[Перевод] Почему TPU так хорошо подходят для глубинного обучения?

Тензорный процессор третьего поколения
Тензорный процессор Google — интегральная схема специального назначения (ASIC), разработанная с нуля компанией Google для выполнения задач по машинному обучению. Он работает в нескольких основных продуктах Google, включая Translate, Photos, Search Assistant и Gmail. Облачный TPU обеспечивает преимущества, связанные с масштабируемостью и лёгкостью использования, всем разработчикам и специалистам по изучению данных, запускающим передовые модели машинного обучения в облаке Google. На конференции Google Next »18 мы объявили о том, что Cloud TPU v2 теперь доступен для всех пользователей, включая бесплатные пробные учётные записи, а Cloud TPU v3 доступен для альфа-тестирования.
Но многие спрашивают — какая разница между CPU, GPU и TPU? Мы сделали демонстрационный сайт, где расположена презентация и анимация, отвечающая на этот вопрос. В этом посте я хотел бы подробнее остановиться на определённых особенностях содержимого этого сайта.
Как работают нейросети
Перед тем, как начать сравнивать CPU, GPU и TPU, посмотрим, какого рода вычисления требуются для машинного обучения –, а конкретно, для нейросетей.
Представьте, к примеру, что мы используем однослойную нейросеть для распознавания рукописных цифр, как показано на следующей диаграмме:
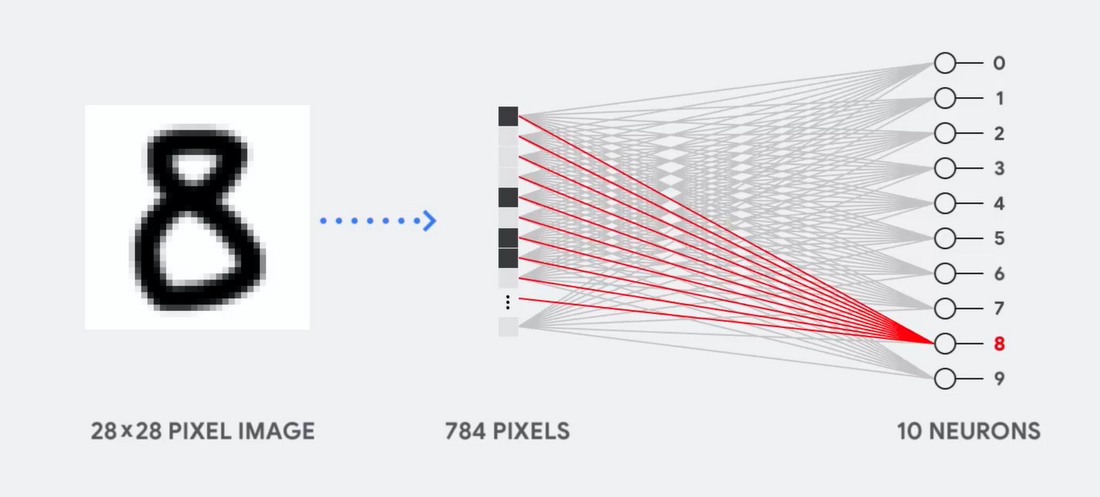
Если картинка будет сеткой размером 28×28 пикселей серой шкалы, её можно преобразовать в вектор из 784 значений (измерений). Нейрон, распознающий цифру 8, принимает эти значения и перемножает их со значениями параметра (красные линии на диаграмме).
Параметр работает как фильтр, извлекая особенности данных, говорящих о схожести изображения и формы 8:

Это наиболее простое объяснение классификации данных нейросетями. Перемножение данных с соответствующими им параметрами (окраска точек) и их сложение (сумма точек справа). Наивысший результат обозначает наилучшее совпадение введённых данных и соответствующего параметра, которое, скорее всего, и будет правильным ответом.
Проще говоря, нейросетям требуется делать огромное количество перемножений и сложений данных и параметров. Часто мы организовываем их в виде матричного перемножения, c которым вы могли столкнуться в школе на алгебре. Поэтому проблема состоит в том, чтобы выполнить большое количество матричных перемножений как можно быстрее, потратив как можно меньше энергии.
Как работает CPU
Как подходит к такой задаче CPU? CPU — процессор общего назначения, основанный на архитектуре фон Неймана. Это значит, что CPU работает с ПО и памятью как-то так:
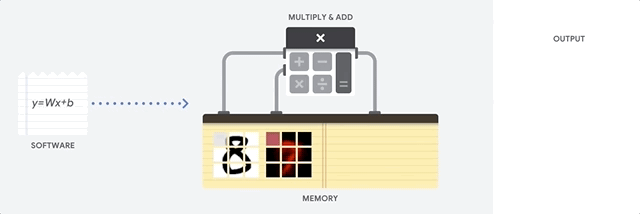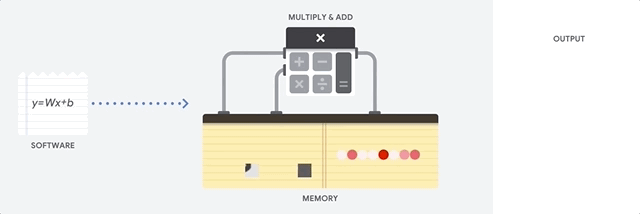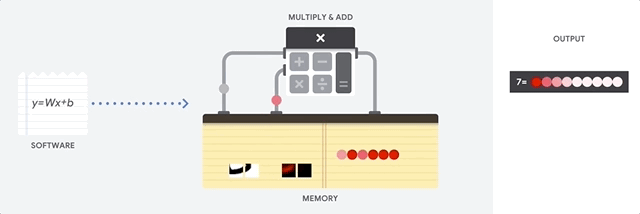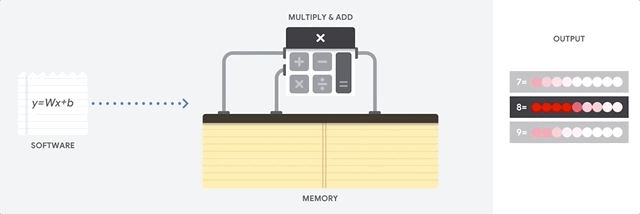
Главное преимущество CPU — гибкость. Благодаря архитектуре фон Неймана, вы можете загружать совершенно разное ПО для миллионов различных целей. CPU можно использовать для обработки текстов, управления ракетными двигателями, выполнения банковских транзакций, классификации изображений при помощи нейросети.
Но поскольку CPU такой гибкий, оборудование не всегда знает заранее, какой будет следующая операция, пока не прочтёт следующую инструкцию от ПО. CPU нужно хранить результаты каждого вычисления в памяти, расположенной внутри CPU (так называемые регистры, или L1-кэш). Доступ к этой памяти становится минусом архитектуры CPU, известным как узкое место архитектуры фон Неймана. И хотя огромное количество вычислений для нейросетей делает предсказуемым будущие шаги, каждое арифметико-логическое устройство CPU (ALU, компонент, хранящий и управляющий множителями и сумматорами) выполняет операции последовательно, каждый раз обращаясь к памяти, что ограничивает общую пропускную способность и потребляет значительное количество энергии.
Как работает GPU
Для увеличения пропускной способности по сравнению с CPU, GPU использует простую стратегию: почему бы не встроить в процессор тысячи ALU? В современном GPU содержится порядка 2500 — 5000 ALU на процессоре, что делает возможным выполнение тысяч умножений и сложений одновременно.

Такая архитектура хорошо работает с приложениями, требующими массивного распараллеливания, такими, например, как умножение матриц в нейросети. При типичной тренировочной нагрузке глубинного обучения (ГО) пропускная способность в этом случае увеличивается на порядок по сравнению с CPU. Поэтому на сегодняшний день GPU является наиболее популярной архитектурой процессоров для ГО.
Но GPU всё равно остаётся процессором общего назначения, который должен поддерживать миллион различных приложений и ПО. А это возвращает нас к фундаментальной проблеме узкого места архитектуры фон Неймана. Для каждого вычисления в тысячах ALU, GPU необходимо обратиться к регистрам или разделяемой памяти, чтобы прочесть и сохранить промежуточные результаты вычислений. Поскольку GPU выполняет больше параллельных вычислений на тысячах своих ALU, он также тратит пропорционально больше энергии на доступ к памяти и занимает большую площадь.
Как работает TPU
Когда мы в Google разрабатывали TPU, мы построили архитектуру, предназначенную для определённой задачи. Вместо разработки процессора общего назначения, мы разработали матричный процессор, специализированный для работы с нейросетями. TPU не сможет работать с текстовым процессором, управлять ракетными двигателями или выполнять банковские транзакции, но он может обрабатывать огромное количество умножений и сложений для нейросетей с невероятной скоростью, потребляя при этом гораздо меньше энергии и умещаясь в меньшем физическом объёме.
Главное, что позволяет ему это делать — радикальное устранение узкого места архитектуры фон Неймана. Поскольку основной задачей TPU является обработка матриц, разработчикам схемы были знакомы все необходимые шаги вычислений. Поэтому они смогли разместит тысячи множителей и сумматоров, и соединить их физически, сформировав большую физическую матрицу. Это называется архитектурой конвейерного массива. В случае с Cloud TPU v2 используются два конвейерных массива по 128×128, что в сумме даёт 32 768 ALU для 16-битных значений с плавающей точкой на одном процессоре.
Посмотрим, как конвейерный массив выполняет подсчёты для нейросети. Сначала TPU загружает параметры из памяти в матрицу множителей и сумматоров.

