[Перевод] Полив газона с помощью модели сегментации изображений и системы на базе Arduino

Инженерная цель данного эксперимента заключалась в разработке системы из трёх частей, а именно модели сегментации изображения, скрипта управления двигателем и спринклера, работающего под управлением Arduino. Эта система должна целенаправленно поливать участки травяного газона, что позволит сэкономить значительное количество воды, а заодно и времени.
Задача
Представьте, что вы прогуливаетесь по своему кварталу мимо красивых зелёных лужаек. Что такое?… Вода же должна литься на газон, а не на тротуар рядом! Здесь люди ходят! Слева от вас большой газон орошается из-под земли десятком спринклеров. Но, хоть вся трава и поливается обильно, на газоне тут и там заметны проплешины. Многие не видят в этом проблемы — эка невидаль! — и безмятежно прыгают через лужи. Но проблема здесь не только в лужах, а в том, что, несмотря на использование такого количества воды, газон всё равно не растёт нормально. И проблема эта более серьёзная, чем можно подумать. В Америке от 30 до 60% городской пресной воды используется для полива газонов, и самое печальное, что приблизительно 50% этой воды тратится впустую из-за небрежно или неправильно установленной системы полива.
Уход за газонами — недешёвое занятие. Чтобы газоны росли так, как нужно, необходимо правильно подобрать удобрения, компост и, самое главное, правильно их поливать. В этой статье я расскажу о разработанном мною решении — какие шаги я предпринял при планировании, создании прототипа и внедрении.
Первоначальные соображения
В начале этого проекта у меня не было ни опыта работы с методами машинного распознавания образов, не говоря уже о каком-никаком плане.
 Сухие проплешины.
Сухие проплешины.Разница в цвете между светло-коричневыми участками и зеленью здоровой травы сразу бросается в глаза. Я начал решать задачу так: проанализировал RGB-значения различных областей изображения. Если бы я мог выявлять «менее зелёные» области и найти критерий, по которому такие участки можно было выделять, я мог бы их точно определить. Однако всё оказалось не так просто, как я думал.
Главной проблемой было множество внешних факторов, на которые я повлиять не мог, но они могли сами повлиять на результаты. Например, RGB-значение участка изображения может быть изменено ночным электрическим освещением. При таком количестве посторонних факторов система была бы просто нежизнеспособна. Мне определённо нужно было искать лучшее решение.
Сегментация изображений
Новое решение оформилось в виде концепции, называемой сегментацией изображения. Сегментация изображений — это процесс машинного распознавания образов, разделяющий изображения на «сегменты» на основе сходства пикселей. В основном он используется, чтобы обнаруживать на изображении объекты (в таком случае он называется методом обнаружения объектов), и применяется в автономных транспортных средствах, при обработке медицинских изображений и спутниковой съёмке.
 Сегментация изображений.
Сегментация изображений.Используя метод сегментации изображений, я смог бы обнаружить проплешины на газоне. И я засел за изучение методов создания моделей сегментации изображений с помощью Tensorflow.
Я обнаружил замечательную библиотеку под названием ImageAI, написанную Олафенвой Мозесом. Библиотека ImageAI позволяет обнаруживать объекты с использованием набора данных, созданного пользователем. С помощью ImageAI мне удалось подобрать оптимальный набор данных, наиболее подходящий для моей модели.
Первый набор данных / Тестовый
Методы машинного обучения работают только в том случае, если в них заложены данные. Без большого количества точных и осмысленных данных обучать модели и получать прогнозы об окружающем нас мире практически невозможно. Если мы хотим хорошо обучить студента, мы должны предоставить ему как можно больше ресурсов, чтобы обучение было эффективным.
Бесплатные общедоступные наборы данных можно найти на множестве веб-сайтов и во многих приложениях. Эти данные, в частности, могут использовать инженеры при работе над проектами. Однако для моего проекта никаких наборов данных не было, и поэтому мне пришлось создавать свои собственные. Как выяснилось, создание набора данных оказалось чуть ли не самой сложной проблемой во всём проекте.
