[Перевод] «Под капотом» индексов Postgres

Капитан Немо у штурвала «Наутилуса»
Индексы — один из самых мощных инструментов в реляционных базах данных. Мы используем их, когда нужно быстро найти какие-то значения, когда объединяем базы данных, когда нужно ускорить работу SQL-операторов и т.д. Но что представляют собой индексы? И как они помогают ускорять поиск по БД? Для ответа на эти вопросы я изучил исходный код PostgreSQL, отследив, как происходит поиск индекса для простого строкового значения. Я ожидал найти сложные алгоритмы и эффективные структуры данных. И нашёл.
Здесь я расскажу о том, как устроены индексы и как они работают. Однако я не ожидал, что в их основе лежит информатика. В понимании подноготной индексов также помогли комментарии в коде, объясняющие не только как работает Postgres, но и почему он так работает.
Алгоритм поиска последовательностей в Postgres демонстрирует странности: он зачем-то просматривает все значения в таблице. В моём прошлом посте использовался вот такой простой SQL-оператор для поиска значения «Captain Nemo»:

Postgres спарсил, проанализировал и спланировал запрос. Затем ExecSeqScan (встроенная функция на языке С, реализующая поиск последовательностей SEQSCAN) быстро нашла нужное значение:

Но затем по необъяснимой причине Postgres продолжил сканировать всю базу, сравнивая каждое значение с искомым, хотя оно уже было найдено!

Если бы таблица содержала миллионы значений, то поиск занял бы очень много времени. Конечно, этого можно избежать, если убрать сортировку и переписать запрос так, чтобы он останавливался на первом найденном совпадении. Но проблема более глубока, и заключается она в неэффективности самого механизма поиска в Postgres. Использование поиска последовательностей для сравнения каждого значения в таблице — процесс медленный, неэффективный и зависящий от порядка размещения записей. Должен быть другой способ!
Решение простое: нужно создать индекс.
Сделать это просто, достаточно выполнить команду: 
Разработчики на Ruby предпочли бы использовать миграцию add_index с помощью ActiveRecord, при которой была бы выполнена та же команда CREATE INDEX. Обычно, когда мы перезапускаем select, Postgres создаёт дерево планирования. Но в данном случае оно будет несколько отличаться:

Обратите внимание, что в нижней части используется INDEXSCAN вместо SEQSCAN. INDEXSCAN не будет сканировать всю базу в отличие от SEQSCAN. Вместо этого он использует только что созданный индекс, чтобы быстро и эффективно найти нужную запись.
Создание индекса позволяет решить проблему производительности, но не даёт ответов на ряд вопросов:
- Что именно представляет собой индекс в Postgres?
- Как именно он выглядит, какова его структура?
- Каким образом индекс ускоряет поиск?
Давайте ответим на эти вопросы, изучив исходники на языке С.
Начнём с документации для команды CREATE INDEX:
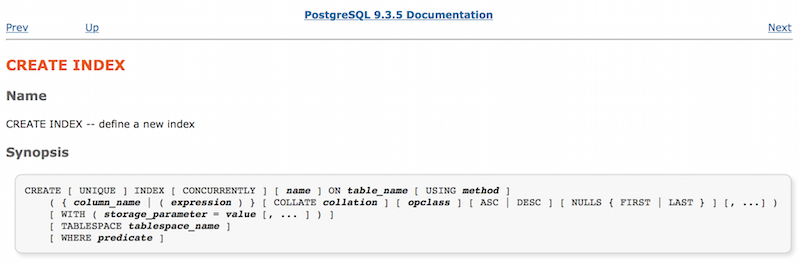
Здесь отображены все параметры, которые можно использовать при создании индекса. Обратите внимание на параметр USING method: он описывает, индекс какого вида нам нужен. На той же странице приведена информация о method, аргументе ключевого слова USING:

Оказывается, в Postgres реализовано четыре разных вида индексов. Их можно использовать для различных типов данных или в зависимости от ситуации. Поскольку мы не определяли параметр USING, то index_users_on_name по умолчанию представляет собой индекс вида «btree» (B-Tree).
Что такое B-Tree и где найти о нём информацию? Для этого изучим соответствующий файл с исходным кодом Postgres:

Вот что говорится о нём в README:

Кстати, сам README является 12-страничным документом. То есть нам доступны не только полезные комментарии в коде на С, но и вся необходимая информация о теории и конкретной реализации сервера БД. Чтение и разбор кода в opensource-проектах часто является непростой задачей, но только не в Postgres. Разработчики постарались облегчить нам процесс понимания устройства их детища.
Обратите внимание, что в первом же предложении есть ссылка на научную публикацию, в которой объяснено, что такое B-Tree (а значит, и как работают индексы в Postgres): Efficient Locking for Concurrent Operations on B-Trees за авторством Лемана (Lehman) и Яо (Yao).
В статье описывается улучшение, внесённое авторами в алгоритм B-Tree в 1981 году. Об этом мы поговорим чуть позже. Сам алгоритм был разработан в 1972 году, так выглядит пример простого B-Tree:

Название является сокращением от англ. «balanced tree». Алгоритм позволяет ускорить операцию поиска. Например, нам нужно найти значение 53. Начнём с корневого узла, содержащего значение 40:

Оно сравнивается с искомым значением. Поскольку 53 > 40, то далее мы следуем по правой ветви дерева. А если бы мы искали, например, значение 29, то пошли бы по левой ветви, потому что 29 < 40. Следуя по правой ветви, мы попадаем в дочерний узел, содержащий два значения:

На этот раз мы сравниваем 53 со значениями 47 и 62: 47 < 53 < 62. Обратите внимание, что значения внутри узлов отсортированы. Поскольку искомое значение меньше одного и больше другого, то далее мы следуем по центральной ветви и попадаем в дочерний узел, содержащий три значения:

Сравниваем со списком отсортированных значений (51 < 53 < 56), идём по второй из четырёх ветвей и наконец попадаем в дочерний узел с искомым значением:

За счёт чего этот алгоритм ускоряет поиск:
- Значения (ключи) внутри каждого узла отсортированы.
- Алгоритм сбалансирован: ключи равномерно распределены по узлам, что позволяет минимизировать количество переходов. Каждая ветвь ведёт к дочернему узлу, содержащему примерно такое же количество ключей, что и все остальные дочерние узлы.
Леман и Яо нарисовали свою диаграмму больше 30 лет назад, какое она имеет отношение к современному Postgres? Оказывается, созданный нами index_users_on_name очень похож на эту самую диаграмму. При выполнении команды CREATE INDEX Postgres сохраняет все значения из пользовательской таблицы в виде ключей дерева B-Tree. Так выглядит узел индекса:

Каждая запись в индексе состоит из структуры на языке С, называющейся IndexTupleData, а также содержит значение и битовый массив (bitmap). Последний используется для экономии места, в него записывается информация о том, принимают ли атрибуты индекса в ключе значение NULL. Сами значения следуют в индексе за битовым массивом.
Вот как выглядит структура IndexTupleData:

t_tid: это указатель на какой-либо другой индекс или запись в БД. Обратите внимание, что это не указатель на физическую память из языка С. Здесь содержатся данные, по которым Postgres ищет сопоставленные страницы памяти.
t_info: здесь содержится информация об элементах индекса. Например, сколько значений в нём хранится, равны ли они NULL и т.д.
Для лучшего понимания, рассмотрим несколько записей из index_users_on_name:

Здесь вместо value вставлены некоторые имена из БД. Узел из верхнего дерева содержит ключи «Dr. Edna Kunde» и «Julius Powlowski», а узел нижнего — «Julius Powlowski» и «Juston Quitzon». В отличие от диаграммы Лемана и Яо, Postgres повторяет родительские ключи в каждом дочернем узле. Например, «Julius Powlowski» является ключом в верхнем дереве и в дочернем узле. Указатель t_tid ссылается с Julius в верхнем узле на такое же имя в нижнем узле. Если вы хотите глубже изучить хранение значений ключей в узлах B-Tree, обратитесь к файлу itup.h:

Вернёмся к нашему исходному оператору SELECT:
Как именно в Postgres осуществляется поиск значения «Captain Nemo» в индексе index_users_on_name? Почему использование индекса позволяет искать быстрее по сравнению с поиском последовательности? Давайте взглянем на некоторые имена, хранящиеся в нашем индексе:

Это корневой узел в index_users_on_name. Я просто развернул дерево так, чтобы имена умещались целиком. Здесь четыре имени и одно значение NULL. Postgres автоматически создал этот корневой узел, как только был создан сам индекс. Обратите внимание, что за исключением NULL, обозначающего начало индекса, остальные четыре имени идут в алфавитном порядке.
Как вы помните, B-Tree является сбалансированным деревом. Поэтому в данном примере дерево имеет пять дочерних узлов:
- Имена, идущие в алфавитном порядке до «Dr. Edna Kunde»
- Имена между «Dr. Edna Kunde» и «Julius Powlowski»
- Имена между «Julius Powlowski» и «Monte Nicolas»
…и т.д.
Поскольку мы ищем «Captain Nemo», то Postgres идёт по первой ветви направо (при алфавитной сортировке искомое значение идёт до «Dr. Edna Kunde»):

Как видно из иллюстрации, далее Postgres находит узел с нужным значением. Для теста я добавил в таблицу 1000 имён. Этот правый узел содержал 240 из них. Так что дерево существенно ускорило процесс поиска, поскольку остальные 760 значений остались «за бортом».
Если вы хотите узнать больше об алгоритме поиска нужного узла в B-Tree, обратитесь к комментариям к функции _bt_search.

Итак, Postgres перешёл в узел, содержащий 240 имён, среди которых ему нужно найти значение «Captain Nemo».

Для этого используется не поиск последовательности, а бинарный поисковый алгоритм. Для начала система сравнивает ключ, который находится в середине списка (позиция 50%):

Искомое значение идёт по алфавиту после «Breana Witting», поэтому Postgres перескакивает к ключу, находящемуся на позиции 75% (три четверти списка):
На этот раз наше значение должно быть выше. Тогда Postgres прыгает на некоторое значение выше. В моём случае системе понадобилось восемь раз прыгать по списку ключей в узле, пока она не нашла наконец нужное значение:

Подробнее об алгоритме поиска значения внутри узла можно почитать в комментариях к функции _bt_binsrch:

Если у вас есть желание, то некоторое количество теории о деревьях B-Tree можно почерпнуть из научной работы Efficient Locking for Concurrent Operations on B-Trees.
Добавление ключей в B-Tree. Процедура внесения новых ключей в дерево выполняется по очень интересному алгоритму. Обычно ключ записывается в узел в соответствии с принятой сортировкой. Но что делать, если в узле уже нет свободного места? В этом случае Postgres разделяет узел на два более мелких и вставляет в один из них ключ. Также добавляет в родительский узел ключ из «точки разделения» и указатель на новый дочерний узел. Конечно, родительский узел тоже приходится разделять, чтобы вставить этот ключ, в результате процедура добавления в дерево одного единственного ключа превращается в сложную рекурсивную операцию.
Удаление ключей из B-Tree. Тоже довольно любопытная процедура. При удалении ключа из какого-то узла Postgres, если это возможно, объединяет его дочерние узлы. Это тоже может быть рекурсивная операция.
Деревья B-Link-Tree. На самом деле, в работе Лемана и Яо описывается придуманное ими нововведение, связанное с параллелизмом и блокированием, когда одно дерево используется несколькими потоками. Код Postgres и его алгоритмы должны поддерживать многопоточность, потому что к одному индексу могут обращаться (или модифицировать его) одновременно несколько клиентов. Если добавить по указателю от каждого узла на следующий дочерний узел («стрелка вправо»), то один поток может искать по дереву, в то время как другой будет разделять узел без блокирования всего индекса:

Возможно, вы знаете всё о том, как использовать Postgres, но знаете ли вы, как он устроен внутри, что у него «под капотом»? Изучение информатики, помимо работы над текущими проектами, не досужее развлечение, а часть процесса развития разработчика. Год от года наши программные инструменты становятся сложнее, многограннее, лучше, облегчая нам процесс создания сайтов и приложений. Но мы не должны забывать, что в основе всего этого лежит наука информатика. Мы, как и всё сообщество opensource-разработчиков Postgres, стоим на плечах наших предшественников, таких как Леман и Яо. Поэтому не доверяйтесь слепо инструментам, которые вы повседневно используете, изучайте их устройство. Это поможет вам достичь более высокого профессионального уровня, вы сможете найти для себя информацию и решения, о которых ранее и не подозревали.
