[Перевод] Продвинутое компьютерное зрение. Введение в Прямое визуальное отслеживание
 Кадр из аниме «Жрица и медведь»
Кадр из аниме «Жрица и медведь»
Задача отслеживания объектов на изображении — одна из самых горячих и востребованных областей ML. Однако уже сейчас мы имеем огромное разнообразие различных техник и инструментов. Данная статья поможет начать Ваш путь в мир компьютерного зрения!
Сперва, мы представим некоторые типы методов визуального отслеживания. После, мы объясним как классифицировать их. Мы также поговорим о фундаментальных аспектах прямого визуального отслеживания, уделяя особое внимание методам, основанным на регионах, и методам основанным на градиентах. В будущих статьях мы представим подробный математический вывод алгоритма Лукаса-Канаде с акцентом на выравнивание изображений. И наконец, мы представим, как реализовать эти методы в Python. Давайте начнем!
Визуальное отслеживание — Введение
Визуальное отслеживание, также известное как отслеживание объектов или отслеживание в видео, представляет собой задачу оценки траектории целевого объекта в сцене с использованием визуальной информации. Визуальная информация может поступать из различных источников изображений. Мы можем использовать оптические камеры, тепловизоры, ультразвук, рентген или магнитный резонанс.
Список наиболее распространенных устройств обработки изображений:

Более того, визуальное отслеживание — очень популярная тема, потому что оно имеет применение в огромном количестве задач. Например, оно применяется в области взаимодействия человека и компьютера, робототехники, дополненной реальности, медицины и вооруженных сил.
На следующем изображении приведены примеры областей применения визуального отслеживания:

Теперь рассмотрим как мы можем классифицировать решения, доступные сегодня.
Классифицирование методов визуального отслеживания
Методы визуального отслеживания могут быть классифицированы по следующим основным компонентам:
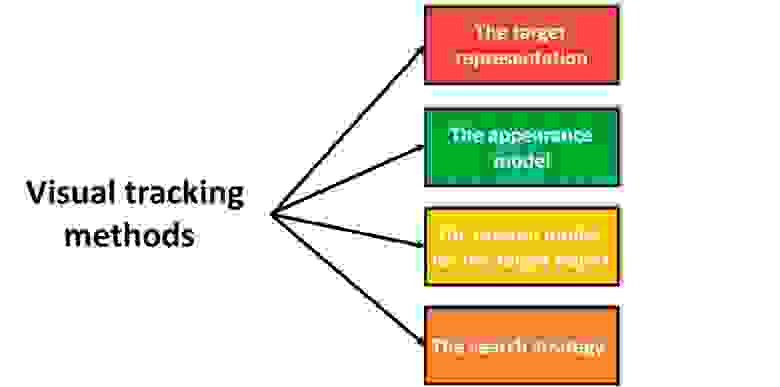
Рассмотрим каждый компонент подробнее.
Представление цели
Во-первых, нам нужно выбрать, что мы отслеживаем. Этот компонент визуального отслеживания называется представление цели (target representation).Согласно Альперу Йилмазу (Alper Yilmaz) и его статье «Object tracking: A Survey», опубликованной в 2006 году, существует несколько типичных представлений целей.Он выделил следующие представления:
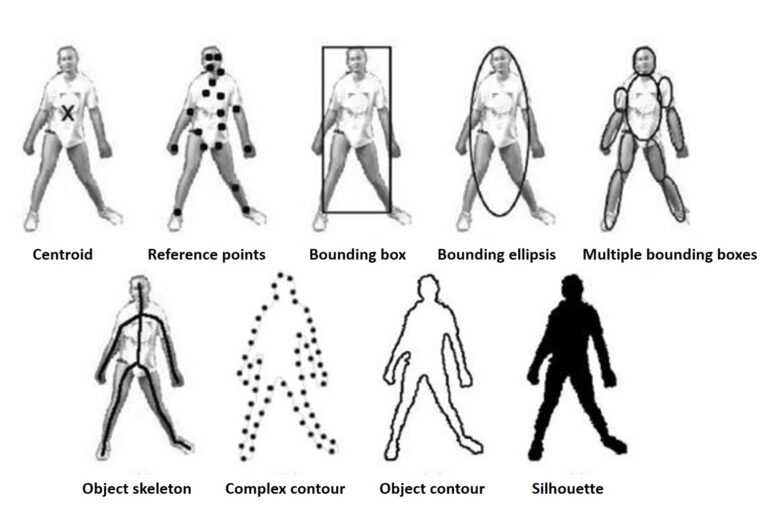
Однако среди этих целевых представлений, bounding box (ограничивающая рамка) является наиболее распространенным методом. Причина в том, что bounding box легко определяет множество объектов.
Модель внешнего вида
Итак, мы рассмотрели несколько способов представить нашу цель. Теперь взглянем на то, как смоделировать внешний вид цели. Идея внешней модели заключается в том, чтобы описать целевой объект на основе доступной визуальной информации. Следовательно, подходящая модель внешнего вида — дискриминационная модель.
Гистограмма изображения
Например, на изображении ниже мы можем заметить футболиста в синей форме, бегущего по полю. Игрок представлен bounding box’ом.
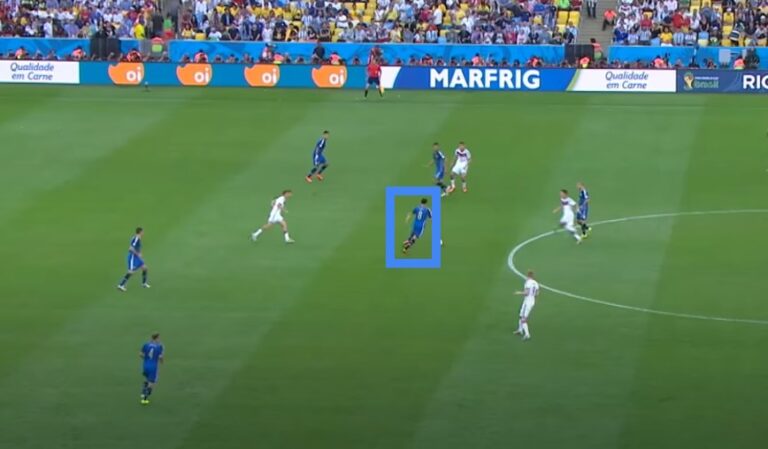
Данный bounding box определит гистограмму. Обычно мы используем гистограмму на изображении в оттенках серого, но также мы можем использовать цветовую гистограмму. На изображении выше мы можем представить цветовую гистограмму прямоугольного bounding box«а. Мы можем использовать эту гистограмму, чтобы отличить целевого игрока от зеленого фона.
Теперь проиллюстрируем это на примере. Например, у нас есть гистограмма где 70% синего цвета и 30% зеленого цвета. Это означает, что когда игрок движется нам необходимо передвигать bounding box по области и найти место с самым высоким процентом синего цвета. Таким образом, найдя рамку, мы всегда будем иметь идеальное совпадение с исходной гистограммой. Таким образом, мы сможем отследить игрока.
Интенсивность изображения
Кроме того, мы можем использовать само эталонное изображение (референс) в качестве модели внешнего вида. В этом случае, целевой объект описывается как набор интенсивности пикселей. Например, если целевой объект движется, наша цель — это найти точное совпадение с эталонным изображением. Этот процесс называется template matching (сопоставлением шаблонов). Он определяет область изображения, которая соответствует ранее заданному шаблону. Однако проблема визуального отслеживания в том, что изображение может быть деформировано, перевернуто, спроецировано и т.д. Это означает, что сопоставление шаблонов не будет работать очень хорошо если изображение искажено.
Мы также можем представить цель с помощью filter bank, который вычисляет результирующее изображение, используя исходные значения интенсивности пикселей. В качестве модели внешнего вида мы можем использовать поля распределения. Эти типы моделей внешнего вида также называются методами на основе регионов (Region-based methods).
