[Перевод] Проверки работоспособности и постепенная деградация распределенных систем

Как всегда, спасибо Фреду Хеберту и Саргуну Дхиллону за то, что прочли черновик этой статьи и предложили нескольких бесценных советов.
В своем докладе о скорости Тамар Берковичи из Box подчеркнула важность проверок работоспособности при автоматическом аварийном переключении баз данных. В частности, она отметила, что мониторинг времени выполнения сквозных запросов, как метод определения работоспособности базы данных, — лучше, чем простое эхо-тестирование (пингирование).
… перебрасывая трафик на другую ноду (реплику), чтобы устранить бездействие, надо построить средства защиты от дребезга и других пограничных ситуаций. Это не сложно. Фокус при организации эффективной работы в том, чтобы знать, когда перевести базу данных в первую позицию, т.е. надо быть в состоянии правильно оценить работоспособность базы данных. Сейчас многие параметры, на которые мы привыкли обращать внимание, — например, загрузка процессора, время ожидания блокировки, частота ошибок, — являются вторичными сигналами. Ни один из этих параметров на самом деле не говорит о способности базы данных к обработке клиентского трафика. Поэтому, если используете их для принятия решения о переключении, можете получить как ложноположительные, так и ложноотрицательные результаты. Наше устройство проверки работоспособности фактически выполняет простые запросы к узлам базы данных и использует данные о выполненных и невыполненных запросах для более точной оценки работоспособности базы данных.
Я обсудила это с другом, и он предположил, что проверки работоспособности должны быть предельно простыми, и что реальный трафик — это лучший критерий для оценки работоспособности процесса.
Нередко обсуждения, связанные с реализацией проверки работоспособности, вращаются вокруг двух противоположных вариантов: простые проверки связи/сигнала или комплексные сквозные тесты. В этой статье я хочу подчеркнуть проблему, связанную с использованием вышеупомянутой формы проверки работоспособности для определенных типов решений по балансировке нагрузки, — равно как и необходимость более детального подхода к оценке работоспособности процесса.
Два типа проверок работоспособности
Проверки работоспособности, даже во многих современных системах, как правило, делятся две категории: проверки на уровне узла и на уровне службы.
Например, Kubernetes реализует проверку путем анализа готовности и живучести. Проверка готовности используется, чтобы определить способность пода обслуживать трафик. Если проверка готовности не выполнена, удаляется под из оконечных точек, составляющих службу, и из-за этого в поде, пока проверка не будет выполнена, никакой трафик не маршрутизируется. С другой стороны, проверка живучести используется, чтобы определить реакцию службы на зависание или блокировку. Если не выполняется она, идет перезапуск индивидуального контейнера в kubelet. Аналогичным образом Consul допускает несколько форм проверок (checks): на основе script, проверки на основе HTTP, направленные на конкретный URL, проверки на основе TTL или даже проверки псевдонимов.
Наиболее распространенный метод реализации проверки работоспособности на уровне службы — это определение оконечной точки проверки работоспособности. Например, в gRPC проверка работоспособности сама по себе становится вызовом RPC. gRPC также допускает проверки работоспособности на уровне службы и общие проверки работоспособности сервера gRPC.
В прошлом проверки работоспособности на уровне узла использовались в качестве сигнала для запуска оповещения. Например, оповещение при средней загрузке процессора (в настоящее время по праву считается антишаблоном проектирования). Даже если проверка работоспособности не используется непосредственно для оповещения, она по-прежнему служит основой для принятия ряда других автоматических инфраструктурных решений, например, относительно балансировки нагрузки и (иногда) обрыва цепи. В схемах данных сервисной сетки, например, Envoy, данные проверки работоспособности, когда дело касается определения маршрутизации трафика к экземпляру, идут вперед относительно данных обнаружения служб.
Работоспособность — это спектр, а не бинарная таксономия
Эхо-запрос, или пинг, может только установить, работает ли служба, тогда как сквозные тесты — это прокси для установления того факта, способна ли система выполнить определенную единицу работы, где единицей работы может быть запрос к базе данных или определенное вычисление. Независимо от формы проверки работоспособности ее результат рассматривается как сугубо бинарный: «пройдена» или «не пройдена».
В современных динамичных и зачастую «автоматически масштабируемых» вариантах инфраструктуры один процесс, который просто «работает», не имеет значения, если не может выполнить конкретную единицу работы. Получается, что упрощенные проверки, например, эхо-тестирование, почти бесполезны.
Определить, когда служба полностью отключена, легко, а вот установить степень работоспособности работающей службы куда сложнее. Вполне возможно, процесс работает (т.е. проверку работоспособности проходит), и осуществляется маршрутизация трафика, но для выполнения определенной единицы работы, допустим, в течение периода задержки службы p99, этого мало.
Часто работу невозможно закончить из-за того, что процесс перегружен. В службах с высоким уровнем конкуренции «перегрузка» аккуратно сопоставляется с количеством параллельных запросов, обрабатываемых только одним процессом с избыточной очередизацией, который может привести к увеличению задержки для вызова RPC (хотя чаще всего служба нижнего уровня просто ставит запрос в режим ожидания и повторяет попытку по истечении заданного времени ожидания). В особенности это верно в том случае, если конечная точка проверки работоспособности настроена на автоматический возврат к коду состояния HTTP 200, в то время как реальная операция, выполняемая службой, предполагает сетевой ввод-вывод или вычисление.

Работоспособность процесса — это спектр. В первую очередь нас интересует качество обслуживания, например, время, необходимое процессу, чтобы восстановить результат конкретной единицы работы, и точность результата.
Вполне возможно, что процесс колеблется между различными степенями работоспособности в течение своего срока службы: от полной работоспособности (например, способность функционировать на ожидаемом уровне параллелизма) до грани неработоспособности (когда очереди начинают заполняться) и точки, где процесс полностью переходит в неработоспособную зону (ощущается снижение качества обслуживания). Только самые тривиальные службы можно построить на предположении об отсутствии некоторой степени частичного отказа в любой период, где частичный отказ подразумевает, что некоторые функции работают, а другие отключаются, а не только «некоторые запросы выполняются, некоторые не выполняются». Если архитектура службы не позволяет корректно исправить частичный отказ, то задача по исправлению ошибок автоматически ложится на клиента.
Адаптивная, самовосстанавливающаяся инфраструктура должна строиться с пониманием того факта, что такие колебания совершенно нормальны. Также важно помнить, что это различие имеет значение только в отношении балансировки нагрузки — оркестратору, например, нет смысла перезапускать процесс только потому, что тот на пороге перегрузки.
Иными словами, для уровня оркестрации вполне разумно рассматривать работоспособность процесса как двоичное состояние и перезапускать процесс только после сбоя или зависания. А вот в слое балансировки нагрузки (будь то внешний прокси, например, Envoy, или внутренняя библиотека со стороны клиента) чрезвычайно важно то, что он действует на основании более детальных сведений о работоспособности процесса — когда принимает соответствующие решения о разрыве цепи и сбросе нагрузки. Постепенная деградация службы невозможна, если невозможно точно определить уровень работоспособности службы в любой момент времени.
Скажу по опыту: неограниченный параллелизм — это зачастую основной фактор, ведущий к деградации службы или постоянному снижению производительности. Балансировка нагрузки (и, как следствие, сброс нагрузки) часто сводится к эффективному управлению параллелизмом и применению противодавления, не давая системе перегрузиться.
Необходимость обратной связи при применении противодавления
Мэтт Ранни написал феноменальную статью о неограниченном параллелизме и необходимости противодавления в Node.js. Статья любопытна целиком, но главный вывод (по крайней мере для меня) заключался в необходимости обратной связи между процессом и его выходным блоком (обычно это балансировщик нагрузки, но иногда — и другая служба).
Хитрость в том, что когда ресурсы исчерпаны, что-то где-то должно отдаваться. Спрос растет, а производительность волшебным образом увеличиться не может. Для ограничения входящих задач первым делом неплохо будет установить некое ограничение скорости на уровне сайта, по IP-адресу, пользователю, сеансу или, в лучшем случае, по некому важному для приложения элементу. Многие балансировщики нагрузки могут ограничить скорость способом посложнее, чем ограничение входящего сервера Node.js, но обычно не замечают проблем, пока процесс не оказывается в трудном положении.
Ограничение скорости и обрыв цепи на основе статических порогов и пределов могут оказаться ненадежными и нестабильными с точки зрения как корректности, так и масштабируемости. Некоторые балансировщики нагрузки (в частности, HAProxy) предоставляют множество статистических данных о длине внутренних очередей для каждого сервера и серверной части. Кроме того, HAProxy допускает выполнение проверки агента (agent-check) (вспомогательной проверки, независимой от обычной проверки работоспособности), что позволяет процессу предоставлять прокси-серверу более точную и динамическую обратную связь о работоспособности. Ссылка на документы:
Проверка работоспособности агента выполняется путем TCP-подключения к порту на основе заданного параметра
agent-portи считывания строки ASCII. Строка состоит из ряда слов, разделенных пробелами, знаками табуляции или запятыми в любом порядке, необязательно заканчивающегося на/rи/или/nи включающего следующие элементы:— Представление положительного целого процентного значения ASCII, например,
75%. Значения в этом формате определяют вес пропорционально начальному
весовому значению сервера, настроенному при запуске HAProxy. Обратите внимание, что нулевое весовое значение указывается на странице статистики какDRAINс момента аналогичного воздействия на сервер (оно удаляется из фермы LB).— Параметр строки
maxconn: за ним следует целое число (без пробела). Значения в
этом формате определяют параметр сервераmaxconn. Максимальное число
заявленных соединений необходимо умножить на число балансировщиков нагрузки и различных серверных частей, использующих эту проверку работоспособности, для получения общего числа соединений, которые может установить сервер. Например:maxconn:30— Слово
ready. Это переводит административное состояние сервера в
режимREADY, отменяя состояниеDRAINилиMAINT.— Слово
drain. Это переводит административное состояние сервера в
режимDRAIN(«сток»), после чего сервер не будет принимать новые соединения, за исключением соединений, которые принимаются через базу данных.— Слово
maint. Это переводит административное состояние сервера в
режимMAINT(«обслуживание»), после чего сервер не будет принимать никакие новые соединения, и проверки работоспособности останавливаются.— Слова
down,failedилиstopped, за которыми может следовать строка описания после символа диез (#). Все они указывают на рабочее состояние сервераDOWN(«выкл»), но, поскольку само слово отображается на странице статистики, разница позволяет администратору определить, была ли ситуация ожидаемой: служба может быть намеренно остановлена, может появиться, но не пройти некоторые тесты подтверждения, или рассматриваться как отключенная (отсутствует процесс, нет ответа от порта).— Слово up указывает на рабочее состояние сервера
UP(«вкл»), если проверки работоспособности также подтверждают доступность службы.Параметры, не заявленные агентом, не изменяются. Например, агент может быть рассчитан только на мониторинг использования процессора и сообщать только относительное весовое значение, не взаимодействуя с рабочим состоянием. Аналогичным образом программу-агент можно спроектировать как интерфейс конечного пользователя с 3 переключателями, позволяющими администратору изменять только административное состояние.
Тем не менее, надо учитывать, что только агент может отменить свои собственные действия, поэтому, если сервер установлен в режим DRAIN или в состояние DOWN с помощью агента, то для повторного запуска службы другие эквивалентные действия выполнять должен агент.
Сбой соединения с агентом не рассматривается как ошибка, поскольку возможность соединения тестируется путем регулярного проведения проверки работоспособности, которая запускается с помощью параметра check. Однако, если пришло сообщение об отключении, то для остановки агента предупреждение — не лучшая идея, поскольку только агент, сообщающий о включении, может повторно включить сервер.
Такая схема динамической связи службы с выходным блоком крайне важна для создания самоадаптирующейся инфраструктуры. Примером может быть архитектура, с которой я работала на предыдущей работе.
Раньше я работала в imgix, стартап-компании по обработке изображений в реальном времени. С помощью простого URL API изображения извлекаются и преобразуются в режиме реального времени и затем используются в любой точке мира через CDN. Наш стек был довольно сложным (как описано выше), но если вкратце, наша инфраструктура включала уровень балансировки и распределения нагрузки (в тандеме с уровнем получения данных из источника), уровень кэширования источника, уровень обработки изображений и уровень доставки контента.

В основе уровня балансировки нагрузки находилась служба Spillway, выступавшая в качестве обратного прокси и брокера запросов. Это была сугубо внутренняя служба; на грани мы запускали nginx и HAProxy и Spillway, таким образом, не была рассчитана на завершение TLS или выполнение каких-либо иных функций из того бесчисленного множества, которое обычно в компетенции пограничного прокси.
Spillway состояла из двух компонентов: клиентской части (Spillway FE) и брокера. Хотя изначально оба компонента находились в одном двоичном файле, в какой-то момент мы решили разделить их на отдельные двоичные файлы, которые разворачивались одновременно на одном хосте. Главным образом, потому, что эти два компонента имели различные профили производительности, а клиентская часть была почти полностью связана с процессором. Задача клиентской части заключалась в выполнении предварительной обработки каждого запроса, включая предварительную проверку на уровне кэширования источника, чтобы убедиться в кэшировании изображения в нашем центре обработки данных перед направлением исполнителю запроса на преобразование изображения.
В любой момент времени у нас был фиксированный пул (дюжина или около того, если память не изменяет) исполнителей, которые могли быть подключены к одному брокеру Spillway. Исполнители отвечали за фактическое преобразование изображения (обрезка, изменение размера, обработка PDF, GIF-рендеринг и т.д.). Они обрабатывали все, от файлов PDF из сотен страниц и файлов GIF с сотнями кадров до простых файлов изображений. Еще одна особенность исполнителя заключалась в том, что, хотя все сети были полностью асинхронными, фактические преобразования на самом GPU отсутствовали. Учитывая, что мы работали в режиме реального времени, было невозможно предсказать, как будет выглядеть наш трафик в определенный момент времени. Наша инфраструктура должна была самоадаптироваться к различным формам входящего трафика — без ручного вмешательства оператора.
Учитывая разрозненные и разнородные схемы трафика, с которыми мы часто сталкивались, для исполнителей необходимой стала возможность отказаться от принятия входящих запросов (даже при полной работоспособности), если принятие соединения грозило перегрузить исполнителя. Каждый запрос к исполнителю содержал некоторый набор метаданных о характере запроса, что позволяло исполнителю определить, в состоянии ли он обслуживать этот запрос. Каждый исполнитель имел собственный набор статистических данных о запросах, с которыми он на данный момент работал. Сотрудник использовал эти статистические данные в сочетании с метаданными запроса и другими эвристическими данными, например, данными о размере буфера сокета, чтобы определить, правильно ли он принял входящий запрос. Если сотрудник определял, что не может принять запрос, то создавал ответ, не отличающийся от проверки агента HAProxy, информирующей его выходной блок (Spillway) о его работоспособности.
Spillway отслеживала работоспособность всех исполнителей пула. Сначала пыталась направить запрос три раза подряд различным исполнителям (предпочтение отдавалось тем, у кого в локальных базах данных имелось исходное изображение и кто не был перегружен), и если все три исполнителя отказывались принять запрос, запрос ставился в очередь в брокере внутри памяти. Брокер поддерживал три формы очередей: очередь LIFO, очередь FIFO и очередь приоритета. Если все три очереди заполнялись, брокер просто отклонял запрос, позволяя клиенту (HAProxy) повторить попытку по истечении периода отсрочки. Когда запрос ставился в одну из трех очередей, любой свободный исполнитель мог убрать его оттуда и обработать. Существуют определенные сложности, связанные с тем, чтобы присвоить запросу приоритет и решить, в какую из трех очередей (LIFO, FIFO, очереди на основе приоритета) следует его поместить, но это уже тема для отдельной статьи.
Нам для эффективной работы службы не требовалось обсуждать эту форму динамической обратной связи. Мы очень внимательно отслеживали размер очереди брокера (всех трех очередей), и Prometheus выдавал одно из ключевых предупреждений, когда размер очереди превышал определенный порог (что происходило довольно редко).
Изображение из моей презентации о системе мониторинга Prometheus на конференции Google NYC в ноябре 2016 года

Предупреждение взято из моей презентации о системе мониторинга Prometheus на конференции OSCON в мае 2017 года
В начале этого года Uber опубликовал интересную статью, в которой пролил свет на свой подход к реализации уровня сброса нагрузки на основе качества обслуживания.
Анализируя сбои за последние полгода, мы обнаружили, что 28% из них можно было смягчить или предотвратить путем плавной деградации.
Три наиболее распространенных типа сбоев были связаны со следующими факторами:
— Изменения схемы входящего запроса, включая перегрузку и плохие узлы-операторы.
— Истощение таких ресурсов, как процессор, память, контур ввода/вывода или сетевые ресурсы.
— Сбои зависимости, включая инфраструктуру, хранилище данных и нижестоящие службы.Мы реализовали детектор перегрузки на основе алгоритма CoDel. Для каждой включенной оконечной точки добавляется облегченный буфер запросов (реализуемый на основе гоурутины и каналов), чтобы отслеживать задержки между моментом получения запроса от источника вызова и началом обработки запроса в обработчике. Каждая очередь отслеживает минимальную задержку в скользящем временном интервале, активируя условие перегрузки, если задержка превышает установленное пороговое значение.
Тем не менее, важно помнить, что если противодавление не распространяется по всей цепочке вызовов, в каком-нибудь компоненте распределенной системы возникнет определенная очередь. Еще в 2013 году Google опубликовала печально известную статью «The Tail at Scale», в которой затронула ряд причин изменчивости задержки в системах с большим числом выходных линий (важной линией является очередь), а также было описано несколько удачных методов (часто с избыточными запросами) для смягчения этой изменчивости.