Набор данных для сегментации изображений состоит из двух частей: изображений и аннотаций. Существует множество способов аннотирования изображений, то есть пометок места расположения объекта на изображении. Я использовал формат Pascal VOC, сохраняющий аннотации в файлах .xml. То есть, если мой набор данных содержит 50 изображений, мне пришлось бы аннотировать каждое отдельное изображение и создать 50 xml-файлов с аннотациями соответствующих изображений.
Вначале у меня было много вопросов о наборе данных: сколько изображений нужно иметь, как аннотировать изображение, как использовать аннотацию в коде, как узнать, подходит ли для модели то или иное изображение, и так далее. Тут мне здорово помог Олафенва Мозес, который, к счастью, написал очень информативную статью о том, как создавать пользовательский набор данных и использовать его в библиотеке ImageAI.
Первым шагом было получение изображений, и он оказался значительно сложнее, чем предполагалось. Как я ни старался, я не смог найти в сети нужные мне высококачественные изображения. Я погуглил строку «трава с проплешинами», и для первого набора данных мне удалось загрузить всего 65 изображений. Чтобы вы понимали — большинство наборов данных содержат тысячи изображений, и только тогда их имеет смысл использовать для обучения модели.
После сбора изображений я закомментировал их с помощью программы Label IMG. Я создал каталог с изображениями и каталог для аннотаций. Затем я поставил аннотацию к каждому изображению, обведя в рамки все проплешины. Привожу ниже скриншот программы Label IMG, которую я использовал для аннотирования изображений.
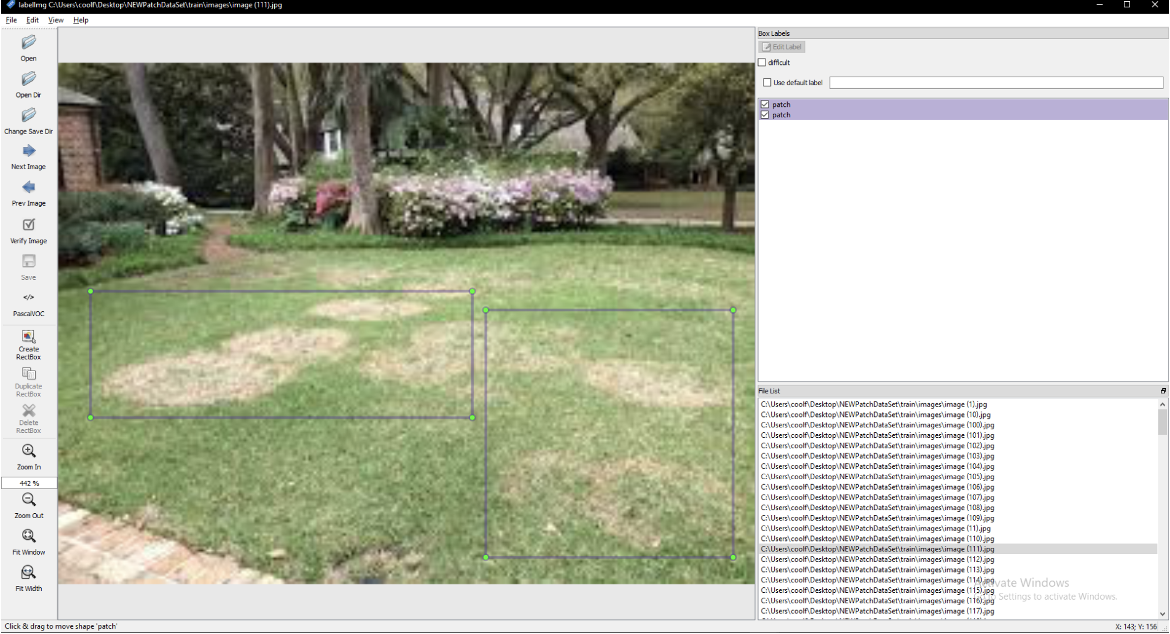 Программа Label IMG.
