[Перевод] Первостепенная задача квантовых компьютеров – усиление искусственного интеллекта
Идея слияния квантовых вычислений и машинного обучения находится в своём расцвете. Сможет ли она оправдать высокие ожидания?

В начале 90-х Элизабет Берман [Elizabeth Behrman], профессор физики в Уичитском университете начала работать над слиянием квантовой физики с искусственным интеллектом — в частности, в области тогда ещё непопулярной технологии нейросетей. Большинство людей считало, что она пытается смешивать масло с водой. «Мне чертовски трудно было публиковаться, — вспоминает она. — Журналы по нейросетям говорили «Что это за квантовая механика?», а журналы по физике говорили «Что это за нейросетевая ерунда?»
Сегодня смесь двух этих понятий кажется самой естественной вещью на свете. Нейросети и другие системы машинного обучения стали самой внезапной технологией XXI века. Человеческие занятия удаются им лучше, чем у людей, и они превосходят нас не только в задачах, в которых большинство из нас и так не блистали — например, в шахматах или глубоком анализе данных, но и в тех задачах, для решения которых эволюционировал мозг — например, распознавание лиц, перевод языков и определение права проезда на четырёхстороннем перекрёстке. Подобные системы стали возможными благодаря огромной компьютерной мощности, поэтому неудивительно, что технокомпании начали поиски компьютеров не просто побольше, а принадлежащих к совершенно новому классу.
Квантовые компьютеры после десятилетий исследований почти готовы выполнять вычисления с опережением любых других компьютеров на Земле. В качестве их главного преимущества обычно приводят разложение на множители больших чисел — операцию, ключевую для современных систем шифрования. Правда, до этого момента осталось ещё как минимум лет десять. Но и сегодняшние рудиментарные квантовые процессоры таинственным образом прекрасно подходят для нужд машинного обучения. Они манипулируют огромными объёмами данных за один проход, выискивают неуловимые закономерности, невидимые для классических компьютеров, и не тушуются перед неполными или неопределёнными данными. «Существует естественный симбиоз между статистической по сути природой квантовых вычислений и машинным обучением», — говорит Иоганн Оттербах, физик из Rigetti Computing, компании, занимающейся квантовыми вычислениями в Беркли, Калифорния.
Если на то пошло, то маятник уже качнулся до другого максимума. Google, Microsoft, IBM и другие техногиганты вливают средства в квантовое машинное обучение (КМО) и в инкубатор стартапов, посвящённый этой теме, расположенный в Торонтском университете. «Машинное обучение» становится модным словечком», — говорит Джейкоб Биамонт, специалист по квантовой физике из Сколковского института науки и технологий. «А смешав его с понятием «квантовый», вы поучите мегамодное слово».
Но понятие «квантовый» никогда не означает именно то, что от него ожидают. Хотя вы могли бы решить, что КМО-система должна быть мощной, она страдает от синдрома «запертости». Она работает с квантовыми состояниями, а не с человекочитаемыми данными, и перевод между двумя этими мирами может нивелировать все её явные преимущества. Это как iPhone X, обладающий всеми своими впечатляющими характеристиками, оказывается не быстрее старого телефона, поскольку местная сеть работает отвратительно. В некоторых особых случаях физики могут преодолеть это узкое место ввода-вывода, но появятся ли такие случаи при решении практических задач с МО, пока непонятно. «У нас пока нет чётких ответов, — говорит Скот Ааронсон, специалист по информатике из Техасского университета в Остине, всегда пытающийся реально смотреть на вещи в области квантовых вычислений. — Люди довольно осторожно относятся к вопросу о том, дадут ли эти алгоритмы какое-то преимущество в скорости».
Квантовые нейроны
Основная задача нейросети, будь она классической или квантовой — распознавать закономерности. Она создана по образу человеческого мозга и представляет собой решётку из базовых вычислительных единиц — «нейронов». Каждый из них может быть не сложнее переключателя вкл/выкл. Нейрон отслеживает выход множества других нейронов, будто бы голосующих по определённому вопросы, и переключается в положение «вкл» если достаточно много нейронов проголосовали «за». Обычно нейроны упорядочиваются в слои. Первый слой принимает ввод (к примеру, пиксели изображения), средние слои создают различные комбинации ввода (представляя такие структуры, как грани и геометрические фигуры), а последний слой выдаёт вывод (высокоуровневое описание того, что содержится на картинке).
