[Перевод] Обзор Python-пакета Datatable
«Пять экзабайт информации создано человечеством с момента зарождения цивилизации до 2003 года, но столько же сейчас создаётся каждые два дня». Эрик Шмидт

Datatable — это Python-библиотека для выполнения эффективной многопоточной обработки данных. Datatable поддерживает наборы данных, которые не помещаются в памяти.
Если вы пишете на R, то вы, вероятно, уже используете пакет data.table. Data.table — это расширение R-пакета data.frame. Кроме того, без этого пакета не обойтись тем, кто пользуется R для быстрой агрегации больших наборов данных (речь идёт, в частности, о 100 Гб данных в RAM).
Пакет data.table для R весьма гибок и производителен. Пользоваться им легко и удобно, программы, в которых он применяется, пишутся довольно быстро. Этот пакет широко известен в кругах R-программистов. Его загружают более 400 тысяч раз в месяц, он используется в почти 650 CRAN и Bioconductor-пакетах (источник).
Какая от всего этого польза для тех, кто занимается анализом данных на Python? Всё дело в том, что существует Python-пакет datatable, являющийся аналогом data.table из мира R. Пакет datatable чётко ориентирован на обработку больших наборов данных. Он отличается высокой производительностью — как при работе с данными, которые полностью помещаются в оперативной памяти, так и при работе с данными, размер которых превышает объём доступной RAM. Он поддерживает и многопоточную обработку данных. В целом, пакет datatable вполне можно назвать младшим братом data.table.
Datatable

Современным системам машинного обучения нужно обрабатывать чудовищные объёмы данных и генерировать множество признаков. Это нужно для построения как можно более точных моделей. Python-модуль datatable был создан для решения этой проблемы. Это — набор инструментов для выполнения операций с большими (до 100 Гб) объёмами данных на одиночном компьютере на максимально возможной скорости. Спонсором разработки datatable является H2O.ai, а первым пользователем пакета — Driverless.ai.
Этот набор инструментов очень напоминает pandas, но он сильнее ориентирован на обеспечение высокой скорости обработки данных и на поддержку больших наборов данных. Разработчики пакета datatable, кроме того, стремятся к тому, чтобы пользователям было бы удобно с ним работать. Речь идёт, в частности, о мощном API и о продуманных сообщениях об ошибках. В этом материале мы поговорим о том, как пользоваться datatable, и о том, как он выглядит в сравнении с pandas при обработке больших наборов данных.
Установка
В MacOS datatable можно легко установить с помощью pip:
pip install datatable
В Linux установка производится из бинарных дистрибутивов:
# Для Python 3.5
pip install https://s3.amazonaws.com/h2o-release/datatable/stable/datatable-0.8.0/datatable-0.8.0-cp35-cp35m-linux_x86_64.whl
# Для Python 3.6
pip install https://s3.amazonaws.com/h2o-release/datatable/stable/datatable-0.8.0/datatable-0.8.0-cp36-cp36m-linux_x86_64.whl
В настоящий момент datatable не работает под Windows, но сейчас ведётся работа в этом направлении, так что поддержка Windows — это лишь вопрос времени.
Подробности об установке datatable можно найти здесь.
Код, который будет использован в этом материале, можно найти в этом GitHub-репозитории или здесь, на mybinder.org.
Чтение данных
Набор данных, с которым мы тут будем экспериментировать, взят с Kaggle (Lending Club Loan Data Dataset). Этот набор состоит из полных данных обо всех займах, выданных в 2007–2015 годах, включая текущее состояние займа (Current, Late, Fully Paid и так далее) и самые свежие сведения о платеже. Файл состоит из 2.26 миллиона строк и 145 столбцов. Размер этого набора данных идеально подходит для демонстрации возможностей библиотеки datatable.
# Импортируем необходимые библиотеки
import numpy as np
import pandas as pd
import datatable as dt
Давайте загрузим данные в объект Frame. Базовая единица анализа в datatable — это Frame. Это — то же самое, что DataFrame из pandas или SQL-таблица. А именно, речь идёт о данных, организованных в виде двумерного массива, в котором можно выделить строки и столбцы.
▍Загрузка данных с использованием datatable
%%time
datatable_df = dt.fread("data.csv")
____________________________________________________________________
CPU times: user 30 s, sys: 3.39 s, total: 33.4 s
Wall time: 23.6 s
Вышеприведённая функция fread() представляет собой мощный и очень быстрый механизм. Она может автоматически обнаруживать и обрабатывать параметры для подавляющего большинства текстовых файлов, загружать данные из .ZIP-архивов и из Excel-файлов, получать данные по URL и делать многое другое.
