[Перевод] Prometheus и VictoriaMetrics: отказоустойчивая инфраструктура для хранения метрик
В статье мой коллега Luca Carboni, DevOps Engineer из амстердамского офиса Miro, рассказывает, как выглядит наша инфраструктура для хранения метрик. Все компоненты в ней соответствуют принципам высокой доступности (High Availability) и отказоустойчивости (Fault Tolerance), имеют чёткую специализацию, могут хранить данные долгое время и оптимальны с точки зрения затрат.
Стек, о котором пойдёт речь: Prometheus, Alertmanager, Pushgateway, Blackbox exporter, Grafana и VictoriaMetrics.
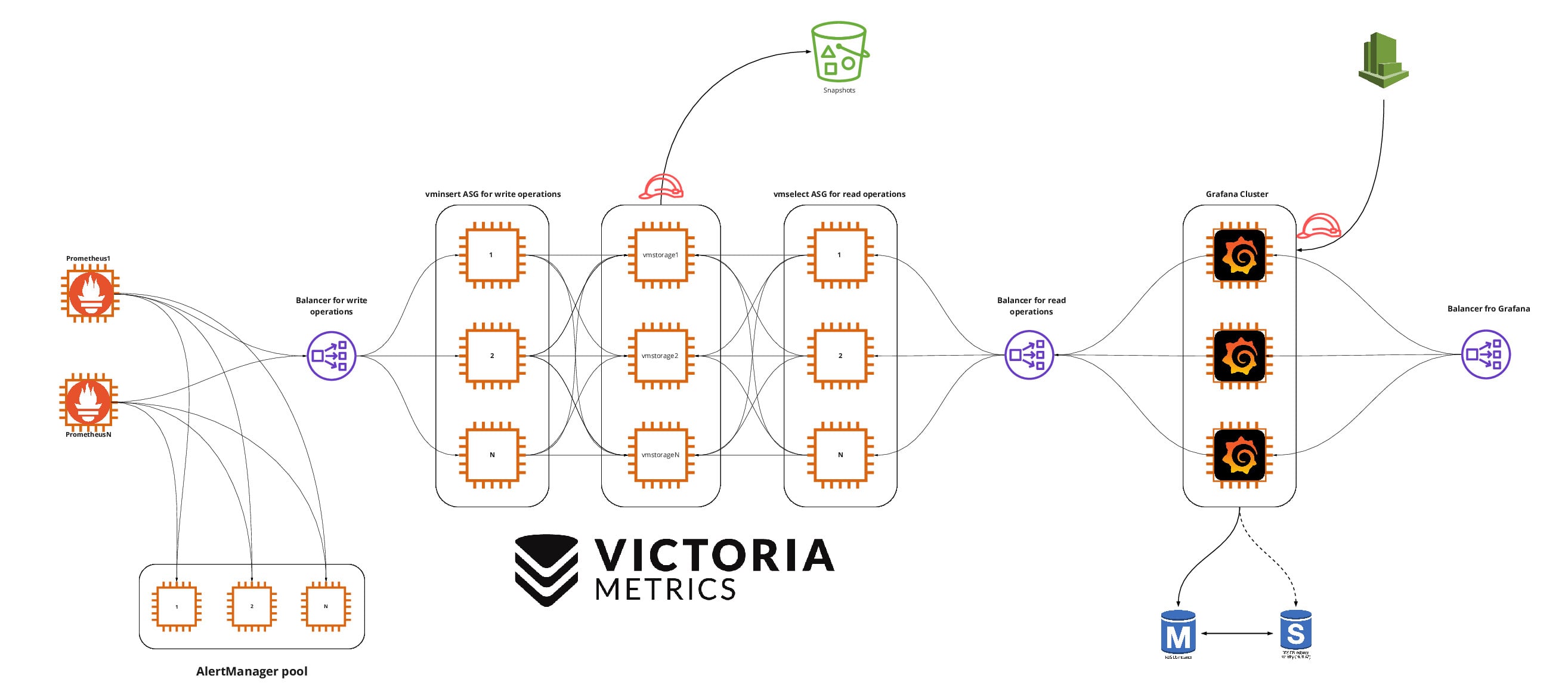
Настройка High Availability и Fault Tolerance для Prometheus
Сервер Prometheus может использовать механизм federation, чтобы собирать метрики с других серверов Prometheus. Он хорошо работает, если вам нужно открыть часть метрик инструментам вроде Grafana или нужно собрать в одном месте метрики разного типа: например, бизнес-метрики и сервисные метрики с разных серверов.
Такой подход широко применяется, но не соответствует принципам высокой доступности и отказоустойчивости. Мы работаем лишь с частью метрик, а если один из серверов Prometheus перестанет отвечать, то данные за этот период собраны не будут.
Готового встроенного решения этой проблемы не существует, но для её решения не обязательно настраивать сложные кластеры и придумывать сложные стратегии взаимодействия серверов. Достаточно продублировать конфигурационный файл (prometheus.yml) на двух серверах, чтобы они собирали одни и те же метрики одинаковым способом. При этом сервер A будет дополнительно мониторить сервер B и наоборот.
Старый добрый принцип избыточности прост в реализации и надежён. Если мы добавим к нему инструмент IaC (инфраструктура как код) вроде Terraform и систему управления конфигурациями (CM) вроде Ansible, то этой избыточностью будет легко управлять и легко её поддерживать. При этом можно не дублировать большой и дорогой сервер, проще дублировать маленькие серверы и хранить на них только краткосрочные метрики. К тому же, небольшие серверы проще воссоздавать.Alertmanager, Pushgateway, Blackbox, экспортёры
Теперь посмотрим на другие сервисы с точки зрения высокой доступности и отказоустойчивости.
Alertmanager может работать в кластерной конфигурации, умеет дедуплицировать данные с разных серверов Prometheus и может связываться с другими копиями Alertmanager, чтобы не отправлять несколько одинаковых оповещений. Поэтому можно установить по одной копии Alertmanager на оба сервера, которые мы продублировали: Prometheus A и Prometheus B. И не забываем про инструменты IaC и CM, чтобы управлять конфигурацией Alertmanager при помощи кода.
Экспортёры устанавливаются на конкретные системы-источники метрик, их дублировать не нужно. Единственное, что нужно сделать — разрешить серверам Prometheus A и Prometheus B подключаться к ним.
С Pushgateway простым дублированием сервером не обойтись, потому что мы получим дуплицирование данных. В этом случае нам нужно иметь единую точку для приёма метрик. Для достижения высокой доступности и отказоустойчивости можно продублировать Pushgateway и настроить DNS Failover или балансировщик, чтобы при отказе одного сервера все запросы шли на другой (конфигурация active/passive). Таким образом у нас будет единая точка доступа для всех процессов, несмотря на наличие нескольких серверов.
Blackbox мы также можем продублировать для серверов Prometheus A и Prometheus B.
Итого, у нас есть два сервера Prometheus, две копии Alertmanager, связанные друг с другом, два Pushgateway в конфигурации active/passive и два Blackbox. Высокая доступность и отказоустойчивость достигнуты.
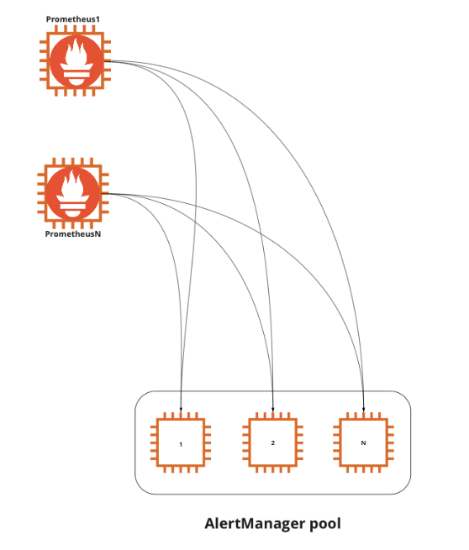
Нет особого смысла использовать только эти копии для сбора всех метрик сервиса. Сервис может быть расположен на нескольких VPC (Virtual Private Cloud), которые могут находиться в разных регионах, принадлежать разным аккаунтам и провайдерам. У вас даже могут быть собственные серверы. В этих случаях копии станут очень большими, а значит их станет сложнее чинить. Распространённая практика достижения высокой доступности и отказоустойчивости здесь — иметь отдельный набор приложений для каждой части инфраструктуры. Принципы разделения инфраструктуры на части зависят от ваших потребностей, настроек сети и безопасности, доверия между командами и так далее.
В итоге мы имеем относительно небольшие копии Prometheus, продублированные вместе со всеми компонентами, упомянутыми выше. У нас есть код, который может их быстро воссоздать. И нам не страшен выход из строя одного компонента в каждой группе. Это определенно лучше плана «скрестить пальцы и надеяться, что ничего не упадёт».
VictoriaMetrics для долгосрочного хранения данных
Мы настроили Prometheus и его экосистему для достижения высокой доступности и отказоустойчивости. У нас есть несколько небольших групп Prometheus со связанными компонентами, каждая из которых решает задачи в своей части инфраструктуры. Это отлично работает для хранения данных в краткосрочном периоде. Для решения большинства задач нам достаточно хранения метрик в течение 10 дней. Что делать, если нужно хранить данные дольше? Например, когда требуется найти связь между разными периодами — неделями или месяцами. Prometheus может работать с долгосрочными данными, но стоимость этого будет очень высокой из-за того, что инструменту требуется иметь к ним быстрый доступ.
Тут на помощь приходят Cortex, Thanos, M3DB, VictoriaMetrics и многие другие инструменты. Все они умеют собирать данные с нескольких серверов Prometheus, дедуплицировать их — у нас точно будут дубликаты, так как каждый наш сервер существует в двух экземплярах, — и предоставлять единое хранилище для собираемых метрик.
В этой статье я не буду сравнивать инструменты между собой, расскажу только про наш опыт работы с VictoriaMetrics.
Настройка кластерной версии
VictoriaMetrics доступен в двух версиях: обычная «всё-в-одном» (single-node version) и кластерная (cluster version). В обычной версии все компоненты объединены в одно приложение, поэтому инструмент проще настраивать, но масштабировать можно только вертикально. Кластерная версия разбита на отдельные компоненты, каждый из которых можно масштабировать вертикально и горизонтально.
Обычная версия — хорошее и стабильное решение. Но мы любим всё усложнять (хех), поэтому выбрали кластерную версию.
Кластерная версия VictoriaMetrics состоит из трёх основных компонентов: vmstorage (хранение данных), vminsert (запись данных в хранилище) и vmselect (выборка данных из хранилища). В таком виде инструмент получается очень гибким, vminsert и vmselect выступают как своего рода прокси.
У vminsert есть множество полезных настраиваемых параметров. Для целей этой статьи важно то, что его можно продублировать любое количество раз и поставить перед этими копиями балансировщик нагрузки, чтобы иметь единую точку приёма данных. У vminsert нет состояния (stateless), поэтому с ним легко работать, легко дублировать, его удобно использовать в неизменяемых инфраструктурах и при автоматическом масштабировании.
Самые важные параметры, которые нужно указать для vminsert — это адреса хранилищ (storageNode) и количество хранилищ, на которые нужно реплицировать данные (replicationFactor=N, где N — количество копий vmstorage). Но кто будет слать данные на балансировщик перед vminsert? Это будет делать Prometheus, если мы укажем адрес балансировщика в настройках remote_write.
vmstorage — пожалуй, самый важный компонент VictoriaMetrics. В отличие от vminsert и vmselect, vmstorage имеет состояние (stateful), и каждая его копия ничего не знает о других копиях. Каждый запущенный vmstorage считает себя изолированным компонентом, он оптимизирован для облачных хранилищ с большим временем отклика (IO latency) и небольшим количеством операций в секунду (IOPS), что делает его существенно дешевле того способа хранения данных, который использует Prometheus.
Самые важные настройки vmstorage:
storageDataPath — путь на диске, по которому будут храниться данные;
retentionPeriod — срок хранения данных;
dedup.minScrapeInterval — настройка дедупликации (считать дубликатами те записи, разница между временными метками которых меньше указанного значения).
У каждой копии vmstorage свои данные, но благодаря параметру replicationFactor, который мы указали для vminsert, одни и те же данные будут отсылаться в несколько (N) хранилищ.
vmstorage можно масштабировать вертикально, можно использовать более вместительные облачные хранилища, и даже для долговременного хранения метрик это будет недорого, так как vmstorage оптимизирован под этот тип хранилищ.
vmselect отвечает за выборку данных из хранилищ. Его легко дублировать, перед созданными копиями тоже можно поставить балансировщик нагрузки, чтобы иметь один адрес для приёма запросов. Через этот балансировщик можно получить доступ ко всем данным, которые были собраны с нескольких групп Prometheus, и эти данные будут доступны столько времени, сколько вам нужно. Основным потребителем этих данных, скорее всего, будет Grafana. Как и vminsert, vmselect можно использовать при автоматическом масштабировании.

Настройка высокой доступности и отказоустойчивости для Grafana
Grafana умеет работать как с метриками, которые собирает Prometheus, так и с метриками, которые хранятся в VictoriaMetrics. Это возможно благодаря тому, что VictoriaMetrics поддерживает кроме собственного языка запросов (MetricsQL) ещё и PromQL, используемый Prometheus. Попробуем достичь высокой доступности и отказоустойчивости для Grafana.
По умолчанию Grafana использует SQLite для хранения состояния. SQLite удобен для разработки, отлично подходит для мобильных приложений, но не очень хорош для отказоустойчивости и высокой доступности. Для этих целей лучше использовать обычную СУБД. Например, мы можем развернуть PostgreSQL на Amazon RDS, который использует технологию Multi-AZ для обеспечения доступности, и это решит нашу главную проблему.
Для создания единой точки доступа мы можем запустить какое угодно количество копий Grafana и настроить их на использование одного и того же облачного PostgreSQL. Количество копий зависит от ваших потребностей, вы можете масштабировать Grafana горизонтально и вертикально. PostgreSQL можно установить и на серверы с Grafana, но нам лень это делать и больше нравится пользоваться услугами облачных провайдеров, когда они отлично справляются с задачей и не используют vendor lock. Это отличный пример того, как можно сделать жизнь проще.
Теперь нам нужен балансировщик нагрузки, который будет распределять трафик между копиями Grafana. Этот балансировщик мы дополнительно можем привязать к красивому домену.
Дальше остаётся соединить Grafana с VictoriaMetrics —, а точнее, с балансировщиком перед vmselect, — указав Prometheus в качестве источника данных. На этом нашу инфраструктуру для мониторинга можно считать завершённой.

***
Теперь все компоненты инфраструктуры соответствуют принципам высокой доступности и отказоустойчивости, имеют чёткую специализацию, могут хранить данные долгое время и оптимальны с точки зрения затрат. Если мы захотим хранить данные ещё дольше, мы можем по расписанию автоматически делать снимки vmstorage и отправлять их в хранилище, совместимое с Amazon S3.
Это всё, что касается метрик. Нам ещё нужна система работы с логами, но это уже совсем другая история.
Список инструментов:
Оригинал статьи в англоязычном блоге Miro.