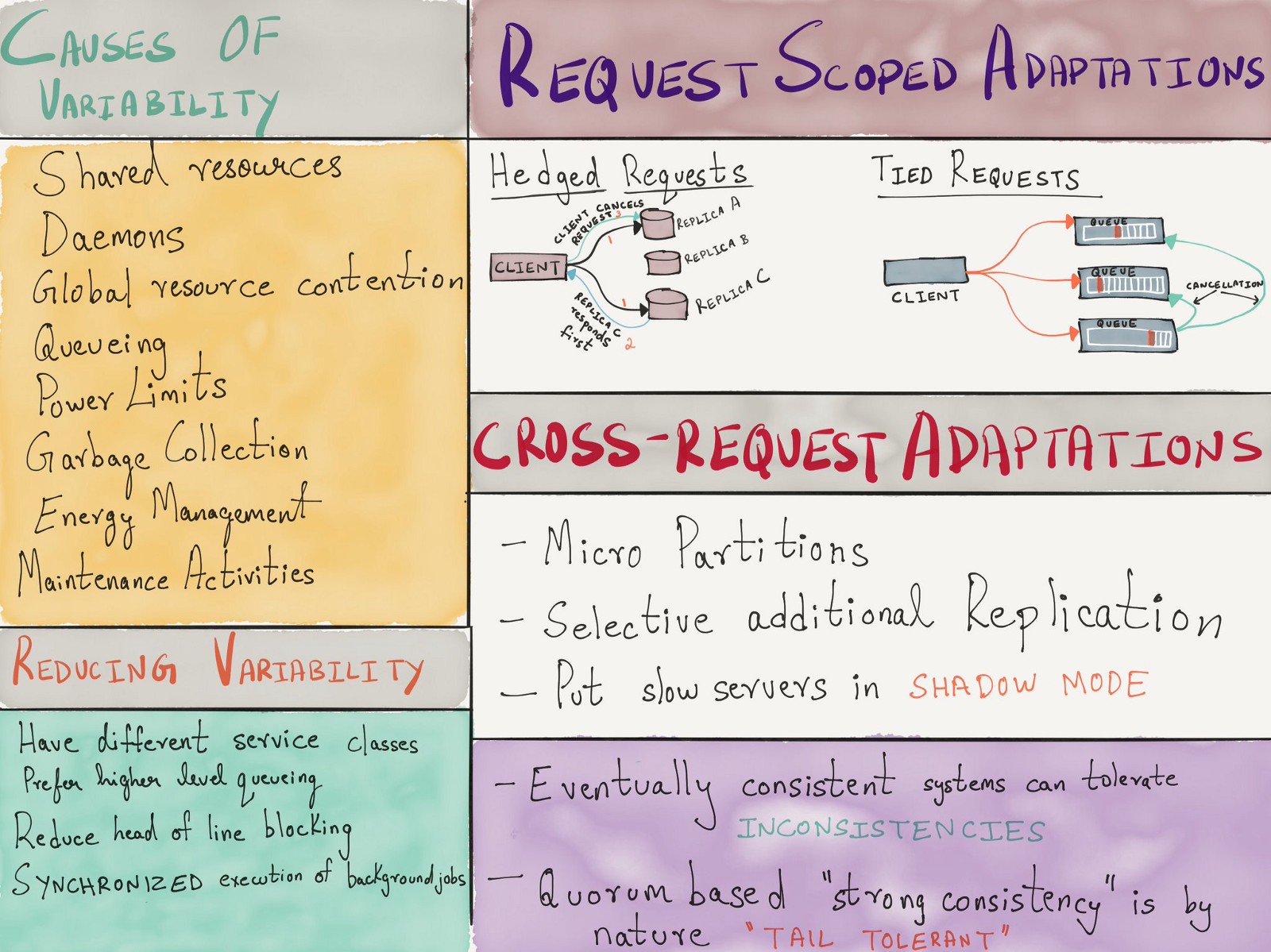
Управление параллелизмом в процессе в режиме реального времени формирует базу для сброса нагрузки, при этом каждый компонент системы принимает решения на основе локальных данных. Помогая в вопросе масштабируемости путем ликвидации потребности в централизованной координации, это не устраняет потребность в централизованном ограничении скорости полностью.

(Множество форм ограничения скорости и методов сброса нагрузки)
Тем, кто заинтересован в получении дополнительной информации о формальном моделировании производительности на основе теории очередизации, я бы рекомендовала ознакомиться со следующими материалами:
- Прикладная теория производительности, Кавья Джоши, QCon London 2018.
- Теория очередизации на практике: Моделирование производительности для инженера-разработчика, Эбен Фримен, из LISA 2017.
- Отмена ограничения скорости — мощность спланирована корректно, Джон Мур, Strangeloop 2017.
- Предиктивная балансировка нагрузки: Несправедливо, но быстрее и надежнее, Стив Гури, Strangeloop 2017.
- Главы по работе с перегрузкой и устранению каскадных сбоев из книги «Техника обеспечения надежности сайта».
Заключение
Контуры управления и противодавление уже являются решенной проблемой в таких протоколах, как TCP/IP (где алгоритмы управления перегрузкой зависят от вывода нагрузки), IP ECN (расширение IP для определения границ пропускной способности) и Ethernet, учитывая эффекты таких элементов, как фреймы паузы.
Крупномасштабных проверок работоспособности может хватать для систем оркестрации, но не для обеспечения качества обслуживания и предотвращения каскадных сбоев в распределенных системах. Балансировщикам нагрузки необходимо видеть уровень приложения для успешного и точного применения противодавления в отношении клиентов. Постепенная деградация службы невозможна, если невозможно точно определить ее уровень работоспособности в любой момент времени. При отсутствии своевременного и достаточного противодавления службы могут быстро провалиться в болото отказов.
