[Перевод] Планировщик Go
Преамбула от переводчика: Это достаточно вольный перевод пусть и не самой свежей (июнь 2013 года), но доходчивой публикации о новом планировщике параллельных ветвей исполнения в Go. Достоинством этой заметки есть то, что в ней совершенно просто, «на пальцах» описывается новый механизм планирования для ознакомления. Тем же, кого не устраивает объяснение «на пальцах» и кто хотел бы обстоятельного изложения, рекомендую Scheduling Multithreaded Computations by Work Stealing — 29 страниц изложения со строгим и сложным математическим аппаратом для анализа производительности, 48 позиций библиографии.
Одной из наибольших новинок в Go 1.1 стал новый диспетчер, спроектированный Дмитрием Вьюковым (Dmitry Vyukov). Новый планировщик дал настолько разительное увеличение производительности для параллельных программ без изменений кода, что я решил написать что-нибудь об этом.
Большинство из того, что написано здесь, уже описано в оригинальном тексте от автора. Текст этот достаточно обстоятелен, но он сугубо технической.
Все, что вам следует знать о новом планировщике, содержится в этом авторском тексте, но моё описание иллюстративно, чем превосходит его для понимания.
Прежде, чем мы взглянем но новый планировщик, нам нужно разобраться зачем он вообще нужен. Зачем создавать планировщик пространства пользователя, когда операционная система осуществляет планирование потоков для вас?
API потоков POSIX являются очень логичным продолжением существующей в операционной системе Unix модели процессов, и, раз так, потоки получают многие из тех органов управления, что и процессы.
Потоки имеют свою собственную сигнальную маску, могут быть закреплены за процессорами с помощью аффинити маски, могут быть введены в группы, и могут быть тестированы на предмет того какие ресурсы они используют. Все эти элементы добавляют накладные расходы для объектов, а, поскольку они просто не нужны для Go программ использующих Go-рутины, эти накладные расходы лавинно складываются, когда у вас становится 100000 потоков в вашей программе.
Другая проблема состоит в том, что операционная система не может делать осмысленных решений в планировании, основанных на модели Go. Например, сборщиком мусора требуется, чтобы все потоки были остановлены при запуске сборщика и их память должна быть в синхронизированном состоянии. Это предполагает ожидание выполняющихся потоков до достижения точки, где мы точно знаем, что память находится в адекватном состоянии.
Когда у вас есть много потоков, планируемых в случайных точках, есть большая вероятность того, что вы будете вынуждены ожидать большинства из них для достижения согласованного состояния. Планировщик Go, напротив, может принимать решение на перепланирование только в таких местах, где он знает, что память находится в согласованных состояниях. Это означает, что когда мы останавливаемся для сборки мусора, мы вынуждены ожидать только тех потоков, которые активно выполняются на процессорных ядрах.
Обычно есть 3 моделей для нарезания вычисления на потоки. Первым является N:1, где несколько пользовательских потоков запущено на едином потоке ядра операционной системы. Этот способ имеет то преимущество, что осуществляется очень быстрое переключение контекстов, но нет возможности воспользоваться преимуществами многоядерных систем. Второй способ — это 1:1, где каждый пользовательский поток выполнения совпадает с одним потоком операционной системы. Он использует все ядра автоматически, но переключение контекста происходит медленно, потому что требует прерываний работы операционной системы.
Go пытается взять лучшее из обоих миров с помощью М:N планировщика. При этом произвольное число Go-рутин (M) планируется на произвольное количество потоков (N) операционной системы. Этим вы получаете одновременно быстрое переключение контекста и возможность воспользоваться всеми ядрами в вашей системе. Основным недостатком данного подхода является сложность его включения в планировщик.
Чтобы исполнять задачу планирования, планировщик Go использует 3 основных сущностей:
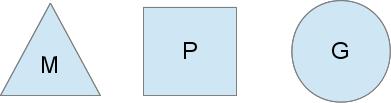
Треугольник представляет поток операционной системы. Выполнением такого потока управляет операционная система, и работает это во многом подобно вашим стандартным потокам POSIX. В исполнимом коде это называется M машиной.
Круг представляет Go-рутину. Он включает стек, указатель команд и другую важную информацию для планирования Go-рутины, такую как канал, который на ней может быть блокирован. В исполнимом коде это обозначается как G.
Прямоугольник представляет контекст планирования. Вы можете понимать его как локализованная версию планировщика, который выполняет код Go-рутин в единственном потоке ядра. Это важная часть, которая позволяет нам уйти от N:1 планировщика к М:N планировщику. Во время выполнения кода контекст обозначается как P для процессора. В общем это и всё, если коротко.

На рисунке показаны 2 потока ядра (M), каждый владеющий контекстом (P), каждый из которых выполняет Go-рутину. Для целей выполнения Go-рутины, поток должен удерживать контекст. Число контекстов устанавливается на старте из значения переменной окружения GOMAXPROCS, или функцией периода выполнения GOMAXPROCS(). Нормально эта величина не изменяется на протяжении выполнения вашей программы.
Факт фиксированного числа контекстов означает, что только GOMAXPROCS участков Go кода выполняются одновременно в любой момент времени. Мы можем использовать это для настройки вызова процесса Go под индивидуальный компьютер, например на 4 ядерном PC выполнять код Go в 4 потока.
Подкрашенные серым на рисунке Go-рутины не выполняются, но готовы для планирования. Они помещены в списки, которые называются очередями исполнения (runqueues). Go-рутины добавляются в конец очереди исполнения каждый раз, когда очередная Go-рутина выполняет оператор go. Каждый раз, когда контекст должен выполнять очередную Go-рутину от точки планирования, он выталкивает Go-рутину из своей очереди исполнения, устанавливает её стек и указатель инструкций, и начинается выполнение Go-рутины.
Чтобы предотвратить разногласие мьютексов, каждый контекст обладает своей собственной локальной очередью исполнения. Предыдущая версия планировщика Go имела только глобальную очередь исполнения, с защитой её мьютексом. Потоки часто блокировались в ожидании освобождения мьютекса. Это было очень неудачно, когда вы используете 32-х ядерную машину, желая выжать максимум производительности насколько это возможно.
Планировщик удерживает планирование в таком устойчивом состоянии, пока все контексты имеют выполняющиеся Go-рутины. Однако, есть несколько сценариев, которые могут изменить это поведение.
Вы могли бы задаться вопросом, а к чему нам контексты вообще? Мы не можем просто присоединить очереди исполнения к потокам и избавиться от контекстов? Не реально. Смысл в том, что мы имеем контексты для того, что мы можем передавать их другим потокам, если текущий поток должен заблокировать по какой-то причине.
Пример того, когда нам необходимо блокироваться, это когда мы производим системный вызов. Поскольку поток не может одновременно исполнять код и быть блокированным на системном вызове, нам нужно передать контекст, поскольку он может задерживать планирование.

Здесь мы видим поток отказавшийся от своего контекста, так что другой поток может запустить его. Планировщик позаботится о том, чтобы существовало достаточно потоков для выполнения всех контекстов. М1 на рисунке выше может быть специально создан только для обработки системного вызова, или он может прийти из какого-то пула потоков. Выполняющий системный вызов поток будет заморожен на Go-рутине, делающей системный вызов, поскольку она технически всё ещё выполняется, хотя и блокирована в операционной системе.
Когда системный вызов возвращает управление, поток должен попытаться получить контекст для того, чтобы запустить выполняться возвратившуюся Go-рутину. Нормальный режим действий — это заимствовать контекст у одного из других потоков. Если поток не может заимствовать, он поставит Go-рутину в глобальную очередь исполнения, возвратив себя в пул свободных потоков, или перейдя в режим сна.
Глобальная очередь исполнения — это очередь исполнения откуда контексты извлекают (работы), когда они закончатся в их локальных очередях. Контексты также периодически проверяют глобальную очередь на предмет Go-роутин. Иначе Go-рутины в глобальной очереди могут никогда не стартовать и умереть голодной смертью.
Такая обработка системных вызовов объясняет почему Go программы выполняются в несколько потоков даже тогда, когда GOMAXPROCS установлено в 1. Среда выполнения использует Go-рутины для системных вызовов, оставляя потоки после них.
Другой способ того, что устойчивое состояние системы может измениться, это когда контекст выпадает из расписания Go-роутин. Это может произойти, если объемы работ на очередях исполнения контекстов являются несбалансированным. Такое может произойти когда контекст, в конечном итоге, исчерпывает свою очередь исполнения, при том, что всё ещё есть работа, которую предстоит сделать в системе. Чтобы продолжить выполнение Go кода, контекст может занять Go-роутины из глобальной очереди исполнения, но если их нет и там, он должен получить их из другого места.
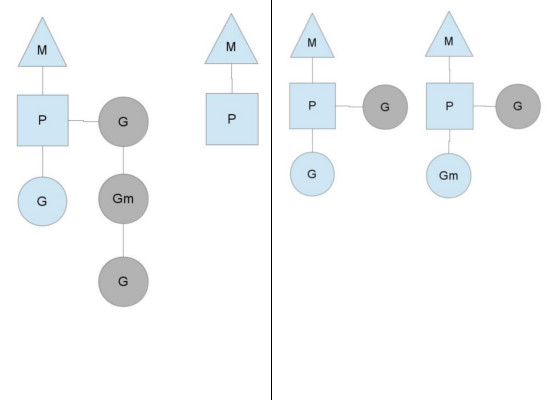
Это нечто находится где-то в других контекстах. Когда контекст иссякает, он будет пытаться заимствовать около половины очереди исполнения из другого контекста. Это гарантирует, что всегда есть работа для выполнения на каждом из контекстов, что в свою очередь подтверждает, что все потоки работают на пределе своих возможностей.
Есть еще множество деталей в планировщике, как cgo потоки, LockOSThread() функция и интеграция с сетевым пуллингом. Они выходят за рамки этих заметок, но все же заслуживают изучения. Я, возможно, напишу о них позже. Конечно, множество интересных конструкций могут быть найдены в Go библиотеках времени исполнения.