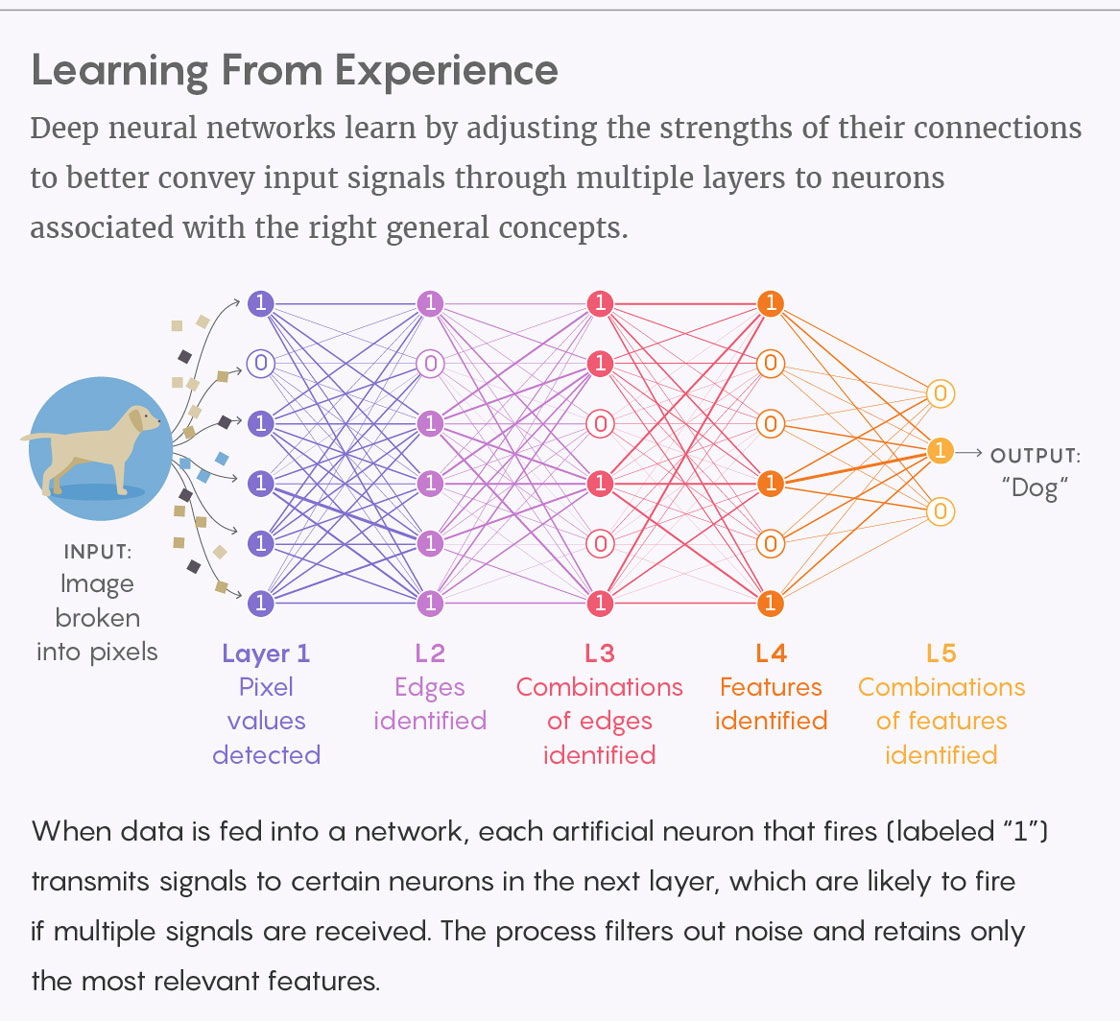
Глубинные нейросети обучаются, регулируя веса их связей так, чтобы наилучшим образом передавать сигналы через несколько слоёв к нейронам, связанным с нужными обобщёнными концепциями
Что важно, вся эта схема не проработана заранее, а адаптируется в процессе обучения методом проб и ошибок. Например, мы можем скармливать сети изображения, подписанные «котёнок» или «щенок». Каждой картинке она присваивает метку, проверяет, правильно ли у неё получилось, и если нет — подправляет нейронные связи. Сначала она работает почти случайно, но затем улучшает результаты; после, допустим, 10 000 примеров она начинает разбираться в домашних животных. В серьёзной нейросети может быть миллиард внутренних связей, и всех их необходимо подстроить.
