[Перевод] Определяем подходящий размер для кластера Kafka в Kubernetes
Прим. перев.: В этой статье компания Banzai Cloud делится примером использования её специальных утилит для облегчения эксплуатации Kafka в рамках Kubernetes. Приводимые инструкции иллюстрируют, как можно определить оптимальный размер инфраструктуры и настроить саму Kafka для достижения требуемой пропускной способности.

Apache Kafka — распределённая стриминговая платформа для создания надёжных, масштабируемых и высокопроизводительных потоковых систем реального времени. Её впечатляющие возможности можно расширить с помощью Kubernetes. Для этого мы разработали Open Source-оператор Kafka и инструмент под названием Supertubes. Они позволяют запускать Kafka в Kubernetes и использовать её различные функции, такие как тонкая настройка конфигурации брокера, масштабирование на основе метрик с ребалансировкой, rack awareness (осведомлённость об аппаратных ресурсах), «мягкое» (graceful) выкатывание обновлений и т.д.
Попробуйте Supertubes в своём кластере:curl https://getsupertubes.sh | sh и supertubes install -a --no-democluster --kubeconfig
Или обратитесь к документации. Также можно почитать о некоторых возможностях Kafka, работа с которыми автоматизирована с помощью Supertubes и Kafka operator. О них мы уже писали в блоге:
Решив развернуть кластер Kafka в Kubernetes, вы наверняка столкнетесь с проблемой определения оптимального размера базовой инфраструктуры и необходимостью тонкой подстройки конфигурации Kafka для удовлетворения требований к пропускной способности. Максимальная производительность каждого брокера определяется производительностью компонентов инфраструктуры в его основе, таких как память, процессор, скорость диска, пропускная способность сети и т.д.
В идеале конфигурация брокера должна быть такой, чтобы все элементы инфраструктуры использовались на максимуме своих возможностей. Однако в реальной жизни такая настройка весьма сложна. Более вероятно, что пользователи будут настраивать конфигурацию брокеров таким образом, чтобы максимизировать использование одного или двух компонентов (диска, памяти или процессора). Вообще говоря, брокер показывает максимальную производительность, когда его конфигурация позволяет задействовать самый медленный компонент «по полной программе». Так мы можем получить примерное представление о нагрузке, с которой способен справиться один брокер.
Теоретически, мы также можем прикинуть число брокеров, необходимое для работы с заданной нагрузкой. Однако на практике вариантов настройки на различных уровнях столь много, что оценить потенциальную производительность некой конфигурации весьма сложно (если не невозможно). Другими словами, очень сложно спланировать конфигурацию, отталкиваясь от некой заданной производительности.
Для пользователей Supertubes мы обычно применяем следующий подход: начинаем с некоторой конфигурации (инфраструктура + настройки), затем измеряем её производительность, корректируем настройки брокера и повторяем процесс ещё раз. Это происходит до тех пор, пока потенциал самого медленного компонента инфраструктуры не будет полностью задействован.
Таким способом мы получаем более чёткое представление о том, сколько брокеров необходимо кластеру, чтобы справиться с определённой нагрузкой (количество брокеров также зависит от других факторов, таких как минимальное число реплик сообщений для обеспечения устойчивости, количество partition-лидеров и т.п.). Кроме того, мы получаем представление о том, для какого инфраструктурного компонента желательно масштабирование по вертикали.
В этой статье речь пойдёт о шагах, которые мы предпринимаем для того, чтобы «выжать всё» из самых медленных компонентов в начальных конфигурациях и измерить пропускную способность кластера Kafka. Высокоустойчивая конфигурация требует наличия по крайней мере трёх работающих брокеров (min.insync.replicas=3), разнесённых по трём разным зонам доступности. Для настройки, масштабирования и мониторинга инфраструктуры Kubernetes мы используем собственную платформу управления контейнерами для гибридных облаков — Pipeline. Она поддерживает on-premise (bare metal, VMware) и пять типов облаков (Alibaba, AWS, Azure, Google, Oracle), а также их любые сочетания.
Мысли по поводу инфраструктуры и конфигурации кластера Kafka
Для примеров, приведённых ниже, мы выбрали AWS в качестве поставщика облачных услуг и EKS в качестве дистрибутива Kubernetes. Аналогичную конфигурацию можно реализовать с помощью PKE — дистрибутива Kubernetes от Banzai Cloud, сертифицированного CNCF.
Диск
Amazon предлагает различные типы томов EBS. В основе gp2 и io1 лежат SSD-диски, однако для обеспечения высокой пропускной способности gp2 потребляет накопленные кредиты (I/O credits), поэтому мы предпочли тип io1, который предлагает стабильную высокую пропускную способность.
Типы инстансов
Производительность Kafka сильно зависит от страничного кэша операционной системы, поэтому нам нужны инстансы с достаточным количеством памяти для брокеров (JVM) и страничного кэша. Инстанс c5.2xlarge — неплохое начало, поскольку имеет 16 Гб памяти и оптимизирован для работы с EBS. Его недостатком является то, что он способен обеспечивать максимальную производительность на протяжении не более 30 минут каждые 24 часа. Если рабочая нагрузка требует максимальной производительности в течение более длительного промежутка времени, следует присмотреться к другим типам инстансов. Мы именно так и поступили, остановившись на c5.4xlarge. Он обеспечивает максимальную пропускную способность в 593,75 Мб/с. Максимальная пропускная способность тома EBS io1 выше, чем у инстанса c5.4xlarge, поэтому самый медленный элемент инфраструктуры, по всей видимости, это пропускная способность I/O этого типа инстанса (что также должны подтвердить результаты наших нагрузочных тестов).
