[Перевод] Отладка злого бага в рантайме Go

Я большой поклонник Prometheus и Grafana. Поработав SRE в Google, я научился ценить хороший мониторинг и за прошедший год предпочитал пользоваться комбинацией этих инструментов. Я использую их для мониторинга своих личных серверов (black-box и white-box мониторинг), внешних и внутренних событий Euskal Encounter, для мониторинга клиентских проектов и много другого. Prometheus позволяет очень просто писать кастомные модули экспорта для мониторинга моих собственных данных, к тому же вполне можно найти подходящий модуль прямо из коробки. Например, для создания симпатичной панели имеющихся метрик Encounter-событий мы используем sql_exporter.
Панель событий для Euskal Encounter (фальшивые данные стейджинга)
Можно легко закинуть node_exporter на любую машину и натравить экземпляр Prometheus, чтобы получить основные системные метрики (использование процессора, памяти, сети, дисков, файловой системы и т. д.). Я подумал, а почему бы таким образом не мониторить свой ноутбук? У меня «игровой» ноут Clevo, который я использую в качестве основной рабочей станции. Обычно он стоит дома, но иногда ездит со мной на большие мероприятия вроде Chaos Communication Congress. И раз у меня уже есть VPN между ноутом и одним из моих серверов, на котором крутится Prometheus, я могу просто выполнить emerge prometheus-node_exporter, поднять службу и указать её экземпляру Prometheus. Он автоматически сконфигурирует предупреждения, и мой телефон начнёт разрываться, когда я открою слишком много вкладок в Chrome и исчерпаю все 32 Гб оперативки. Замечательно.
На горизонте проблема
Примерно через час после настройки мой телефон сообщил, что свежедобавленный объект мониторинга недоступен. Увы, я прекрасно соединялся с ноутбуком по SSH, так что всё дело было в обрушении node_exporter.
fatal error: unexpected signal during runtime execution
[signal SIGSEGV: segmentation violation code=0x1 addr=0xc41ffc7fff pc=0x41439e]
goroutine 2395 [running]:
runtime.throw(0xae6fb8, 0x2a)
/usr/lib64/go/src/runtime/panic.go:605 +0x95 fp=0xc4203e8be8 sp=0xc4203e8bc8 pc=0x42c815
runtime.sigpanic()
/usr/lib64/go/src/runtime/signal_unix.go:351 +0x2b8 fp=0xc4203e8c38 sp=0xc4203e8be8 pc=0x443318
runtime.heapBitsSetType(0xc4204b6fc0, 0x30, 0x30, 0xc420304058)
/usr/lib64/go/src/runtime/mbitmap.go:1224 +0x26e fp=0xc4203e8c90 sp=0xc4203e8c38 pc=0x41439e
runtime.mallocgc(0x30, 0xc420304058, 0x1, 0x1)
/usr/lib64/go/src/runtime/malloc.go:741 +0x546 fp=0xc4203e8d38 sp=0xc4203e8c90 pc=0x411876
runtime.newobject(0xa717e0, 0xc42032f430)
/usr/lib64/go/src/runtime/malloc.go:840 +0x38 fp=0xc4203e8d68 sp=0xc4203e8d38 pc=0x411d68
github.com/prometheus/node_exporter/vendor/github.com/prometheus/client_golang/prometheus.NewConstMetric(0xc42018e460, 0x2, 0x3ff0000000000000, 0xc42032f430, 0x1, 0x1, 0x10, 0x9f9dc0, 0x8a0601, 0xc42032f430)
/var/tmp/portage/net-analyzer/prometheus-node_exporter-0.15.0/work/prometheus-node_exporter-0.15.0/src/github.com/prometheus/node_exporter/vendor/github.com/prometheus/client_golang/prometheus/value.go:165 +0xd0 fp=0xc4203e8dd0 sp=0xc4203e8d68 pc=0x77a980node_exporter, как и многие компоненты Prometheus, написан на Go. Это относительно безопасный язык: он позволяет вам при желании выстрелить себе в ногу, а его гарантии безопасности несравнимы с Rust, например, но всё же случайно вызвать segfault в Go не так-то легко. Кроме того, node_exporter — довольно простое Go-приложение, по большей части использующее чисто гошные зависимости. Значит, случай с падением будет интересным. Особенно учитывая, что падение произошло в mallocgc, который вообще не должен падать при нормальных условиях.
