { position: [-0.21918549, -0.44939706, 0.0], color: [0.5, 0.0, 0.5] }, // C
Vertex { position: [0.44147372, 0.2347359, 0.0], color: [0.5, 0.0, 0.5] }, // E
Vertex { position: [-0.21918549, -0.44939706, 0.0], color: [0.5, 0.0, 0.5] }, // C
Vertex { position: [0.35966998, -0.3473291, 0.0], color: [0.5, 0.0, 0.5] }, // D
Vertex { position: [0.44147372, 0.2347359, 0.0], color: [0.5, 0.0, 0.5] }, // E
];Можно заметить, что вершины C и B повторяются дважды, а E трижды. Если взять размер каждой вершины в 24 байта, то из 216 байт, 96 будут повторяться. Было бы здорово, если мы могли бы перечислить каждую из вершин только один раз?
Здесь приходит на помощь индексный буфер!
const VERTICES: &[Vertex] = &[
Vertex { position: [-0.0868241, 0.49240386, 0.0], color: [0.5, 0.0, 0.5] }, // A
Vertex { position: [-0.49513406, 0.06958647, 0.0], color: [0.5, 0.0, 0.5] }, // B
Vertex { position: [-0.21918549, -0.44939706, 0.0], color: [0.5, 0.0, 0.5] }, // C
Vertex { position: [0.35966998, -0.3473291, 0.0], color: [0.5, 0.0, 0.5] }, // D
Vertex { position: [0.44147372, 0.2347359, 0.0], color: [0.5, 0.0, 0.5] }, // E
];
const INDICES: &[u16] = &[
0, 1, 4, // треугольник A, B, E
1, 2, 4, // треугольник B, C, E
2, 3, 4, // треугольник C, D, E
];В таком сценарии VERTICES будет занимать всего 120 байт, а INDICES 18 байт + 2 на выравнивание. Мы сэкономили 76 байт! Это кажется мало, но для больших фигур разница будет больше.
Нужно внести несколько правок, прежде чем использовать индексный буфер.
struct State {
surface: wgpu::Surface,
device: wgpu::Device,
queue: wgpu::Queue,
config: wgpu::SurfaceConfiguration,
size: winit::dpi::PhysicalSize,
render_pipeline: wgpu::RenderPipeline,
vertex_buffer: wgpu::Buffer,
// NEW!
index_buffer: wgpu::Buffer, // положим индексный буфер сюда
num_indices: u32,
} Начнем с создания нового буфера для индексов в методе State::new:
let index_buffer = device.create_buffer_init(
&wgpu::util::BufferInitDescriptor {
label: Some("Index Buffer"),
contents: bytemuck::cast_slice(INDICES),
usage: wgpu::BufferUsages::INDEX,
}
);
let num_indices = INDICES.len() as u32;Еще я добавил переменную num_indices, которая также будет находиться в State:
Self {
surface,
device,
queue,
config,
size,
render_pipeline,
vertex_buffer,
// NEW!
index_buffer,
num_indices,
}Теперь обновим метод State::render:
// render()
render_pass.set_pipeline(&self.render_pipeline);
render_pass.set_vertex_buffer(0, self.vertex_buffer.slice(..));
render_pass.set_index_buffer(self.index_buffer.slice(..), wgpu::IndexFormat::Uint16); // 1
render_pass.draw_indexed(0..self.num_indices, 0, 0..1); // 2Несколько вещей, которые нужно отметить:
Единовременно вы можете использовать только один индексный буфер, о чем говорит название метода
set_index_bufferКогда вы используете индексный буфер, для отрисовки нужно вызывать
draw_indexed. Также не забудьте, чтоself.num_indicesравно количеству элементов в индексном буфере, но не количеству вершин. Ошибки в этом параметре приведут к неправильной отрисовке или экстренному завершению процесса.Код шейдера не требуется менять для поддержки индексного буфера
Вот, что получилось:

Цветовая коррекция
Если вы проверите цвет пентагона, то получите значение #BC00BC. Сконвертировав значение в RGB получаем (188, 0, 188). Разделив значения на 255, чтобы получить цвет в промежутке [0, 1], получим значение (0.737254902, 0, 0.737254902), вместо указанного (0.5, 0.0, 0.5).
Мы можем вычислить аппроксимацию значения цвета по формуле srgb_color = (rgb_color / 255) ^ 2.2. Для цвета (188, 0, 188) мы получим значение (0.511397819, 0.0, 0.511397819), что уже гораздо ближе к исходному.
Кроме этого, можно использовать текстуры, тк в них цвета уже в нужном формате.
Домашнее задание
Нарисуйте более сложную фигуру, с большим количеством треугольников, используя вершинный и индексный буфер. Сделайте смену фигур по кнопке space.
Ссылка на код урока
Заключение
Мы научились писать кроссплатформенный код и работать с графикой на базовом уровне, после чего можно двигаться дальше. В следующих статьях мы рассмотрим, как работать с текстурами, загружать модели и делать освещение.