Программа Label IMG.Я, наконец, получил полный набор данных с аннотациями и изображениями и был готов приступить к обучению своей модели. С набором данных и загруженными библиотеками у меня возникло много проблем, но мне удалось их решить, и я обучил свою первую модель за 15 эпох с размером пакета 4.
 Набор данных 1. Результаты.
Набор данных 1. Результаты.После тестирования модели на изображении моей лужайки перед домом у меня получился вот такой результат. Я так долго не мог добиться, чтобы программа хотя бы доходила до конца без ошибок, что был в восторге даже от того, что она, наконец, обвела проплешину рамкой! То, что полученный результат был ужасен и абсолютно бесполезен для работы системы, я понял уже позднее. Модель, в принципе, способна обозначать область с плохой травой. Однако получившиеся границы очень неточны, и такой результат практически бесполезен.
Наборы данных 2–4 / Последующие тесты
После оценки полученных на первом наборе данных результатов стало очевидно, что для правильной разработки модели мне не хватает изображений. Я понял, что мне нужно гораздо больше данных, но загружать изображения вручную… нет уж, увольте.
Полистав Интернет, я обнаружил такую вещь, как парсеры (web scrapers). Парсер — это инструмент, способный извлекать данные и содержимое с веб-сайтов и загружать эти файлы на локальный компьютер. Это было как раз то, что мне нужно, и после изучения краткого руководства я создал элементарный парсер, загружающий изображения, содержащие ключевые слова «трава с проплешинами», «плохая трава» и «плохой газон». С помощью этого парсера я собрал папку из 180 изображений, и это был мой второй набор данных.
После удаления всех непригодных изображений у меня получился третий набор данных из 160 изображений. После обучения модели на третьем наборе данных результаты всё равно оставались нестабильными и неточными. Как и в прошлый раз, я подумал, что главная проблема заключается в отсутствии достаточного количества изображений в наборе.
Я обратился кое к кому за помощью, поизучал ещё теорию и вычитал, что есть такой хитрый приём — аугментация изображений (image augmentation), то есть процесс, с помощью которого набор данных может быть расширен посредством внесения изменений в существующие изображения. Количество изображений меняется за счёт того, что меняются их ориентация и RGB-значения пикселей. Пример аугментации изображений.
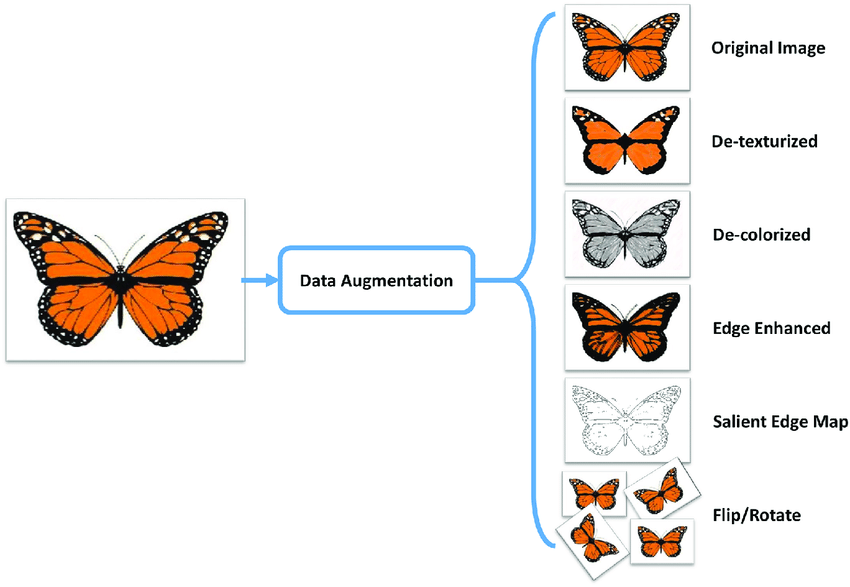 Пример аугментации изображений.
Пример аугментации изображений.
 Пример дополненных и реальных данных.