На классическом компьютере эти связи представлены баснословной матрицей чисел, а работа сети означает выполнение матричных вычислений. Обычно эти операции с матрицей отдают на обработку особому чипу — к примеру, графическому процессору. Но никто не справляется с матричными операциями лучше квантового компьютера. «Обработка больших матриц и векторов на квантовом компьютере происходит экспоненциально быстрее», — говорит Сет Ллойд, физик из Массачусетского технологического института и пионер квантовых вычислений.
Для решения этой задачи квантовые компьютеры способны воспользоваться преимуществами экспоненциальной природы квантовой системы. Большая часть информационной ёмкости квантовой системы содержится не в её отдельных единицах данных — кубитах, квантовых аналогах битов классического компьютера –, но в совместных свойствах этих кубитов. У двух кубитов совместно есть четыре состояния: оба вкл, оба выкл, вкл/выкл и выкл/вкл. У каждого есть определённый вес, или «амплитуда», которая может играть роль нейрона. Если добавить третий кубит, можно представить уже восемь нейронов; четвёртый — 16. Ёмкость машины растёт экспоненциально. По сути, нейроны размазаны по всей системе. Когда вы изменяете состояние четырёх кубитов, вы обрабатываете 16 нейронов одним махом, а классическому компьютеру пришлось бы обрабатывать эти числа по одному.
Ллойд оценивает, что 60 кубитов хватит для кодирования такого количества данных, которое человечество производит за год, а 300 могут содержать классическое информационное наполнение всей Вселенной. У самого большого из имеющихся на сегодня квантовых компьютеров, построенного IBM, Intel и Google, порядка 50 кубитов. И это только если принять, что каждая амплитуда представляет один классический бит. На самом деле амплитуды — величины непрерывные (и представляют комплексные числа), и с точностью, подходящей для решения практических задач, каждая из них может хранить до 15 битов, говорит Ааронсон.
Но способность квантового компьютера хранить информацию в сжатом виде не делает его быстрее. Нужно иметь возможность использовать эти кубиты. В 2008 Ллойд, физик Арам Хэрроу из MIT и Авинатан Хассидим, специалист по информатике из Университета имени Бар-Илана в Израиле показали, как можно выполнить важную алгебраическую операцию по инвертированию матрицы. Они разбили её на последовательность логических операций, которые можно выполнять на квантовом компьютере. Их алгоритм работает для огромного количества технологий МО. И ему не требуется так много шагов, как, допустим, разложению большого числа на множители. Компьютер способен быстро выполнить задачу по классификации до того, как шум — крупный ограничивающий фактор современных технологий — сможет всё испортить. «До того, как у вас будет полностью универсальный, устойчивый к ошибкам квантовый компьютер, у вас может появиться просто некое квантовое преимущество», — сказал Кристан Темм из Исследовательского центра им. Томаса Уотсона компании IBM.
Дайте природе решить задачу
Пока что машинное обучение на основе квантовых матричных вычислений было продемонстрировано только на компьютерах с четырьмя кубитами. Большая часть экспериментальных успехов квантового машинного обучения использует другой подход, в котором квантовая система не просто симулирует сеть, а является сетью. Каждый кубит отвечает за один нейрон. И хотя тут об экспонентном росте говорить не приходится, подобное устройство может воспользоваться другими свойствами квантовой физики.
Крупнейшее из таких устройств, содержащее порядка 2000 кубитов, изготовлено компанией D-Wave Systems, расположенной недалеко от Ванкувера. И это не совсем то, что люди представляют себе, думая о компьютере. Вместо того, чтобы получить некие вводные данные, выполнить последовательность вычислений и показать вывод, он работает, находя внутреннюю непротиворечивость. Каждый из кубитов — сверхпроводящая электрическая петля, работающая, как крохотный электромагнит, ориентированный вверх, вниз, или и вверх и вниз — то есть, находясь в суперпозиции. Совместно кубиты связываются за счёт магнитного взаимодействия.

Чтобы запустить эту систему, сначала необходимо применить горизонтально ориентированное магнитное поле, инициализирующее кубиты одинаковой суперпозицией вверх и вниз — эквивалент чистого листа. Для ввода данных есть пара способов. В некоторых случаях можно зафиксировать слой кубитов в необходимых начальных значениях; чаще входные данные включаются в силу взаимодействий. Затем вы позволяете кубитам взаимодействовать друг с другом. Некоторые пытаются выстроиться одинаково, некоторые — в противоположном направлении, и под влиянием горизонтального магнитного поля они переключаются в предпочтительную ориентацию. В этом процессе они могут заставить переключиться и другие кубиты. Сначала это происходит довольно часто, поскольку так много кубитов расположено неправильно. Со временем они успокаиваются, после чего можно выключить горизонтальное поле и зафиксировать их в этом положении. В этот момент кубиты выстроились в последовательность положений «вверх» и «вниз», представляющую собой вывод на основе ввода.
Не всегда очевидно, какой будет итоговое расположение кубитов, но в этом и смысл. Система, просто ведя себя естественно, решает задачу, над которой классический компьютер бился бы долго. «Нам не нужен алгоритм, — объясняет Хидетоси Нисимори, физик из Токийского технологического института, разработавший принципы работы машин D-Wave. — Это полностью отличный от обычного программирования подход. Задачу решает природа».
Переключение кубитов происходит из-за квантового туннелирования, естественного стремления квантовых систем к оптимальной конфигурации, наилучшей из возможных. Можно было бы построить классическую сеть, работающую на аналоговых принципах, использующих случайное дрожание вместо туннелирования для переключения битов, и в некоторых случаях она на самом деле работала бы лучше. Но, что интересно, для задач, появляющихся в области машинного обучения, квантовая сеть, судя по всему, быстрее достигает оптимума.
У машины от D-Wave есть и недостатки. Она чрезвычайно подвержена влиянию шума, и в текущей версии может выполнять не очень много разновидностей операций. Но алгоритмы машинного обучения терпимы к шуму по своей природе. Они полезны именно потому, что могут распознать смысл в неопрятной реальности, отделяя котят от щенков, несмотря на отвлекающие моменты. «Нейросети известны сопротивляемостью к шуму», — сказал Берман.
В 2009-м команда под руководством Хартмута Нивена, специалиста по информатике из Google, пионера дополненной реальности (он был сооснователем проекта Google Glass), перешедшего в область квантовой обработки информации, показала, как ранний прототип машины от D-Wave способен выполнять вполне настоящую задачу машинного обучения. Они использовали машину как однослойную нейросеть, сортирующую изображения по двум классам: «автомобиль» и «не автомобиль» на библиотеке из 20 000 фотографий, сделанных на улицах. В машине было всего 52 рабочих кубита, совсем недостаточно для того, чтобы полностью ввести изображение. Поэтому команда Нивена скомбинировала машину с классическим компьютером, анализировавшим различные статистические параметры изображений и подсчитывал, насколько чувствительны эти величины к наличию на фото автомобиля — обычно они были не особенно чувствительными, но, по крайней мере, отличались от случайных. Некоторая комбинация этих величин могла надёжным образом определить наличие автомобиля, просто не было очевидно — какая именно комбинация. А определением нужной комбинации как раз занималась нейросеть.
Каждой величине команда сопоставила кубит. Если кубит устанавливался на значении 1, он отмечал соответствующую величину как полезную; 0 означал, что она не нужна. Магнитные взаимодействия кубитов закодировали требования этой задачи — к примеру, необходимость учитывать лишь наиболее сильно отличающиеся величины, чтобы итоговый выбор был наиболее компактным. Получившаяся система оказалась способной распознать автомобиль.
В прошлом году группа под руководством Марии Спиропулу, специалиста по физике частиц из Калифорнийского технологического института, и Дэниела Лидара, физика из Университета Южной Калифорнии, применили алгоритм для решения практической задачи по физике: классификации столкновений протонов на категории «бозон Хиггса» и «не бозон Хиггса». Ограничив оценки только столкновениями, порождавшими фотоны, они использовали основную теорию частиц для предсказания того, какие свойства фотона должны указывать на кратковременное появление частицы Хиггса — к примеру, превышающая некий порог величина импульса. Они рассмотрели восемь таких свойств и 28 их комбинаций, что в сумме дало 36 сигналов-кандидатов и позволило чипу D-Wave найти оптимальную выборку. Он определил 16 переменных как полезные, а три — как наилучшие. «Учитывая малый размер тренировочного набора, квантовый подход дал преимущество в точности над традиционными методами, используемыми в сообществе специалистов по физике высоких энергий», — сказал Лидар.

Мария Спиропулу, физик в Калифорнийском технологическом институте, использовала машинное обучение в поисках бозонов Хиггса
В декабре компания Rigetti продемонстрировала способ автоматической группировки объектов при помощи квантового компьютера общего назначения из 19 кубитов. Исследователи скормили машине список городов и расстояний между ними и попросили её рассортировать города на два географических региона. Трудность этой задачи в том, что распределение одного города зависит от распределения всех остальных, поэтому вам надо искать решение для всей системы сразу.
Команда компании, по сути, назначила каждому городу по кубиту и отметила, к какой группе его приписали. Через взаимодействие кубитов (в системе Rigetti оно не магнитное, а электрическое) каждая пара кубитов стремилась принять противоположные значения, поскольку в таком случае их энергия минимизировалась. Очевидно, что в любой системе, содержащей больше двух кубитов, некоторым парам придётся принадлежать к одной и той же группе. Ближе расположенные города охотнее соглашались на это, поскольку для них энергетическая стоимость принадлежность к одной и той же группе была ниже, чем в случае с далёкими городами.
Чтобы привести систему к наименьшей энергии, команда Rigetti избрала подход, в чём-то похожий на подход D-Wave. Они инициализировали кубиты суперпозицией из всех возможных распределений по группам. Они позволили кубитам недолго взаимодействовать друг с другом, и это склонило их к принятию тех или иных значений. Затем они применили аналог горизонтального магнитного поля, что позволило кубитам поменять ориентацию на противоположную, если у них была такая склонность, что немного подтолкнуло систему по направлению к энергетическому состоянию с минимальной энергией. Затем они повторяли этот двухэтапный процесс — взаимодействие и переворот — пока система не минимизировала энергию, распределив города в два разных региона.
Подобные задачи по классификации, хотя и полезны, но довольно просты. Реальные прорывы МО ожидаются в генеративных моделях, которые не просто распознают щенков и котят, но способны создать новые архетипы — животных, никогда не существовавших, но настолько же милых, насколько реальные. Они даже способны самостоятельно вывести такие категории, как «котята» или «щенки», или реконструировать изображение, на котором отсутствует лапа или хвостик. «Эти технологии способны на многое и очень полезны в МО, но очень сложны в реализации», — сказал Мохаммед Амин, главный учёный в D-Wave. Помощь квантовых компьютеров пришлась бы тут кстати.
D-Wave и другие исследовательские команды приняли этот вызов. Тренировать такую модель — значит, подстраивать магнитные или электрические взаимодействия кубитов так, чтобы сеть могла воспроизвести некие пробные данные. Для этого нужно скомбинировать сеть с обычным компьютером. Сеть занимается сложными задачами — определяет, что данный набор взаимодействий означает в плане конечной конфигурации сети –, а партнёрский компьютер использует эту информацию для подстройки взаимодействий. В одной демонстрации в прошлом году Алехандро Пердомо-Ортиз, исследователь из Лаборатории квантового искусственного интеллекта НАСА вместе с командой дали D-Wave систему изображений, состоящую из написанных от руки цифр. Она определила, что всего их десять категорий, сопоставила цифры от 0 до 9, и создала свои собственные каракули в виде цифр.
Бутылочные горлышки, ведущие в туннели
Это всё хорошие новости. А плохие новости в том, что неважно, насколько крут ваш процессор, если вы не сможете предоставить ему данные для работы. В алгоритмах матричной алгебры единственная операция может обрабатывать матрицу из 16 чисел, но для загрузки матрицы всё равно требуется 16 операций. «Вопроса подготовки состояния — размещение классических данных в квантовом состоянии — избегают, а я думаю, что это одна из важнейших частей», — сказала Мария Шульд, исследователь стартапа квантовых компьютеров Xanadu и один из первых учёных, получивших степень в области КМО. Физически распределённые системы МО сталкиваются с параллельными сложностями — как ввести задачу в сеть кубитов и заставить кубиты взаимодействовать, как нужно.
После того, как вы смогли ввести данные, вам нужно хранить их таким образом, чтобы квантовая система смогла взаимодействовать с ними, не обрушив текущие вычисления. Ллойд с коллегами предложили квантовую оперативную память, использующую фотоны, но ни у кого пока нет аналогового устройства для сверхпроводящих кубитов или пойманных ионов — технологий, использующихся в ведущих квантовых компьютерах. «Это ещё одна огромная техническая проблема, кроме проблемы постройки самого квантового компьютера, — сказал Ааронсон. — При общении с экспериментаторами у меня создаётся впечатление, что они испуганы. Они вообще не представляют, как подойти к созданию этой системы».
И, наконец, как вывести данные? Это значит — измерить квантовое состояние машины, но измерение не только возвращает по одному числу за раз, выбранному случайно, оно ещё рушит всё состояние компьютера, стирая остаток данных до того, как у вас будут шансы их востребовать. Придётся запускать алгоритм снова и снова, чтобы вынуть всю информацию.
Но не всё потеряно. Для некоторых типов задач можно воспользоваться квантовой интерференцией. Можно управлять ходом операций так, чтобы неправильные ответы взаимно уничтожались, а правильные подкрепляли сами себя; таким образом, когда вы будете измерять квантовое состояние, вам вернут не просто случайное значение, а желаемый ответ. Но только несколько алгоритмов, например, поиск с полным перебором, могут воспользоваться интерференцией, и ускорение обычно получается небольшим.
В некоторых случаях исследователи обнаружили обходные пути для ввода и вывода данных. В 2015 году Ллойд, Сильвано Гарнероне из Университета Ватерлоо в Канаде и Паоло Занарди из Университета Южной Калифорнии показали, что в определённых видах статистического анализа не обязательно вводить или хранить весь набор данных целиком. Точно так же не нужно считывать все данные, когда будет достаточно нескольких ключевых значений. К примеру, технокомпании используют МО для выдачи рекомендаций телепередач к просмотру или товаров к покупке на основе огромной матрицы человеческих привычек. «Если вы делаете такую систему для Netflix или Amazon, вам нужна не сама записанная где-то матрица, а рекомендации для пользователей», — говорит Ааронсон.
Всё это вызывает вопрос: если квантовая машина демонстрирует свои способности в особых случаях, может, и классическая машина тоже сможет хорошо себя показать в этих случаях? Это главный неразрешённый вопрос в этой области. В конце концов, обычные компьютеры тоже могут очень многое. Обычный метод выбора для обработки больших наборов данных — случайная выборка — на самом деле очень похожа по духу на квантовый компьютер, который, что бы там внутри его ни происходило, в итоге выдаёт случайный результат. Шульд отмечает: «Я реализовывала множество алгоритмов, на которые я реагировала как: «Это так здорово, это такое ускорение», а затем, просто ради интереса, писала технологию выборки для классического компьютера, и понимала, что того же самого можно добиться и при помощи выборки».
Ни один из достигнутых на сегодняшний день успехов КМО не обходится без подвоха. Возьмём машину D-Wave. При классификации изображений автомобилей и частиц Хиггса она работала не быстрее классического компьютера. «Одна из тем, не обсуждаемых в нашей работе — это квантовое ускорение», — сказал Алекс Мотт, специалист по информатике из проекта Google DeepMind, работавший в команде, исследовавшей частицу Хиггса. Подходы с матричной алгеброй, например, алгоритм Хэрроу-Хассидими-Ллойда демонстрируют ускорение только в случае разреженных матриц — почти полностью заполненных нулями. «Но никто не задаёт вопрос –, а разреженные данные вообще интересны для машинного обучения?» — отметила Шульд.
Квантовый интеллект
С другой стороны, даже редкие улучшения существующих технологий могли бы порадовать технокомпании. «Получающиеся улучшения скромные, не экспоненциальные, но хотя бы квадратичные», — говорит Нэйтан Вайеб, исследователь в области квантовых компьютеров из Microsoft Research. «Если взять достаточно большой и быстрый квантовый компьютер, мы могли бы произвести революцию во многих областях МО». И в процессе использования этих систем специалисты по информатике, возможно, решат теоретическую загадку — на самом ли деле они по определению быстрее, и в чём именно.
Шульд также считает, что со стороны ПО есть место для инноваций. МО — это не просто куча вычислений. Это комплекс задач со своей особой, определённой структурой. «Алгоритмы, создаваемые людьми, отделены от тех вещей, что делают МО интересным и красивым, — сказала она. — Поэтому я начала работу с другого конца и задумалась: Если у меня уже есть квантовый компьютер — мелкомасштабный — какую модель МО на нём можно реализовать? Может, эту модель пока ещё не изобрели». Если физики хотят впечатлить экспертов по МО, им придётся сделать что-то большее, чем просто создать квантовые версии существующих моделей.
Точно так же, как многие нейробиологи пришли к выводу, что структура мыслей человека отражает потребность в теле, так же материализуются и системы МО. Изображения, языке и большая часть протекающих через них данных приходят из реального мира и отражают его свойства. КМО тоже материализуется –, но в более богатом мире, чем наш. Одна из областей, где оно, без сомнения, будет блистать — в обработке квантовых данных. Если эти данные будут представлять не изображение, а результат физического или химического эксперимента, квантовая машина станет одним из его элементов. Проблема ввода исчезает, а классические компьютеры остаются далеко позади.
Будто бы в ситуации замкнутого круга, первые КМО могут помочь разработать их преемников. «Один из способов, которым мы реально можем захотеть использовать эти системы — это для создания самих квантовых компьютеров, — сказал Вайбе. — Для некоторых процедур устранения ошибок это единственный имеющийся у нас подход». Может, они даже смогут устранить ошибки в нас. Не затрагивая тему того, является ли человеческий мозг квантовым компьютером –, а это очень спорный вопрос — он всё же иногда ведёт себя именно так. Поведение человека чрезвычайно привязано к контексту; наши предпочтения формируются через предоставляемые нам варианты выбора и не подчиняются логике. В этом мы похожи на квантовые частицы. «То, каким образом вы задаёте вопросы и в каком порядке, имеет значение, и это типично для квантовых наборов данных», — сказал Пердомо-Ортиз. Поэтому система КМО может оказаться естественным методом изучения когнитивных искажений человеческого мышления.
У нейросетей и квантовых процессоров есть нечто общее: удивительно, что они вообще работают. Возможность натренировать нейросеть никогда не была очевидной, и десятилетиями большинство людей сомневались, что это вообще окажется возможным. Точно также неочевидно, что квантовые компьютеры когда-нибудь можно будет приспособить к вычислениям, поскольку отличительные черты квантовой физики так хорошо скрыты от всех нас. И всё же оба они работают — не всегда, но чаще, чем мы могли бы ожидать. И учитывая это, кажется вероятным, что и их объединение найдёт себе место под солнцем.
