[Перевод] Проектирование надёжности сайта для Kubernetes

За последние 4,5 года Kubernetes значительно улучшилась с точки зрения удобства использования, и теперь начать работу с Kubernetes стало проще, чем когда-либо. Облачные провайдеры, такие как Amazon AWS, теперь располагают продуктами Kubernetes, которые создают кластеры для вас и управляют ими. Это существенное преимущество по сравнению с созданием собственного кластера Kubernetes.
Один из самых заметных сдвигов в нашей отрасли, который я наблюдал за последние 2 года, заключается в том, что теперь все больше компаний используют Kubernetes в своих производственных нагрузках. Именно сейчас все становится интересным для SRE. Мы получаем возможность учиться друг у друга, обсуждать общие проблемы в области надежности и делиться ее принципами, которым нужно следовать, чтобы укрепить кластеры Kubernetes.
Спасибо https://twitter.com/MindsEyeCCF за эту иллюстрацию
Глубокое изучение надежности
Как в SRE, у меня также существует система, которую я использую при проведении глубокого анализа надежности:
Оглянитесь назад и проанализируйте неудачи
Определите цели и ключевые параметры
Создайте стратегию надежности
Проверьте стратегию надежности на практике
После того, как эта схема приведена в действие, я постоянно отслеживаю прогресс и сообщаю о нем.
Оглянитесь назад и проанализируйте неудачи
Далее, давайте начнем с рассмотрения распространенных видов отказов при запуске Kubernetes в продакшн.
Распространенные типы отказов для Kubernetes в продакшн
На основе анализа отчетов, собранных и опубликованных на сайте k8s.af, мы можем определить наиболее распространенные виды отказов, которые в настоящее время влияют на Kubernetes в продакшн. Чаще всего инциденты были вызваны проблемами, связанными с процессором (CPU) (25%) или недоступностью кластеров из-за целого ряда проблем (25%). Остальные 50% инцидентов были связаны с сетью (DNS, задержка и потеря пакетов), ресурсами (диск или память) или безопасностью.
Перебои, связанные с CPU, можно разделить на три категории: высокий уровень загрузки CPU (High CPU), троттлинг CPU и автомасштабирование через CPU.
Тип отказа Kubernetes: High CPU
Несколько компаний сообщили о резких скачках нагрузки на процессор (High CPU), вызывающих проблемы для них и их пользователей. Инженер по тестированию компании Дэн Вудс рассказал о том, как его кластеры Kubernetes пострадали от инцидента с высокой нагрузкой на процессор, в заметке на Medium под названием «Инфраструктура в масштабе: Каскадный отказ распределенных систем».
Ниже приведены ключевые выдержки (иллюстрации Эмили Гриффин):

Тип отказа Kubernetes: троттлинг CPU
В июле 2019 года Хеннинг Якобс (Zalando) выступил на ContainerDays в Гамбурге с докладом «Истории неудач Kubernetes, или: Как обрушить ваш кластер — Хеннинг Якобс». В этом докладе Хеннинг объяснил, что троттлинг CPU влияет на надежность кластера.
Тип отказа Kubernetes: автомасштабирование через CPU
В 2017 году компания Nordstrom рассказала о 101 способе выхода из строя вашего кластера на основе опыта, который они получили при масштабировании Kubernetes. Среди них были примеры, связанные с автомасштабированием.
Далее посмотрим, есть ли разница в типах отказов для различных облачных провайдеров. Мы предполагаем, что определенные отказы будут чаще ассоциироваться с конкретными провайдерами.
Анализ сообщений о сбоях Kubernetes от облачных провайдеров
На сайте k8s.af собрано и размещено 45 сообщений об инцидентах, связанных с продакшн Kubernetes. Анализируя список облачных провайдеров, которые чаще всего упоминаются в этих сообщениях, мы видим, что 65,8% этих инцидентов произошли на AWS. В основном это были кластеры AWS Kubernetes, запущенные вручную на EC2 (а не управляемый сервис Kubernetes, предоставляемый AWS, EKS), есть только 1 сообщение об инциденте AWS EKS. Пользователи GKE столкнулись с 23,7% сбоев, за ними следует Azure (5,3% сбоев). 5,3% сбоев произошли с кластерами Kubernetes, расположенными на локальных серверах.
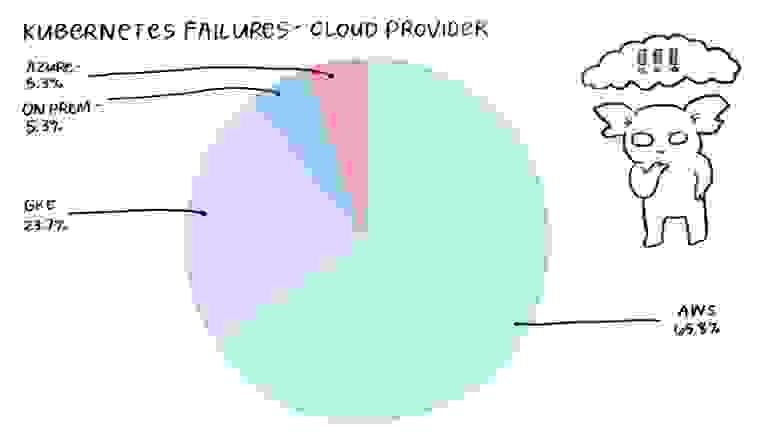
Далее рассмотрим распространенные типы отказов в зависимости от поставщика облачных услуг. Поскольку автомасштабирование, CPU и отключение инстансов управляются по-разному у каждого облачного провайдера, я ожидаю, что определенные сбои будут чаще встречаться у конкретной компании (например, CPU у Amazon AWS).
Основные типы отказов, к которым следует готовиться поставщикам облачных услуг
Kubernetes на AWS: типы отказов
Если вы используете AWS, я рекомендую вам сосредоточиться на CPU в качестве основного способа устранения неисправностей во время ваших действий по обеспечению надежности. Затем я рекомендую исследовать отказы, связанные с сетью (в первую очередь «Черные дыры» (Blackhole), задержки и DNS).
Kubernetes на GKE: типы отказов
Если вы используете GKE, то я рекомендую вам сосредоточиться на Blackhole в качестве основного типа отказа во время мероприятий по укреплению надежности. Затем я рекомендую изучить отключение, задержку и DNS.
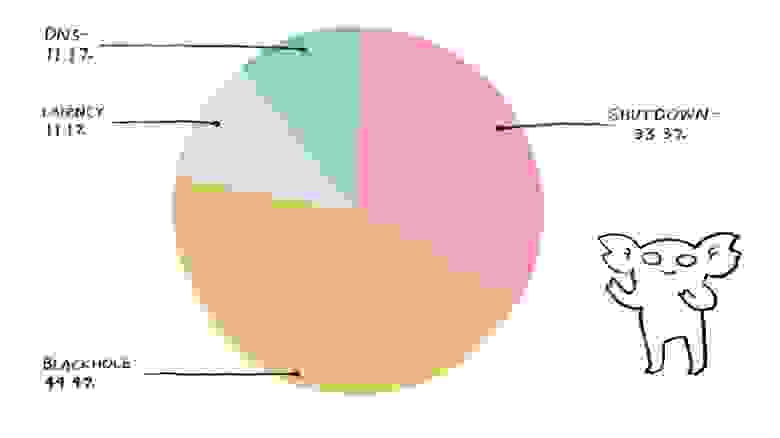
Если вы используете Azure, я рекомендую вам сосредоточиться на отключении (Shutdown) в качестве основного типа отказов во время мероприятий по укреплению надежности.
Kubernetes локальный вариант: типы отказов
Если вы используете собственное оборудование локально и имеете свои центры данных, я рекомендую вам сосредоточиться на CPU и DNS.
Проектирование надежности сайта для Kubernetes
Теперь, когда мы изучили общие виды отказов для Kubernetes у различных облачных провайдеров, пришло время взять полученные знания использовать их на практике в SRE для Kubernetes.
SRE — это инженеры-программисты, специализирующиеся на надежности. SRE применяют принципы компьютерной науки и инженерии для проектирования и разработки компьютерных систем: главным образом, больших распределенных систем.
Теперь мы готовы определить наши цели и основные параметры.
Определение целей и основных параметров
Существует ряд важных параметров, на которые следует обратить внимание, когда речь идет о надежности вашего кластера Kubernetes. Ниже приведена подборка показателей Kubernetes, о которых необходимо сообщать и отслеживать их в режиме реального времени:
Количество кластеров Kubernetes
Количество узлов
Количество узлов по кластерам
Количество подов
Количество подов по узлам
Узлы по времени работы (от минимального до максимального)
Поды по времени работы (от минимального до максимального)
Количество приложений/сервисов
Количество приложений/сервисов по кластерам
Использование ресурсов по узлам (например, CPU)
Запись на диск на узел
Чтение диска на узел
Сетевые ошибки на узел
Создание плана надежности
Теперь мы готовы создать стратегию надежности для Kubernetes в нашей компании. Я настоятельно рекомендую создать индивидуальную стратегию, основанную на специфике компании и целях, к которым вы стремитесь как организация.
Оглянитесь назад и проанализируйте неудачи
Определите цели и основные показатели
Создайте стратегию надежности
Испытайте свою стратегию надежности на практике
При создании плана мероприятий по обеспечению надежности мы должны начать с принципов, которые основаны на том, что же мы собой представляем. Что представляет собой компания? Кого мы обслуживаем? Каковы наши убеждения и убеждения клиентов? Что клиенты ценят в нас?
Затем необходимо определить наше видение надежности, для чего задаем себе вопросы «Почему мы в этом бизнесе?» и «Зачем мы нужны нашим клиентам?». Затем определяем миссию надежности, где спрашиваем: «Что мы делаем?» и «Как мы можем изменить наш мир, отрасль и сообщество?». Затем определяем стратегические цели, задавая себе вопрос: «Чего хотим достичь и когда должны это сделать?». Наконец, определяем тактику, которую будем использовать для достижения стратегических целей, спрашивая себя «как мы этого добьемся?». Определяем наши краткосрочные цели (менее 1 года) и выделяем проекты, ресурсы и людей, необходимых для их реализации.
Фиктивный план надежности: Интернет-банкинг как услуга
Давайте создадим фиктивный (придуманный) план надежности для банка, предоставляющего услугу интернет-банкинга:
Ценности: Увлеченность клиентами — ставим себя на место наших клиентов, находим и предоставляем им правильные решения и быстро исправляем ошибки.
Видение: Мы стремимся побеждать вместе, проявляя смелость и принимая правильные решения в интересах наших клиентов, людей и общества.
Миссия: Быть ведущим в мире онлайн-банком, которому доверяют клиенты и который ценят за безупречный сервис.
Стратегические цели: В ближайшие 5 лет мы хотим стать самым популярным онлайн-банком как по общему количеству клиентов, так и по рейтингу их удовлетворенности.
Тактика:
Масштабирование — чтобы обеспечить надежное расширение и удовлетворение потребностей наших клиентов, мы сосредоточимся на масштабируемости. По мере привлечения новых клиентов наши существующие и новые клиенты должны иметь положительный опыт.
Доступность — для того чтобы клиенты всегда могли получить доступ к интернет-банкингу, сосредоточимся на обеспечении длительности времени безотказной работы в качестве основной услуги и будем быстро исправлять ошибки. Мы будем следить за тем, чтобы клиенты всегда имели доступ к своим деньгам.
Корректность — обеспечение точности операций интернет-банкинга и предоставление их клиентам в режиме реального времени.
Я лично не верю, что можно заниматься надежностью в вакууме, вдали от клиентов или ценностей, видения и миссии компании.
Протестируйте свою стратегию надежности Kubernetes
Теперь, когда мы проанализировали отказы, определили цели и создали план надежности, мы готовы испытать его на практике!
Исходя из того, что мы обнаружили, стало ясно, что нужно быть готовым к определенным видам отказов, которые помешают нашему плану надежности быть успешным.
На основе нашего придуманного примера мы можем классифицировать распространенные типы отказов с учетом тактики нашего плана надежности следующим образом:
Масштаб — процессор
Доступность — Blackhole, DNS
Корректность — отключение, задержка и потеря пакетов.
Далее мы можем сосредоточиться на обеспечении защиты наших кластеров K8s в приоритетном порядке, основываясь на полученных знаниях и тактике нашей компании. В следующем разделе я расскажу, как выполнять мероприятия по укреплению.
Укрепление кластеров K8s: Масштабирование (CPU)
Управление CPU очень важно для распределения рабочих нагрузок, и при неправильном его использовании могут возникнуть проблемы. Есть несколько важных вопросов, которые вы должны задать себе:
Сколько процессоров мне понадобится на один инстанс?
Буду ли я использовать приоритеты подов Kubernetes для управления ресурсами?
Насколько сложно мне будет обновить мои инстансы и увеличить количество CPU?
Пример по укреплению #1: Kubernetes — High CPU
Для этого задания мы будем использовать сценарий Gremlin «Kubernetes — Масштаб — High CPU». Это сценарий масштабирования Kubernetes. Он вызовет увеличение нагрузки на CPU. Мы ожидаем, что это не ухудшит функциональность для пользователя, и все операции будут выполняться так, как ожидается.
https://app.gremlin.com/scenarios/recommended/kubernetes-scale-high-cpu/hosts
Пример по укреплению #2: Kubernetes — троттлинг CPU
Для этого примера укрепления мы будем использовать сценарий Gremlin «Kubernetes — Масштаб — Троттлинг CPU». Это сценарий масштабирования для Kubernetes. Он будет способствовать ускорению CPU в виде серии атак. С его помощью можно убедиться в отсутствии проблем, связанных с троттлингом CPU. В июле 2019 года Хеннинг Якобс (Zalando) выступил на ContainerDays в Гамбурге с докладом «Истории неудач Kubernetes, или: Как обрушить ваш кластер — Хеннинг Якобс». В этом докладе Хеннинг объяснил, что троттлинг CPU влияет на надежность кластера.
https://app.gremlin.com/scenarios/recommended/kubernetes-scale-throttle-cpu/hosts
Пример по укреплению #3: Kubernetes — автомасштабирование через CPU
Для этого примера по укреплению мы будем использовать сценарий Gremlin «Kubernetes — Масштаб — Автомасштабирование через CPU». Это сценарий масштабирования для Kubernetes. Он запустит автомасштабирование AWS, основанное на ускорении работы CPU. Мы ожидаем, что это не приведет к ухудшению функциональности для пользователя, и все операции будут выполняться так, как ожидается.
AWS Autoscaling Docs
https://app.gremlin.com/scenarios/recommended/kubernetes-scaling-autoscaling-via-cpu/
Укрепление кластеров K8s: Доступность (Blackhole и DNS)
«Черная дыра» (Blackhole) — способ, который можно использовать для более безопасного обеспечения недоступности узлов и подсистем. Это не такое разрушительное действие, как отключение. Есть несколько важных вопросов, которые вы должны задать себе:
Может ли мой кластер Kubernetes корректно справиться с недоступностью узла?
Может ли мой кластер Kubernetes корректно справиться с недоступностью пода?
Как мой кластер Kubernetes справится с отключением DNS?
Пример по укреплению #4: Kubernetes — Blackhole на узле Kubernetes
Для этого примера по укреплению мы будем использовать сценарий Gremlin «Kubernetes — Доступность — Blackhole на узле Kubernetes». Это сценарий доступности для Kubernetes. Он сделает недоступным один узел в вашем кластере Kubernetes. При этом ожидается, что приложение все равно сможет обслуживать пользовательский трафик и работать как положено.
https://app.gremlin.com/scenarios/recommended/kubernetes-availability-blackhole-kubernetes-node/hosts
Пример по укреплению #5: Kubernetes — Blackhole в области
Для этого примера по укреплению мы будем использовать сценарий Gremlin «Kubernetes — Доступность — Blackhole в области». Этот сценарий сделает одну область недоступной. Мы предполагаем, что приложение сможет правильно маршрутизировать пользовательский трафик. Приложение будет функционировать так, как ожидается.
https://app.gremlin.com/scenarios/recommended/kubernetes-availability-blackhole-a-region
Пример по укреплению #6: Kubernetes — отключение DNS
Для этого примера по укреплению мы будем использовать сценарий Gremlin «Kubernetes — Доступность — отключение DNS». Это сценарий доступности для Kubernetes. Согласно такому сценарию произойдет отключение DNS. Мы ожидаем, что приложение все еще сможет обслуживать пользовательский трафик и работать как положено благодаря отказоустойчивости DNS. Если восстановление работоспособности DNS настроено неправильно, мы ожидаем, что произойдет перебой.
https://app.gremlin.com/scenarios/recommended/kubernetes-availability-dns-outage/hosts
Укрепление кластеров K8s: Корректность (отключение, задержка и потеря пакетов)
Целостность и корректность данных всегда является одной из основных проблем клиентов. Проблемы с данными — самый быстрый способ потерять доверие и клиентов. Есть несколько важных вопросов, которые вы должны задать себе:
Если узел будет выключен, сохранится ли целостность и корректность данных?
Как мой кластер Kubernetes справляется с задержками?
Как мой кластер Kubernetes справляется с потерей пакетов?
Пример по укреплению #7: Kubernetes — выключение узла
Для этого примера по укреплению мы будем использовать сценарий Gremlin «Kubernetes — Корректность — Выключение узла». Это сценарий корректности для Kubernetes. В этом сценарии узел будет выключен. Мы ожидаем, что приложение не потеряет данные. Приложение должно работать так, как ожидается.
https://app.gremlin.com/scenarios/recommended/kubernetes-correctness-shutdown-a-node/hosts
Пример по укреплению #8: Kubernetes — отключение службы
Для этого примера по укреплению мы будем использовать сценарий Gremlin «Kubernetes — Корректность — Выключение службы». Это сценарий корректности для Kubernetes. В этом сценарии будет отключен один сервис. Мы ожидаем, что приложение сможет правильно маршрутизировать пользовательский трафик и что отключение одной службы не окажет влияния на работу других служб. Приложение должно работать так, как ожидается.
https://app.gremlin.com/scenarios/recommended/kubernetes-correctness-shutdown-a-service/containers
Пример по укреплению #9: Kubernetes — внесение задержки на узле
Для этого примера по укреплению мы будем использовать сценарий Gremlin «Kubernetes — Корректность — Внесение задержки на узле». Это сценарий корректности для Kubernetes. Данный сценарий приведет к задержке на одном узле. Мы ожидаем, что приложение будет продолжать обслуживать трафик, но, возможно, с меньшей скоростью. Приложение должно работать как ожидается и не выдавать ошибок.
https://app.gremlin.com/scenarios/recommended/kubernetes-correctness-inject-latency-to-a-node/hosts
Пример по укреплению #10: Kubernetes — внесение задержки в службу
В этом примере мы будем использовать сценарий Gremlin «Kubernetes — Корректность — Внесение задержки в службу». Это сценарий корректности для Kubernetes. В этом сценарии будет внесена задержка в один сервис. Мы ожидаем, что приложение будет продолжать обслуживать трафик, но, возможно, с меньшей скоростью. Приложение должно работать как ожидается и не выдавать ошибок.
https://app.gremlin.com/scenarios/recommended/kubernetes-correctness-inject-latency-to-a-service/containers
Пример по укреплению #11: Kubernetes — внесение потери пакетов на узле
Для этого примера по укреплению мы будем использовать сценарий Gremlin «Kubernetes — Корректность — Внесение потери пакетов на узле». Это сценарий корректности для Kubernetes. В этом сценарии будет внесена потеря пакетов на одном узле. Мы ожидаем, что приложение будет продолжать обслуживать трафик, но, возможно, с меньшей скоростью. Приложение должно работать как ожидается и не выдавать ошибок.
https://app.gremlin.com/scenarios/recommended/kubernetes-correctness-inject-packet-loss-to-a-service/containers
Пример по укреплению #12: Kubernetes — внесение потери пакетов в службу
В этом примере мы будем использовать сценарий Gremlin «Kubernetes — Корректность — Внести потерю пакетов в службу». Это сценарий корректности для Kubernetes. В этом сценарии будет внесена потеря пакетов для одного сервиса. Мы ожидаем, что приложение будет продолжать обслуживать трафик, но, возможно, с меньшей скоростью. Приложение должно работать как ожидается и не выдавать ошибок.
https://app.gremlin.com/scenarios/recommended/kubernetes-correctness-inject-packet-loss-to-a-service/containers
Заключение
Мы рассмотрели, как применять методы проектирования надежности сайта к вашим кластерам Kubernetes. Начав с анализа неудач, определили цели и ключевые показатели, создали план мероприятий по обеспечению надежности, а затем протестировали его с помощью сценариев Gremlin.
Материал подготовлен в рамках курса «SRE практики и инструменты». Если вам интересно узнать подробнее о формате обучения и программе, познакомиться с преподавателем курса — приглашаем на день открытых дверей онлайн. Регистрация здесь.