Пример дополненных и реальных данных.Для нас, людей, все приведённые выше изображения одинаковы, если не считать крохотных изменений; однако для компьютера, который рассматривает изображения как массивы значений пикселей, эти изображения совершенно разные. Попробуем использовать эту идею и создадим больше обучающих данных. И вот, я, страдавший от нехватки изображений, сразу получил их много больше, чем значительно улучшил свой набор данных. Для пополнения всего каталога изображений я использовал библиотеку Keras с определёнными параметрами и граничными значениями. Мой четвёртый набор данных содержал 300 изображений. Теперь я был уверен, что модель, наконец, заработает. Но неожиданно возникла ещё одна серьёзная проблема.
Проблема совместимости библиотек
В большинстве проектов по программированию, особенно проектов в области анализа и обработки данных, для работы определённых функций и инструментов требуется ряд библиотек и зависимостей. В этом конкретном проекте библиотека ImageAI потребовала установки определённых версий различных библиотек, в том числе tensorflow-gpu 1.13 и keras 2.4.
Разные версии библиотеки отличаются одна от другой, причём использование разных версий может повлиять на взаимодействие между библиотеками. В моём случае это было особенно актуально, так как обучение и работа модели были возможны только при использовании определённых версий библиотек.
В январе вышло обновление библиотеки ImageAI, и оно сразу поставило крест на работе других библиотек, которые я использовал в проекте, — оно было просто несовместимо с ними. И вот, время обучения, обычно составлявшее около 5 минут на эпоху, стало составлять более 14 часов. Кроме того, модель постоянно перестраивалась под данные, а это свидетельствовало о том, что она была неспособна генерализовывать новые данные.
Сначала я подумал, что такое длительное время обучения обусловлено большим количеством изображений в наборе данных, но скоро стало очевидно, что проблема кроется не в этом и она более серьёзная. Я ещё раз обратился к учебникам, но ничего путного найти не смог. Если бы вы знали, сколько различных вариантов я перепробовал, чтобы устранить проблему!… Я пробовал менять способы извлечения набора данных, менять аппаратный ускоритель, менять размер пакета… Ни один из этих вариантов не снизил время обучения модели.
Но тут я наткнулся на недавно опубликованный пост в разделе проблем и вопросов на Github, в котором кто-то жаловался на такую же точно проблему, как и у меня. Олафенва Мозес, создатель библиотеки, ответил на это пост и объяснил проблему, предложив собственное решение. Суть этого решения была такой: три основные библиотеки — Tensorflow, Keras и ImageAI — должны иметь чётко определённые версии.
Окончательный набор данных / Модель
После избавления от предыдущей проблемы я сначала протестировал набор данных из 300 изображений. Результаты улучшились, но ненамного, им не хватало стабильности. На некоторых изображениях газона с разных углов моя модель вообще не смогла обнаружить проплешин.
 Набор данных 4. Результаты.
Набор данных 4. Результаты.Я решил добавить ещё больше данных и в итоге получил набор из 1738 изображений. Чтобы обучить модель, мне пришлось аннотировать каждое изображение, вручную очерчивая участки на каждом из них. К счастью, этой работой я занимался не один, а с друзьями. Менее чем за два часа нам удалось аннотировать все изображения.
Окончательный набор данных был разделён на 1400 тренировочных и 338 тестовых изображений. После обучения модели за 5 эпох я провел валидацию и получил впечатляющий результат — 0,7204, что, безусловно, стало моим лучшим результатом с начала проекта.
 Набор данных 5. Результаты.
Набор данных 5. Результаты.Окончательный результат работы модели меня, наконец, удовлетворил. После обучения модели я приступил к разработке прототипа системы, которая могла бы целенаправленно поливать участки газона.
Создание спринклера
 Схема системы.
Схема системы.Чтобы контролировать полив, мне нужно было обеспечить вращение спринклера по двум осям — так я мог бы контролировать расстояние и направление разбрызгивания воды. Я использовал два шаговых двигателя NEMA с разными характеристиками мощности и крутящего момента. Нижний двигатель NEMA-23 использовался для управления направлением разбрызгивания воды. Верхний двигатель NEMA 14 вращал стержень с закреплённым на нём с помощью трубки из ПВХ спринклером, чтобы можно было управлять расстоянием, на которое разбрызгивается вода. Для управления этими двигателями я использовал Arduino, два регулятора частоты вращения двигателя A4988 и два адаптера питания 12 В.
Если бы я мог выяснить, на какое расстояние разбрызгивается вода и на какой угол поворачивается спринклер за определённое количество шагов, я мог бы рассчитать коэффициенты преобразования шагов в углы и шагов — в расстояние. Для того чтобы можно было использовать такие коэффициенты преобразования, мне потребовался скрипт, определяющий фактическое расстояние до проплешины и угол, на который надо повернуть спринклер для полива.
Я рассчитал угол, на который необходимо повернуть спринклер от начального места до центра проплешины, определил приблизительное количество пикселей/футов на моём изображении и после этого вычислил приблизительное расстояние до центра проплешины.
 Результат работы скрипта управления двигателем.
Результат работы скрипта управления двигателем.На рисунке выше показаны результаты работы скрипта управления двигателем. Их них следует, что спринклер должен повернуться на 42°, а расстояние до проплешины составляет примерно 3 м 89 см.
 Согласно скрипту угол до проплешины составляет 42°.
Согласно скрипту угол до проплешины составляет 42°.
Длина рулетки — 3 м (10 футов); от центра проплешины до спринклера — примерно 12 футов 9 дюймов (3,8862 м), как и предсказал скрипт.
Я выполнил несколько тестов для определения коэффициентов преобразования шагов в углы и шагов — в футы, и это позволило мне создать скрипт Arduino для ориентирования спринклера на проплешину с использованием данных скрипта управления двигателем.
Готовность к окончательному тестированию
К сожалению, всю систему в итоге мне протестировать не удалось.
Перед окончательным тестом я стал проверять готовую конструкцию, чтобы убедиться, что она способна держать спринклер и поворачивать его. Но я был очень неосторожен: в моторы попала вода, и они сгорели. Двигатели были довольно дорогими, а покупать новые было непрактично.

Анализ кода / Краткий обзор
Google Colab PatchDetector
PatchDetector на Github
!wget https://github.com/fazalmittu/PatchDetection/raw/master/BlackedOutLawn.jpg
!wget https://github.com/fazalmittu/PatchDetection/raw/master/BlackedOutLawn_Detected.jpg
!wget https://github.com/fazalmittu/PatchDetection/releases/download/v3.0/detection_model-ex-04--loss-25.86.h5
!wget https://github.com/fazalmittu/PatchDetection/releases/download/v3.0/detection_config1700_v1.json
!wget https://github.com/fazalmittu/PatchDetection/raw/master/BlackedOutFullLawn.jpg
!wget https://github.com/fazalmittu/PatchDetection/raw/master/BlackedOutFullLawn_Detected.jpg
!wget https://github.com/fazalmittu/PatchDetection/raw/master/SprinklerPOV.jpg
!wget https://github.com/fazalmittu/PatchDetection/raw/master/SprinklerPOV_Detected.jpg
!wget https://github.com/OlafenwaMoses/ImageAI/releases/download/essential-v4/pretrained-yolov3.h5Этот код используется для импорта модели и изображений (для тестирования), которые я хранил на Github, чтобы их можно было легко извлечь с помощью Google Colab. Последняя строка — импортирование предварительно обученной модели YOLO-v3, которая, в свою очередь, использовалась для обучения модели (трансферное обучение).
!pip uninstall -y tensorflow
!pip install tensorflow-gpu==1.13.1
!pip install keras==2.2.4
!pip install imageai==2.1.0
!pip install numpyЭтот код импортирует определённые версии библиотек, необходимых при проектировании. Используемые библиотеки: tensorflow-gpu, keras, imageai и numpy.
%load_ext autoreload
%autoreload 2
from google.colab import drive
import sys
from pathlib import Path
drive.mount("/content/drive", force_remount=True)
base = Path('/content/drive/MyDrive/PatchDetectorProject/')
sys.path.append(str(base))
zip_path = base/'AugmentedDataSetFinal.zip'
!cp "{zip_path}" .
!unzip -q AugmentedDataSetFinal.zip
!rm AugmentedDataSetFinal.zipЭтот код используется для получения набора данных из места, которое я определил для него на Google-диске. Для сохранения на Github набор данных был слишком велик, поэтому мне пришлось использовать альтернативный источник.
from imageai.Detection.Custom import DetectionModelTrainer
from __future__ import print_function
trainer = DetectionModelTrainer()
trainer.setModelTypeAsYOLOv3()
trainer.setDataDirectory(data_directory="AugmentedDataSetFinal")
trainer.setTrainConfig(object_names_array=["patch"], batch_size=4, num_experiments=5, train_from_pretrained_model="pretrained-yolov3.h5")
trainer.trainModel()В этом коде осуществляется обучение модели. В нём указывается объект для поиска («patch» (проплешина)), количество эпох (5), размер пакета (4) и используется трансферное обучение.
from imageai.Detection.Custom import DetectionModelTrainer
trainer = DetectionModelTrainer()
trainer.setModelTypeAsYOLOv3()
trainer.setDataDirectory(data_directory="AugmentedDataSetFinal")
trainer.evaluateModel(model_path="AugmentedDataSetFinal/models", json_path="AugmentedDataSetFinal/json/detection_config.json", iou_threshold=0.5, object_threshold=0.3, nms_threshold=0.5)Этот код используется для валидации модели. С окончательной моделью я получил оценку 72,04%. Я считаю этот результат очень хорошим, учитывая, что обнаруживаемые мною объекты представляют собой проплешины без определённой формы, цвета или размера.
from imageai.Detection.Custom import CustomObjectDetection
from PIL import Image, ImageDraw
import numpy as np
detector = CustomObjectDetection()
detector.setModelTypeAsYOLOv3()
detector.setModelPath("/content/detection_model-ex-04--loss-25.86.h5")
detector.setJsonPath("/content/detection_config1700_v1.json")
detector.loadModel()
detections = detector.detectObjectsFromImage(input_image="SprinklerPOV.jpg", output_image_path="SprinklerPOV_Detected.jpg", minimum_percentage_probability=30)
i = 0
coord_array = []
for detection in detections:
coord_array.append(detection["box_points"])
print(detection["name"], " : ", detection["percentage_probability"], " : ", detection["box_points"])
i+=1
print(coord_array)
detected = Image.open("SprinklerPOV_Detected.jpg")
box = ImageDraw.Draw(detected)
for i in range(len(coord_array)):
box.rectangle(coord_array[i], width=10)
detectedВ этом коде я тестирую модель на новом изображении, чтобы проверить, сможет ли она найти проплешину. После этого, если проплешина будет найдена, модель сохраняет её координаты пикселей в массив, который будет использоваться скриптом управления двигателем.
!wget https://github.com/fazalmittu/PatchDetection/raw/master/FeetToPixel.JPG
img_ft = Image.open("FeetToPixel.JPG")
ft_line = ImageDraw.Draw(img_ft)
ft_line.line([(175, 1351), (362, 1360)], fill=(0, 255, 0), width=10)
ft_distance = np.sqrt(9*9 + 187*187)
print(ft_distance)
img_ftС этого кода начинается скрипт управления двигателем. Код импортирует изображение, на нём — разложенная на траве рулетка. Я использовал это изображение для определения примерного количества пикселей в футе.
 Пиксели/футы.
Пиксели/футы.from PIL import Image, ImageDraw
#TOP LEFT = [0, 1]
#BOTTOM LEFT = [0, 3]
#TOP RIGHT = [2, 1]
#BOTTOM RIGHT = [2, 3]
img = Image.open("SprinklerPOV_Detected.jpg")
middle_line = ImageDraw.Draw(img)
avg_1Line = ImageDraw.Draw(img)
avg_2Line = ImageDraw.Draw(img)
avg_1 = (coord_array[1][1] + coord_array[1][3])/2
avg_2 = (coord_array[1][0] + coord_array[1][2])/2
middle_line.line([(2180, 0), (2180, 3024)], fill=(0, 255, 0), width=10)
# avg_1Line.line([(coord_array[1][0], coord_array[1][1]), (coord_array[1][0], coord_array[1][3])], fill=(255, 0, 0), width=10)
# avg_2Line.line([(coord_array[1][0], coord_array[1][3]), (coord_array[1][2], coord_array[1][3])], fill=(255, 0, 0), width=10)
def find_angle():
line_to_patch = ImageDraw.Draw(img)
line_to_patch.line([(avg_2, avg_1), (2180, 3024)], fill=(255, 0, 0), width=10)
length_1_vertical = 3024 - avg_1
length_2_horizontal = 2500 - avg_2
print("Distance = ", np.sqrt(length_1_vertical*length_1_vertical + length_2_horizontal*length_2_horizontal)/ft_distance, "ft")
angle_radians = np.arctan(length_2_horizontal/length_1_vertical)
angle = (180/(np.pi/angle_radians)) #Convert radians to degrees
return angle
print(avg_1, avg_2)
print(find_angle())
imgЭтот код используется для определения угла до проплешины. Я нарисовал треугольник от центра проплешины до места, где вначале находился спринклер. Для определения угла до центра проплешины я воспользовался тригонометрическими формулами и координатами каждой из точек. Для определения расстояния до центра проплешины в футах я также использовал тригонометрические функции и коэффициент пересчёта пикселей в футы.
/*
*
* Fazal Mittu; Sprinkler Control
*
*/
const int ROTATEstepPin = 3;
const int ROTATEdirPin = 4;
const int ANGLEstepPin = 6;
const int ANGLEdirPin = 7;
const int ROTATEangle = 42.25191181;//TODO: Find Conversion: Steps --> Angle 1000 steps = 90 degrees
const int ANGLEangle = 12.76187539;// pixels --> ft: 187 pixels = 1 feet
bool TURN = true;
float angleToSteps(float angle){
float steps = 1000/(90/angle);
return steps;
}
float ftToSteps(float feet) {
float steps = 100/(8/feet);
return steps;
}
void setup() {
Serial.begin(9600);
pinMode(ROTATEstepPin,OUTPUT);
pinMode(ROTATEdirPin,OUTPUT);
pinMode(ANGLEstepPin,OUTPUT);
pinMode(ANGLEdirPin,OUTPUT);
}
void loop() {
int ROTATEsteps = angleToSteps(ROTATEangle); //Angle was determined using Python Script
int ANGLEsteps = angleToSteps(ANGLEangle);
delay(7000);
if (TURN == true) {
for(int x = 0; x < ROTATEsteps; x++) {
digitalWrite(ROTATEstepPin,HIGH);
delayMicroseconds(500);
digitalWrite(ROTATEstepPin,LOW);
delayMicroseconds(500);
}
delay(5000);
for (int x = 0; x < 100; x++) { //100 steps = 8 ft, 0 steps = 14.5 ft
digitalWrite(ANGLEstepPin,HIGH);
delayMicroseconds(500);
digitalWrite(ANGLEstepPin,LOW);
delayMicroseconds(500);
}
}
TURN = false;
}Приведённый выше код использовался для управления обоими двигателями. Перед использованием любого кода сначала нужно определить взаимозависимости шаги/градусы и шаги/футы, что я и сделал посредством проведения тестов и измерений. В итоге у меня появился рабочий скрипт, который мог управлять работой двигателей в соответствии со значениями, полученными в результате работы скрипта управления.
Заключение
Даже несмотря на печальную судьбу двух двигателей, работа над этим проектом доставила мне истинное удовольствие. Я узнал, как собирать данные, как увеличивать количество изображений, как строить модели. Я понял, как интерпретировать результаты, как создавать систему управления, как подключать механические части, а также научился разгребать подводные камни на пути к успеху.
А если вы хотите научиться работать с данными и обрабатывать их помощью машинного обучения — обратите внимание на наш курс по ML или на его расширенную версию Machine Learning и Deep Learning, партнером которого является компания Nvidia.

Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
Другие профессии и курсыПРОФЕССИИ
КУРСЫ
