[Перевод] Pulsar vs Kafka: сравнение и мифы

Pulsar или Kafka — что лучше? Здесь мы обсудим плюсы и минусы, распространенные мифы и нетехнические критерии, чтобы найти лучший инструмент для ваших задач.
Обычно я рассказываю об Apache Kafka и ее экосистеме. О Pulsar за последние годы меня спрашивали только коммитеры и авторы Pulsar. Они задавали сложные технические вопросы, чтобы показать, что Kafka не идет ни в какое сравнение с Pulsar. На Reddit и подобных платформах разгораются яростные и очень субъективные споры на эту тему. Я поделюсь своей точкой зрения, основанной на многолетнем опыте работы со стриминговыми опенсорс-платформами.
Сравнение технологий нынче в моде: Kafka vs. Middleware, Event Streaming и API Platforms
Цель сравнения технологий — помочь людям подобрать подходящее решение и архитектуру для своих потребностей. Универсального решения не существует. И это не дело вкуса. Просто для каждой задачи есть свой инструмент.
При этом такие сравнения почти всегда субъективны. Даже если автор не работает на вендора и представляется «независимым» консультантом, скорее всего, у него все равно есть любимчики, даже если он сам себе в этом не признается. Однако полезно посмотреть на инструменты с разных точек зрения. Поскольку Apache Pulsar сейчас обсуждают, я решил поделиться своим мнением и сравнить его с Kafka. Я работаю в Confluent, а мы лучшие эксперты по Apache Kafka и ее экосистеме. И все же я постараюсь быть максимально объективным и оперировать голыми фактами.
Опенсорс-фреймворки и коммерческие программы постоянно сравнивают. Я и сам делал такие сравнения в своем блоге и на других платформах, например InfoQ: Сравнение платформ интеграции, Выбор подходящего ESB для ваших потребностей, Kafka vs. ETL / ESB / MQ, Kafka vs. Mainframe и Apache Kafka и API Management / API Gateway. Просто заказчики хотели понять, какой инструмент поможет решить те или иные задачи.
Если говорить о сравнении Pulsar и Kafka, ситуация немного отличается.
Зачем сравнивать Pulsar и Kafka?
Реальные и потенциальные заказчики редко спрашивают о Pulsar. Хотя, если честно, в последние месяцы чуть чаще — где-то на каждой 15-й или 20-й встрече. Потому что фичи и варианты использования у них частично совпадают. Хотя, по-моему, все дело в паре статей о том, что Pulsar якобы в чем-то лучше Kafka. В пользу противоположной точки зрения нет никаких фактов и очень мало материала.
Я не видел ни одной организации, которая бы всерьез задумывалась о Pulsar в продакшене, хотя по всему миру множество пользователей, которым нужна технология распределенной обработки сообщений, вроде Kafka или Pulsar. По-моему, те, кто рекомендует Pulsar, чего-то не договаривают.
Например, их главный пользователь — Tencent, крупная китайская технологическая компания, которая при этом очень активно использует Kafka везде, кроме одного проекта, где пригодился Pulsar. Tencent обрабатывает с Kafka десять триллионов сообщений в день (только представьте: 10 000 000 000 000). Если посчитать, Tencent использует Kafka в тысячу раз активнее, чем Pulsar (10 трлн против десятков млрд). Tencent с удовольствием рассказывают о своем деплое Kafka: Как Tencent PCG использует Apache Kafka для обработки 10+ трлн сообщений в день.
Сравнение двух конкурирующих опенсорс-платформ
Apache Kafka и Apache Pulsar — две замечательные конкурирующие технологии. Логично будет их сравнить.
У Apache Kafka и Apache Pulsar очень схожий набор функций. Советую оценить обе платформы на предмет доступных функций, зрелости, распространения на рынке, опенсорс-инструментов и проектов, обучающего материала, проведения митапов по регионам, видео, статей и так далее. Примеры вариантов использования в вашей отрасли помогут принять правильное решение.
Confluent уже писал сравнение Kafka vs. Pulsar vs. RabbitMQ: производительность, архитектура и функции. Я тоже поучаствовал. Значит, сравнение уже есть…
О чем тогда эта статья?
Я хочу рассмотреть несколько мифов из споров на тему «Kafka против Pulsar», которые регулярно возникают в блогах и на форумах. Затем я сравню их не только по техническим аспектам, потому что обычно никто не говорит о Pulsar с этой стороны.

Kafka vs Pulsar — мифы
Мне попадалось несколько мифов. С некоторыми я согласен, другие можно легко развенчать фактами. Ваше мнение может отличаться от моего, это нормально. Я излагаю исключительно свою точку зрения.
Миф 1. У Pulsar есть характеристики, которых нет у Kafka.
Правда.
Если сравнивать Apache Kafka и Apache Pulsar, можно найти различия в многоуровневой архитектуре, очередях и мультитенантности.
Но!
У Kafka тоже есть уникальные особенности:
- В два раза меньше серверов, которыми приходится управлять.
- Данные сохраняются на диск только один раз.
- Данные кэшируются в памяти только однажды.
- Проверенный протокол репликации.
- Производительность zero-copy.
- Транзакции.
- Встроенная обработка потока.
- Долгосрочное хранилище.
- В разработке: удаление ZooKeeper (KIP-500), чтобы использовать и деплоить Kafka было еще проще, чем Pulsar с его четырехкомпонентной архитектурой (Pulsar, ZooKeeper, BookKeeper и RocksDB), а еще чтобы повысить масштабируемость, устойчивость и т. д.
- В разработке: многоуровневое хранилище (KIP-405), чтобы повысить эластичность и экономичность Kafka.
Спросите себя: можно ли сравнивать опенсорс-платформы или продукты и вендоров с комплексным предложением?
Легко добавлять новые функции, если для них не нужно предоставлять критическую поддержку. Не оценивайте характеристики по списку. Узнайте, насколько они проверены в рабочих сценариях. Сколько из этих «уникальных особенностей» имеют низкое качество и реализованы наспех?
Например. Понадобилось несколько лет, чтобы реализовать и испытать в бою Kafka Streams в качестве нативного движка обработки потоков. Как это можно сравнивать с Pulsar Functions? Последнее позволяет добавлять определяемые пользователем функции (UDF) безо всякой связи с обработкой реальных потоков. Или это скорее похоже на Single Message Transformations (SMT), основную функцию Kafka Connect? Не сравнивайте круглое с квадратным и не забывайте учитывать зрелость. Чем критичнее функция, тем больше зрелости ей требуется.
Сообщество Kafka вкладывает невероятные усилия в работу над основным проектом и его экосистемой. Только в Confluent 200 инженеров занимаются исключительно проектом Kafka, дополнительными компонентами, коммерческими продуктами и предложениями SaaS в основных облачных провайдерах.
Миф 2. У Pulsar есть несколько крупных пользователей, например китайский Tencent.
Правда.
Но! Tencent использует Kafka активнее, чем Pulsar. Отдел выставления счетов, где используется Pulsar, — это лишь малая часть Tencent, в то время как остальные используют Kafka. У них есть глобальная архитектура на основе Kafka, где больше тысячи брокеров сгруппированы в единый логический кластер.
Будьте осторожны с опенсорс-проектами. Проверяйте, какого успеха добились с ними «обычные» компании. Если эту технологию использует один технологический гигант, это еще не значит, что вам она тоже подойдет. Сколько компаний из Fortune 2000 могут похвастаться историями успеха с Pulsar?
Ищите примеры не только среди гигантов!
Примеры обычных компаний позволят лучше понять, как применяется тот или иной инструмент в реальном мире. Если это не истории успеха от самих вендоров. На сайте Kafka можно найти много примеров компаний. Более того, на конференциях Kafka Summit в Сан-Франциско, Нью-Йорке и Лондоне каждый год разные предприятия из разных отраслей делятся своими историями и кейсами. Это компании из Fortune 2000, предприятия среднего бизнеса и стартапы.
Приведу один пример про Kafka. Для репликации данных в реальном времени между отдельными кластерами Kafka существует много разных инструментов, включая MirrorMaker 1 (часть проекта Apache Kafka), MirrorMaker 2 (часть проекта Apache Kafka), Confluent Replicator (от Confluent, доступен только в рамках Confluent Platform и Confluent Cloud), uReplicator (опенсорс от Uber), Mirus (опенсорс от Salesforce), Brooklin (опенсорс от LinkedIn).
На практике разумно использовать только два варианта, если, конечно, вы не хотите обслуживать и улучшать код самостоятельно. Это MirrorMaker 2 (еще не вполне зрелая новинка, но отличный выбор для средне- и долгосрочной перспективы) и Confluent Replicator (проверенный на практике во многих критически важных для бизнеса деплоях, но платный). Остальные варианты тоже нормальные. Но кто обслуживает эти проекты? Кто разбирается с багами и проблемами безопасности? Кому звонить, если в продакшене что-то случилось? Одно дело — деплоить критически важные системы в продакшене, другое — оценивать и пробовать опенсорс-проект.
Миф 3. Pulsar предлагает очереди и стриминг в одном решении.
Частично.
Очереди используются для обмена сообщениями между двумя точками. Они предоставляют асинхронный протокол взаимодействия, то есть отправитель и получатель сообщения не должны обращаться к очереди одновременно.
Pulsar предлагает только ограниченную поддержку очередей сообщений и стриминга событий. В обеих областях он пока не может составить крепкую конкуренцию по двум причинам:
Pulsar предлагает ограниченную поддержку очередей сообщений, потому что ему не хватает таких популярных функций, как XA-транзакции, маршрутизация, фильтрация сообщений и т. д. Это обычные функции в таких системах сообщений, как IBM MQ, RabbitMQ, и ActiveMQ. Адаптеры Pulsar для систем сообщений тоже ограничены в этом смысле. В теории все выглядит нормально, но на практике…
Pulsar предлагает ограниченную поддержку стриминга. Например, на практике в большинстве случаев он не поддерживает семантику строго однократной (exactly-once) доставки и обработки. Вряд ли кто-то станет использовать Pulsar для платежной системы, потому что платежи могут дублироваться и теряться. Ему не хватает функционала для обработки потоков с соединением, агрегированием, окнами, отказоустойчивым управлением состоянием и обработкой на основе времени событий. Топики в Pulsar отличаются от топиков в Kafka в худшую сторону из-за BookKeeper, который был придуман в 2008 году как лог упреждающей записи для HDFS namenode в Hadoop в расчете на краткосрочное хранение.
Примечание. Адаптер Kafka для Pulsar тоже ограничен. В теории звучит заманчиво, но в реальности не все получается, потому что он поддерживает только небольшую часть функционала Kafka.
Как и Pulsar, Kafka предлагает ограниченную поддержку очереди.
В Kafka можно использовать разные обходные пути, чтобы реализовать нормальное поведение очереди. Если вы хотите использовать отдельные очереди вместо общих топиков Kafka для:
- Безопасности => используйте Kafka ACL (и дополнительные инструменты, вроде контроля доступа на основе ролей (RBAC) от Confluent).
- Семантики (отдельных приложений) => используйте группы консюмеров в Kafka.
- Балансировки нагрузки => используйте партиции Kafka.
Обычно я спрашиваю заказчиков, зачем им нужны очереди. Kafka предлагает готовые решения для разных сценариев, на которые можно просто посмотреть с другой стороны. Редко встречаются случаи, когда действительно требуется высокая пропускная способность с очередями.
Зная обходные пути и ограничения Pulsar и Kafka в плане сообщений, давайте проясним: ни одна из платформ не предлагает решение для обмена сообщениями.
Если вам нужно именно оно, возьмите что-то вроде RabbitMQ или NATS.
Однозначного решения здесь нет. Многие наши заказчики заменяют имеющиеся системы сообщений, вроде IBM MQ, на Kafka (из соображений масштабируемости и затрат). Просто нужно знать имеющиеся варианты и их недостатки, все взвесить и подобрать решение, которое лучше всего подходит именно вам.
Миф 4. Pulsar предоставляет потоковую обработку.
Неправда.
Или, если по-честному, все зависит от того, что вы называете обработкой потоков. Это какая-то простейшая функция или прямо полноценная обработка?
Если в двух словах, обработкой потоков я называю непрерывное потребление, обработку и агрегирование событий из разных источников данных. В реальном времени. В любом масштабе. Естественно, с защитой от сбоев, особенно если речь идет о stateful.
Pulsar предлагает минимальную потоковую обработку через Pulsar Functions. Она подходит для простых обратных вызовов, но не сравнится с функционалом Kafka Streams или ksqlDB для создания стриминговых приложений со stateful-информацией, скользящими окнами и другими функциями. Варианты применения можно найти в разных отраслях. Например, на сайте Kafka Streams есть кейсы New York Times, Pinterest, Trivago, Zalando и других.
Для стриминга аналитики Pulsar обычно используется в сочетании с «нормальной» платформой обработки потоков, вроде Apache Spark или Apache Flink, но вам придется управлять дополнительным элементами распределенной архитектуры и разбираться в их сложном взаимодействии.
Миф 5. Pulsar предоставляет семантику exactly-once, как и Kafka.
Неправда.
В Pulsar есть функция дедупликации, чтобы одно сообщение не сохранялось в брокере Pulsar дважды, но ничто не мешает консюмеру прочитать это сообщение несколько раз. Этого недостаточно для любого применения обработки потоков, где для входа и выхода используется Pulsar.
В отличие от функции транзакций в Kafka, здесь нельзя привязывать отправленные сообщения к состоянию, записанному в обработчике потоков.
Семантика Exactly-Once Semantics (EOS) доступна с версии Kafka 0.11, которая вышла три года назад, и используется во многих продакшен-деплоях. Kafka EOS поддерживает всю экосистему Kafka, включая Kafka Connect, Kafka Streams, ksqlDB и такие клиенты, как Java, C, C++, Go и Python. На конференции Kafka Summit было несколько выступлений, посвященных функционалу Kafka EOS, включая это превосходное и понятное введение со слайдами и видео.
Миф 6. У Pulsar производительность выше, чем у Kafka.
Неправда.
Я не поклонник разных бенчмарков производительности и пропускной способности. Обычно они субъективны и относятся к конкретной задаче независимо от того, кто их проводит — вендор, независимый консультант или исследователь.
Например, GIGAOM опубликовали один бенчмарк, где сравнивается задержка и производительность в Kafka и Pulsar. Автор намеренно замедлил Kafka, настроив параметр flush.messages = 1, в результате которого каждый запрос вызывает fsync и Kafka синхронизируется с диском при каждом сообщении. В этом же бенчмарке консюмер Kafka отправляет подтверждение синхронно, а консюмер Pulsar — асинхронно. Неудивительно, что Pulsar вышел явным «победителем». Правда, автор забыл упомянуть или объяснить существенные отличия в конфигурации и измерениях. Давайте не будем путать теплое с мягким.
На самом деле архитектура Pulsar сильнее нагружает сеть (из-за брокера, который выступает как прокси перед серверами bookie BookKeeper) и требует в два раза больше пропускной способности (потому что BookKeeper записывает данные в лог упреждающей записи и в главный сегмент).
Confluent тоже делал бенчмарки. Только там сравнивалось сопоставимое. Неудивительно, что результаты получились другими. Но нужно ли вообще встревать в эти бои на бенчмарках между вендорами?
Оцените свои требования к производительности. Сделайте proof-of-concept с Kafka и Pulsar, если надо. Скорее всего, в 99% случаев обе платформы покажут приемлемую производительность для вашего сценария. Не доверяйте посторонним субъективным бенчмаркам! Ваш случай все равно уникален, и производительность — это только один из аспектов.
Миф 7. Pulsar проще в использовании, чем Kafka.
Неправда.
Без дополнительных инструментов вам будет сложно и с Kafka, и с Pulsar.
У Kafka две распределенных системы: сама Kafka и Apache ZooKeeper.
Но! У Pulsar три распределенных системы, а еще хранилище: Pulsar, ZooKeeper и Apache BookKeeper. Как и Pulsar, BookKeeper использует ZooKeeper. Для некоторых задач хранения используется RocksDB. Это означает, что Pulsar гораздо сложнее понять и настроить по сравнению с Kafka. Кроме того, у Pulsar больше параметров конфигурации, чем у Kafka.
Kafka движется в противоположном направлении — скоро ZooKeeper будет удален (см. KIP-500), так что останется всего одна распределенная система, которую нужно деплоить, обслуживать, масштабировать и мониторить:
ZooKeeper мешает масштабированию в Kafka и усложняет эксплуатацию. Но у Pulsar все еще хуже!
Одна из главных проблем моих заказчиков — использование ZooKeeper в критически важных деплоях в большом масштабе. С нетерпением жду упрощения архитектуры Kafka, чтобы остались только брокеры. Кроме того, мы получим единую модель безопасности, потому что больше не придется отдельно настраивать безопасность для ZooKeeper. Это огромное преимущество, особенно для крупных организаций и отраслей со строгим регулированием. Ребята из комплаенса и ИБ скажут вам спасибо за упрощенную архитектуру.
Использование платформы связано НЕ только с архитектурой
У Kafka гораздо более подробная документация, огромное сообщество экспертов и большой набор поддерживающих инструментов, которые упрощают работу.
Кроме того, по Kafka есть много вариантов обучения — онлайн-курсы, книги, митапы и конференции. К сожалению, у Pulsar с этим все плохо.
Миф 8. Архитектура с тремя уровнями лучше, чем с двумя.
Зависит от ситуации.
Лично я скептически отношусь к тому, что трехуровневую архитектуру Pulsar (брокеры Pulsar, ZooKeeper и BookKeeper) можно считать преимуществом для большинства проектов. Тут есть издержки.
Twitter рассказал, как отказался от BookKeeper + DistributedLog (DistributedLog похож на Pulsar по архитектуре и дизайну) около года назад, соблазнившись такими преимуществами одноуровневой архитектуры Kafka, как экономичность и улучшенная производительность, которых недоставало двухуровневой архитектуре с отдельным хранилищем.
Как и Pulsar, DistributedLog построен на BookKeeper и добавляет стриминговый функционал, схожий с Pulsar (например, уровень обработки существует отдельно от уровня хранилища). Изначально DistributedLog был отдельным проектом, но потом присоединился к BookKeeper, хотя сегодня им, похоже, мало кто занимается (всего пара коммитов за последний год). Среди основных причин перехода Twitter на Kafka называлась значительная экономия и повышение производительности, а также обширное сообщество и популярность Kafka. Вот какие выводы они сделали: «Для одного консюмера экономия ресурсов составила 68%, а для нескольких — целых 75%».
Преимущества трехуровневой архитектуры проявляются при создании масштабируемой инфраструктуры. При этом дополнительный уровень увеличивает нагрузку на сеть минимум на 33%, а данные, которые хранятся в брокерах Pulsar, приходится дополнительно кэшировать на обоих уровнях, чтобы добиться аналогичной производительности, а еще дважды записывать на диск, потому что формат хранения в Bookkeeper основан не на логе.
В облаке, где работает большинство деплоев Kafka, лучшим внешним хранилищем выступает не такая узкоспециализированная технология, как BookKeeper, а популярное и проверенное хранилище объектов, вроде AWS S3 и GCP GCS.
