[Перевод] Отладка скрытых утечек памяти в Ruby

В 2015-м я написал об инструментарии, который Ruby предоставляет для обнаружения управляемых утечек памяти. В основном статья рассказывала о легко управляемых утечках. На этот раз я расскажу об инструментах и хитростях, которые вы можете применять для ликвидации утечек, которые в Ruby не так легко проанализировать. В частности, я расскажу о mwrap, heaptrack, iseq_collector и chap.
Эта маленькая программа провоцирует утечку с помощью прямого вызова malloc. Он начинает с потребления 16 Мб RSS, а заканчивает на 118 Мб. Код размещает в памяти 100 тыс. блоков по 1024 байтов и удаляет 50 тыс. из них.
require 'fiddle'
require 'objspace'
def usage
rss = `ps -p #{Process.pid} -o rss -h`.strip.to_i * 1024
puts "RSS: #{rss / 1024} ObjectSpace size #{ObjectSpace.memsize_of_all / 1024}"
end
def leak_memory
pointers = []
100_000.times do
i = Fiddle.malloc(1024)
pointers << i
end
50_000.times do
Fiddle.free(pointers.pop)
end
end
usage
# RSS: 16044 ObjectSpace size 2817
leak_memory
usage
# RSS: 118296 ObjectSpace size 3374
Несмотря на то, что RSS составляет 118 Мб, нашему объекту Ruby известно только о трёх мегабайтах. При анализе мы видим лишь очень маленькую часть этой очень большой утечки памяти.
Реальный пример такой утечки описан Олегом Дашевским, рекомендую прочитать эту замечательную статью.
Mwrap — это профилировщик памяти для Ruby, который отслеживает все размещения данных в памяти, перехватывая malloc и другие функции этого семейства. Он перехватывает вызовы, которые размещают и освобождают память с помощью LD_PRELOAD. Для подсчёта он использует liburcu и может отслеживать счётчики размещения и удаления из памяти по каждой точке вызова, в коде на C и Ruby. Mwrap небольшой по размеру, примерно вдвое больше RSS для профилируемой программы и примерно вдвое медленнее.
Он отличается от многих других библиотек очень маленьким размером и поддержкой Ruby. Он отслеживает местоположения в файлах Ruby и не ограничивается бэктреками С-уровня valgrind+masif и аналогичными профилировщиками. Это сильно упрощает изолирование источников проблем.
Для использования профилировщика нужно запустить приложение через оболочку Mwrap, она внедрит среду LD_PRELOAD и выполнит бинарник Ruby.
Давайте добавим Mwrap к нашему скрипту:
require 'mwrap'
def report_leaks
results = []
Mwrap.each do |location, total, allocations, frees, age_total, max_lifespan|
results << [location, ((total / allocations.to_f) * (allocations - frees)), allocations, frees]
end
results.sort! do |(_, growth_a), (_, growth_b)|
growth_b <=> growth_a
end
results[0..20].each do |location, growth, allocations, frees|
next if growth == 0
puts "#{location} growth: #{growth.to_i} allocs/frees (#{allocations}/#{frees})"
end
end
GC.start
Mwrap.clear
leak_memory
GC.start
# Don't track allocations for this block
Mwrap.quiet do
report_leaks
end
Теперь запустим скрипт с обёрткой Mwrap:
% gem install mwrap
% mwrap ruby leak.rb
leak.rb:12 growth: 51200000 allocs/frees (100000/50000)
leak.rb:51 growth: 4008 allocs/frees (1/0)
Mwrap корректно определил утечку в скрипте (50,000×1024). И не просто определил, но ещё и изолировал конкретную строку (i = Fiddle.malloc(1024)), которая привела к утечке. Профилировщик корректно привязал её к вызовам Fiddle.free.
Важно отметить, что мы имеем дело с оценкой. Mwrap отслеживает общую память, выделенную точкой вызова, а затем отслеживает освобождение памяти. Но если у вас есть одна точка вызова, которая выделяет блоки памяти разного размера, результат будет неточным. У нас есть доступ к оценке: ((total / allocations) * (allocations - frees))
Кроме того, для упрощения отслеживания утечек Mwrap отслеживает age_total, который является суммой продолжительности жизни каждого освобождённого объекта, а также отслеживает max_lifespan — продолжительность жизни самого старого объекта в точке вызова. Если значение age_total / frees велико, значит потребление памяти растёт несмотря на многочисленные сборки мусора.
У mwrap есть несколько помощников для уменьшения шума. Mwrap.clear очистит всё внутреннее хранилище. Mwrap.quiet {} заставит Mwrap отслеживать блок кода.
Другой отличительной особенностью Mwrap является отслеживание общего количества выделенных и освобожденных байтов. Удалим clear из скрипта и запустим его:
usage
puts "Tracked size: #{(Mwrap.total_bytes_allocated - Mwrap.total_bytes_freed) / 1024}"
# RSS: 130804 ObjectSpace size 3032
# Tracked size: 91691
Результат очень интересный, потому что несмотря на размер RSS в 130 Мб Mwrap видит только 91 Мб. Это говорит о том, что мы раздули наш процесс. Исполнение без Mwrap показывает, что в обычной ситуации процесс занимает 118 Мб, и в этом простом случае разница составила 12 Мб. Паттерн выделение/освобождение памяти привёл к фрагментации. Это знание может быть очень полезным, в ряде случаев ненастроенные процессы glibc malloc фрагментируют так сильно, что очень большой объём памяти, занятый в RSS, на самом деле является свободным.
В своей статье Олег обсуждает очень основательный способ изолирования очень тонкой утечки в redcarpet. Там множество подробностей. Очень важно проводить измерения. Если вы не строите график для процесса RSS, то вряд ли вам удастся избавиться от каких-либо утечек.
Давайте сядем в машину времени и продемонстрируем, насколько легче использовать Mwrap для таких утечек.
def red_carpet_leak
100_000.times do
markdown = Redcarpet::Markdown.new(Redcarpet::Render::HTML, extensions = {})
markdown.render("hi")
end
end
GC.start
Mwrap.clear
red_carpet_leak
GC.start
# Don't track allocations for this block
Mwrap.quiet do
report_leaks
end
Redcarpet 3.3.2:
redcarpet.rb:51 growth: 22724224 allocs/frees (500048/400028)
redcarpet.rb:62 growth: 4008 allocs/frees (1/0)
redcarpet.rb:52 growth: 634 allocs/frees (600007/600000)
Redcarpet 3.5.0:
redcarpet.rb:51 growth: 4433 allocs/frees (600045/600022)
redcarpet.rb:52 growth: 453 allocs/frees (600005/600000)
Если вы можете позволить себе исполнить процесс с вдвое меньшей скоростью, просто перезапустив его в проде с Mwrap с журналированием результата в файл, то вы сможете идентифицировать широкий спектр утечек памяти.
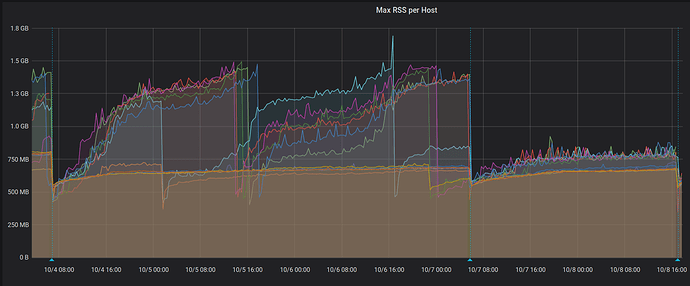
Недавно Rails обновился до версии 6. В целом, опыт оказался очень положительным, производительность осталась примерно той же. Rails 6 имеет несколько очень хороших возможностей, которые мы будем использовать (например, Zeitwerk). В Rails изменён способ отрисовки шаблонов, что потребовало внесения нескольких изменений ради совместимости. Через несколько дней после обновления мы заметили рост RSS для исполнителя задач Sidekiq.
Mwrap сообщил о резком повышении потребления памяти из-за её выделения (ссылка):
source.encode!
# Now, validate that the source we got back from the template
# handler is valid in the default_internal. This is for handlers
# that handle encoding but screw up
unless source.valid_encoding?
raise WrongEncodingError.new(source, Encoding.default_internal)
end
begin
mod.module_eval(source, identifier, 0)
rescue SyntaxError
# Account for when code in the template is not syntactically valid; e.g. if we're using
# ERB and the user writes <%= foo( %>, attempting to call a helper `foo` and interpolate
# the result into the template, but missing an end parenthesis.
raise SyntaxErrorInTemplate.new(self, original_source)
end
end
def handle_render_error(view, e)
if e.is_a?(Template::Error)
Сначала нас это сильно озадачило. Мы пытались понять, чем недоволен Mwrap? Может быть, он сломался? Пока потребление памяти росло, кучи в Ruby оставались неизменными.
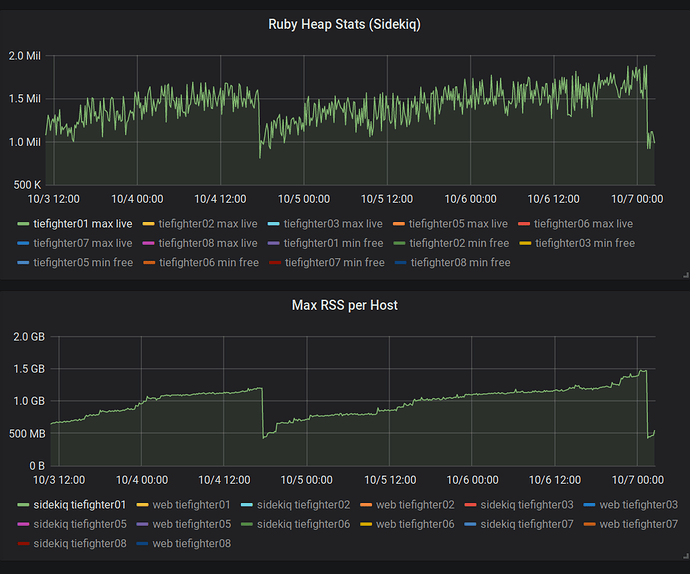
Два миллиона слотов в куче потребляли всего лишь 78 Мб (по 40 байтов на слот). Строки и массивы могут занимать больше места, но это всё-равно не объясняло аномального потребления памяти, которое мы наблюдали. Это подтвердилось, когда я выполнил rbtrace -p SIDEKIQ_PID -e ObjectSpace.memsize_of_all.
Куда подевалась память?
Heaptrack — это профилировщик памяти для кучи под Linux.
Милиан Вольф (Milian Wolff) прекрасно объяснил, как работает профилировщик, и рассказывал о нём в нескольких выступлениях (1, 2, 3). По сути, это очень эффективный нативный профилировщик кучи, который с помощью libunwind собирает бэктрейсы из профилируемых приложений. Он работает заметно быстрее Valgrind/Massif и обладает возможностью, которая делает его гораздо более удобным для временного профилирования в проде. Его можно прикреплять к уже запущенному процессу!
Как и в случае с большинством профилировщиков кучи, при вызове каждой функции из семейства malloc Heaptrack должен произвести подсчёт. Эта процедура определённо несколько замедляет работу процесса.
На мой взгляд, архитектура здесь самая лучшая из всех возможных. Перехват выполняется использованием LD_PRELOAD или GDB для загрузки профилировщика. С помощью специального файла FIFO он максимально быстро передаёт данные из профилируемого процесса. Обёртка heaptrack представляет собой простой оболочечный скрипт, упрощающий поиск проблемы. Второй процесс считывает информацию из FIFO и на лету сжимает данные отслеживания. Поскольку Heaptrack оперирует «чанками», вы можете анализировать профиль уже через несколько секунд после начала профилирования, прямо посреди сессии. Просто скопируйте файл профиля в другое место и запустите графический интерфейс Heaptrack.
Этот тикет на GitLab подсказал мне о самой возможности запуска Heaptrack. Если они смогли его запустить, то и я смогу.
