[Перевод] Обучение с подкреплением: математический аппарат
В предыдущем материале из этой серии мы простыми словами рассказали о том, что такое обучение с подкреплением (Reinforcement learning, RL). Там мы, на интуитивном уровне, разобрались с тем, как работают механизмы RL, поговорили о том, как обучение с подкреплением применяется для решения практических задач. В этом материале мы изучим математический аппарат RL, начав с его базовых принципов и дойдя до примеров применения этих принципов при проектировании RL-алгоритмов.

Компоненты алгоритма обучения с подкреплением
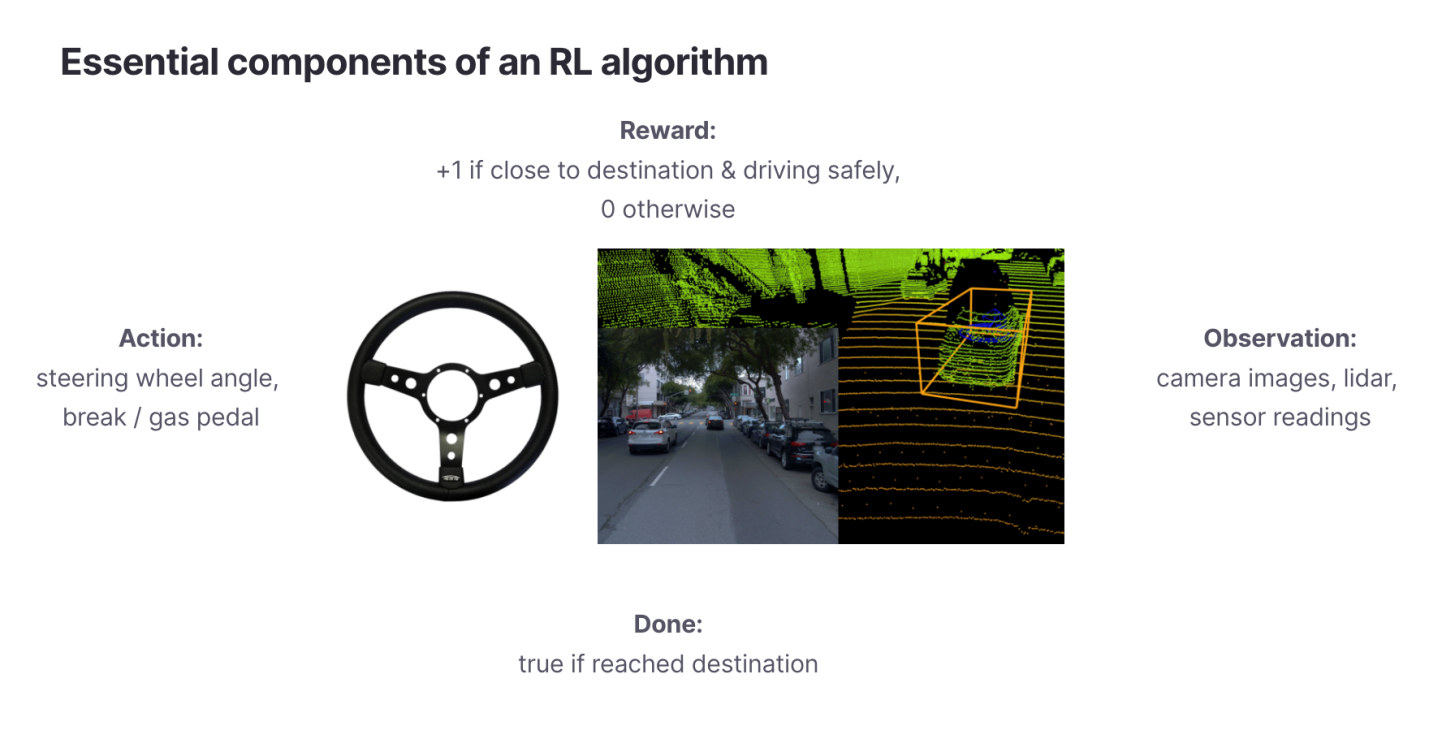 Базовые компоненты RL-алгоритма (изображение с беспилотного транспортного средства взято отсюда — https://github.com/waymo-research/waymo-open-dataset)
Базовые компоненты RL-алгоритма (изображение с беспилотного транспортного средства взято отсюда — https://github.com/waymo-research/waymo-open-dataset)
Начнём с постановки задачи. Перед применением алгоритма обучения с подкреплением мы должны определить следующие его свойства:
Пространство наблюдения (observation space),
 . Наблюдения — это данные, которые RL-агент использует для познания мира. Беспилотное транспортное средство (Autonomous Vehicle, AV) может наблюдать за миром посредством камер и лидара.
. Наблюдения — это данные, которые RL-агент использует для познания мира. Беспилотное транспортное средство (Autonomous Vehicle, AV) может наблюдать за миром посредством камер и лидара.Пространство действия (action space),
 . Пространство действия определяет то, какие действия может предпринять RL-агент. В пространство действия беспилотного автомобиля может входить поворот рулевого колеса на определённый угол, а так же — использование педалей газа и тормоза.
. Пространство действия определяет то, какие действия может предпринять RL-агент. В пространство действия беспилотного автомобиля может входить поворот рулевого колеса на определённый угол, а так же — использование педалей газа и тормоза.Функция вознаграждения (reward function),
 . С использованием функции вознаграждения каждому временному шагу назначают метку, отражающую его вклад в результирующий показатель, который мы стремимся оптимизировать.
. С использованием функции вознаграждения каждому временному шагу назначают метку, отражающую его вклад в результирующий показатель, который мы стремимся оптимизировать.Конечное условие (terminal condition),
 . Конечное условие определяет длительность одного эпизода цикла обучения с подкреплением. Оно выражается либо фиксированным количеством времени (например — 1000 шагов), либо срабатывает по достижении благоприятного исхода некоей последовательности действий (например — когда беспилотный автомобиль благополучно прибыл в пункт назначения, или когда пользователь купил то, что ему предложила рекомендательная система).
. Конечное условие определяет длительность одного эпизода цикла обучения с подкреплением. Оно выражается либо фиксированным количеством времени (например — 1000 шагов), либо срабатывает по достижении благоприятного исхода некоей последовательности действий (например — когда беспилотный автомобиль благополучно прибыл в пункт назначения, или когда пользователь купил то, что ему предложила рекомендательная система).
Цель алгоритма обучения с подкреплением
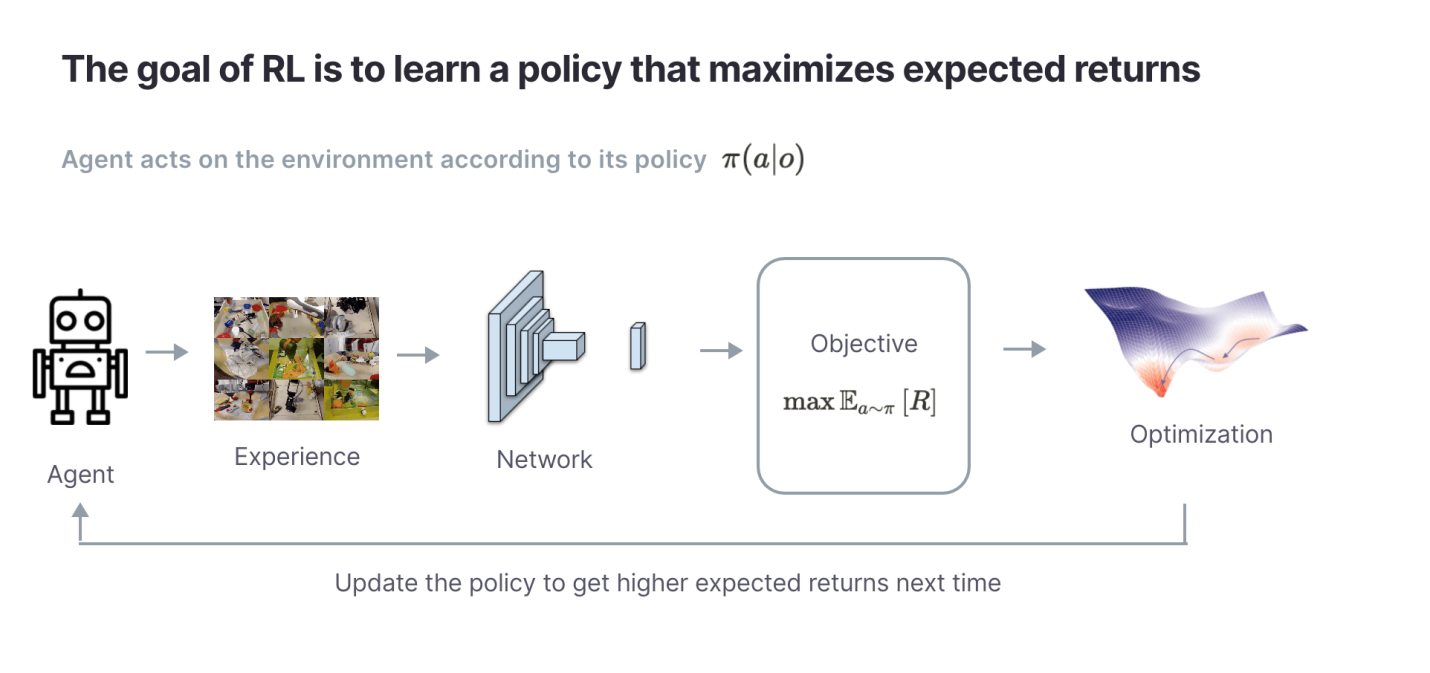 Агент воздействует на окружающую среду в соответствии с правилами своего поведения. Цель алгоритма — найти такие правила поведения, которые максимизируют ожидаемые результаты.
Агент воздействует на окружающую среду в соответствии с правилами своего поведения. Цель алгоритма — найти такие правила поведения, которые максимизируют ожидаемые результаты.
