[Перевод] Повышение эффективности SQL-запросов: советы и рекомендации

Задача
В данном контексте, подчеркивается важность умения настраивать («в нужный режим») SQL-запросы для обеспечения их оптимальной производительности. Этот навык полезен для всех, кто работает с базой данных SQL Server — от обычных пользователей до администраторов и разработчиков, которые пишут собственные SQL-запросы.
В статье представлен ряд советов и методов, которые помогут читателям оценить производительность своих SQL-запросов и улучшить ее при необходимости. Здесь будут рассмотрены некоторые ключевые аспекты оптимизации запросов для SQL Server, чтобы помочь пользователям сделать их более эффективными и быстрыми.
Решение
Данный учебный материал предоставит общие рекомендации по проверке и устранению проблем в SQL-запросах. Важно отметить, что это не полный перечень, а скорее руководство по тому, с чего начать и какие наиболее распространенные сложности могут возникнуть. Это основные моменты, которые следует проверить в первую очередь при исследовании запросов, и после выявления общей проблемы можно будет более детально изучить ее причины и затем справиться с ней.
Эти советы могут быть применены к SQL Server, работающей как на собственном сервере, так и в облаке.
Всегда проверяйте план выполнения запроса
Не важно, используете ли вы SQL Server Management Studio, Azure Data Studio или сторонний инструмент, всегда следует анализировать план выполнения запроса, чтобы выявить проблемы и определить, на чем следует сосредоточиться для улучшения производительности.
О том, как создать план выполнения, вы можете узнать больше с помощью следующих статей:
Как только у вас есть план выполнения (я предпочитаю визуальный формат), мы можем проверить несколько важных моментов, как показано ниже.
Находим операторы с наибольшей стоимостью
В данном примере мы можем рассмотреть стоимость операции Index Scan (сканирования индекса) и увидеть, что она составляет 94 процента от общей стоимости запроса. Исходя из этой стоимости, мы получаем представление о том, с чего начать, чтобы улучшить производительность.

Для больших запросов это может быть сложной задачей, так как возможно использование значительного количества операторов, как в приведенном ниже плане. Но мы видим, что здесь присутствует операция Sort (сортировка), которая занимает 91% времени выполнения запроса. То есть, большая часть времени запроса тратится именно на эту операцию. Это может свидетельствовать о том, что сортировка выполняется неэффективно или что есть потенциал для оптимизации данной операции.
В целом, выявление операции сортировки, которая занимает большую часть времени выполнения запроса, является важным шагом в процессе оптимизации запросов. Она может указать на участок, который требует внимания и оптимизации для улучшения производительности запроса.

Если вы работаете с Azure Data Studio, то в нем присутствует функциональный компонент — Operations grid (операционная сетка). Этот инструмент облегчает администрирование баз данных и отладку запросов, предоставляя детальную информацию о том, как база данных взаимодействует с запросами и операциями.

Посмотрите на предупреждения
Для некоторых операций генерируются предупреждения, которые определяются по желтому символу, как показано ниже. Если навести курсор на операцию, то можно увидеть подробную информацию о предупреждении.
В приведенном ниже примере речь идет о предупреждении «implicit conversion» (неявное преобразование).
Предупреждение «implicit conversion» относится к ситуации, когда система управления базами данных (СУБД) автоматически выполняет преобразование одного типа данных в другой без явного указания программиста или пользователя. Это может произойти, когда в SQL-запросе сравниваются или выполняются операции с данными разных типов.
В нашем примере речь идет о предупреждении «implicit conversion» в контексте операции сравнения или фильтрации данных. Оно может указывать на потенциальное место для оптимизации запроса, например, путем явного указания типов данных или преобразований, чтобы избежать implicit conversion и улучшить производительность и предсказуемость запроса.

Вот еще один пример, который показывает предупреждение о «high memory grant» (высоком выделении памяти). Такая ситуация возникает, когда запрос требует выполнения сложных операций со значительным объемом информации или используется большое количество временных структур данных в памяти.

Стрелки между операторами предоставляют ценную информацию
Стрелки дают информацию о предполагаемом и фактическом количестве строк и объеме данных, передаваемых между операторами. Чем толще стрелка, тем больше данных и строк передается между операторами.
Для одного и того же запроса размер стрелки может быть разным в зависимости от значения параметра, которое было использовано.
Здесь показана более крупная стрелка, и при наведении на нее мы можем увидеть подробности и большое количество строк.

Если мы снова выполним запрос, используя другое значение параметра, то увидим, что размер стрелки уменьшается и отображает только 1 строку.

Окно свойств плана выполнения
Окно свойств плана выполнения — это инструмент, предоставляющий дополнительные сведения и подробности о конкретном операторе в плане выполнения SQL-запроса. Оно позволяет пользователям получить более глубокое понимание о том, как выполняется запрос и какие ресурсы используются при его выполнении.
Чтобы воспользоваться окном свойств плана выполнения, обычно нужно выполнить следующие шаги:
Открыть план выполнения запроса в инструменте управления базой данных, таком как SQL Server Management Studio или Azure Data Studio.
Выбрать конкретный оператор или часть плана выполнения, который вас интересует, кликнув по нему правой кнопкой мыши.
В контекстном меню выбрать опцию «Properties » (Свойства) или аналогичную команду.

После этого откроется окно свойств, которое содержит детальную информацию о выбранном операторе или части плана выполнения. Оно может включать в себя статистику, оценки ресурсов, использование индексов, структуры данных и другие параметры, которые помогают анализировать и оптимизировать запрос.

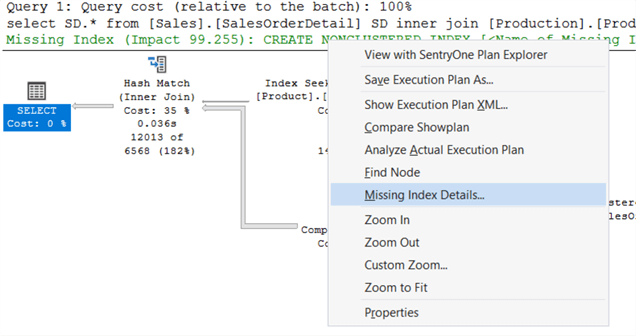
Рекомендации по индексам
В некоторых случаях план выполнения может предложить создать индексы для того, чтобы оптимизировать выполнение запроса. Эти рекомендации отображаются зеленым текстом, как показано ниже.

Если вы кликните правой кнопкой мыши и выберете «Missing Index Details» (Сведения о недостающем индексе), то получите информацию и скрипт для создания нового индекса. Я рекомендую сначала оценить предложения и просмотреть уже существующие индексы перед созданием, чтобы избежать их дублирования.
Прежде чем создавать рекомендуемый индекс, важно проанализировать рекомендации и убедиться, что они действительно улучшат производительность запроса. Рассмотрите, какие именно столбцы таблицы включены в индекс, и учтите, что создание слишком многих индексов по одной таблице может увеличить накладные расходы при обслуживании базы данных.
После создания индекса желательно провести тестирование запросов, чтобы убедиться, что производительность улучшилась, и следить за использованием индекса в продакшн-среде с помощью мониторинга.
SARGABLE запросы
Большинство запросов в продакшне содержат определенный фильтр, чтобы уменьшить количество возвращаемых строк данных. Вот почему наличие правильных индексов так важно. Однако не все сводится только к наличию индекса. Также необходимо убедиться, что запрос использует индексы эффективно.
Для эффективного использования индексов запрос должен быть SARGable (search + argument + able). Это означает, что аргумент поиска (например, в предложении WHERE) может успешно использовать индекс. Здесь очень важна структура запроса, и для решения данной проблемы чаще всего требуется изменение кода.
Например, для следующего простого запроса мы хотим получить информацию, где фамилия начинается с буквы «A».

Даже если используется правильный индекс, выполняется index scan (сканирование индекса), как показано ниже, поскольку аргумент в предложении WHERE не является sargable. Система не может гарантировать, что функция substring (подстроки) вернет верное значение. Также она не может «угадать», что именно вернется, поэтому и используется сканирование, чтобы проверить каждую строку индекса.

Если вы модифицируете запрос, чтобы убрать функцию и переместить манипуляции с данными на сторону параметра, это означает, что вместо того, чтобы применять операции и функции к данным внутри запроса, вы предварительно обрабатываете данные до того, как передаете их в сам запрос.
Это будет выглядеть следующим образом:

Тогда движок (система) может напрямую извлекать необходимые значения с использованием index seek (индексного поиска), поскольку ему не нужно угадывать, какие значения есть в столбце.
Index seek (индексный поиск) — это метод доступа к данным в системе управления базами данных (СУБД), который позволяет непосредственно находить нужные значения в индексе, так как теперь запрос стал SARGable и использует точное значение из переменной @StartChar. Системе не нужно сканировать весь индекс, она может точно найти соответствующие записи.
Давайте разберемся более подробно:
Индекс в базе данных: Для того чтобы понять индексный поиск, важно понимать, что в базе данных могут быть созданы индексы. Индексы представляют собой структуры данных, которые ускоряют поиск и фильтрацию записей в таблице.
SARGable запросы: Термин «SARGable» означает, что запрос можно оптимизировать с использованием индексов. Это возможно, когда запрос использует точные значения, а не сложные вычисления или функции, которые затрудняют использование индексов.
Переменная @StartChar: В нашем контексте, @StartChar является параметром, который содержит точное значение, и запрос использует это значение при фильтрации данных.
Когда запрос становится SARGable и использует точное значение из переменной @StartChar, СУБД может выполнить индексный поиск следующим образом:
Она определяет, какой индекс подходит для запроса, и выбирает тот индекс, который содержит столбец, соответствующий нашему условию (в данном случае, связанный с символами или строками, начинающимися с определенного символа).
Затем СУБД непосредственно ищет значения в этом индексе, используя точное значение из переменной @StartChar. Она может быстро найти соответствующие записи, не сканируя весь индекс, благодаря структуре индекса и оптимизации индексного поиска.
Этот метод обеспечивает быстрый и эффективный доступ к данным и позволяет избежать сканирования больших объемов данных, что способствует улучшению производительности запроса.
Итак, модификация запроса таким образом, чтобы он стал SARGable, позволяет использовать index seek, что может значительно улучшить производительность запроса и сократить количество ресурсов, затрачиваемых на его выполнение.

Распределение данных
Если по каким-то причинам запрос выполняется иногда быстрее, а в других случаях значительно медленнее, это может быть связано с изменением данных или с их распределением.
Можно проверить таблицы, включенные в запрос, и если на каком-либо этапе выполнения возвращается большой датасет, то надо проанализировать статистику распределения. С ее помощью получится оценить, как распределены данные.
Когда статистика покажет, что данные сосредоточены в определенных сегментах и частях таблицы, это и станет местом для улучшений.
Получить доступ к такой информации можно, развернув таблицу в SQL Server Management Studio (SSMS) и в разделе Statistics (Статистика) выбрав один из элементов, кликнув правой кнопкой мыши и выбрав Properties (Свойства). Затем смотрите страницу Details (Детали).
На примере ниже мы видим, что данные распределены вполне равномерно, без каких-либо отдельных областей, в которых содержится большая часть строк.

Вы также можете получить такую же информацию, выполнив следующую команду, указав в качестве двух параметров имя таблицы и статистики:

Качественный проект базы данных должен предусматривать очистку данных и перенос истории в какую-либо архивную систему. Меньший по размеру датасет облегчает операции объединения (joins) и фильтрации, а также выполнение технического обслуживания.
Метрики производительности
Помимо того, что мы обсудили выше, существует множество других инструментов, которые могут помочь определить причину медленной работы запросов. Возможно, проблема заключается вовсе не в запросе, а в чем-то другом.
Существует несколько бесплатных инструментов, которые можно использовать для сбора текущей статистики и данных, например sp_whoisactive, SQL Server First Responder Kit или wait stats query (запрос по статистике ожидания). С их помощью можно выявить запросы, выполняющиеся в течение длительного времени, высокую загрузку процессора, статистику ожидания и многое другое.
Также можно использовать такие средства, как SQL Performance Counters, Extended Events и Query Store. Чтобы отслеживать прошлое и иметь доступ к историческим данным, можно настроить процессы сбора данных на периодической основе. Такой процесс называется регистрацией данных или аудитом.
SQL Performance Counters (Счетчики производительности SQL):
SQL Performance Counters — это собранные и доступные для мониторинга системные метрики и статистика, связанные с производительностью SQL Server.
Они предоставляют информацию о различных аспектах работы SQL Server, таких как использование процессора, объем используемой памяти, количество запросов и блокировок, а также многое другое.
Счетчики производительности могут быть использованы администраторами для мониторинга и настройки производительности SQL Server.
Extended Events (Расширенные события):
Extended Events — это механизм SQL Server для сбора и анализа информации о событиях, происходящих в базе данных и сервере.
Они предоставляют более гибкий и детальный способ мониторинга и трассировки запросов и событий в SQL Server.
Extended Events могут быть использованы для отслеживания выполнения запросов, блокировок, ошибок и других событий, которые могут влиять на производительность.
Query Store (Хранилище запросов):
Query Store — это интегрированный компонент SQL Server, предназначенный для управления и мониторинга производительности запросов.
Он сохраняет историю выполнения запросов, планов выполнения и статистику запросов, что позволяет анализировать и оптимизировать запросы с течением времени.
Query Store позволяет обнаруживать изменения в производительности запросов, исследовать проблемы и принимать меры для их решения.
Я бы не стал тратить много времени на создание собственных инструментов, поскольку существует множество сторонних средств для настройки производительности, с помощью которых можно достичь желаемого результата.
Если вы используете базу данных Azure SQL, то в Azure Portal есть встроенные метрики производительности, которые могут быть применены для мониторинга и анализа работы вашей базы данных. Эти метрики предоставляют информацию о различных аспектах производительности и состоянии вашей базы данных в облаке Azure, как показано на примере ниже.

Новые возможности SQL Server
С каждой версией SQL Server добавляются новые возможности для повышения эффективности выполнения запросов. Ниже приведены некоторые из усовершенствований, появившихся в SQL Server 2017 и SQL Server 2019.

источник изображения
Вот их краткие объяснения:
Adaptive QP (Query Processing): Адаптивная обработка запросов позволяет SQL Server адаптироваться к изменяющимся условиям выполнения запросов, выбирая различные стратегии выполнения.
Adaptive Joins: Оптимизация выполнения запросов, при которой SQL Server может выбирать между различными типами объединений (например, соединение по хешу или по вложенным циклам) на основе статистики данных и производительности.
Interleaved Execution: Метод выполнения запросов, при котором несколько операторов запроса выполняются параллельно, что может улучшить производительность.
Memory Grant Feedback (Обратная связь о выделении памяти): Оптимизация, предназначенная для улучшения производительности запросов, которые выполняются в среде с ограниченным объемом оперативной памяти. Обратная связь — механизм, который позволяет SQL Server адаптироваться к производительности запросов на основе предыдущих выполнений.
Batch Mode: Режим выполнения запросов, при котором данные обрабатываются пакетами, что может улучшить производительность в операциях сканирования и агрегации больших объемов данных.
Intelligent QP (Query Processing): Интеллектуальная обработка запросов — набор функций и оптимизаций, которые делают выполнение запросов более эффективным и адаптивным.
Table Variable Deferred Compilation: Оптимизация, связанная с использованием временных переменных типа таблицы (table variable) в SQL-запросах и отложенной компиляцией (deferred compilation). Table variable используется для временного хранения данных в пределах одной процедуры, функции или пакета SQL. Она представляет собой таблицу, определенную как переменная и может использоваться для хранения и манипулирования данными, аналогично обычным таблицам в базе данных. Отложенная компиляция — метод оптимизации, при котором компиляция SQL-запроса происходит при первом выполнении, а не при создании запроса.
Batch Mode on Rowstore: Оптимизация, которая позволяет использовать режим пакетной обработки (Batch Mode) для операций обработки данных на обычных (rowstore) таблицах. Ранее режим пакетной обработки использовался преимущественно для работы с колоночными хранилищами данных (columnstore), но с внедрением Batch Mode on Rowstore, он стал доступен и для обычных строковых таблиц. Row Store — хранение данных в виде строк, что является одним из способов организации данных в таблицах.
T-SQL Scalar UDF (User-Defined Function) Inlining: Оптимизация, которая позволяет встроить (inline) код скалярных пользовательских функций (scalar UDF) непосредственно в текст SQL-запроса во время компиляции. Она позволяет улучшить производительность запросов, содержащих скалярные функции, и избежать накладных расходов, связанных с вызовами функций.
Approximate QP (Query Processing): Обработка запросов с использованием приближенных алгоритмов, которые могут быть менее точными, но более быстрыми.
Approximate Count Distinct: Приближенное вычисление уникальных значений в столбце, что может улучшить производительность при анализе больших объемов данных.
Row Mode: Режим выполнения запросов, при котором операции обработки данных выполняются на уровне отдельных строк данных в таблицах. Этот режим предназначен для операций, которые обрабатывают данные по одной строке за раз.
Microsoft реализовала некоторые функциональные возможности искусственного интеллекта и машинного обучения, поэтому в зависимости от рабочей нагрузки сервер способен адаптироваться к вашим потребностям и вносить улучшения без каких-либо дополнительных усилий с вашей стороны. У нас сейчас не получится рассказать о каждой из этих фич, но вы можете прочитать больше об интеллектуальной обработке запросов в базах данных SQL.
Начиная с SQL Server 2017 доступна автоматическая настройка, и эта возможность позволяет выявлять проблемы с производительностью запросов и автоматически вносить изменения в конфигурацию, например:
Automatic plan correction (Автоматическая коррекция плана) — при возникновении регрессии плана (частой причиной является parameter sniffing). Parameter sniffing (прослушивание параметров) — это процесс, при котором SQL Server оптимизирует план выполнения на основе конкретных значений параметров при первом выполнении запроса. Когда система обнаруживает, что текущий план выполнения стал неэффективным из-за регрессии, она может принудительно вернуть выполнение к последнему известному хорошему плану. Это происходит автоматически без необходимости вмешательства администратора базы данных или разработчика
Automatic index management (Автоматическое управление индексами) — (только для Azure SQL), если эта функция включена, она автоматически добавляет или удаляет индексы в зависимости от их использования.
Следующие шаги