Tiered Storage в Confluent Platform на основе AWS S3, GCP GCS и им подобных, дает те же преимущества без дополнительного слоя BookKeeper, как у Pulsar, и без дополнительных затрат и задержек, связанных с передачей данных по сети. У Confluent ушло два года на то, чтобы выпустить GA-версию Tiered Storage for Kafka с круглосуточной поддержкой для самых критичных данных. Tiered Storage пока недоступно для опенсорсной версии Apache Kafka, но Confluent вместе с сообществом Kafka (включая крупные технологические компании, вроде Uber) работает над KIP-405, чтобы добавить Tiered Storage в Kafka с разными вариантами хранения.
У обеих архитектур есть плюсы и минусы. Лично мне кажется, что 95% проектов не нуждаются в сложной трехуровневой архитектуре. Она может пригодиться там, где требуется внешнее недорогое хранилище, но вам придется отвечать за круглосуточное соблюдение SLA, масштабируемость и пропускную способность. А еще за безопасность, управление, поддержку и интеграцию в вашу экосистему. Если вам действительно нужна трехуровневая архитектура, не стану вас останавливать.
Связанный миф: Pulsar лучше подходит для отстающих консюмеров благодаря уровню кэширования и хранения.
Неправда.
Основная проблема отстающих консюмеров в том, что они занимают page cache, то есть последние сообщения уже кэшированы. При чтении из предыдущих сегментов они заменяются, что снижает производительность консюмеров, читающих с начала лога.
Архитектура Pulsar проявляет себя даже хуже в этом отношении. Проблема сброса кэша сохраняется, при этом для чтения нужно сделать лишний прыжок по сети и загрузить сеть вместо того, чтобы просто прочитать сообщение с локального носителя.
Миф 9. Kafka масштабируется хуже, чем Pulsar.
Неправда.
Это один из главных аргументов сообщества Pulsar. Как я уже говорил, это всегда зависит от выбранного бенчмарка. Например, я видел тесты с эквивалентными вычислительными ресурсами, где на высокой пропускной способности у Kafka результат был гораздо лучше, чем у Pulsar. Вот один из таких бенчмарков:
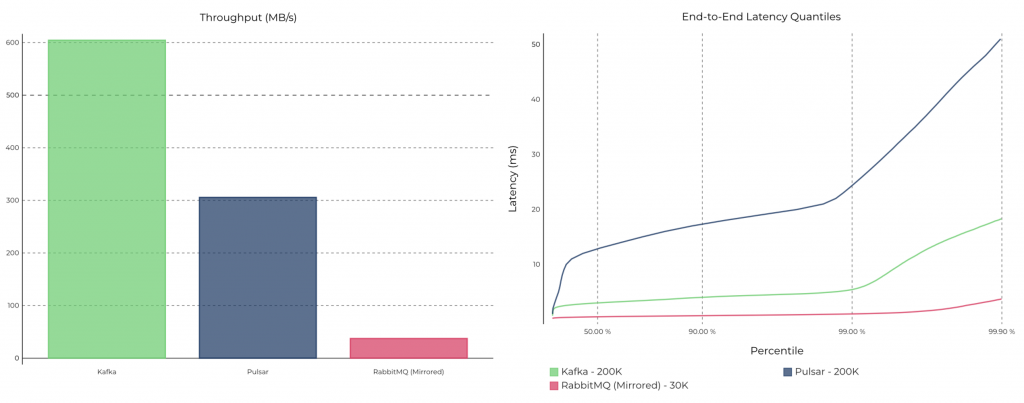
В большинстве случаев масштабируемость не проблема. Kafka можно легко разогнать до нескольких гигабайтов в секунду, как в демонстрации «Масштабирование Apache Kafka до 10+ ГБ в секунду в Confluent Cloud»:

Честно говоря, этот вопрос должен волновать менее 1% пользователей. Если у вас требования, как у Netflix (петабайты в день) или LinkedIn (триллионы сообщений), есть смысл обсуждать самую подходящую архитектуру, железо и конфигурацию. Остальным можно не беспокоиться.
Связанный миф: сейчас в Kafka может храниться всего 500к партиций на кластер.
Правда.
Пока у Kafka не лучшая архитектура для масштабных деплоев с сотнями тысяч топиков и партиций.
Но! Pulsar тоже не резиновый. Просто у него другие лимиты.
Ограничения в Kafka связаны с Zookeeper. Когда Zookeeper удалят через KIP-500, верхняя граница уйдет вместе с ним.
Примечание: успех зависит от подходящего устройства архитектуры!
Если у заказчика возникли проблемы с количеством партиций и масштабируемостью в Kafka, скорее всего, он ошибся в архитектуре и приложениях (Pulsar бы тут точно не помог).
Kafka — это платформа стриминга, а не очередной IBM MQ. Если вы попробуете воссоздать любимое решение и архитектуру MQ с Kafka, у вас вряд ли что-то получится. У меня было несколько заказчиков, которые потерпели крах, но смогли привести все в порядок с нашей помощью.
Скорее всего, у вас не возникнет проблем с количеством партиций и масштабируемостью, даже пока Kafka еще использует ZooKeeper, если вы правильно все спроектируете и разберетесь в базовых принципах Kafka. Такие проблемы часто возникают с любой технологией, вроде Kafka, которая вводит совершенно новый уровень и парадигму (например, при первом появлении облаков немало компаний набили себе шишки при попытке их освоить).
Связанный миф: Pulsar поддерживает практически неограниченное число партиций.
Неправда.
У BookKeeper существуют те же ограничения по одному файлу на ledger, что и у Kafka, но в одной партиции таких ledger несколько. Брокеры Pulsar объединяют партиции в группы, но на уровне хранения, в Bookkeeper, данные хранятся в сегментах, и на каждую партицию приходится много сегментов.
В Kafka метаданные для этих сегментов хранятся в Zookeeper, откуда и возникают эти ограничения по числу. Когда Kafka избавится от этой зависимости, границы возможного раздвинутся. С нетерпением жду реализации KIP-500. Подробности читайте в статье Apache Kafka справится сама: удаление зависимости от Apache ZooKeeper.
Связанный миф: потребности масштабирования в Kafka необходимо определять при создании топика.
Отчасти это правда.
Если требуется очень большой масштаб, в топиках Kafka можно сразу создать больше партиций, чем обычно требуется для этой задачи. (См. Потоки и таблицы в Apache Kafka: топики, партиции и хранение.) Или можно добавить партиции позже. Это не идеальное решение, но так уж устроены распределенные системы стриминга (которые, кстати, масштабируются лучше, чем традиционные системы обработки сообщений, вроде IBM MQ).
Оптимальные методы создания топиков и изменения их конфигурации уже тщательно продуманы за вас, так что не волнуйтесь.
Но! У топиков Pulsar есть то же ограничение!
Пропускная способность для записи зависит от числа партиций, назначенных топику Pulsar, точно так же, как это происходит в топике Kafka, поэтому там тоже придется создавать партиции с запасом. Дело в том, что в каждой партиции записывать можно только в один ledger за раз (а их может быть несколько). Увеличение числа партиций динамически влияет на порядок сообщений, как и в Kafka (порядок нарушается).
У Kafka и Pulsar с масштабированием все отлично. Этого будет более чем достаточно почти в любом сценарии.
Если вам нужен совсем заоблачный масштаб, лучше взять реализацию без ZooKeeper. Так что KIP-500 — это самое ожидаемое изменение в Kafka, судя по сообществу и заказчикам Confluent.
Миф 10. В случае аппаратного сбоя Pulsar восстанавливается моментально, а Kafka приходится перегружать данные.
И да, и нет.
Если брокер Pulsar вырубится, ничего не страшного не будет, это правда, но, в отличие от брокера Kafka, он и не хранит данные, а просто выступает в качестве прокси для уровня хранения, то есть BookKeeper. Так что подобные заявления о Pulsar — это просто маркетинговый ход. Почему никто не говорит, что бывает, если полетит нода BookKeeper (bookie)?
Если завершить и перезапустить BookKeeper bookie, данные будут точно так же перераспределяться, как и в Kafka. В этом суть распределенных систем с их репликацией и партициями.
Kafka уже предлагает эластичность.
Это важно. Основатель Confluent, Джей Крепс (Jay Kreps) недавно писал об этом: Эластичные кластеры Apache Kafka в Confluent Cloud. В облачном сервисе SaaS, вроде Confluent Cloud, конечный пользователь не думает об аппаратных сбоях. Он ожидает непрерывный аптайм и SLA на уровне 99, xx. С оплатой за потребление пользователь не заботится об управлении брокерами, изменении размеров нод, увеличении или уменьшении кластеров и подобных деталях.
Самоуправляемым кластерам Kafka нужны такие же возможности. Tiered Storage for Kafka — это огромное хранилище, с которым данные не хранятся на брокере и восстановление после сбоев происходит почти моментально. Если добавить сюда такие инструменты, как Self-Balancing Kafka (эта фича от Confluent описана в статье по ссылке выше), можно вообще забыть об эластичности в самоуправляемых кластерах.
К сожалению, в Pulsar вы ничего подобного не найдете.
Миф 11. Pulsar справляется с репликацией между кластерами лучше, чем Kafka.
Неправда.
Любая распределенная система должна решать такие проблемы, как CAP-теорема и кворум в распределенных вычислениях. Кворум — это минимальное число голосов, которое распределенная транзакция должна получить, чтобы выполнить операцию в распределенной системе. Такой подход позволяет обеспечить согласованность операций.
Задачи по кворуму Kafka поручает ZooKeeper. Даже после реализации KIP-500 и удаления ZooKeeper законы физики не перестанут действовать: проблемы задержки в распределенных системах существуют в таких регионах, как Восточная, Центральная и Западная часть США и даже по всему миру. Скорость света, конечно, впечатляет, но все же имеет ограничения.
Эту проблему можно обойти разными способами, включая использование инструментов репликации в реальном времени, например MirrorMaker 2 в Apache Kafka, Confluent Replicator или Confluent Multi-Region-Clusters. Эти варианты и советы см. в статье Архитектурные шаблоны для распределенных, гибридных, периферийных и глобальных деплоев Apache Kafka.
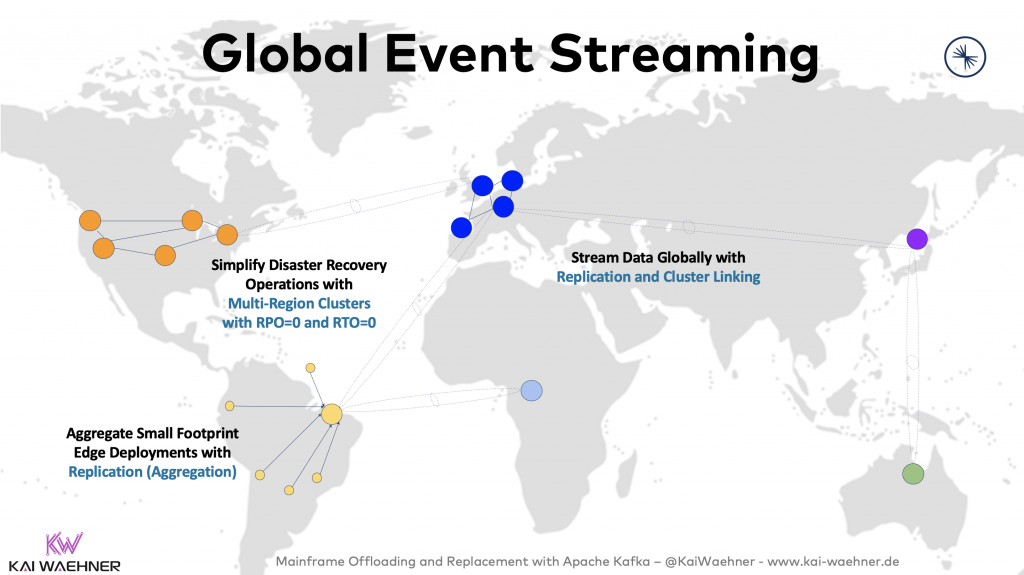
Вы не найдете универсальное решение, которое обеспечит глобальную репликацию + нулевой простой + нулевую потерю данных. Для самых критически важных приложений Confluent Multi-Region-Clusters предлагает RTO=0 и RPO=0 (нулевой простой и нулевую потерю данных) с автоматическим аварийным восстановлением и отработкой отказа, даже если упадет целый датацентр или облачный регион.
Для таких случаев архитектура Pulsar будет еще сложнее, чем ее базовая версия. Просто для георепликации Pulsar требует дополнительный глобальный кластер Zookeeper, а для больших расстояний это не годится. Обходной путь есть, но от CAP-теоремы и законов физики не уйдешь.
Что с Kafka, что с Pulsar вам нужна проверенная архитектура для борьбы с физикой в глобальных деплоях.
Миф 12. Pulsar совместим с интерфейсом и API Kafka.
Отчасти.
Pulsar предлагает простейшую реализацию с зачаточной совместимостью с протоколом Kafka v2.0.
У Pulsar есть конвертер для базовых элементов протокола Kafka.
В теории совместимость с Kafka выглядит убедительно, но вряд ли это серьезный аргумент для переноса действующей инфраструктуры Kafka в Pulsar. Зачем такой риск?
Мы слышали заявления о совместимости с Kafka и в других примерах, например для гораздо более зрелого сервиса Azure Event Hubs. Почитайте об ограничивающих факторах их Kafka API. Вы удивитесь. Никакой поддержки основных функций Kafka, вроде транзакций (и семантики exactly-once), сжатия или compaction для логов.
Раз, по сути, это не Kafka, существующие приложения Kafka будут вести себя непредсказуемо в таких вот «совместимых» системах, будь то Azure Event Hubs, Pulsar или другая оболочка.
Kafka vs. Pulsar — комплексное сравнение
Выше мы говорили о мифах, которые гуляют по разным статьям и постам. С ними, вроде, все понятно.
Но я обещал, что мы поговорим не только о технических деталях. При выборе технологии важны и другие аспекты.
Рассмотрим три из них: доля на рынке, корпоративная поддержка и облачные предложения.
Доля на рынке у Apache Kafka и Apache Pulsar
Статистика в Google Trends за последние пять лет совпадает с моими личными наблюдениями — интерес к Apache Kafka гораздо выше, чем к Apache Pulsar:
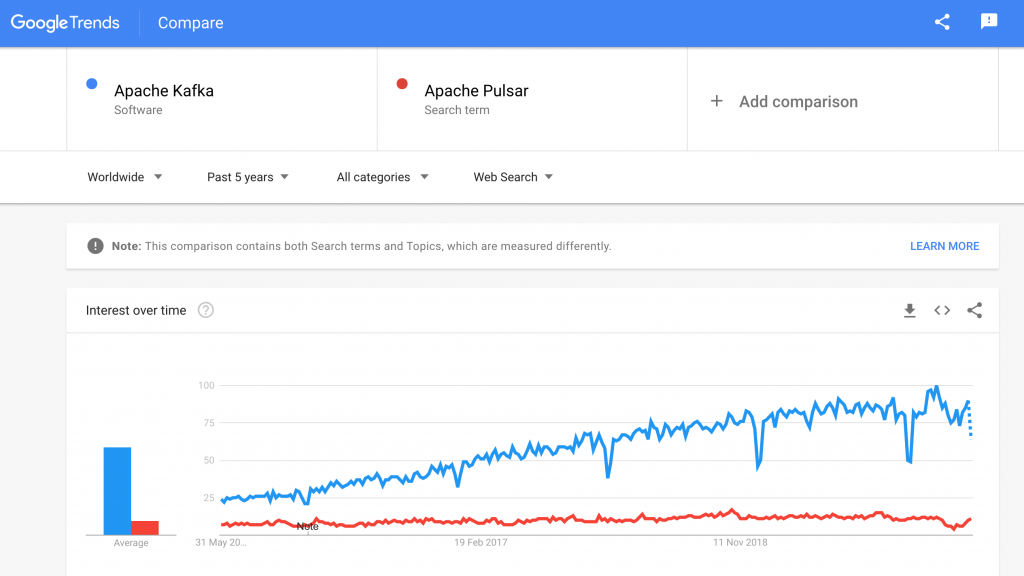
Примерно так же выглядит картинка сравнения на Stack Overflow и аналогичных платформах, по числу и размеру поддерживающих вендоров, открытой экосистеме (интеграция инструментов, обертки, вроде Spring Kafka) и подобным характеристикам.
Открытые вакансии — еще один индикатор распространения технологии. Для Pulsar их мало, то есть его использует не так много компаний. Убедитесь сами — поищите на любом сайте. Если искать по всему миру, для Pulsar вакансий меньше сотни, а для Kafka — тысячи. Кроме того, в большинстве вакансий для Pulsar указано, что требуется опыт с Kafka, Pulsar, Kinesis и аналогичными технологиями.
В большинстве случаев такие характеристики важнее для успешного проекта, чем технические детали. В конце концов ваша цель — решить определенную бизнес-задачу, правда же?
Раз Pulsar так мало распространен, почему о нем вообще говорят? Во-первых, потому, что независимые консультанты, аналитики и блоггеры (включая меня) должны рассказывать о новых современных технологиях, чтобы привлечь аудиторию. Если честно, люди любят об этом читать.
Корпоративная поддержка для Kafka и Pulsar
Корпоративная поддержка для Kafka и Pulsar существует.
Но все не совсем так, как можно ожидать. Вот несколько вендоров, к которым вы можете обратиться, если решили работать с Pulsar:
- Streamlio (теперь принадлежит Splunk) — компания, которая раньше стояла за Apache Pulsar. Splunk пока не объявили о своей будущей стратегии для поддержки пользователей, которые работают над проектами на основе Pulsar. Splunk славится своими популярными аналитическими платформами. Это их основной бизнес (1,8 млрд долларов в 2019 году). Единственное, на что жалуются пользователи, — ценник. Splunk активно используют Kafka, а сейчас интегрируют Pulsar в Splunk Data Stream Processor (DSP). Сильно сомневаюсь, что Splunk вдруг увлечется опенсорсом, чтобы поддержать ваш драгоценный проект на базе Pulsar (возможно, чего-то можно ожидать от DSP). Будущее покажет.
- StreamNative основана одним из изначальных разработчиков Apache Pulsar и поддерживает платформу стриминга на основе Pulsar. На июнь 2020 года у StreamNative было 13 (целых 13, да!) сотрудников в LinkedIn. Уж не знаю, хватит этого для поддержки вашего критически важного проекта или нет.
- TIBCO объявили о поддержке Pulsar в декабре 2019 года. За последние годы стратегия у них сместилась с интеграции на аналитику. Пользователи их промежуточного ПО уходят от TIBCO толпами. В отчаянии они приняли стратегическое решение: поддерживать другие платформы, даже если у них нет никакого опыта и никакой связи с ними. Да, звучит как миф, но TIBCO делают то же самое для Kafka. Любопытный факт: TIBCO предлагает Kafka и ZooKeeper в Windows! Такого больше никто не делает. Все знают, это приводит к нестабильности и несогласованности. Но если что, TIBCO помогут вам с Kafka и Pulsar. Зачем вообще сравнивать эти платформы, если можно получить обе у одного вендора, причем даже на Windows, с .exe и bat-скриптами для запуска серверных компонентов:
Вендоров для Kafka больше с каждым днем.
Это очень распространенная на рынке платформа. Лучшее подтверждение — поддержка от крупнейших вендоров. IBM, Oracle, Amazon, Microsoft и многие другие поддерживают Kafka и встраивают возможности интеграции с ней в свои продукты.
Окончательное подтверждение этому я получил на конференции Oracle OpenWorld 2019 в Сан-Франциско, где выступал менеджер по GoldenGate (вел