Теперь, когда мы разобрались с постановкой задачи, нам нужно определить то, что именно RL-алгоритм будет оптимизировать. Цель RL-алгоритмов довольно-таки проста: она заключается в том, чтобы найти такие правила поведения (policy),  , которые максимизируют общие вознаграждения (известные ещё как результаты)
, которые максимизируют общие вознаграждения (известные ещё как результаты)  в эпизоде. На интуитивном уровне понятно, что «правила поведения» — это RL-агент. Правила поведения формируют действие в ответ на текущие наблюдения за окружающей средой, сделанные агентом.
в эпизоде. На интуитивном уровне понятно, что «правила поведения» — это RL-агент. Правила поведения формируют действие в ответ на текущие наблюдения за окружающей средой, сделанные агентом.
К сожалению, определение текущей цели алгоритма — это разновидность «проблемы курицы и яйца». Для достижения  RL-агенту нужно видеть будущие результаты, но для того чтобы их видеть, правила поведения агента должны воздействовать на окружение, а значит результаты уже не окажутся «будущими». Каким образом агент может выбрать действие так, чтобы достигнуть
RL-агенту нужно видеть будущие результаты, но для того чтобы их видеть, правила поведения агента должны воздействовать на окружение, а значит результаты уже не окажутся «будущими». Каким образом агент может выбрать действие так, чтобы достигнуть  до того, как он окажет некое реальное влияние на окружающую среду?
до того, как он окажет некое реальное влияние на окружающую среду?
Именно тут в дело вступает очень и очень важная концепция ожидаемого результата. RL-агент не максимизирует реальные вознаграждения. Он формирует оценку того, каким в будущем окажется  в том случае, если он будет действовать в соответствии с
в том случае, если он будет действовать в соответствии с  . Другими словами — цель агента заключается в том, чтобы достигнуть
. Другими словами — цель агента заключается в том, чтобы достигнуть ![max\, \mathbb{E}_{a\sim\pi}\,\left [ R \right ]](https://habrastorage.org/getpro/habr/upload_files/393/698/f45/393698f455bb3e3fb18d3856db7c933f.svg) , а не
, а не  . Эта концепция ожидаемого результата является центральным элементом всех алгоритмов обучения с подкреплением. В следующем материале из этой серии мы поговорим о том, как вышеозначенная цель ведёт к Q-обучению, а пока мы можем сформулировать главную цель обучения с подкреплением так:
. Эта концепция ожидаемого результата является центральным элементом всех алгоритмов обучения с подкреплением. В следующем материале из этой серии мы поговорим о том, как вышеозначенная цель ведёт к Q-обучению, а пока мы можем сформулировать главную цель обучения с подкреплением так:
