[Перевод] Оптимизация времени запуска Prometheus 2.6.0 с помощью pprof
В Prometheus 2.6.0 оптимизирована загрузка WAL, что ускоряет процесс запуска.
Неофициальная цель разработки Prometheus 2.x TSDB — ускорить запуск, чтобы он занимал не более минуты. В последние месяцы появились сообщения о том, что процесс немного затягивается, и если Prometheus по какой-либо причине перезапускается, то это — уже проблема. Почти все это время загружается WAL (регистрация записи с упреждением), включающий образцы за последние несколько часов, которые еще предстоит сжать в блок. В конце октября мне, наконец, удалось разобраться в этом; результат — PR#440, снижающий время работы ЦПУ в 6,5 раз и время расчета в 4 раза. Рассмотрим, каким образом я добился этих улучшений.

Во-первых, необходима тестовая установка. Я создал небольшую программу на Go, генерирующую TSDB с WAL с миллиардом образцов, разбросанных по 10.000 временных рядов. Затем я открыл этот TSDB и посмотрел, сколько времени занимает использование утилиты time (не встроенной структуры, поскольку она не включает статистику памяти), а также создал профиль ЦПУ с помощью пакета runtime/pprof:
f, err := os.Create("cpu.prof")
if err != nil {
log.Fatal(err)
}
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
Профиль ЦПУ не позволяет напрямую установить интересующее нас время расчета, однако существует значительная корреляция. В результате на моем настольном компьютере (процессор i7–3770 с 16 ГБ оперативной памяти и твердотельными накопителями) загрузка заняла около 4 минут и чуть менее 6 ГБ оперативной памяти на пике:
1727.50user 16.61system 4:01.12elapsed 723%CPU (0avgtext+0avgdata 5962812maxresident)k
23625165inputs+95outputs (196major+2042817minor)pagefaults 0swaps
Это не есть гуд, поэтому давайте загрузим профиль с помощью go tool pprof cpu.prof и посмотрим, сколько времени займет процесс, если использовать команду top.

Здесь flat — это количество времени, затраченного на данную функцию, а cum — время, затраченное на данную функцию и на все функции, вызванные ей. Также может быть полезно просмотреть эти данные в виде графика, чтобы получить представление о вопросе. Я предпочитаю использовать для этого команду web, но существуют и другие варианты, включая файлы svg, png и pdf.
Видно, что около трети нашего ЦПУ тратится на добавление образцов во внутреннюю базу данных, около двух третей — на обработку WAL в целом и четверть — на очистку памяти (runtime.scanobject). Давайте посмотрим на код первого из этих процессов с помощью list memSeries.*append:
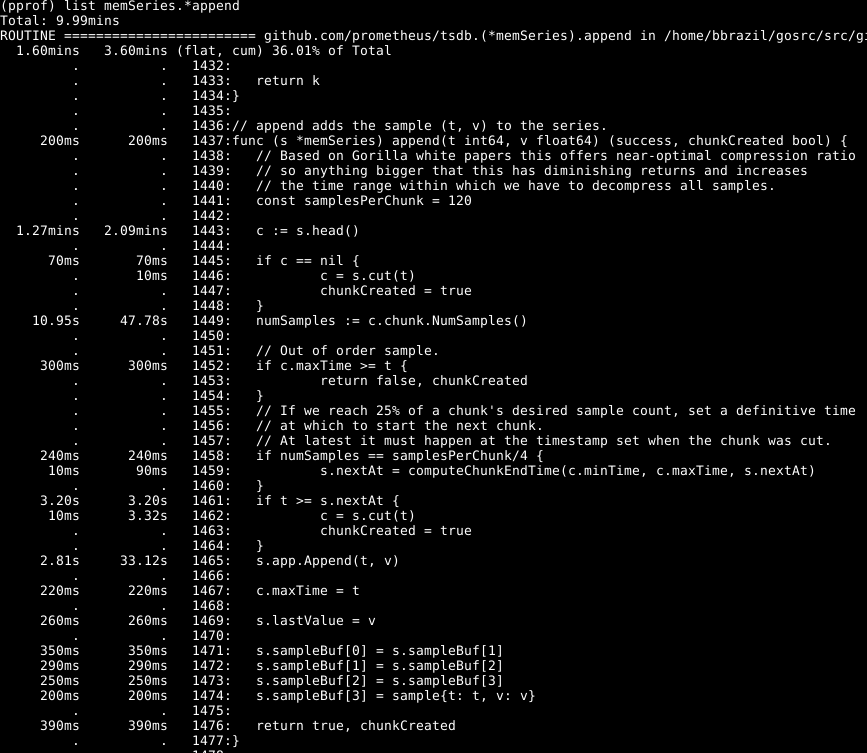
Здесь в глаза бросается следующее: больше половины времени тратится на то, чтобы получить головной фрагмент данных для серии в строке 1443. Также не маленькое время тратится на то, чтобы установить количество образцов в этом фрагменте данных в строке 1449. Временные затраты на дополнение строки 1465 — ожидаемы, поскольку это ядро действий данной функции. Соответственно, я ожидал, что операция займет большую часть времени.
Взгляните на элемент memSeries.head: он вычисляет фрагмент данных, который каждый раз возвращается. Фрагмент данных изменяется только после каждых 120 добавлений, и таким образом, мы можем сохранить текущий головной фрагмент в структуре данных ряда. Это занимает некоторую часть оперативной памяти (к чему я вернусь позднее), но экономит значительный объем ЦПУ. И в целом также ускоряет работу Prometheus.
Затем давайте взглянем на Head.processWALSamples:
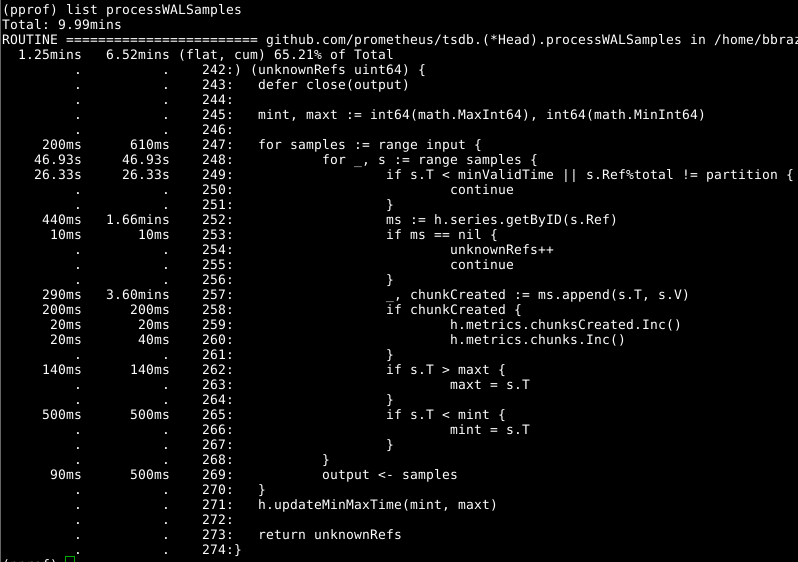
Это дополнение уже оптимизировано выше, так что смотрите на следующего очевидного виновника, getByID в строке 252:
(код)
Похоже, что существует некий конфликт блокировки, и время тратится на выполнение поиска по двухуровневой карте. Кэш для каждого идентификатора значительно сокращает этот показатель.
Стоит повторно взглянуть на Head.processWALSamples, и удивляешься, сколько потрачено времени в строке 249. Вернемся чуток назад, к вопросу о том, как функционирует загрузка WAL: гоурутина Head.processWALSamples создается для каждого имеющегося ЦПУ, в дополнение к еще одной для чтения и декодирования WAL с диска. Ряды сегментируются по этим гоурутинам, так что параллелизм может быть преимуществом. Способ реализации заключается в следующем: все образцы направляются в первую гоурутину, которая обрабатывает нужные ей элементы. Затем она направляет все образцы во вторую гоурутину, которая обрабатывает нужные ей элементы, и так далее, пока последняя гоурутина Head.processWALSamples не направит все данные обратно в управляющую гоурутину.
А пока дополнения распределяются по ядрам — что Вам и требуется, — также выполняется много дублирующихся задач в каждой гоурутине, которая должна обработать все образцы и произвести расчет модуля. По факту, чем больше ядер, тем больше работы дублируется. Я внес изменения для сегментирования данных в гоурутине контроллера, так что каждая гоурутина Head.processWALSamples теперь получает только нужные ей образцы. На моем компьютере — 8 работающих гоурутин — времени расчета сэкономилось чуть, зато объема ЦПУ — прилично. У компьютеров с большим количеством ядер преимущества должны быть существенней.
И снова возвращаемся к вопросу: время на очистку памяти. Мы не можем (обычно) определить это через профили ЦПУ. Вместо этого следует обратить внимание на профили динамической памяти, чтобы найти выделяющиеся элементы. Это требует некоторого расширения кода в конце программы:
runtime.GC()
hf, err := os.Create("heap.prof")
if err != nil {
log.Fatal(err)
}
pprof.WriteHeapProfile(hf)
Формальная очистка памяти связана с некоторой информацией в динамической памяти, сбор и очистка которой производится только во время очистки памяти.
Мы снова используем тот же инструмент, но указываем метку -alloc_space, поскольку нас интересуют все операции выделения памяти, а не только операции, использующие память в конкретный момент; таким образом, выполняем go tool pprof -alloc_space heap.prof. Если взглянуть на верхний распределитель, то виновник очевиден:
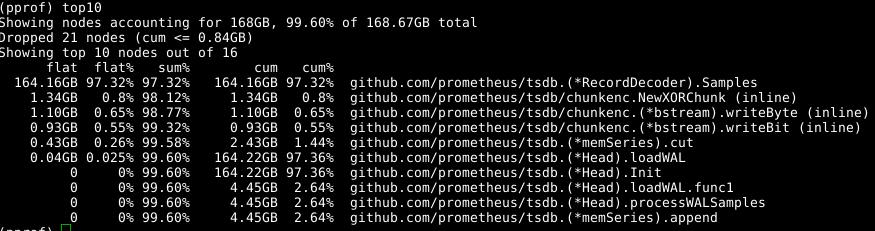
Взглянем на код:
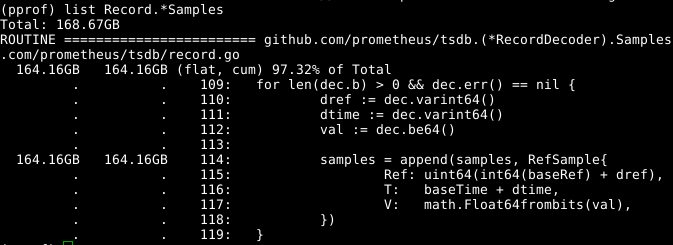
Кажется, что расширяемый массив samples является проблемой. Если бы мы могли повторно использовать массив одновременно с вызовом RecordDecoder.Samples, это позволило бы сэкономить значительный объем памяти. Оказывается, код был составлен именно таким образом, но небольшая ошибка кодирования привела к тому, что он не работал. Если исправить ее, память очищается за 8 секунд работы ЦПУ вместо 151 секунды.
Общие результаты довольно ощутимы:
269.18user 10.69system 1:05.58elapsed 426%CPU (0avgtext+0avgdata 3529556maxresident)k
23174929inputs+70outputs (815major+1083172minor)pagefaults 0swap
У нас не только время расчета сократилось в 4 раза, а время работы ЦПУ — в 6,5 раз, но еще и объем занятой памяти уменьшается более чем на 2 ГБ.
С виду вроде все просто, но фишка вот в чем: я прилично покопался в кодовой базе и анализирую все как бы задним числом. Изучая код, я несколько раз заходил в тупики, например, при удалении вызова NumSamples, выполнении чтения и декодирования в отдельных потоках, а также в нескольких вариантах сегментирования работы processWALSamples. Я почти уверен, что регулируя количество гоурутин, можно добиться большего, но для этого тесты надо проводить на машинах помощнее моей, чтобы ядер было больше. Я-то своей цели добился: производительность выросла, — и понял, что лучше не делать реестр программ слишком большим, а посему решил остановиться на достигнутом.
