[Перевод] Путь Go: как ускорялась сборка мусора
Но эта статья — не очередное воспевание Go. Она о том, как наше использование этого языка раздвигает некоторые границы текущей реализации runtime«а и как мы реагируем на достижение этих границ.
Это история о том, как улучшение runtime«а с Go 1.4 по Go 1.6 дало нам 20-кратное уменьшение пауз при работе сборщика мусора, как мы получили ещё 10-кратное уменьшение пауз в Go 1.6 и как, передав наш опыт команде разработчиков, работающей над runtime«ом Go, обеспечили 10-кратное ускорение в Go 1.7 без дополнительных ручных настроек с нашей стороны.
Наша система чата на базе IRC впервые была реализована на Go в конце 2013 года. Она пришла на смену предыдущей реализации на Python. Для её создания использовались пререлизные версии Go 1.2, и система была способна одновременно обслуживать до 500 000 пользователей с каждого физического хоста без особых ухищрений.
При обслуживании каждого соединения группой из трёх горутин (легковесные потоки выполнения в Go) программа утилизировала 1 500 000 горутин на один процесс. И даже при таком их количестве единственной серьёзной проблемой в производительности, с которой мы столкнулись в версиях до Go 1.2, была продолжительность пауз на сборку мусора. Приложение останавливалось на десятки секунд при каждом запуске сборщика, а это было недопустимо для нашего интерактивного чат-сервиса.
Мало того что каждая пауза на сборку мусора обходилась очень дорого, так ещё и сборка запускалась по несколько раз в минуту. Мы потратили много сил на снижение количества и размера выделяемых блоков памяти, чтобы сборщик запускался реже. Для нас стало победой увеличение кучи (heap) лишь на 50% каждые две минуты. И хотя пауз стало меньше, они оставались очень продолжительными.
После релиза Go 1.2 паузы сократились «всего» до нескольких секунд. Мы распределили трафик по большему количеству процессов, что позволило уменьшить продолжительность пауз до более комфортного значения.
Работа над уменьшением выделений памяти на нашем чат-сервере продолжает приносить пользу и сейчас, несмотря на развитие Go, но разбиение на несколько процессов — обходное решение только для определённых версий Go. Подобные ухищрения не выдерживают испытания временем, но важны для решения сиюминутных задач по обеспечению качественного сервиса. И если мы будем делиться друг с другом опытом использования обходных решений, то это поможет сделать в runtime«е Go улучшения, которые принесут пользу всему сообществу, а не одной программе.
Начиная с Go 1.5 в августе 2015-го сборщик мусора Go стал работать по большей части конкуррентно и инкрементально. Это означает, что почти вся работа выполняется без полной остановки приложения. Кроме того что фазы подготовки и прерывания достаточно короткие, наша программа продолжает работать в то время, как процесс сборки мусора уже идёт. Переход на Go 1.5 моментально привёл к 10-кратному уменьшению пауз в нашей чат-системе: при большой нагрузке в тестовом окружении с двух секунд до приблизительно 200 мс.
Go 1.5 — новая эра сборки мусораХотя уменьшение задержки в Go 1.5 само по себе стало для нас праздником, самым лучшим свойством нового сборщика мусора оказалось то, что он подготовил почву для дальнейших последовательных улучшений.
Сборка мусора в Go 1.5 по-прежнему состоит из двух основных фаз:
- Mark — сначала помечаются те участки памяти, которые ещё используются;
- Sweep — все неиспользуемые участки подготавливаются к повторному использованию.
Но каждая из этих фаз теперь состоит из двух стадий:
- Mark:
- приложение приостанавливается, ожидая завершения предыдущей sweep-фазы;
- затем одновременно с работой приложения выполняется поиск используемых блоков памяти.
- Sweep:
- приложение снова ставится на паузу для прерывания mark-фазы;
- одновременно с работой приложения неиспользуемая память постепенно подготавливается к переиспользованию.
Runtime-функция
gctrace позволяет вывести на экран информацию с результатами по каждой итерации сборки мусора, включая продолжительность всех фаз. Для нашего чат-сервера она показала, что бOльшая часть паузы приходится на прерывание mark-фазы, поэтому мы решили сосредоточить на этом своё внимание. И хотя группа разработчиков Go, отвечающая за runtime, запросила баг-репорты из приложений, в которых наблюдаются длинные паузы на сборку мусора, мы оказались разгильдяями и сохранили это в секрете! Конечно, нам нужно было собрать больше подробностей о работе сборщика во время пауз. Основные пакеты в Go включают в себя замечательный CPU-профилировщик пользовательского уровня, но для своей задачи мы воспользовались инструментом perf из Linux. Во время нахождения в ядре он позволяет получать семплы с более высокой частотой и видимостью. Мониторинг циклов в ядре может помочь нам отладить медленные системные вызовы и сделать прозрачным управление виртуальной памятью.
Ниже показана часть профиля нашего чат-сервера, работающего на Go 1.5.1. График (Flame Graph) построен с помощью инструмента Брендана Грегга. Включены только те семплы, в стеке которых есть функция runtime.gcMark, в Go 1.5 аппроксимирующая время, потраченное на прерывание mark-фазы.
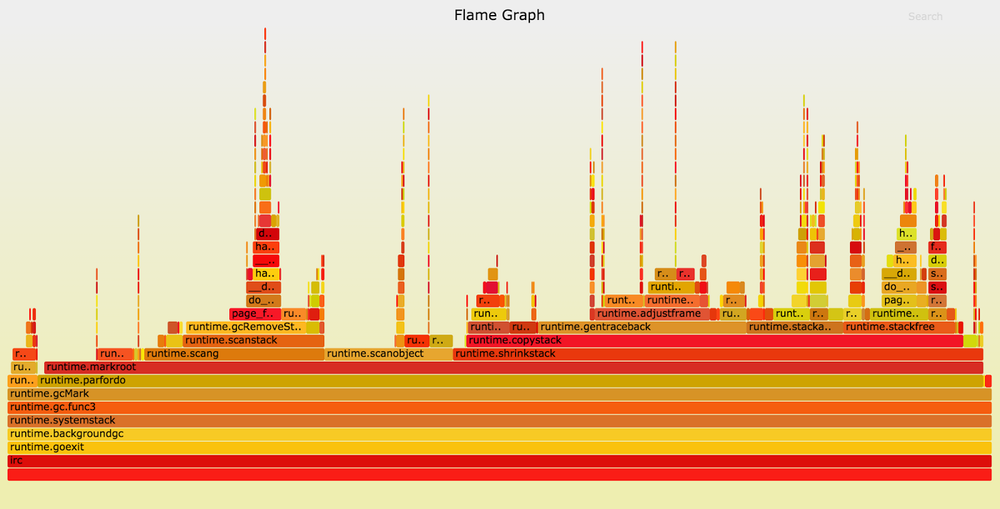
Пики на графике показывают увеличение глубины стека, а ширина каждой секции отражает время работы CPU. На цвета и порядок по оси Х не обращайте внимания, они не имеют значения. В левой части графика мы видим, что почти в каждом из семпловых стеков runtime.gcMark вызывает runtime.parfordo. Посмотрев выше, замечаем, что бо̒льшую часть времени занимают совершаемые runtime.markroot вызовы runtime.scang, runtime.scanobject и runtime.shrinkstack.
Функция runtime.scang предназначена для пересканирования памяти, чтобы помочь завершиться mark-фазе. Суть прерывания заключается в окончании сканирования памяти приложения, так что эта работа совершенно необходима. Лучше придумать, как повысить производительность других функций.
Переходим к runtime.scanobject. У этой функции несколько задач, но её выполнение во время прерывания mark-фазы в Go 1.5 нужно для реализации финализаторов (функция, выполняемая перед удалением объекта сборщиком мусора. — Примеч. переводчика). Вы можете спросить: «Почему программа использует так много финализаторов, что они заметно влияют на длительность пауз при сборке мусора?» В данном случае приложение — это чат-сервер, обрабатывающий сообщения от сотен тысяч пользователей. Основной «сетевой» пакет в Go прикрепляет по финализатору к каждому TCP-соединению для помощи в управлении утечками файловых дескрипторов. А поскольку каждый пользователь получает собственное TCP-соединение, то это вносит небольшой вклад в продолжительность прерывания mark-фазы.
Нам показалось, что это достойно быть зарепорченным команде Go. Мы написали разработчикам, и они очень помогли нам своими советами, как можно диагностировать проблемы в производительности и как их выделить в минимальные тестовые кейсы. В Go 1.6 разработчики перенесли сканирование финализаторов в параллельную mark-фазу, что позволило уменьшить паузу в приложениях с большим количеством TCP-соединений. Было сделано и много других улучшений, в результате при переходе на Go 1.6 паузы на нашем чат-сервере уменьшились по сравнению с Go 1.5 вдвое — до 100 мс. Прогресс!
Сокращение стекаПринятый в Go подход к concurrency подразумевает дешевизну использования большого количества горутин. Если приложение, использующее 10 000 потоков ОС, может работать медленно, для горутин такое количество в порядке вещей. В отличие от традиционных больших стеков фиксированного размера, горутины начинают с очень маленького стека — всего 2 Кб, — который увеличивается по мере необходимости. В начале вызова функции в Go выполняется проверка, достаточно ли размера стека для следующего вызова. И если нет, то перед продолжением вызова стек горутины перемещается в более крупную область памяти, с перезаписью указателей в случае необходимости.
Следовательно, по мере работы приложения стеки горутин увеличиваются, чтобы выполнять самые глубокие вызовы. В задачи сборщика мусора входит возвращение неиспользуемой памяти. За перемещение стеков горутин в более подходящие по размеру области памяти отвечает функция runtime.shrinkstack, которая в Go 1.5 и 1.6 выполняется во время прерывания mark-фазы, когда приложение стоит на паузе.
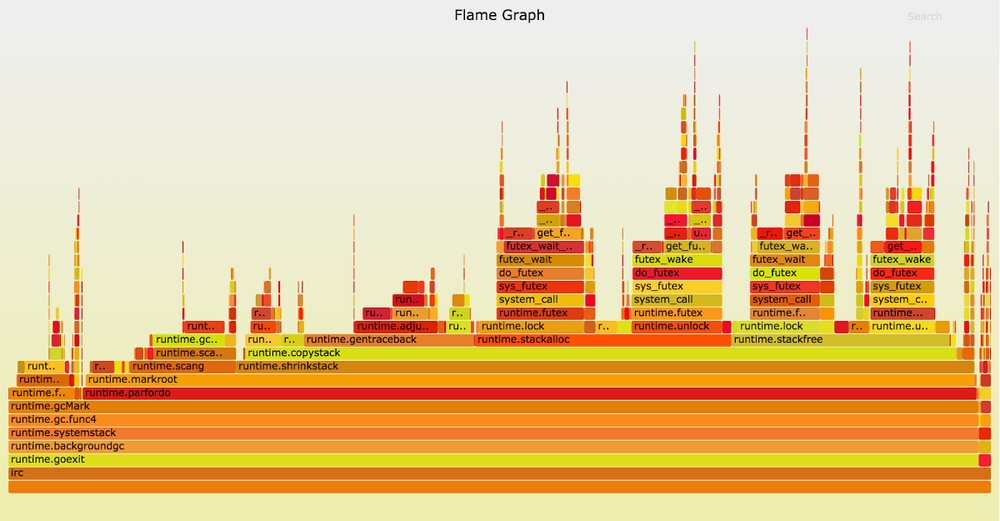
Этот график записан на пререлизной версии 1.6 от октября 2015 года. runtime.shrinkstack занимает примерно три четверти семплов. Если бы эта функция выполнялась во время работы приложения, то мы получили бы серьёзное сокращение пауз на нашем чат-сервере и других подобных приложениях.
Документация по runtime-пакету Go объясняет, как отключить сокращение стеков. Для нашего чат-сервера потеря какой-то части памяти — небольшая плата за уменьшение пауз на сборку мусора. Мы так и сделали, перейдя на Go 1.6. После отключения сокращения стеков продолжительность пауз снизилась до 30—70 мс, в зависимости от «направления ветра».
Структура и схема работы нашего чат-сервера почти не менялись, но от многосекундных пауз в Go 1.2 мы дошли до 200 мс в Go 1.5, а затем до 100 мс в Go 1.6. В конце концов большинство пауз стали короче 70 мс, то есть мы получили улучшение более чем в 30 раз.
Но наверняка должен быть потенциал для дальнейшего совершенствования. Пришло время опять снимать профиль!
Page fault«ы?!До этого момента разброс длительности пауз был невелик. Но теперь они стали меняться в широких пределах (от 30 до 70 мс), не коррелируя с любыми результатами
gctrace. Вот график циклов во время достаточно длинных пауз прерывания mark-фазы: 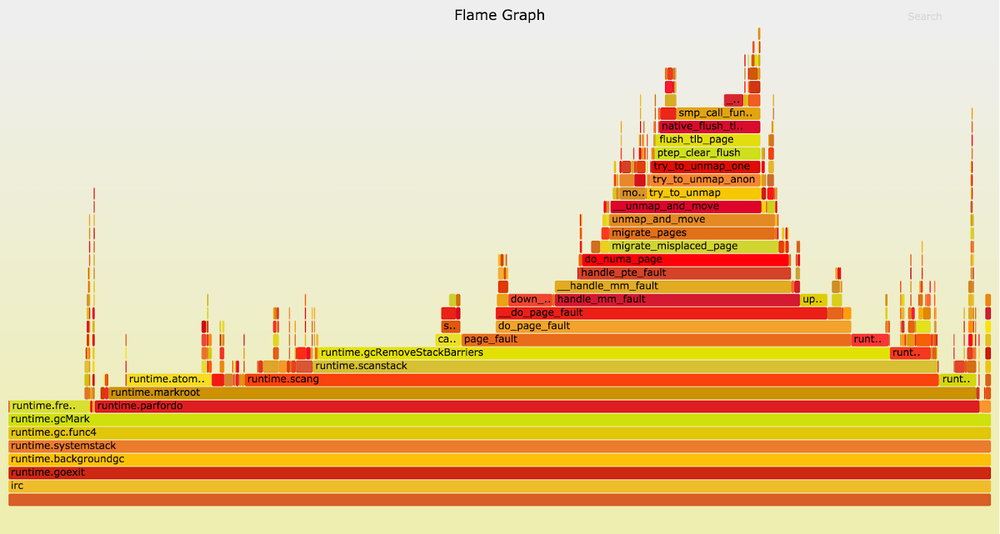
Когда сборщик мусора вызывает runtime.gcRemoveStackBarriers, система генерирует ошибку отсутствия страницы (page fault), что приводит к вызову функции ядра page_fault. Это отражает широкая «башня» справа от центра графика. С помощью page fault«ов ядро распределяет страницы виртуальной памяти (обычно размером по 4 Кб) в памяти физической. Зачастую процессы могут размещать огромные объёмы виртуальной памяти, которая преобразуется в резидентную при обращении приложения только посредством page fault«ов.
Функция runtime.gcRemoveStackBarriers преобразует память стека, к которой недавно обращалось приложение. Фактически она предназначена для удаления «барьеров стека» (stack barriers), добавленных за некоторое время до этого, в начале цикла сборки мусора. Системе доступно достаточно памяти, она не присваивает физическую память каким-то другим, более активным процессам. Так почему же доступ к ней приводит к ошибкам?
Подсказка может скрываться в нашем оборудовании. Для чат-системы мы используем современные двухпроцессорные серверы. К каждому сокету напрямую подключено несколько банков памяти. Такая конфигурация позволяет реализовать неравномерный доступ к памяти (NUMA, Non-Uniform Memory Access). Когда поток (thread) выполняется в ядре сокета 0, то к подключённой к этому сокету памяти у него доступ быстрее, чем к остальной памяти. Ядро Linux старается уменьшить эту разницу, запуская потоки на том ядре, к которому подключена используемая ими память, и перемещая страницы физической памяти «ближе» к соответствующим потокам.
Учитывая эту схему, давайте повнимательнее изучим поведение функции ядра page_fault. Если посмотреть на стек вызова (выше на графике), то увидим, что ядро вызывает do_numa_page and migrate_misplaced_page. Это означает, что ядро перемещает память приложения между банками физической памяти.
Ядро Linux подхватило почти бессмысленные паттерны доступа к памяти во время прерывания mark-фазы и из-за них переносит страницы памяти, что дорого нам обходится. Такое поведение очень слабо проявлялось на графике Go 1.5.1, но, когда мы обратили внимание на runtime.gcRemoveStackBarriers, стало гораздо заметнее.
Здесь наиболее отчётливо проявились преимущества профилирования с помощью perf. Этот инструмент может показать стеки ядра, в то время как профилировщик Go пользовательского уровня показал бы только, что Go-функции выполняются необъяснимо медленно. Perf гораздо сложнее в использовании, он требует root-доступа для просмотра стеков ядра и в Go 1.5 и 1.6 требует использования нестандартного тулчейна (toolchain) (GOEXPERIMENT=framepointer ./make.bash, в Go 1.7 будет стандартным). Но решение описываемых проблем сто̒ит таких усилий.
Управление миграциямиЕсли использование двух сокетов и двух банков памяти вызывает трудности, давайте уменьшим количество. Лучше всего воспользоваться командой
taskset, которая может заставить приложение работать на ядрах только одного сокета. Поскольку программные потоки обращаются к памяти из единственного сокета, ядро переместит их данные в соответствующие банки.
После привязки к единственному узлу NUMA длительность прерывания mark-фазы снизилась до 10—15 мс. Существенное улучшение по сравнению с 200 мс в Go 1.5 или двумя секундами в Go 1.4. Такой же результат можно получить и без того, чтобы пожертвовать половиной сервера. Достаточно с помощью set_mempolicy(2) или mbind(2) назначить процессу политику использования памяти MPOL_BIND. Приведённый профиль был получен на пререлизной версии Go 1.6 в октябре 2015 года. В левой части видно, что выполнение runtime.freeStackSpans занимает немало времени. После того как эта функция была перенесена в параллельно выполняемую фазу сборки мусора, она больше не влияет на длительность паузы. Мало что теперь можно удалить из стадии прерывания mark-фазы!
Вплоть до Go 1.6 мы отключали функцию сокращения стека. Это оказывало минимальное воздействие на использование памяти нашим чат-сервером, но существенно повышало операционную сложность. Для некоторых приложений уменьшение стека играет очень большую роль, поэтому мы отключали эту функцию очень избирательно. В Go 1.7 стек теперь уменьшается прямо во время работы приложения. Так что мы получили всё самое лучшее из двух миров: малое потребление памяти без специальных настроек.
С момента появления параллельно выполняемого сборщика мусора в Go 1.5 runtime отслеживает, выполнялась ли каждая горутина после его последнего сканирования. Во время прерывания mark-фазы снова выявляются горутины, которые недавно выполнялись, и подвергаются сканированию. В Go 1.7 runtime поддерживает отельный короткий список таких горутин. Это позволяет больше не искать по всему списку горутин, когда код ставится на паузу, и сильно сокращает количество обращений к памяти, которые могут запустить миграцию памяти в соответствии с алгоритмами NUMA.
Наконец, компиляторы для архитектуры AMD64 по умолчанию поддерживают указатели фреймов, так что стандартные инструменты отладки и повышения производительности, наподобие perf, могут определять текущий стек вызова функций. Пользователи, создающие свои приложения с помощью подготовленных для их платформы пакетов Go, при необходимости смогут выбрать более продвинутые инструменты без изучения процедуры ребилда тулчейна и ребилда/переразвёртывания своих приложений. Это сулит хорошее будущее с точки зрения дальнейших улучшений производительности основных пакетов и runtime«а Go, когда инженеры вроде меня и вас смогут собирать достаточно информации для качественных репортов.
В пререлизной версии Go 1.7 от июня 2016 года паузы на сборку мусора стали ещё меньше, причём безо всяких дополнительных ухищрений. У нашего сервера они «из коробки» приблизились к 1 мс — в десять раз меньше по сравнению с настроенной конфигурацией Go 1.6!
Наш опыт помог команде разработчиков Go найти постоянное решение проблем, с которыми мы сталкивались. Для приложений, подобных нашему, при переходе с Go 1.5 на 1.6 профилирование и настройка позволили в десять раз уменьшить паузы. Но в Go 1.7 разработчики смогли достичь уже 100-кратной разницы по сравнению с Go 1.5. Снимаем шляпу перед их стараниями улучшить производительность runtime«а.
Что дальшеВесь этот анализ посвящён проклятью нашего чат-сервера — паузам в работе, но это лишь одно измерение производительности сборщика мусора. Решив проблему пауз, разработчики Go теперь могут заняться проблемой пропускной способности.
Согласно описанию транзакционного сборщика (Transaction Oriented Collector), в нём применяется подход прозрачного недорогого выделения и сборки памяти, которая не используется совместно горутинами. Это позволит откладывать потребность в полноценном запуске сборщика и снижает общее количество циклов CPU на сборку мусора.