Наше приложение работает в контейнере, и мне нужно перезапустить его с --cap-add=SYS_PTRACE, это позволяет GDB использовать ptrace, необходимый, чтобы Heaptrack смог себя внедрить. Также мне нужен небольшой хак для shell-файла, чтобы применять root к профилю не-root процесса (мы запустили наше приложение Discourse в контейнере под ограниченным аккаунтом).
После того, как всё было сделано, осталось только выполнить heaptrack -p PID и ждать появления результатов. Heaptrack оказался превосходным инструментом, было очень легко отслеживать всё происходящее с утечками памяти.
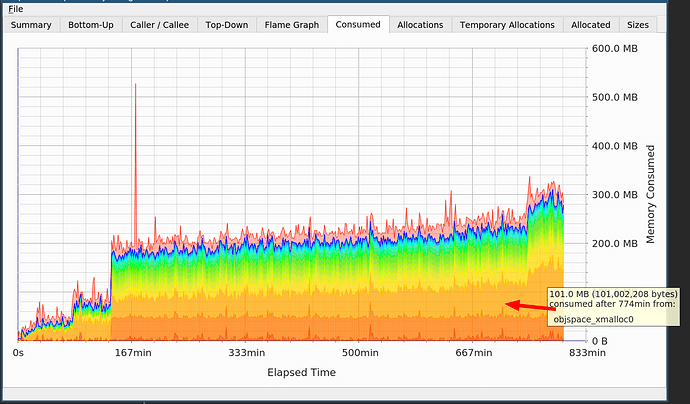
На графике вы видите два скачка, один из-за cppjieba, другой из-за objspace_xmalloc0 в Ruby.
Я знал о cppjieba. Сегментировать китайский язык дорого, нужны большие словари, так что это не утечка. Но что насчёт выделения памяти в Ruby, который ещё и не говорит мне об этом?
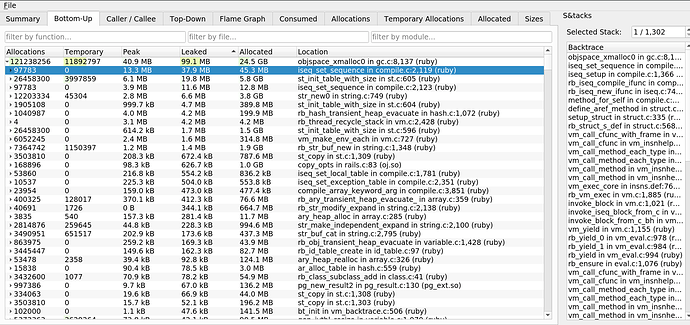
Основной прирост связан с iseq_set_sequence в compile.c. Получается, что утечка возникает из-за последовательностей инструкций. Это прояснило ситуацию с утечкой, обнаруженной Mwrap. Её причиной была mod.module_eval(source, identifier, 0), которая создавала последовательности инструкций, не удалявшиеся из памяти.
Если бы при ретроспективном анализе я тщательно рассмотрел дамп кучи из Ruby, то я бы заметил все эти IMEMO, поскольку они включаются в этот дамп. Просто они невидимы при внутрипроцессной диагностике.
С этого момента отладка была довольно простой. Я отслеживал все вызовы модуля eval и дампил то, что он оценивал. Я обнаружил, что мы снова и снова добавляем методы в большой класс. Вот упрощённое представление бага, с которым мы столкнулись:
require 'securerandom'
module BigModule; end
def leak_methods
10_000.times do
method = "def _#{SecureRandom.hex}; #{"sleep;" * 100}; end"
BigModule.module_eval(method)
end
end
usage
# RSS: 16164 ObjectSpace size 2869
leak_methods
usage
# RSS: 123096 ObjectSpace size 5583
В Ruby есть класс для хранения вызванных последовательностей инструкций: RubyVM::InstructionSequence. Однако Ruby лень создавать эти объекты-обёртки, потому что хранить их без необходимости неэффективно. Коичи Сасада (Koichi Sasada) создал зависимость iseq_collector. Если мы добавим этот код, то сможем находить нашу скрытую память:
require 'iseq_collector'
puts "#{ObjectSpace.memsize_of_all_iseq / 1024}"
# 98747
ObjectSpace.memsize_of_all_iseq
материализует каждую последовательность инструкций, которая может слегка увеличить потребление процессом памяти и дать сборщику мусора чуть больше работы.
Если мы, к примеру, посчитаем количество ISEQ до и после запуска сборщика, то увидим, что после запуска ObjectSpace.memsize_of_all_iseq наш счётчик класса RubyVM::InstructionSequence увеличится с 0 до 11128 (в этом примере):
def count_iseqs
ObjectSpace.each_object(RubyVM::InstructionSequence).count
end
Эти обёртки будут оставаться в течение всего жизненного цикла метода, их нужно будет посетить при полном прогоне сборщика мусора. Нашу проблему удалось решить с помощью повторного использования класса, отвечающего за отрисовку шаблонов электронной почты (исправление 1, исправление 2).
В ходе отладки я воспользовался очень интересным инструментом. Несколько лет назад Тим Бодди (Tim Boddy) извлёк внутренний инструмент, применяемый VMWare для анализа утечек памяти, и сделал его код открытым. Вот единственное видео об этом, которое мне удалось найти: https://www.youtube.com/watch? v=EZ2n3kGtVDk. В отличие от большинства подобных инструментов, этот никак не влияет на исполняемый процесс. Он может просто применяться к файлам основного дампа, при этом в качестве аллокатора используется glibc (отсутствует поддержка jemalloc/tcmalloc и т.п.).
С помощью chap можно очень легко обнаружить утечку, которая у меня была. Мало в каких дистрибутивах есть бинарник для chap, но вы можете легко собрать его из исходного кода. Он очень активно поддерживается.
# 444098 is the `Process.pid` of the leaking process I had
sudo gcore -p 444098
chap core.444098
chap> summarize leaked
Unsigned allocations have 49974 instances taking 0x312f1b0(51,573,168) bytes.
Unsigned allocations of size 0x408 have 49974 instances taking 0x312f1b0(51,573,168) bytes.
49974 allocations use 0x312f1b0 (51,573,168) bytes.
chap> list leaked
...
Used allocation at 562ca267cdb0 of size 408
Used allocation at 562ca267d1c0 of size 408
Used allocation at 562ca267d5d0 of size 408
...
chap> summarize anchored
....
Signature 7fbe5caa0500 has 1 instances taking 0xc8(200) bytes.
23916 allocations use 0x2ad7500 (44,922,112) bytes.
Для поиска мест выделения различной памяти chap может использовать сигнатуры, а также он может дополнять GDB. При отладке в Ruby он может оказать огромную помощь в определении, какая именно память используется процессом. Он показывает общую используемую память, иногда glibc malloc может фрагментировать так сильно, что используемый объём может разительно отличаться от фактического RSS. Можете почитать обсуждение: Feature #14759: [PATCH] set M_ARENA_MAX for glibc malloc — Ruby master — Ruby Issue Tracking System. Chap способен корректно подсчитывать всю используемую память и предоставлять глубокий анализ её выделения.
Кроме того, chap можно интегрировать в рабочие процессы, чтобы он автоматически определял утечки и помечал такие сборки.
Этот раунд отладки заставил меня поднять несколько вопросов, связанных с нашими вспомогательными наборами инструментов:
- Мне хотелось бы иметь в Heaptrack поддержку захвата из Ruby фреймов стека вызовов. В этом заинтересован и Милиан: 412929 — Can we grab a frame from Ruby land?
- Мне хотелось бы, чтобы Ruby поддерживал более широкие возможности по диагностике: https://bugs.ruby-lang.org/issues/16245
- Мне хотелось бы, чтобы Mwrap был чуть проще в использовании в проде. Читайте здесь.
Наш сегодняшний инструментарий для отладки очень сложных утечек памяти гораздо лучше того, что было 4 года назад! Mwrap, Heaptrack и chap — очень мощные инструменты для решения проблем, связанных с памятью, которые возникают при разработке и в эксплуатации.
Если вы охотитесь на простую утечку памяти в Ruby, рекомендую почитать мою статью 2015-го года, по большей части она актуальна.
Надеюсь, вам будет проще, когда в следующий раз начнёте отлаживать сложную нативную утечку памяти.