Сеть
Пропускная способность сети должна оказаться достаточно большой по сравнению с производительностью инстанса VM и диска, в противном случае сеть становится узким местом. В нашем случае сетевой интерфейс c5.4xlarge поддерживает скорость до 10 Гб/с, что значительно выше пропускной способности I/O инстанса VM.
Развёртывание брокеров
Брокеры должны разворачиваться (планироваться в Kubernetes) на выделенные узлы, чтобы избежать конкуренции с другим процессами за ресурсы процессора, памяти, сети и диска.
Версия Java
Логичным выбором является Java 11, поскольку она совместима с Docker в том смысле, что JVM правильно определяет процессоры и память, доступные контейнеру, в котором работает брокер. Зная, что лимиты по процессорам важны, JVM внутренне и прозрачно устанавливает количество потоков GC и потоков JIT-компилятора. Мы использовали образ Kafka banzaicloud/kafka:2.13-2.4.0, включающий версию Kafka 2.4.0 (Scala 2.13) на Java 11.
Если вы желаете подробнее узнать о Java/JVM на Kubernetes, обратите внимание на следующие наши публикации:
Настройки памяти брокера
Существует два ключевых аспекта в настройке памяти брокера: настройки для JVM и для pod’а Kubernetes. Предел памяти, установленный для pod’а, должен быть больше, чем максимальный heap size, чтобы у JVM оставалось место для метапространства Java, которое находится в собственной памяти, и для страничного кэша операционной системы, который Kafka активно использует. Мы в своих тестах запускали брокеры Kafka с параметрами -Xmx4G -Xms2G, а предел памяти для pod’а составлял 10 Gi. Обратите внимание, что настройки памяти для JVM можно получать автоматом с помощью -XX:MaxRAMPercentage и -X:MinRAMPercentage, исходя из лимита памяти для pod’а.
Процессорные настройки брокера
Вообще говоря, можно поднять производительность, повысив параллелизм за счёт увеличения числа потоков, используемых Kafka. Чем больше процессоров доступны для Kafka, тем лучше. В нашем тесте мы начали с лимита в 6 процессоров и постепенно (итерациями) подняли их число до 15. Кроме того, мы установили num.network.threads=12 в настройках брокера, чтобы увеличить количество потоков, принимающих данные из сети и посылающих их. Сразу обнаружив, что брокеры-последователи не могут получать реплики достаточно быстро, подняли num.replica.fetchers до 4, чтобы увеличить скорость, с которой брокеры-последователи реплицировали сообщения от лидеров.
Инструмент генерирования нагрузки
Следует убедиться, что потенциал выбранного генератора нагрузки не иссякнет до того, как кластер Kafka (бенчмарк которого проводится) достигнет своей максимальной нагрузки. Другими словами, необходимо провести предварительную оценку возможностей инструмента генерирования нагрузки, а также выбрать для него типы instance’ов с достаточным количеством процессоров и памяти. В этом случае наш инструмент будет продуцировать больше нагрузки, чем способен переварить кластер Kafka. После множества опытов, мы остановились на трёх экземплярах c5.4xlarge, в каждом из которых был запущен генератор.
Бенчмаркинг
Измерение производительности — итеративный процесс, включающий следующие стадии:
- настройка инфраструктуры (кластера EKS, кластера Kafka, инструмента генерирования нагрузки, а также Prometheus и Grafana);
- генерирование нагрузки в течение определённого периода для фильтрации случайных отклонений в собираемых показателях производительности;
- подстройка инфраструктуры и конфигурации брокера на основе наблюдаемых показателей производительности;
- повторение процесса до тех пор, пока не будет достигнут требуемый уровень пропускной способности кластера Kafka. При этом он должен быть стабильно воспроизводимым и демонстрировать минимальные вариации пропускной способности.
В следующем разделе описаны шаги, которые выполнялись в процессе бенчмарка тестового кластера.
Инструменты
Для быстрого развёртывания базовой конфигурации, генерации нагрузки и измерения производительности использовались следующие инструменты:
- Banzai Cloud Pipeline для организации кластера EKS от Amazon c Prometheus (для сбора метрик Kafka и инфраструктуры) и Grafana (для визуализации этих метрик). Мы воспользовались интегрированными в Pipeline сервисами, которые обеспечивают федеративный мониторинг, централизованный сбор логов, сканирование уязвимостей, восстановление после сбоев, безопасность корпоративного уровня и многое другое.
- Sangrenel — инструмент для нагрузочного тестирования кластера Kafka.
- Панели Grafana для визуализации метрик Kafka и инфраструктуры: Kubernetes Kafka, Node Exporter.
- Supertubes CLI для максимально простой настройки кластера Kafka в Kubernetes. Zookeeper, Kafka operator, Envoy и множество других компонентов установлены и должным образом сконфигурированы для запуска готового к production кластера Kafka в Kubernetes.
- Для установки supertubes CLI воспользуйтесь инструкциями, приведенными здесь.

Кластер EKS
Подготовьте кластер EKS с выделенными рабочими узлами c5.4xlarge в различных зонах доступности для pod’ов с брокерами Kafka, а также выделенные узлы для генератора нагрузки и мониторинговой инфраструктуры.
banzai cluster create -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/cluster_eks_202001.json
Когда кластер EKS заработает, включите его интегрированную службу мониторинга — она развернёт Prometheus и Grafana в кластер.
Системные компоненты Kafka
Установите системные компоненты Kafka (Zookeeper, kafka-operator) в EKS с помощью supertubes CLI:
supertubes install -a --no-democluster --kubeconfig Кластер Kafka
По умолчанию в EKS используются тома EBS типа gp2, поэтому необходимо создать отдельный класс хранилищ на основе томов io1 для кластера Kafka:
kubectl create -f - <
Установите для брокеров параметр min.insync.replicas=3 и разверните pod’ы брокеров на узлах в трёх разных зонах доступности:
supertubes cluster create -n kafka --kubeconfig -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/kafka_202001_3brokers.yaml --wait --timeout 600 Топики
Мы параллельно запускали три экземпляра генератора нагрузки. Каждый из них пишет в свой топик, то есть всего нам нужно три топика:
supertubes cluster topic create -n kafka --kubeconfig -f -< -f -< -f -<
Для каждого топика фактор репликации равен 3 — минимальному рекомендованному значению для высокодоступных production-систем.
Инструмент генерирования нагрузки
Мы запускали три экземпляра генератора нагрузки (каждый писал в отдельный топик). Для pod’ов генератора нагрузки необходимо прописать node affinity, чтобы они планировались только на выделенные для них узлы:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: loadtest
name: perf-load1
namespace: kafka
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: loadtest
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: loadtest
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodepool.banzaicloud.io/name
operator: In
values:
- loadgen
containers:
- args:
- -brokers=kafka-0:29092,kafka-1:29092,kafka-2:29092,kafka-3:29092
- -topic=perftest1
- -required-acks=all
- -message-size=512
- -workers=20
image: banzaicloud/perfload:0.1.0-blog
imagePullPolicy: Always
name: sangrenel
resources:
limits:
cpu: 2
memory: 1Gi
requests:
cpu: 2
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
Несколько моментов, на которые следует обратить внимание:
- Генератор нагрузки генерирует сообщения длиной 512 байт и публикует их в Kafka партиями по 500 сообщений.
- С помощью аргумента
-required-acks=allпубликация признаётся успешной, когда все синхронизированные реплики сообщения получены и подтверждены брокерами Kafka. Это означает, что в бенчмарке мы измеряли не только скорость работы лидеров, получающих сообщения, но и их последователей, реплицирующих сообщения. В задачу данного теста не входит оценка скорости чтения потребителями (consumers) недавно принятых сообщений, которые пока остаются в страничном кэше ОС, и её сравнение со скоростью чтения сообщений, хранящихся на диске. - Генератор нагрузки параллельно запускает 20 worker’ов (
-workers=20). Каждый worker содержит 5 producer’ов, которые совместно используют подключение worker’а к кластеру Kafka. В итоге каждый генератор насчитывает 100 producer’ов, и все они отправляют сообщения в кластер Kafka.
Наблюдение за состоянием кластера
Во время нагрузочного тестирования кластера Kafka мы также следили за его здоровьем, чтобы убедиться в отсутствии перезапусков pod’ов, рассинхронизированных реплик и максимальной пропускной способности с минимальными флуктуациями:
Результаты измерений
3 брокера, размер сообщений — 512 байт
С partition’ами, равномерно распределёнными по трём брокерам, нам удалось достичь производительности ~500 Мб/с (примерно 990 тыс. сообщений в секунду):



