[Перевод] Осенний отчет о состоянии Haxe
26 октября в г. Линц-ам-Райн (Германия) прошла мини-конференция HaxeUp Sessions 2019, посвященная Haxe и смежным технологиям. И самым знаменательным ее событием был, конечно же, финальный релиз Haxe 4.0.0 (на момент публикации, то есть спустя примерно неделю, вышло обновление 4.0.1). В этом материале я хотел бы представить вам перевод первого доклада конференции — отчета о работе, проделанной командой Haxe за 2019 год.

Немного об авторе доклада:
Саймон работает с Haxe c 2010 года, когда он был еще студентом и писал работу, посвященную симуляции жидкостей во Flash. Реализация подобной симуляции требовала постоянных обращений к данным, описывающим состояние частиц (на каждом шаге осуществлялось более 100 запросов к массивам данных о состоянии каждой из ячеек в симуляции), при этом работа с массивами в ActionScript 3 не такая уж и быстрая. Поэтому первоначальная реализация попросту была нерабочей и требовалось найти решение для данной проблемы. В своих поисках Саймон натолкнулся на статью Николя Каннасса (создателя Haxe), посвященную недокументированным тогда опкодам Alchemy, которые не были доступны с помощью ActionScript, но Haxe позволял их использовать. Переписав симуляцию на Haxe с использованием опкодов, Саймон получил рабочую симуляцию! И так, благодаря медленным массивам в ActionScript, Саймон узнал о Haxe.
С 2011 года Саймон присоединился к разработке Haxe, он начал изучать OCaml (на котором написан компилятор) и вносить различные исправления в работу компилятора.
А с 2012 года он стал основным разработчиком компилятора. В том же году был создан Haxe Foundation (организация, основным целями которой являются развитие и поддержание экосистемы Haxe, помощь сообществу в организации конференций, консультационные услуги), и Саймон стал одним из его сооснователей.

В 2014–2015 году Саймон пригласил в Haxe Foundation Жозефину Пертозу, которая со временем стала отвечать за организацию конференций и связи с сообществом.
В 2016 году Саймон впервые выступил с докладом о Haxe, а в 2018 организовал первый HaxeUp Sessions.

Так что же произошло в мире Haxe за прошедший 2019 год?
В феврале и марте вышли 2 релиз-кандидата (4.0.0-rc1 и 4.0.0-rc2)
В апреле к команде Haxe Foundation присоединились Аурел Били (в качестве интерна) и Александр Кузьменко (в качестве разработчика компилятора).
В мае прошел Haxe US Summit 2019.
В июне вышел Haxe 4.0.0-rc3. А в сентябре — Haxe 4.0.0-rc4 и Haxe 4.0.0-rc5.

Haxe — это не только компилятор, но и целый набор различных инструментов, и в течение года работа над ними также постоянно велась:
Благодаря усилиям Энди Ли Haxe теперь использует Azure Pipelines вместо Travis CI и AppVeyor. Это значит, что сборка и автоматические тесты теперь выполняются гораздо быстрее.
Хью Сандерсон продолжает работу над hxcpp (библиотекой для поддержки C++ в Haxe).
Внезапно к работе над экстернами для Node.js присоединились пользователи Github terurou и takashiski.
Руди Гес работал над исправлениями и улучшениями для поддержки C# таргета.
Джордж Корни продолжает поддержку генератора HTML-экстернов.
Йенс Фишер работает над vshaxe (расширение для VS Code для работы с Haxe) и над многими другими проектами, связанными с Haxe.

И главным событием года конечно же стал долгожданный релиз Haxe 4.0.0 (а также neko 2.3.0), случайно совпавший с HaxeUp 2019 Linz:)

Основную часть доклада Саймон посвятил новым возможностям в Haxe 4.0.0 (о них вы также могли узнать из доклада Александра Кузьменко с прошедшего Haxe US Summit 2019).

Новый интерпретатор макросов eval в несколько раз быстрее старого. Саймон подробно рассказывал о нем в своем выступлении на Haxe Summit EU 2017. Но с тех пор в нем были улучшены возможности отладки кода, исправлено множество багов, переработана реализация строк.
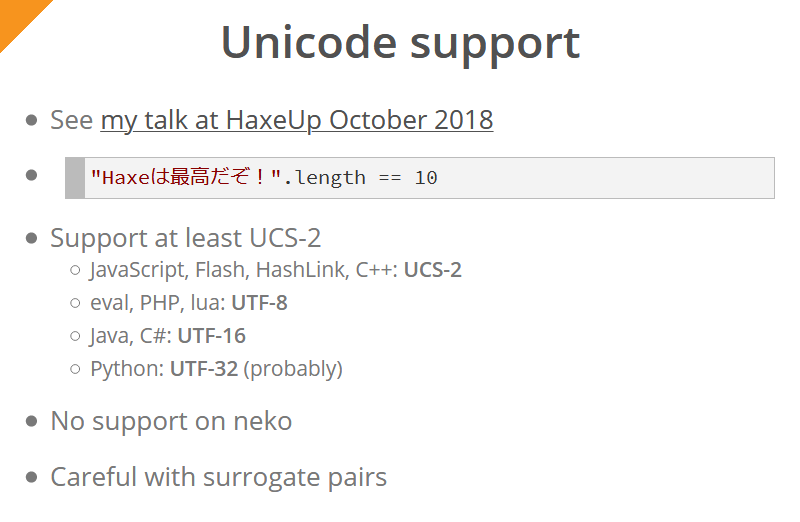
В Haxe 4 появилась поддержка юникод для всех платформ (кроме Neko). Подробно об этом Саймон рассказывал в своем прошлогоднем выступлении. Для конечного пользователя компилятора это означает то, что выражение "Haxeは最高だぞ!".length для всех платформ всегда будет возвращать 10 (опять же, кроме Neko).
Минимально поддерживается кодировка UCS-2 (для каждой платформы / языка используется нативно поддерживаемая кодировка; пытаться поддерживать везде одну и ту же кодировку было бы непрактично):
- для JavaScript, Flash, HashLink и C++ используется кодировка UCS-2
- для eval, PHP, lua — UTF-8
- для Java и C# — UTF-16
- для Python — UTF-32
Все символы, находящиеся за пределами основной многоязычной плоскости (в том числе и эмодзи), представляются в виде «суррогатных пар» — такие символы представляются двумя байтами. Например, если в Java/C#/JavaScript (то есть для строк в UTF-16 и UCS-2 кодировках) запросить длину строки, состоящей из одного эмодзи, то результатом будет »2». Этот факт нужно принимать во внимание при работе с такими строками на данных платформах.
В Haxe 4 появился новый вид итератора — «ключ-значение»:

Он работает с контейнерами типа Map (словари) и строками (с помощью класса StringTools), поддержка для массивов пока что не реализована. Также есть возможность реализовать такой итератор для пользовательских классов, для этого достаточно реализовать для них метод keyValueIterator():KeyValueIterator.
Новый мета-тэг @:using позволяет связывать статические расширения с типами по месту их объявления.
В примере, приведенном на слайде ниже, перечисление MyOption связывается с MyOptionTools, таким образом мы статически расширяем данное перечисление (что в обычной ситуации невозможно) и получаем возможность вызывать метод get(), обращаясь к нему как к методу объекта.

В этом примере метод get() является встраиваемым (inline), что также позволяет компилятору дополнительно оптимизировать код: вместо вызова метода MyOptionTools.get(myOption), компилятор подставит хранимое значение, то есть 12.
Если же метод не объявлен как встраиваемый, то еще одним средством оптимизации, доступным программисту, является встраивание функций по месту их вызова (call-site inlining). Для этого при вызове функции нужно дополнительно использовать ключевое слово inline:

Благодаря работе Даниила Коростелева в Haxe появилась возможность генерации ES6-классов для JavaScript. Все что нужно для этого сделать — просто добавить флаг компиляции -D js-es=6.
В настоящий момент компилятор генерирует один js-файл для всего проекта (возможно в будущем появится возможность генерации отдельных js-файлов для каждого из классов, но пока что это можно сделать только с помощью дополнительных инструментов).

Для абстрактных перечислений теперь автоматически генерируются значения.
В Haxe 3 было необходимо вручную задавать значения для каждого конструктора. В Haxe 4 абстрактные перечисления, созданные поверх Int, ведут себя по тем же правилам, что и в C. Аналогично ведут себя абстрактные перечисления, созданные поверх строк — для них сгенерированные значения будут совпадать с именами конструкторов.

Следует упомянуть также некоторые улучшения в синтаксисе:
- абстрактные перечисления и extern-функции стали полноценными полноценными членами Haxe и для их объявления теперь не нужно использовать мета-тэги
@:enumи@:extern - в 4-м Haxe используется новый синтаксис для объединения типов (type intersection), лучше отражающий суть расширения структур. Такие конструкции наиболее полезны при объявлении структур данных: выражение
typedef T = A & Bозначает, что структураTимеет все поля, которые есть в типахAиB - аналогично в четверке объявляются ограничения типов параметров (type parameters constraints): запись
Tдолжен быть одновременно иAиB. - старый синтаксис будет работать (за исключением синтаксиса для ограничений типов, т.к. он будет конфликтовать с новым синтаксисом описания типов функций)

Новый синтаксис для описания типов функций (function type syntax) является более логичным: использование скобок вокруг типов аргументов функции визуально легче воспринимается. Кроме того, новый синтаксис позволяет определять имена аргументов, что можно использовать как часть документации к коду (хотя никак не влияет на саму типизацию).

Старый синтаксис при этом продолжает поддерживаться и не объявлен устаревшим, т.к. в противном случае это потребовало бы слишком много изменений в существующем коде (сам Саймон постоянно ловит себя на том, что по привычке продолжает использовать старый синтаксис).
В Haxe 4 наконец-то появились стрелочные функции (или лямбда-выражения)!

Особенностями стрелочных функций в Haxe являются:
- неявный
return. Если тело функции состоит из одного выражения, то эта функция неявно возвращает значение этого выражения - есть возможность задавать типы аргументов функции, т.к. компилятор не всегда может определить требуемый тип (например,
FloatилиInt) - если тело функции состоит из нескольких выражений, то потребуется окружить его фигурными скобками
- но при этом нет возможности явно задать возвращаемый тип функции
В общем, синтаксис стрелочных функций очень похож на используемый в Java 8 (хотя и работает несколько иначе).
И раз уж мы упомянули Java, то следует сказать о том, что в Haxe 4 появилась возможность генерации JVM-байткода напрямую. Для этого при компиляции проекта под Java достаточно добавить флаг -D jvm.
Генерация JVM-байткода означает, что необходимость использования Java-компилятора отпадает, при этом процесс компиляции осуществляется значительно быстрее.

Пока что JVM-таргет имеет статус экспериментального по следующим причинам:
- в некоторых случаях байткод работает несколько медленнее, полученного в результате трансляции Haxe в Java и последующей компиляции с помощью javac. Но команда компилятора в курсе проблемы и знает как ее исправить, просто это требует дополнительной работы.
- есть проблемы с MethodHandle на Android, что также требует дополнительной работы (Саймон будет рад, если ему помогут в решении этих проблем).

Общее сравнение генерации байткода напрямую (genjvm) и компиляции Haxe в Java-код, который затем компилируется в байткод (genjava):
- как уже упоминалось, по скорости компиляции genjvm работает быстрее genjava
по скорости исполнения байткода genjvm пока что уступает genjava - есть некоторые проблемы при использовании параметров типов (type parameters) и genjava
- для ссылок на функции в genjvm используются MethodHandle, а в genjava — так называемые «Waneck-функции» (в честь Кауи Ванека, благодаря которому в Haxe появилась поддержка Java и C#). И хотя код, полученный с помощью Waneck-функций не выглядит красиво, он работает и работает достаточно быстро.
Общие советы при работе с Java в Haxe:
- благодаря тому, что сборщик мусора в Java работает быстро, проблемы связанные с ним редки. Конечно, постоянно создавать новые объекты — не очень хорошая идея, но Java достаточно хорошо справляется с управлением памятью и необходимость постоянно заботиться об аллокациях стоит не так остро, как на некоторых других платформах, поддерживаемых Haxe (например, в HashLink)
- обращение к полям класса в jvm-таргете может работать очень медленно в случае, когда это делается через структуру (
typedef) — пока что компилятор не может оптимизировать такой код - следует избегать чрезмерного использования ключевого слова
inline— JIT-компилятор неплохо справляется и сам - следует избегать использования
Null, особенно при работе со сложными математическими вычислениями. Иначе в сгенерированном коде появится множество условных операторов, что крайне негативно скажется на скорости исполнения вашего кода.
Избежать использования Null может помочь новая фича Haxe 4 — Null-безопасность (Null safety). Александр Кузьменко подробно о ней рассказал на прошлогоднем HaxeUp.

В примере на слайде выше для статического метода safe() включен Strict-режим проверок на Null-безопасность, при этом данный метод имеет необязательный параметр arg, который может иметь нулевое значение. Для того, чтобы данная функция успешно скомпилировалась, программисту потребуется добавить проверку значения аргумента arg (в противном случае компилятор выдаст сообщение о невозможности вызвать метод charAt() у потенциально нулевого объекта).
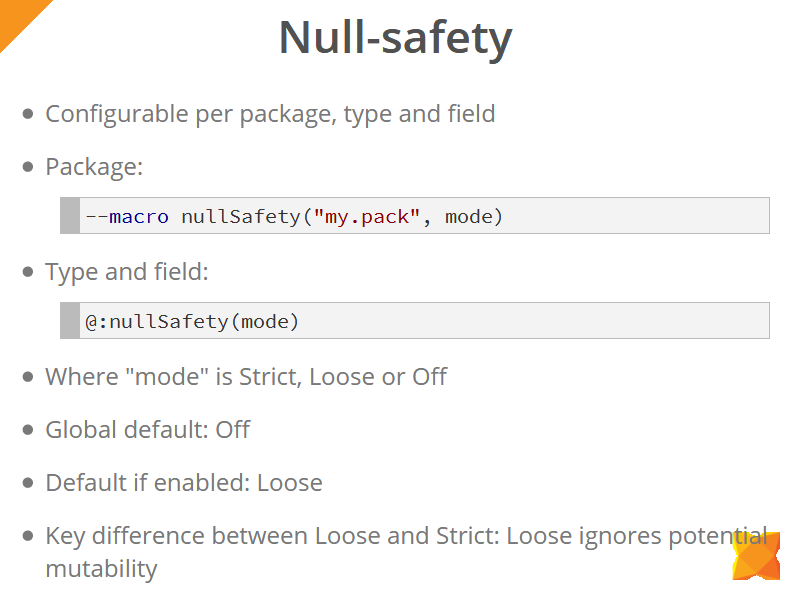
Null-безопасность можно настраивать как на уровне пакетов (с помощью макроса), так и типов и отдельных полей объектов (с помощью мета-тэга @:nullSafety).
Режимы, в которых работают проверки на Null-безопасность, следующий: Strict, Loose и Off. Глобально эти проверки отключены (Off-режим). При их включении по-умолчанию используется Loose-режим (если явно не указать режим). Ключевым отличием между Loose и Strict режимами является то, что Loose-режим игнорирует возможность изменения значений между операциями обращений к этим значениям. В примере на слайде ниже мы видим, что для переменной x добавлена проверка на null. Однако в Strict-режиме данный код не скомпилируется, т.к. перед непосредственной работой с переменной x вызывается метод sideEffect(), который потенциально может обнулить значение этой переменной, таким образом потребуется добавить еще одну проверку или скопировать значение переменной в локальную переменную, с которой и будем работать в дальнейшем.

В Haxe 4 появилось новое ключевое слово final, которое в зависимости от контекста имеет различный смысл:
- если использовать его вместо ключевого слова
var, то объявленному таким образом полю нельзя будет назначить новое значение. Задать его можно будет только напрямую при объявлении (для статических полей) или в конструкторе (для нестатических полей) - если использовать его при объявлении класса, то это запретит наследование от него
- если использовать его в качестве модификатора доступа к свойству объекта, то это запретить переопределение геттера / сеттера в классах-наследниках.

Теоретически компилятор, встретив ключевое слово final, может попытаться оптимизировать код, предполагая, что значение данного поля не меняется. Но пока что такая возможность только рассматривается и в компиляторе не реализована.

И немного о будущем Haxe:
- в настоящее время ведется работа над асинхронным API для работы с вводом/выводом
запланирована поддержка корутин, но пока что работа над ними застряла на этапе планирования. Возможно они появятся в Haxe 4.1, а возможно и позже - в компиляторе появится оптимизация хвостовых вызовов (tail-call optimization)
- и возможно появятся функции, доступные на уровне модуля. Хотя приоритет данной фичи постоянно меняется