Кроме этого, парсер datatable обладает следующими возможностями:
- Он может автоматически обнаруживать разделители, заголовки, типы столбцов, правила экранирования символов и так далее.
- Он может читать данные из различных источников. Среди них — файловая система, URL, командная оболочка, необработанный текст, архивы.
- Он умеет выполнять многопоточное чтение данных для обеспечения максимальной производительности.
- Он отображает индикатор прогресса при чтении больших файлов.
- Он может читать файлы, соответствующие и не соответствующие RFC4180.
▍Загрузка данных с использованием pandas
Теперь посмотрим — сколько времени нужно pandas на то, чтобы прочитать тот же самый файл.
%%time
pandas_df= pd.read_csv("data.csv")
___________________________________________________________
CPU times: user 47.5 s, sys: 12.1 s, total: 59.6 s
Wall time: 1min 4s
Можно видеть, что datatable явно работает быстрее pandas при чтении больших наборов данных. Pandas в нашем эксперименте нужно больше минуты, а время, необходимое datatable, измеряется секундами.
Преобразование объекта Frame
Существующий объект Frame пакета datatable можно конвертировать в объект DataFramenumpy или pandas. Делается это так:
numpy_df = datatable_df.to_numpy()
pandas_df = datatable_df.to_pandas()
Попробуем преобразовать существующий объект Frame datatable в объект DataFrame pandas и посмотрим на то, сколько это займёт времени.
%%time
datatable_pandas = datatable_df.to_pandas()
___________________________________________________________________
CPU times: user 17.1 s, sys: 4 s, total: 21.1 s
Wall time: 21.4 s
Похоже, что чтение файла в объект Frame datatable и последующее преобразование этого объекта в объект DataFrame pandas занимает меньше времени, чем загрузка данных в DataFrame средствами pandas. Поэтому, возможно, если планируется обрабатывать большие объёмы данных с помощью pandas, лучше будет загружать их средствами datatable, а потом уже преобразовывать в DataFrame.
type(datatable_pandas)
___________________________________________________________________
pandas.core.frame.DataFrameОсновные свойства объекта Frame
Рассмотрим основные свойства объекта Frame из datatable. Они очень похожи на аналогичные свойства объекта DataFrame из pandas:
print(datatable_df.shape) # (количество строк, количество столбцов)
print(datatable_df.names[:5]) # имена первых 5 столбцов
print(datatable_df.stypes[:5]) # типы первых 5 столбцов
______________________________________________________________
(2260668, 145)
('id', 'member_id', 'loan_amnt', 'funded_amnt', 'funded_amnt_inv')
(stype.bool8, stype.bool8, stype.int32, stype.int32, stype.float64)
Тут нам доступен и метод head(), выводящий n первых строк:
datatable_df.head(10)
Первые 10 строк объекта Frame из datatable
Цвета заголовков указывают на тип данных. Красным цветом обозначены строки, зелёным — целые числа, синим — числа с плавающей точкой.
Суммарная статистика
Вычисление суммарной статистики в pandas — это операция, для выполнения которой требуется много памяти. В случае с datatable это не так. Вот команды, которые можно использовать для вычисления различных показателей в datatable:
datatable_df.sum() datatable_df.nunique()
datatable_df.sd() datatable_df.max()
datatable_df.mode() datatable_df.min()
datatable_df.nmodal() datatable_df.mean()
Вычислим среднее значение по столбцам с использованием datatable и pandas и проанализируем время, необходимое для выполнения этой операции.
▍Нахождение среднего значения с использованием datatable
%%time
datatable_df.mean()
_______________________________________________________________
CPU times: user 5.11 s, sys: 51.8 ms, total: 5.16 s
Wall time: 1.43 s▍Нахождение среднего значения с использованием pandas
pandas_df.mean()
__________________________________________________________________
Throws memory error.
Как видно, в pandas нам не удалось получить результат — выдана ошибка, связанная с памятью.
Манипуляции с данными
Frame и DataFrame — это структуры данных, представляющие собой таблицы. В datatable для выполнения манипуляций с данными используются квадратные скобки. Это напоминает то, как работают с обычными матрицами, но здесь при применении квадратных скобок можно пользоваться дополнительными возможностями.
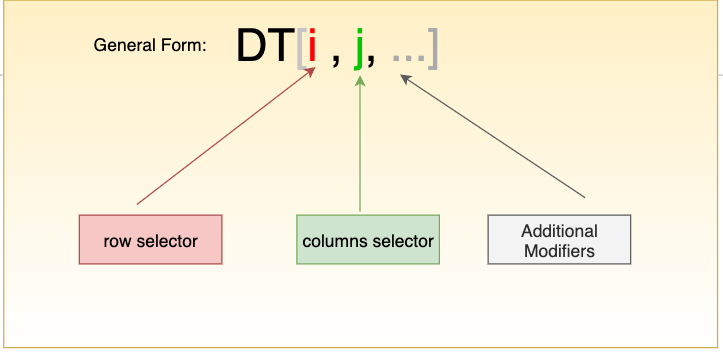
Работа с данными в datatable с использованием квадратных скобок
В математике при работе с матрицами также используются конструкции вида DT[i, j]. Похожие структуры можно найти в языках C, C++ и R, в пакетах pandas и numpy, а так же во многих других технологиях. Рассмотрим выполнение распространённых манипуляций с данными в datatable.
▍Формирование выборок строк или столбцов
Следующий код выбирает все строки из столбца funded_amnt:
datatable_df[:,'funded_amnt']
Выбор всех строк столбца funded_amnt
Вот как выбрать первые 5 строк и 3 столбца:
datatable_df[:5,:3]
Выбор первых 5 строк и 3 столбцов
▍Сортировка данных с использованием datatable
Отсортируем набор данных по выбранному столбцу:
%%time
datatable_df.sort('funded_amnt_inv')
_________________________________________________________________
CPU times: user 534 ms, sys: 67.9 ms, total: 602 ms
Wall time: 179 ms▍Сортировка данных с использованием pandas
%%time
pandas_df.sort_values(by = 'funded_amnt_inv')
___________________________________________________________________
CPU times: user 8.76 s, sys: 2.87 s, total: 11.6 s
Wall time: 12.4 s
Обратите внимание на значительное различие во времени, необходимом на сортировку datatable и pandas.
▍Удаление строк и столбцов
Вот как удалить столбец с именем member_id:
del datatable_df[:, 'member_id']Группировка
Datatable, как и pandas, поддерживает возможности по группировке данных. Посмотрим на то, как получить среднее по столбцу funded_amound, данные в котором сгруппированы по столбцу grade.
▍Группировка данных с использованием datatable
%%time
for i in range(100):
datatable_df[:, dt.sum(dt.f.funded_amnt), dt.by(dt.f.grade)]
____________________________________________________________________
CPU times: user 6.41 s, sys: 1.34 s, total: 7.76 s
Wall time: 2.42 s
Здесь вы можете видеть использование конструкции .f. Это — так называемый фрейм-прокси — простой механизм, позволяющий ссылаться на объект Frame, с которым в данный момент производятся какие-то действия. В нашем случае dt.f — это то же самое, что datatable_df.
▍Группировка данных с использованием pandas
%%time
for i in range(100):
pandas_df.groupby("grade")["funded_amnt"].sum()
____________________________________________________________________
CPU times: user 12.9 s, sys: 859 ms, total: 13.7 s
Wall time: 13.9 sФильтрация строк
Синтаксис фильтрации похож на синтаксис группировки. Отфильтруем те строки loan_amnt, для которых значение loan_amnt больше, чем funded_amnt.
datatable_df[dt.f.loan_amnt>dt.f.funded_amnt,"loan_amnt"]Сохранение объекта Frame
Содержимое объекта Frame можно записать в CSV-файл, что позволяет использовать данные в будущем. Делается это так:
datatable_df.to_csv('output.csv')
О других методах datatable, предназначенных для работы с данными, можно почитать здесь.
Итоги
Python-модуль datatable, определённо, работает быстрее привычного многим pandas. Он, кроме того, прямо-таки находка для тех, кому нужно обрабатывать очень большие наборы данных. Пока единственный минус datatable в сравнении с pandas — это объём функционала. Однако сейчас ведётся активная работа над datatable, поэтому вполне возможно то, что в будущем datatable превзойдёт pandas по всем направлениям.
Уважаемые читатели! Планируете ли вы использовать пакет datatable в своих проектах?