Признаки изображения
Еще одним очень популярным типом модели внешнего вида являются признаки изображения. Он основан на эталонном изображении целевого объекта, где набор различимых признаков может быть вычислен для представления цели. Для извлечения признаков часто используются несколько алгоритмов обнаружения объектов. Например такие алгоритмы как SIFT, SURF, ORB, Shi-Tomasi, которые мы рассмотрели в нашей статье «Как извлечь признаки из изображения в Python» (How to extract features from the image in Python).

Разложение подпространства
В некоторых случаях, подпространства эталонного изображения используются для моделирования внешнего вида объекта. Эти более сложные модели оказались очень полезными в ситуациях, где внешний вид отслеживаемого объекта со временем изменяется. В этом контексте часто используют метод главных компонент (Principal Component Anaylysis) и подходы, основанных на словаре (dictionary-based approaches). Здесь можно разобрать эталонное изображение целевого объекта. Например, предположим, что у нас есть датасет изображений 100 человек. Мы получим среднее изображение и добавим один компонент. Этот компонент фиксирует направление куда смотрит человек — влево или вправо. Затем, мы можем использовать этот компонент для поиска людей, смотрящих вправо (Eigenface — одни из подходов по распознаванию людей на изображении).
Далее мы сосредоточимся на типах моделей внешнего вида, которые часто используются в методах отслеживания на основе региона.
Методы отслеживания на основе региона
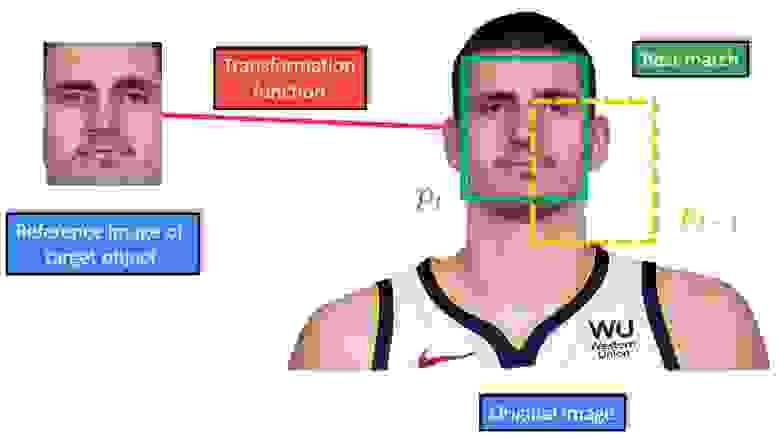
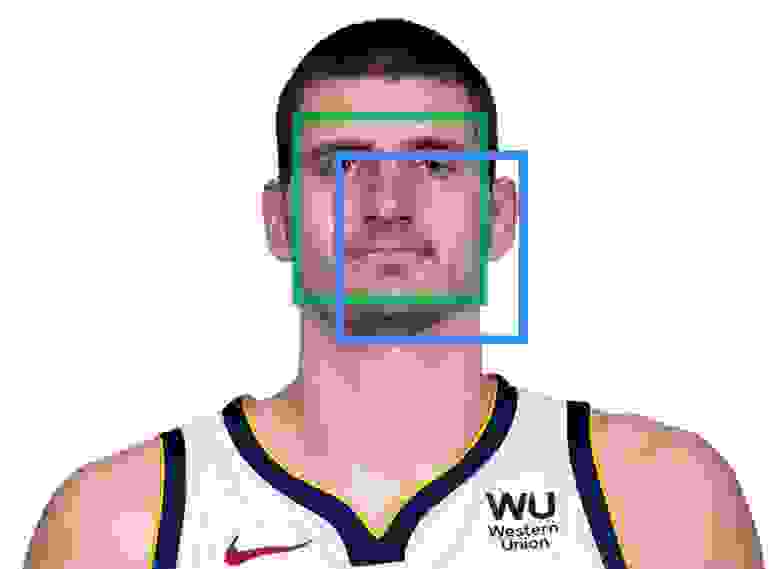
Отслеживание на основе региона пришло из идеи отслеживания региона или части изображения. Как мы говорили раньше, мы будем представлять целевой объект с помощью bounding box«а. Чтобы отслеживать объекты, ограниченные bounding box«ом, нам необходимо определить подходящую модель внешнего вида. В приведенном ниже примере модель внешнего вида это шаблон интенсивности изображения. Здесь у нас есть эталонное изображение целевого объекта слева и мы ищем лучшее совпадение в исходном изображении.
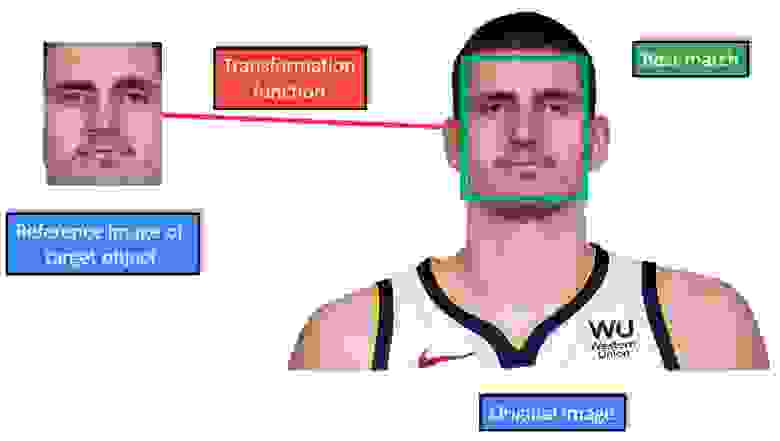
Теперь когда мы приняли модель внешнего вида для нашего целевого объекта, нам необходимо смоделировать его движение в сцене. Это означает, что задача отслеживания решается путем нахождения параметров модели движения. Параметры модели движения максимизируют сходство между референсом и исходным изображением целевого объекта. Например, предположим, что целевой объект перемещается в сцене только в горизонтальном и вертикальном направлениях. В этом случае, простой трансляционной модели с двумя параметрами txи ty будет достаточно для моделирования положения эталонного изображения.
Естественно, если целевой объект движется более сложным образом, то нам необходимо настроить и использовать более сложные модели преобразования с дополнительными степенями свободы, как показано ниже:
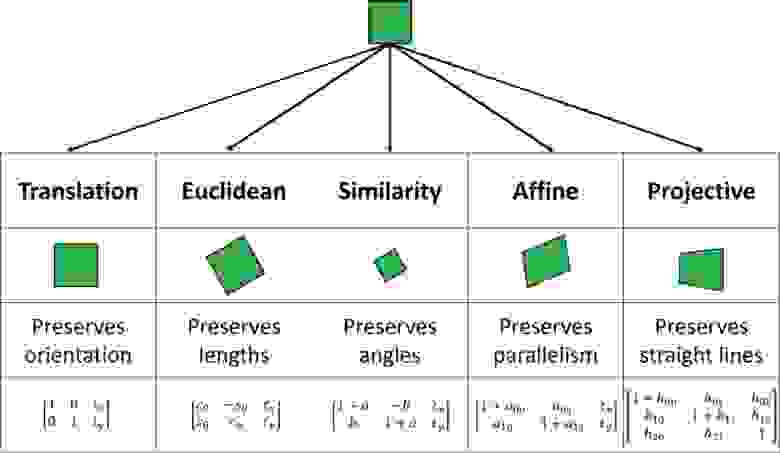
К примеру, если мы отслеживаем обложку книги, затем мы должны использовать проекционную модель которая имеет 8 степеней свободы. С другой стороны, если целевой объект не жесткий, то нам необходимо использовать деформируемую модель. Таким образом, мы могли бы использовать B-spline (Базисный сплайн) или Thin-Plate Splines (Тонкие пластинчатые сплайны) чтобы корректно описать деформацию объекта.
Деформируемы параметрические модели:
Splines (B- Splines, TPS, Multivariate)
Triangular meshes (Треугольная сетка)
Другой аспект прямых методов в том, что часто на практике мы используем позиции целевого объекта в предыдущих кадрах для инициализации поиска его текущей позиции. Итак, учитывая вектор параметров pt-1, нашей движущейся модели в предыдущем кадре t-1, наша задача это найти новый вектор pt, которая наилучшим образом соответствует эталонному и текущему изображениям.
Функция сходства
Это подводит нас к очень интересному вопросу: Что является лучшим совпадением для референса и текущего изображения? Чтобы найти лучшее совпадение нужно найти ту часть текущего изображения которая наиболее похожа на эталонное изображение. Это означает, что мы должны выбрать функцию сходства f между эталонным и исходным изображением. Это было использовано при сопоставлении шаблонов. В следующем примере мы видим, что сходство между первыми двумя изображениями должно быть больше, чем сходство между вторыми двумя изображениями.
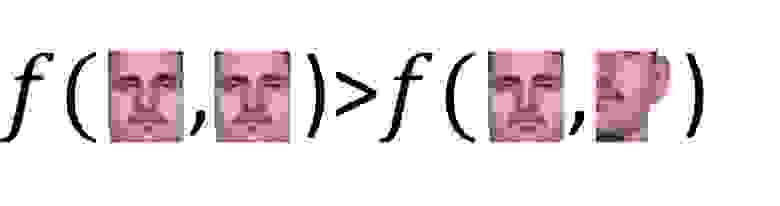
Чтобы вычислить схожесть между шаблоном и исходным изображением, используется несколько функций сходства. Вот несколько из них:
Функции сходства:
Sum of Absolute Differences (SAD)
Sum of Squared Differences (SSD)
Normalized Cross-Correlation (NCC)
Mutual Information (MI)
Structural Similarity Index (SSIM)
Итак, мы выяснили, что для отслеживания необходимо выбрать модель внешнего вида целевого объекта, модель движения и функцию сходства, чтобы определить, насколько эталонное изображение похоже на исходное изображение в видео. Учитывая параметры pt-1 для предыдущего кадра t-1, нам нужно разработать стратегию поиска новых параметров модели pt в текущий момент времени t. Наиболее простой подход заключается в определении локальной области поиска вокруг предыдущих параметров pt-1. В приведенном ниже примере мы будем двигаться от -20 пикселей до +20 пикселей по оси x и от -20 пикселей до +20 пикселей по оси y от положения целевого объекта в предыдущем кадре (предполагается, что у нас есть только трансляция).
Если мы хотим улучшить исчерпывающий поиск в широкой окрестности предыдущего положения объекта, мы можем сократить поиск, используя наши предварительные знания о движении объекта. Например, мы можем использовать классическую систему фильтрации Калмана или более сложные фильтры, такие как фильтр частиц.
Методы основанные на градиентах
Другой очень популярной стратегией поиска является градиентный спуск. Сначала мы выбираем функцию сходства, которая дифференцируема относительно параметров отслеживания и имеет гладкий и выпуклый ландшафт вокруг наилучшего соответствия. Затем мы можем использовать градиентные методы и найти оптимальные параметры модели трансформации (движения).
В следующем примере у нас есть случай, когда нам нужно рассчитать SSD (Sum of Squared Differences).
Предположим, что зеленый прямоугольник является эталонным изображением, и мы хотим проверить его сходство с исходным изображением (синим прямоугольником). Мы вычислим SSD, сдвинув синий прямоугольник так, чтобы он совпадал с зеленым прямоугольником, и вычтем эти два изображения. Затем возведем разницу в квадрат и просуммируем. Если мы получим небольшое число, это означает, что у нас есть похожий шаблон. Этот процесс показан на следующем рисунке.
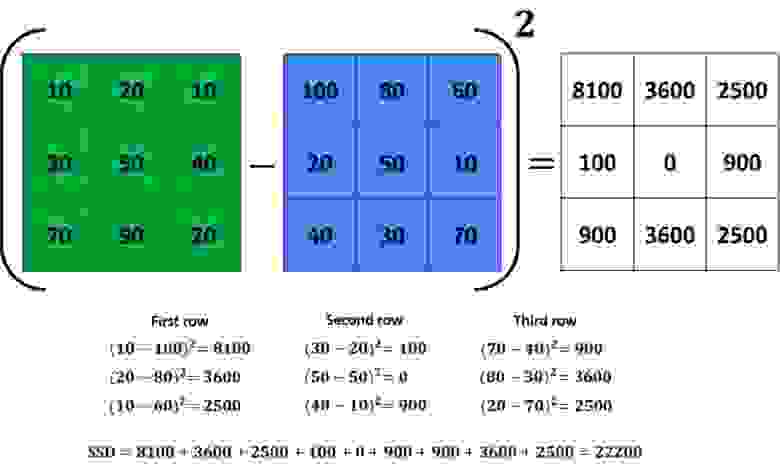
Важно отметить, что SSD будет функцией вектора p, где p=[xy] — наш вектор. Здесь x и y — параметры трансляции, которые мы ищем. Результат вычисления показателя SSD для синего прямоугольника, для смещения плюс-минус пять пикселей вокруг оптимального места выравнивания, дает нам такую кривую. Таким образом, мы можем четко видеть выпуклую и гладкую природу SSD в этом примере.
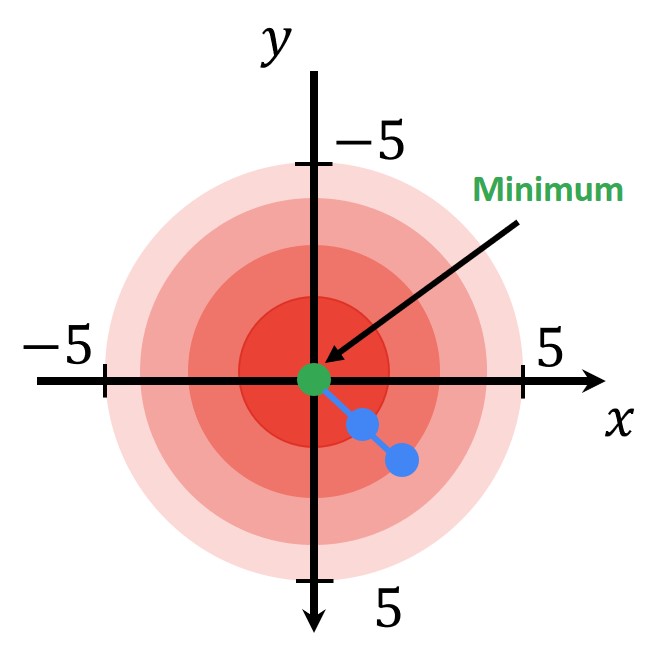
В примере выше справа мы видим двумерную функцию с высоты птичьего полета. В центре находится минимум, а затем вокруг него располагаются большие значения. Теперь, если мы захотим нарисовать эту функцию в одномерном виде, это будет выглядеть следующим образом:
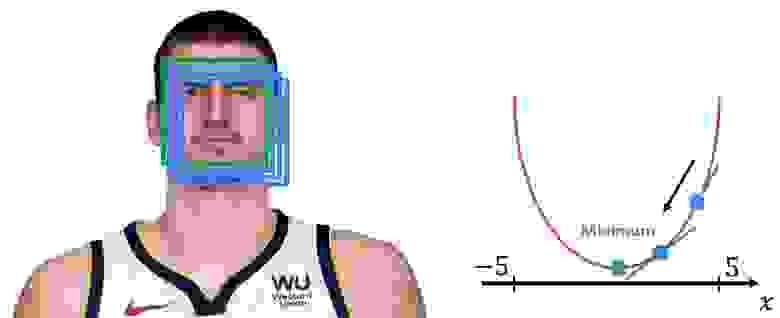
Допустим, что мы ищем вдоль направления x. Сначала мы случайным образом выберем начальную позицию для x. Допустим, x=4. Затем вычислим градиент функции SSD. Далее мы узнаем, что нам нужно двигаться к минимуму функции. Градиент подскажет нам, в каком направлении нужно двигаться в исходном изображении.
Итак, в чем же основное преимущество градиентного спуска? Представьте, что у нас есть модель преобразования с несколькими степенями свободы, например, проективная модель, которую мы используем для отслеживания платы в следующем примере.
Сначала объясним, что значит несколько степеней свободы. Допустим, у нас есть исходное изображение прямоугольника и шаблонное изображение. Обратите внимание, что в приведенном ниже примере прямоугольник на оригинальном изображении слева является спроецированной версией шаблонного изображения справа.
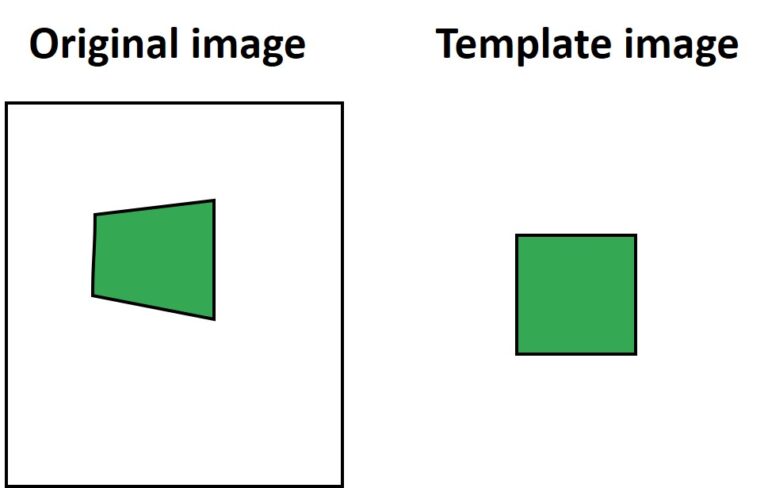
Однако теперь вычислить SSD будет невозможно. Одним из способов решения этой проблемы является обнаружение ключевых точек на обоих изображениях, а затем использование некоторого алгоритма сопоставления признаков, который найдет их совпадения. Однако мы также можем выполнить поиск, используя значения интенсивности изображения шаблона. Для этого мы применим трансформационное искривление. Как мы уже объясняли ранее в этой статье, мы умножим изображение на следующую матрицу перехода:

Это означает, что здесь у нас 8 степеней свободы, потому что в матрице у нас всего 8 параметров и одно число, которое фиксировано на 1. Таким образом, наш исходный прямоугольник теперь будет иметь изменение в перспективе. Это означает, что для расчета SSD, помимо нахождения параметров трансляции x и y, нам также необходимо найти другие параметры для представления вращения, масштабирования, перекоса и проекции.
Итак, основное преимущество градиентного спуска заключается в том, что при вращении, масштабировании и деформации искомого объекта нам не нужно перебирать 1000 и 1000 комбинаций, чтобы найти наилучшие параметры преобразования. С помощью градиентного спуска мы можем получить эти параметры с очень высокой точностью всего за несколько итераций. Таким образом, это значительная экономия вычислительных усилий.
Итог
В этой статье мы узнали, что методы отслеживания изображений состоят из четырех основных компонентов: модели внешнего вида, модели преобразования, меры сходства и стратегии поиска. Мы представили несколько моделей внешнего вида, а также рассказали о моделях преобразования, как жестких, так и нежестких. Кроме того, мы посмотрели, как рассчитать SSD, а также рассказали, как применить градиентный спуск — одну из наиболее распространенных стратегий поиска. В следующих статьях мы продолжим использовать эти методы.