После нескольких перезапусков стало ещё интереснее:
2017/11/07 06:32:49 http: panic serving 172.20.0.1:38504: runtime error: growslice: cap out of range
goroutine 41 [running]:
net/http.(*conn).serve.func1(0xc4201cdd60)
/usr/lib64/go/src/net/http/server.go:1697 +0xd0
panic(0xa24f20, 0xb41190)
/usr/lib64/go/src/runtime/panic.go:491 +0x283
fmt.(*buffer).WriteString(...)
/usr/lib64/go/src/fmt/print.go:82
fmt.(*fmt).padString(0xc42053a040, 0xc4204e6800, 0xc4204e6850)
/usr/lib64/go/src/fmt/format.go:110 +0x110
fmt.(*fmt).fmt_s(0xc42053a040, 0xc4204e6800, 0xc4204e6850)
/usr/lib64/go/src/fmt/format.go:328 +0x61
fmt.(*pp).fmtString(0xc42053a000, 0xc4204e6800, 0xc4204e6850, 0xc400000073)
/usr/lib64/go/src/fmt/print.go:433 +0x197
fmt.(*pp).printArg(0xc42053a000, 0x9f4700, 0xc42041c290, 0x73)
/usr/lib64/go/src/fmt/print.go:664 +0x7b5
fmt.(*pp).doPrintf(0xc42053a000, 0xae7c2d, 0x2c, 0xc420475670, 0x2, 0x2)
/usr/lib64/go/src/fmt/print.go:996 +0x15a
fmt.Sprintf(0xae7c2d, 0x2c, 0xc420475670, 0x2, 0x2, 0x10, 0x9f4700)
/usr/lib64/go/src/fmt/print.go:196 +0x66
fmt.Errorf(0xae7c2d, 0x2c, 0xc420475670, 0x2, 0x2, 0xc420410301, 0xc420410300)
/usr/lib64/go/src/fmt/print.go:205 +0x5aТак, уже интереснее. В этот раз сломался Sprintf. Шта?
runtime: pointer 0xc4203e2fb0 to unallocated span idx=0x1f1 span.base()=0xc4203dc000 span.limit=0xc4203e6000 span.state=3
runtime: found in object at *(0xc420382a80+0x80)
object=0xc420382a80 k=0x62101c1 s.base()=0xc420382000 s.limit=0xc420383f80 s.spanclass=42 s.elemsize=384 s.state=_MSpanInUse
fatal error: found bad pointer in Go heap (incorrect use of unsafe or cgo?)
runtime stack:
runtime.throw(0xaee4fe, 0x3e)
/usr/lib64/go/src/runtime/panic.go:605 +0x95 fp=0x7f0f19ffab90 sp=0x7f0f19ffab70 pc=0x42c815
runtime.heapBitsForObject(0xc4203e2fb0, 0xc420382a80, 0x80, 0xc41ffd8a33, 0xc400000000, 0x7f0f400ac560, 0xc420031260, 0x11)
/usr/lib64/go/src/runtime/mbitmap.go:425 +0x489 fp=0x7f0f19ffabe8 sp=0x7f0f19ffab90 pc=0x4137c9
runtime.scanobject(0xc420382a80, 0xc420031260)
/usr/lib64/go/src/runtime/mgcmark.go:1187 +0x25d fp=0x7f0f19ffac90 sp=0x7f0f19ffabe8 pc=0x41ebed
runtime.gcDrain(0xc420031260, 0x5)
/usr/lib64/go/src/runtime/mgcmark.go:943 +0x1ea fp=0x7f0f19fface0 sp=0x7f0f19ffac90 pc=0x41e42a
runtime.gcBgMarkWorker.func2()
/usr/lib64/go/src/runtime/mgc.go:1773 +0x80 fp=0x7f0f19ffad20 sp=0x7f0f19fface0 pc=0x4580b0
runtime.systemstack(0xc420436ab8)
/usr/lib64/go/src/runtime/asm_amd64.s:344 +0x79 fp=0x7f0f19ffad28 sp=0x7f0f19ffad20 pc=0x45a469
runtime.mstart()
/usr/lib64/go/src/runtime/proc.go:1125 fp=0x7f0f19ffad30 sp=0x7f0f19ffad28 pc=0x430fe0 Теперь проблемы начались и у сборщика мусора. Уже другой сбой.
Здесь можно было сделать два логичных вывода: либо у меня серьёзная проблема с оборудованием, либо в бинарнике баг, связанный с повреждением памяти. Сначала я решил, что первое маловероятно, потому что ноутбук обрабатывал одновременно очень разные виды нагрузок и не было ни малейших признаков нестабильной работы, которые можно было бы связать с оборудованием (у меня падало ПО, но это никогда не происходило случайно). Поскольку бинарники Go вроде node_exporter связаны статично и не зависят от каких-то иных библиотек, я скачал официальный релиз бинарника и попробовал сделать так, чтобы большая часть моей системы не представляла собой переменную. Но всё равно получил сбой:
unexpected fault address 0x0
fatal error: fault
[signal SIGSEGV: segmentation violation code=0x80 addr=0x0 pc=0x76b998]
goroutine 13 [running]:
runtime.throw(0xabfb11, 0x5)
/usr/local/go/src/runtime/panic.go:605 +0x95 fp=0xc420060c40 sp=0xc420060c20 pc=0x42c725
runtime.sigpanic()
/usr/local/go/src/runtime/signal_unix.go:374 +0x227 fp=0xc420060c90 sp=0xc420060c40 pc=0x443197
github.com/prometheus/node_exporter/vendor/github.com/prometheus/client_model/go.(*LabelPair).GetName(...)
/go/src/github.com/prometheus/node_exporter/vendor/github.com/prometheus/client_model/go/metrics.pb.go:85
github.com/prometheus/node_exporter/vendor/github.com/prometheus/client_golang/prometheus.(*Desc).String(0xc4203ae010, 0xaea9d0, 0xc42045c000)
/go/src/github.com/prometheus/node_exporter/vendor/github.com/prometheus/client_golang/prometheus/desc.go:179 +0xc8 fp=0xc420060dc8 sp=0xc420060c90 pc=0x76b998Совершенно новый сбой. Похоже, проблема с node_exporter или одной из его зависимостей, так что я заполнил отчёт о баге на GitHub. Быть может, разработчики уже сталкивались с подобным? Надо привлечь их внимание и послушать, что они скажут.
Не-такой-уж-короткий обходной путь
Неудивительно, что сначала предположили: дело в оборудовании. Вполне обоснованно, ведь я столкнулся с проблемой только на одном компьютере. Все остальные мои машины прекрасно гоняли node_exporter. У меня не было других доказательств железного сбоя на этом хосте и даже объяснений, что именно могло вызвать падение node_exporter. Memtest86+ ещё никому не вредил, поэтому я решил им воспользоваться.
А затем случилось это:
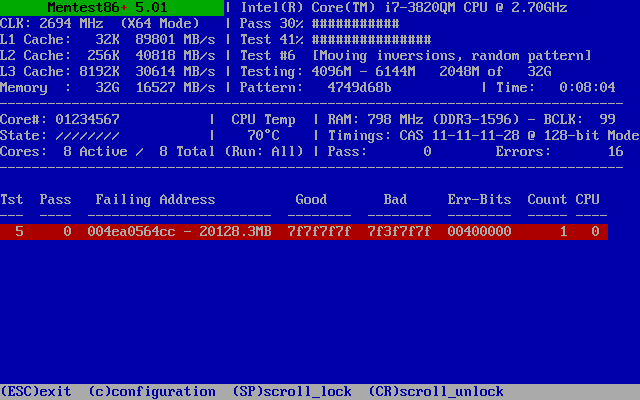
Вот что бывает, когда пользуешься ширпотребом для серьёзных задач
Опа! Битая память. Точнее, один бит. Я прогнал тест целиком и нашёл этот бит и несколько ложноположительных в тесте № 7 (в нём перемещаются блоки, что может привести к размножению единственной ошибки).
Дальнейшее тестирование в Memtest86+ показало, что тест № 5 в режиме SMP быстро обнаруживает проблему, но обычно не при первом проходе. Проблема всегда возникала с одним битом по одному и тому же адресу. Похоже, слабая ячейка памяти, которая при нагреве начинает барахлить. Логично: рост температуры увеличивает утечки в ячейках памяти, и повышается вероятность, что какая-нибудь маргинальная ячейка начнёт сбоить.
Чтобы было понятнее: это один плохой бит из 274 877 906 944. Прекрасное соотношение! У жёстких дисков и флеш-памяти коэффициент ошибок гораздо выше — в этих устройствах битые блоки помечаются ещё на заводах, а во время эксплуатации новые битые блоки незаметно для пользователей помечаются и переносятся в резервную зону. У оперативной памяти таких механизмов нет, так что битый блок остаётся навечно.
Увы, вряд ли этот бит приводит к сбоям в моём node_exporter. Приложение использует очень мало памяти, так что вероятность попадания в плохой бит (причём раз за разом) крайне мала. Проблема этого бита проявилась бы, в худшем случае приводя к битому пикселю в изображении, или выпадению одного символа в письме, или невыполнению какой-нибудь инструкции, или редкому segfault, если на плохой бит пришлось что-то серьёзное. Тем не менее это означает долгосрочные проблемы с надёжностью, и поэтому серверы и прочие устройства, для которых важна надёжность, используют ECC RAM — память с коррекцией ошибок.
У меня в ноутбуке такой роскоши нет. Но зато я могу пометить битый блок как плохой и сказать ОС, чтобы она его не использовала. У GRUB 2 есть малоизвестная возможность изменять схему памяти, передающуюся в загруженное ядро ОС. Не стоит покупать новую линейку памяти из-за одного плохого бита (к тому же DDR3 уже устарела, и велика вероятность, что новая память тоже будет со слабыми ячейками).
Но я могу сделать ещё кое-что. Раз ситуация ухудшается с ростом температуры, что будет, если я нагрею память?


100 °C
Установив температуру фена на 130 °C, я прогрел два модуля памяти (остальные два прячутся под задней крышкой, всего в моём ноутбуке четыре слота). Поигравшись с очерёдностью модулей, я нашёл ещё три слабых бита, которые были разбросаны по трём модулям и проявлялись только при нагреве.
Ещё я обнаружил, что расположение ошибок оставалось практически неизменным даже при переставлении модулей: верхние биты адреса были одни и те же. Всё дело в чередовании оперативной памяти: вместо того чтобы каждому модулю присваивать цельную четверть адресного пространства, данные распределяются по всем четырём модулям. Это удобно, потом что на область памяти можно наложить маску, охватывающую все возможные адреса для каждого плохого бита, и не беспокоиться о том, что всё перепутается, если поменять модули местами. Я выяснил, что если наложить маску на сплошную область в 128 Кб, то этого хватит для закрытия всех возможных перестановок адресов для каждого плохого бита. Но округлил до 1 Мб. Получилось три мегабайтных выравненных блока для маскирования (один из них покрывает два плохих бита, а всего я хотел покрыть четыре):
0x36a700000 – 0x36a7fffff0x460e00000 – 0x460efffff0x4ea000000 – 0x4ea0fffff
Маски я задал в /etc/default/grub с помощью синтаксиса маскирования адресов:
GRUB_BADRAM="0x36a700000,0xfffffffffff00000,0x460e00000,0xfffffffffff00000,0x4ea000000,0xfffffffffff00000"Затем быстро выполнил grub-mkconfig и выключил 3 Мб памяти с четырьмя плохими битами. Конечно, не ECC RAM, и всё же надёжность моей ширпотребовской памяти должна стать выше, ведь я знаю, что остальные ячейки ведут себя стабильно при нагреве до 100 °C.
Как вы понимаете, node_exporter продолжил падать, но мы же знали, что эта проблема была несерьёзной, верно?
Копаем глубже
В этом баге меня раздражало то, что причина явно была в повреждении памяти, которое рушило исполняемый код. Это очень трудно отладить, потому что нельзя предсказать, что именно будет повреждено (проблема плавающая), и нельзя поймать плохой код за руку.
Сначала я попробовал разделить пополам доступные релизы node_exporter и включать/выключать разные сборщики, но это ничего мне не дало. Пытался запускать экземпляр под strace. Падения прекратились, что свидетельствовало о состоянии гонки. Позднее оказалось, что strace-экземпляр тоже падает, но этого пришлось ждать гораздо дольше. Я предположил, что дело в распараллеливании. Задал GOMAXPROCS=1, чтобы Go использовал только один системный поток выполнения. Падения снова прекратились, так что у меня появились аргументы в пользу проблемы распараллеливания.
К тому времени я собрал большое количество логов падений и начал подмечать некоторые закономерности. Хотя места и порядок падений сильно менялись, но в целом сообщения об ошибках можно было разделить на три группы, и одна из ошибок возникала чаще одного раза. Я залез в поисковик и наткнулся на проблему в Go № 20427. Вроде бы она относилась к другой части Go, но приводила к таким же segfault и случайным сбоям. Тикет был закрыт без анализа, потому что ситуацию не удалось воспроизвести в Go 1.9. Никто не знал, в чём корень проблемы, она просто прекратилась.
Я взял код из отчёта об ошибке, который приводил к сбоям, и запустил у себя. О чудо, через секунды получил падение. Попал! Так гораздо лучше, чем часами ожидать падения node_exporter.
Это не приблизило меня к отладке на стороне Go, но позволило тестировать решения гораздо быстрее. Попробуем с другой стороны
Проверяем на машинах
Сбои возникают на моём ноутбуке, но не на других моих компьютерах. Я попробовал воспроизвести баг на всех серверах, к которым был лёгкий доступ, и не столкнулся ни с одним падением. Значит, на моём ноуте есть что-то особенное. Go статично связывает бинарники, так что остальное пользовательское пространство не имеет значения. Остаётся два кандидата: железо или ядро ОС.
Из железа мне доступны только мои компьютеры, но зато я могу протестировать ядра. Первый вопрос: будет ли падение в виртуальной машине?
Я сделал минимальную initramfs (initial ram file system), чтобы очень быстро запускать в виртуальной машине QEMU код воспроизведения сбоев без установки дистрибутива или загрузки полной версии Linux. Моя initramfs была построена на линуксовом scripts/gen_initramfs_list.sh и содержала файлы:
dir /dev 755 0 0
nod /dev/console 0600 0 0 c 5 1
nod /dev/null 0666 0 0 c 1 3
dir /bin 755 0 0
file /bin/busybox busybox 755 0 0
slink /bin/sh busybox 755 0 0
slink /bin/true busybox 755 0 0
file /init init.sh 755 0 0
file /reproducer reproducer 755 0 0/init — входная точка Linux-initramfs, в моём случае это был простой скрипт оболочки для запуска теста и измерения времени:
#!/bin/sh
export PATH=/bin
start=$(busybox date +%s)
echo "Starting test now..."
/reproducer
ret=$?
end=$(busybox date +%s)
echo "Test exited with status $ret after $((end-start)) seconds"/bin/busybox — статично связанная версия BusyBox, обычно используется в минимизированных системах вроде моей для предоставления всех основных утилит Linux-оболочки (включая саму оболочку).
Initramfs можно сделать так (на основе исходного дерева ядра Linux), где list.txt — вышеприведённый список файлов:
scripts/gen_initramfs_list.sh -o initramfs.gz list.txtА QEMU может напрямую загружать ядро и initramfs:
qemu-system-x86_64 -kernel /boot/vmlinuz-4.13.9-gentoo -initrd initramfs.gz -append 'console=ttyS0' -smp 8 -nographic -serial mon:stdio -cpu host -enable-kvmВ консоли ничего не отобразилось… затем я сообразил, что даже не скомпилировал в ядре на моём ноутбуке поддержку серийного порта 8250. Блин. У него же нет физического серийного порта, верно? Ладно, быстренько пересобрал ядро с поддержкой порта (и скрестил пальцы, чтобы не поменять ничего важного), попробовал снова, успешно загрузил и запустил воспроизводящий баг код.
Упал? Ага. Хорошо, сбой можно воспроизвести в виртуальной машине на том же компьютере. Попробовал ту же QEMU-команду на своём домашнем сервере, на его собственном ядре, и… ничего. Затем скопировал ядро с ноутбука, загрузил и… сбой. Всё дело в ядре. Это не железо.
Жонглируя ядрами
Я понимал, что придётся скомпилировать много ядер, чтобы выловить проблему. Решил делать это на своём самом мощном компьютере: довольно старом 12-ядерном Xeon с 24 потоками исполнения (он уже не работает, к сожалению). Скопировал исходный код сбойного ядра, собрал и протестировал.
Не упало.
Чё?
Поскрёб в голове, проверил, падает ли оригинальный бинарник ядра (упал). Неужели всё-таки железо? Неужели имеет значение, на каком компьютере я собираю ядро? Попробовал собрать на домашнем сервере, вскоре случилось падение. Если собрать одно ядро на двух машинах, то падения есть, а если собрать на третьей — падений нет. Почему так?
На всех трёх машинах стоит Linux Gentoo с изменениями Hardened Gentoo. Но на ноутбуке и домашнем сервере стоит ~amd64 (нестабильная версия), а на Xeon-сервере — amd64 (стабильная). То есть GCC разные. На ноуте и домашнем сервере стоял gcc (Gentoo Hardened 6.4.0 p1.0) 6.4.0, а на Xeon — gcc (Gentoo Hardened 5.4.0-r3 p1.3, pie-0.6.5) 5.4.0.
Но ядро на домашнем сервере, почти той же версии, что и на ноуте, собранное с помощью того же GCC, не воспроизвело падения. Получается, что важны оба компилятора, использованные для сборки ядра, а также само ядро (или его конфигурация)?
Для выяснения я скомпилировал на домашнем сервере точно такое же дерево ядра с моего ноутбука (linux-4.13.9-gentoo), оно падало. Потому скопировал .config с домашнего сервера и скомпилировал его — не падало. Получается, нужно учитывать разницу в конфигурациях и компиляторах:
linux-4.13.9-gentoo + gcc 5.4.0-r3 p1.3 + laptop .config— не падает.linux-4.13.9-gentoo + gcc 6.4.0 p1.0 + laptop .config— падает.linux-4.13.9-gentoo + gcc 6.4.0 p1.0 + server .config— не падает.
Два конфига, один хороший, второй плохой. Конечно, они сильно различались (я предпочитаю включать в конфигурацию своего ядра только те драйверы, что нужны на конкретном компьютере), так что пришлось последовательно пересобирать ядро, выискивая различия.
Решил начать с «точно плохого» конфига и стал выкидывать из него разные вещи. Поскольку воспроизводящий сбой код падал через разные промежутки времени, проще было тестировать на «всё ещё падает» (просто дожидаясь падения), чем на «не падает» (сколь придётся ждать, чтобы подтвердить отсутствие сбоя?). На протяжении 22 сборок ядра я настолько упростил конфигурацию, что ядро лишилось поддержки сети, файловой системы, основы блокового устройства и даже поддержки PCI (причём в виртуальной машине продолжало прекрасно работать!). Мои сборки занимали теперь меньше 60 секунд, а ядро стало примерно на ¾ меньше обычного.
Затем я перешёл к «точно хорошей» конфигурации и убрал всё ненужное барахло, проверяя, не падает ли воспроизводящий код (это было труднее и дольше, чем предыдущий тест). У меня было несколько ложных веток, когда я изменил что-то (не знаю что), рушащее воспроизводящий код. Я ошибочно пометил их как «не падающие», и, когда столкнулся с падениями, пришлось возвращаться к предыдущим собранным ядрам и выяснять, когда же именно появились падения. Я собрал семь ядер.
В конце концов я сузил зону поисков до небольшого количества различающихся опций. Некоторые привлекали внимание, например CONFIG_OPTIMIZE_INLINING. После осторожной проверки я убедился, что виновницей была именно эта опция. Если её выключить, то воспроизводящий код падает, а если включить, сбоев нет. Включение этой опции позволяет GCC определять, какие функции inline действительно нужно инлайнить, а не делать это принудительно. Это объясняет и связь с GCC: поведение инлайнинга наверняка различается в разных версиях компилятора.
/*
* Force always-inline if the user requests it so via the .config,
* or if gcc is too old.
* GCC does not warn about unused static inline functions for
* -Wunused-function. This turns out to avoid the need for complex #ifdef
* directives. Suppress the warning in clang as well by using "unused"
* function attribute, which is redundant but not harmful for gcc.
*/
#if !defined(CONFIG_ARCH_SUPPORTS_OPTIMIZED_INLINING) || \
!defined(CONFIG_OPTIMIZE_INLINING) || (__GNUC__ < 4)
#define inline inline __attribute__((always_inline,unused)) notrace
#define __inline__ __inline__ __attribute__((always_inline,unused)) notrace
#define __inline __inline __attribute__((always_inline,unused)) notrace
#else
/* A lot of inline functions can cause havoc with function tracing */
#define inline inline __attribute__((unused)) notrace
#define __inline__ __inline__ __attribute__((unused)) notrace
#define __inline __inline __attribute__((unused)) notrace
#endifЧто дальше? Мы знаем, что к падениям приводит опция CONFIG_OPTIMIZE_INLINING, но она может менять поведение каждой функции inline во всём ядре. Как вычислить корень зла?
Есть идея.
Дифференциальная компиляция на основе хешей
Замысел в том, чтобы компилировать одну часть ядра с включённой опцией, а другую часть — с выключенной. После проверки можно понять, какое подмножество вычислительных модулей ядра содержит проблемный код.
Вместо перечисления всех файлов объектов и выполнения бинарного поиска и я решил воспользоваться хешами. Написал скрипт-обёртку для GCC:
#!/bin/bash
args=("$@")
doit=
while [ $# -gt 0 ]; do
case "$1" in
-c)
doit=1
;;
-o)
shift
objfile="$1"
;;
esac
shift
done
extra=
if [ ! -z "$doit" ]; then
sha="$(echo -n "$objfile" | sha1sum - | cut -d" " -f1)"
echo "${sha:0:8} $objfile" >> objs.txt
if [ $((0x${sha:0:8} & (0x80000000 >> $BIT))) = 0 ]; then
echo "[n]" "$objfile" 1>&2
else
extra=-DCONFIG_OPTIMIZE_INLINING
echo "[y]" "$objfile" 1>&2
fi
fi
exec gcc $extra "${args[@]}"Он на основе имени файла объекта генерирует хеш SHA-1, затем проверяет один из первых 32 битов хеша (определяются по переменной среды $BIT). Если бит равен 0, собирается без CONFIG_OPTIMIZE_INLINING. Если равен 1, собирается с CONFIG_OPTIMIZE_INLINING. Я выяснил, что ядро содержит около 685 файлов объектов (помогли мои усилия по минимизации), так что для уникальной идентификации требовалось примерно 10 битов. У подхода с использованием хеша есть одна особенность: можно беспокоиться только о сбойных вариантах (бит равен 0), поскольку гораздо сложнее доказать, что данная сборка ядра не падает (падения вероятностны и могут происходить далеко не сразу).
Я собрал 32 ядра, по одному на каждый бит префикса SHA-1, это заняло всего 29 минут. Затем начал тестировать ядра и при каждом падении определял те регулярные выражения возможных хешей SHA-1, что имели на определённых позициях нулевые биты. После восьми падений (и нулевых битов) я вычислил четыре файла объектов, ещё пара оказалась под подозрением. После десяти падений совпадение было одно.
$ grep '^[0246][012389ab][0189][014589cd][028a][012389ab][014589cd]' objs_0.txt
6b9cab4f arch/x86/entry/vdso/vclock_gettime.oКод vDSO. Ну конечно.
Выходки vDSO
vDSO на самом деле не является кодом ядра. Это маленькая библиотека общего использования, которую ядро кладёт в адресное пространство каждого процесса. vDSO позволяет приложениям выполнять особые системные вызовы без выхода из пользовательского режима. Это значительно повышает производительность, при этом ядро при необходимости может менять подробности реализации этих системных вызовов.
Иными словами, vDSO — компилируемый GCC код, собираемый с ядром и в конце концов связываемый с каждым приложением в пользовательском пространстве. Это код пользовательского пространства. Теперь понятно, почему важны версии ядра и компилятора: дело не в самом ядре, а в библиотеке, идущей с ядром! Go использует vDSO для повышения производительности. Также в Go есть (довольно безумная, как я считаю) политика переизобретения собственной стандартной библиотеки, так что для вызова vDSO он не использует код стандартной Linux-библиотеки glibc, а выкатывает собственные вызовы (и системные тоже).
Как переключение CONFIG_OPTIMIZE_INLINING влияет на vDSO? Посмотрим на машинный код.
С CONFIG_OPTIMIZE_INLINING=n:
arch/x86/entry/vdso/vclock_gettime.o.no_inline_opt: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 :
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 90 nop
5: 90 nop
6: 90 nop
7: 0f 31 rdtsc
9: 48 c1 e2 20 shl $0x20,%rdx
d: 48 09 d0 or %rdx,%rax
10: 48 8b 15 00 00 00 00 mov 0x0(%rip),%rdx # 17
17: 48 39 c2 cmp %rax,%rdx
1a: 77 02 ja 1e
1c: 5d pop %rbp
1d: c3 retq
1e: 48 89 d0 mov %rdx,%rax
21: 5d pop %rbp
22: c3 retq
23: 0f 1f 00 nopl (%rax)
26: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
2d: 00 00 00
0000000000000030 <__vdso_clock_gettime>:
30: 55 push %rbp
31: 48 89 e5 mov %rsp,%rbp
34: 48 81 ec 20 10 00 00 sub $0x1020,%rsp
3b: 48 83 0c 24 00 orq $0x0,(%rsp)
40: 48 81 c4 20 10 00 00 add $0x1020,%rsp
47: 4c 8d 0d 00 00 00 00 lea 0x0(%rip),%r9 # 4e <__vdso_clock_gettime+0x1e>
4e: 83 ff 01 cmp $0x1,%edi
51: 74 66 je b9 <__vdso_clock_gettime+0x89>
53: 0f 8e dc 00 00 00 jle 135 <__vdso_clock_gettime+0x105>
59: 83 ff 05 cmp $0x5,%edi
5c: 74 34 je 92 <__vdso_clock_gettime+0x62>
5e: 83 ff 06 cmp $0x6,%edi
61: 0f 85 c2 00 00 00 jne 129 <__vdso_clock_gettime+0xf9>
[...] С CONFIG_OPTIMIZE_INLINING=y:
arch/x86/entry/vdso/vclock_gettime.o.inline_opt: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <__vdso_clock_gettime>:
0: 55 push %rbp
1: 4c 8d 0d 00 00 00 00 lea 0x0(%rip),%r9 # 8 <__vdso_clock_gettime+0x8>
8: 83 ff 01 cmp $0x1,%edi
b: 48 89 e5 mov %rsp,%rbp
e: 74 66 je 76 <__vdso_clock_gettime+0x76>
10: 0f 8e dc 00 00 00 jle f2 <__vdso_clock_gettime+0xf2>
16: 83 ff 05 cmp $0x5,%edi
19: 74 34 je 4f <__vdso_clock_gettime+0x4f>
1b: 83 ff 06 cmp $0x6,%edi
1e: 0f 85 c2 00 00 00 jne e6 <__vdso_clock_gettime+0xe6>
[...]Любопытно, CONFIG_OPTIMIZE_INLINING=y должен позволять GCC инлайнить меньше, а на деле компилятор инлайнит больше: в этой версии vread_tsc оказалась инлайненной, в отличие от версии с CONFIG_OPTIMIZE_INLINING=n. Но vread_tsc вообще не помечена как inline, так что GCC повёл себя целиком в рамках дозволенного, хотя на первый взгляд это и не так.
Но что плохого в инлайнинге функции? В чём проблема? Давайте посмотрим на неинлайненную версию…
30: 55 push %rbp
31: 48 89 e5 mov %rsp,%rbp
34: 48 81 ec 20 10 00 00 sub $0x1020,%rsp
3b: 48 83 0c 24 00 orq $0x0,(%rsp)
40: 48 81 c4 20 10 00 00 add $0x1020,%rspПочему GCC выделяет больше 4 Кб в стеке? Это не выделение памяти в стеке, это стековый зонд (stack probe), а точнее — результат свойства GCC -fstack-check.
В Linux Gentoo Hardened -fstack-check включено по умолчанию. Это сделано для закрытия уязвимости Stack Clash. Хотя -fstack-check — старое свойство GCC и не предназначалось для этой задачи, но всё же успешно закрывает уязвимость (мне сказали, что нормальная защита от Stack Clash появится в GCC 8). Но есть побочный эффект: каждая функция, не относящаяся к листьям дерева ядра (функция, вызывающая функции), перед указателем стека размещает 4 Кб стекового зонда. То есть код, скомпилированный с -fstack-check, потребует как минимум 4 Кб памяти в стеке, если это не функция-«лист» (или функция, в которой каждый вызов инлайненный).
Go любит маленькие стеки.
TEXT runtime·walltime(SB),NOSPLIT,$16
// Be careful. We're calling a function with gcc calling convention here.
// We're guaranteed 128 bytes on entry, and we've taken 16, and the
// call uses another 8.
// That leaves 104 for the gettime code to use. Hope that's enough!Похоже, 104 байтов на всех не хватит. Уж точно не моему ядру.
Надо сказать, что спецификация vDSO не упоминает о необходимости использования максимального стека, так что это исключительно Go виноват в том, что он делает ошибочные предположения.
Заключение
Это полностью объясняет все симптомы. Стековый зонд — это orq, логическое ИЛИ с 0. Холостая инструкция, но эффективно зондирующая целевые адреса (если они не распределены, возникает segfault). Но в коде vDSO не было segfaults, почему же Go ломается? Дело в том, что ИЛИ с 0 не совсем холостая инструкция. Поскольку orq не атомарная инструкция, процессор считывает адрес памяти и записывает в него. Возникает состояние гонки. Если в других процессорах параллельно выполняются другие потоки, orq может в то же время прервать запись в память. Поскольку запись выполнялась вне границ стека, то наверняка она вторглась в стеки других потоков выполнения или в случайные данные, и когда звёзды выстраивались нужным образом, то запись в память прерывалась. В том числе и поэтому GOMAXPROCS=1 имеет отношение к описанной проблеме, этот параметр не позволяет двум потокам выполнения одновременно выполнять код Go.
Как исправить? Я оставил это на усмотрение разработчикам Go. Они решили увеличить стек перед вызовом функций vDSO. Это немножко уменьшило скорость (наносекунды), но вполне приемлемо. После сборки node_exporter с исправленным Go падения прекратились.