Затем TPU загружает данные из памяти. По выполнению каждого умножения результат передаётся следующим множителям, при одновременном выполнении сложений. Поэтому на выходе будет сумма всех умножений данных и параметров. В течение всего процесса объёмных вычислений и передачи данных доступ к памяти совершенно не нужен.
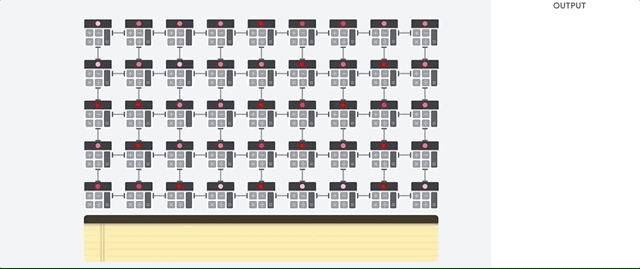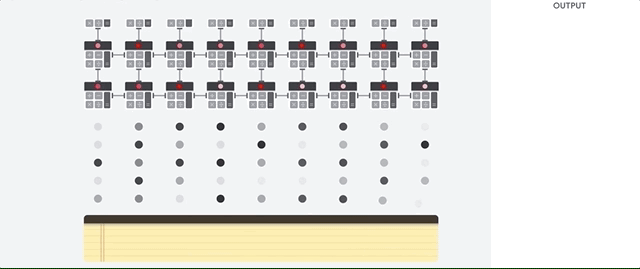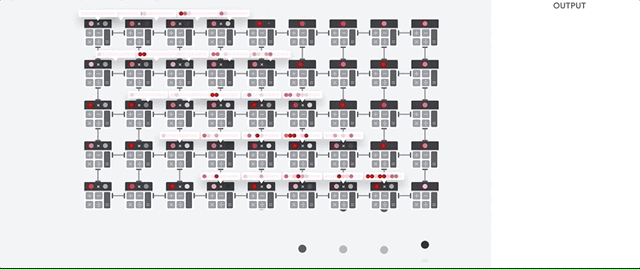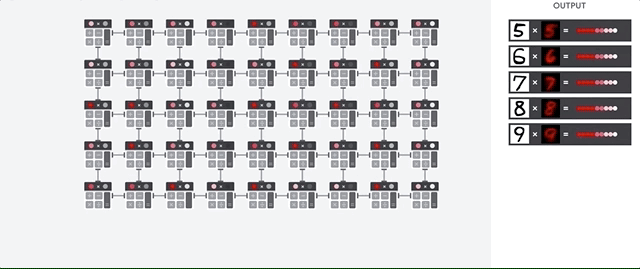
Поэтому TPU демонстрирует большую пропускную способность при подсчётах для нейросетей, потребляя гораздо меньше энергии и занимая меньше места.
Преимущество: уменьшение стоимости в 5 раз
Какие же преимущества даёт архитектура TPU? Стоимость. Вот стоимость работы Cloud TPU v2 на август 2018 года, на время написания статьи:
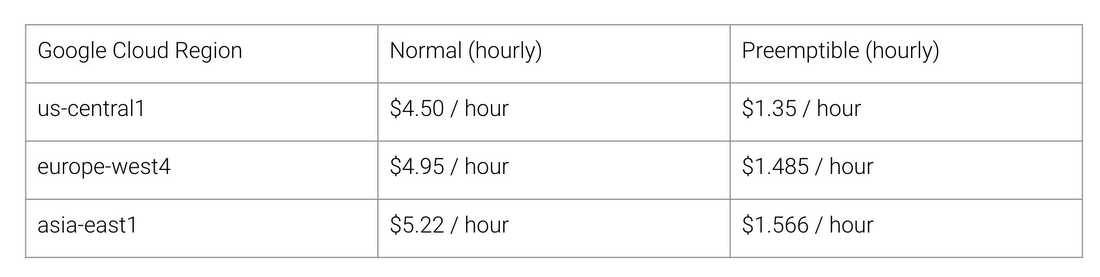
Обычная и TPU-шная стоимость работы для разных регионов Google Cloud
Стэнфордский университет раздаёт набор тестов DAWNBench, измеряющих быстродействие систем с глубинным обучением. Там можно посмотреть на различные комбинации задач, моделей и вычислительных платформ, а также на соответствующие результаты тестов.
На момент завершения соревнования в апреле 2018 минимальная стоимость тренировки на процессорах с архитектурой, отличной от TPU, равнялась $72,40 (для тренировки ResNet-50 с 93% точностью на ImageNet на спотовых инстансах). При помощи Cloud TPU v2 такую тренировку можно провести за $12,87. Это меньше 1/5 стоимости. Такова сила архитектуры, предназначенной специально для нейросетей.