Потребление памяти виртуальной машиной JVM не превысило 2 Гб:



Пропускная способность диска достигла максимальной пропускной способности I/O узла на всех трёх инстансах, на которых работали брокеры:
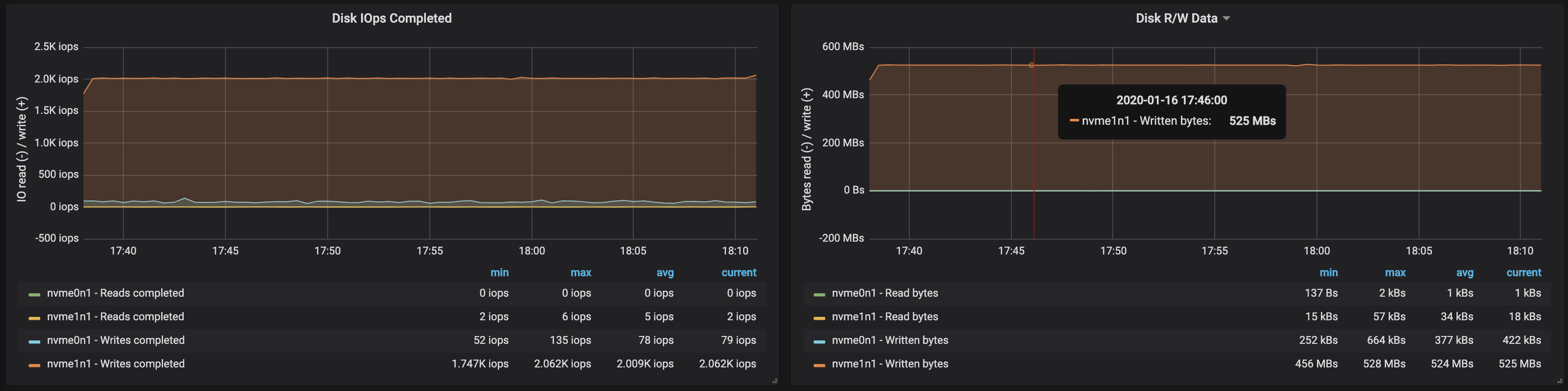


Из данных об использовании памяти узлами следует, что системная буферизация и кэширование заняли ~10–15 Гб:



3 брокера, размер сообщений — 100 байт
С уменьшением размера сообщений пропускная способность падает примерно на 15–20%: сказывается время, затрачиваемое на обработку каждого сообщения. Кроме того, нагрузка на процессор выросла почти вдвое.



Поскольку на узлах брокеров по-прежнему имеются неиспользуемые ядра, производительность можно повысить за счёт изменения конфигурации Kafka. Это непростая задача, поэтому для увеличения пропускной способности лучше работать с сообщениями большего размера.
4 брокера, размер сообщений — 512 байт
Можно легко увеличить производительность кластера Kafka, просто добавляя новые брокеры и сохраняя баланс partition’ов (это обеспечивает равномерное распределение нагрузки между брокерами). В нашем случае после добавления брокера пропускная способность кластера возросла до ~580 Мб/с (~1,1 млн сообщений в секунду). Рост оказался меньшим, чем ожидалось: преимущественно это объясняется дисбалансом partition’ов (не все брокеры работают на пике возможностей).




Потребление памяти машиной JVM осталось ниже 2 Гб:




На работе брокеров с накопителями сказался дисбаланс partition’ов:




Выводы
Представленный выше итеративный подход может быть расширен для охвата более сложных сценариев, включающих сотни consumer’ов, repartitioning, накатываемые обновления, перезапуски pod’ов и т.д. Всё это позволяет нам оценить пределы возможностей кластера Kafka в различных условиях, выявить узкие места в его работе и найти способы борьбы с ними.
Мы разработали Supertubes для быстрого и лёгкого развёртывания кластера, его конфигурирования, добавления/удаления брокеров и топиков, реагирования на оповещения и обеспечения правильной работы Kafka в Kubernetes в целом. Наша цель — помочь сконцентрироваться на основной задаче («генерировать» и «потреблять» сообщения Kafka), а всю тяжёлую работу предоставить Supertubes и Kafka operator’у.
Если вам интересны технологии и Open Source-проекты Banzai Cloud, подписывайтесь на компанию в GitHub, LinkedIn или Twitter.
P.S. от переводчика
Читайте также в нашем блоге:
