[Перевод] О стримах и таблицах в Kafka и Stream Processing, часть 1
* Michael G. Noll — активный контрибьютор в Open Source проекты, в том числе в Apache Kafka и Apache Storm.
Статья будет полезна в первую очередь тем, кто только знакомится с Apache Kafka и/или потоковой обработкой [Stream Processing].
В этой статье, возможно, в первой из мини-серии, я хочу объяснить концепции Стримов [Streams] и Таблиц [Tables] в потоковой обработке и, в частности, в Apache Kafka. Надеюсь, у вас появится лучшее теоретическое представление и идеи, которые помогут вам решать ваши текущие и будущие задачи лучше и/или быстрее.
Содержание:
* Мотивация
* Стримы и Таблицы простым языком
* Иллюстрированные примеры
* Стримы и Таблицы в Kafka простым языком
* Пристальный взгляд на Kafka Streams, KSQL и аналоги в Scala
* Таблицы стоят на плечах гигантов (на стримах)
* Turning the Database Inside-Out
* Заключение
Мотивация, или почему это должно заботить?
В своей повседневной работе я общаюсь со многими пользователями Apache Kafka и теми, кто занимается потоковой обработкой с помощью Kafka через Kafka Streams и KSQL (потоковый SQL для Kafka). У некоторых пользователей уже есть опыт потоковой обработки или использования Kafka, у некоторых есть опыт использования РСУБД, таких как Oracle или MySQL, у некоторых нет ни того, ни другого опыта.
Часто задаваемый вопрос: «В чём разница между Стримами и Таблицами?» В этой статье я хочу дать оба ответа: как короткий (TL; DR), так и длинный, чтобы вы могли получить более глубокое понимание. Некоторые из приведённых ниже объяснений будут немного упрощены, потому что это упрощает понимание и запоминание (например, как более простая модель притяжения Ньютона вполне достаточна для большинства повседневных ситуаций, что избавляет нас от необходимости переходить сразу к релятивистской модели Эйнштейна, к счастью, потоковая обработка не настолько сложна).
Другой распространённый вопрос: «Хорошо, но почему это должно меня волновать? Как это поможет мне в моей повседневной работе?» Короче говоря, по многим причинам! Как только вы начнёте использовать потоковую обработку, вы вскоре осознаете, что на практике в большинстве случаев требуются и стримы, и таблицы. Таблицы, как я объясню позже, представляют состояние. Всякий раз, когда вы выполняете любую обработку с состоянием [stateful processing], как объединения [joins] (например, обогащение данных [data enrichment] в реальном времени путём объединения потока фактов с «размерными» таблицами [dimension tables]) или агрегации [aggregations] (например, вычисление в реальном времени среднего значения для ключевых бизнес-показателей за 5 минут), тогда таблицы вводят потоковую картину [streaming picture]. В противном случае, это означает, что вы вынуждены будете делать это сами [a lot of DIY pain].
Даже пресловутый пример WordCount, вероятно ваш первый «Hello World» из этой области, попадает в категорию «с состоянием»: это пример обработки с состоянием, где мы агрегируем поток строк в непрерывно обновляемую таблицу/мапу для подсчёта слов. Таким образом, независимо от того, реализуете вы простой стриминг WordCount или что-то более сложное, как выявление мошенничества [fraud detection], вы хотите простое в использовании решение для потоковой обработки с основными структурами данных и всем необходим внутри (подсказка: стримы и таблицы). Вы, конечно же, не захотите строить сложную и ненужную архитектуру, где требуется соединять технологию (только лишь) потоковой обработки с удалённым хранилищем, таким как Cassandra или MySQL, и возможно, с добавлением Hadoop/HDFS для обеспечения отказоустойчивости обработки [fault-tolerance processing] (три вещи — слишком много).
Стримы и Таблицы простым языком
Вот лучшая аналогия, которую я смог придумать:
- Стрим в Kafka — это полная история всех случившихся событий (или только бизнес-событий) в мире с начала времён по сегодняшний день. Он представляет прошлое и настоящее. По мере того, как мы переходим из сегодняшнего дня в завтрашний, новые события постоянно добавляются к мировой истории.
- Таблица в Kafka — это состояние мира на сегодняшний день. Она представляет настощее. Это совокупность [aggregation] всех событий в мире, которая постоянно изменяется по мере того, как мы переходим из сегодняшнего в завтрашний.
И как аперитив к будущему посту: если у вас есть доступ ко всей истории событий в мире (стрим), тогда вы можете восстановить состояние мира на любой момент времени, то есть таблицу в произвольное время t в потоке, где t не ограничивается только t=сейчас. Другими словами, мы можем создавать «снимки» [snapshots] состояния мира (таблицу) на любой момент времени t, например, 2560 г. до н.э., когда была построена Великая Пирамида в Гизе, или 1993 год, когда был основан Европейский Союз.
Иллюстрированные примеры
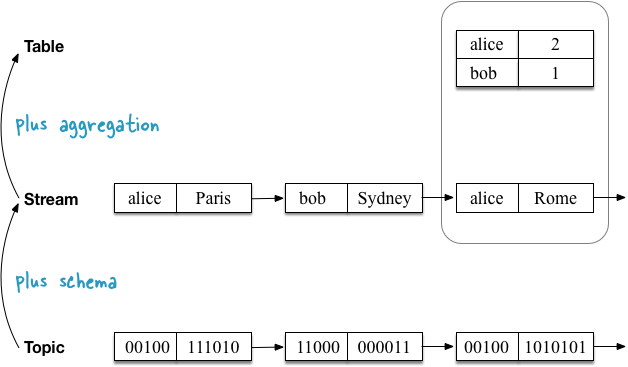
В первом примере показан стрим с геоположениями пользователей, которые агрегируются в таблицу, фиксирующую текущее (последнее) положение каждого пользователя. Как я объясню позже, это также оказывается для таблиц семантикой по умолчанию, когда вы читаете топик [Topic] Kafka непосредственно в таблицу.

Второй пример использования демонстрирует один и тот же поток обновлений геолокаций пользователей, но теперь стрим агрегируется в таблицу, которая фиксирует количество посещённых мест каждым пользователем. Поскольку функция агрегации отличается (здесь: подсчёт количества), содержимое таблицы так же отличается. Точнее, другие значения по ключу.

Стримы и Таблицы в Kafka простым языком
Прежде чем мы погрузимся в детали, давайте начнём с простого.
Топик в Kafka — неограниченная последовательность key-value пар. Ключи и значения — обычные массивы байтов, т.е.
Стрим — топик со схемой [schema]. Ключи и значения больше не массивы байтов, а имеют определённый типы.
Пример:топик читается какстрим геоположений пользователей.
Таблица — таблица в обычном смысле этого слова (я чувствую радость тех из вас, кто уже знаком с РСУБД и только знакомится с Kafka). Но глядя через призму потоковой обработки, видим, что таблица также является агрегированным стримом (вы действительно не ожидали, что мы остановимся на определении «таблица — это таблица», не так ли?).
Пример:стрим с обновлениями геоданных агрегируется втаблицу, которая отслеживает последнее положение пользователя. На этапе агрегации обновляются [UPSERT] значения в таблице по ключу из входного стрима. Мы видели это в первом проиллюстрированном примере выше.
Пример:стрим агрегируется втаблицу, которая отслеживает количество посещённых местоположений для каждого пользователя. На этапе агрегации непрерывно подсчитываются (и обновляются) значения по ключам в таблице. Мы видели это во втором проиллюстрированном примере выше.
Итого:
Топики, стримы и таблицы обладают следующими свойствами в Kafka:
| Тип | Есть партиции | Не ограничен | Есть порядок | Изменчив | Уникальность ключа | Схема |
|---|---|---|---|---|---|---|
| Topic | Да | Да | Да | Нет | Нет | Нет |
| Stream | Да | Да | Да | Нет | Нет | Да |
| Table | Да | Да | Нет | Да | Да | Да |
Давайте посмотрим, как топики, стримы и таблицы соотносятся с Kafka Streams API и KSQL, а также проведём аналогии с языками программирования (в аналогиях проигнорировано, к примеру, что топики / стримы / таблицы могут быть партицированы):
| Тип | Kafka Streams | KSQL | Java | Scala | Python |
|---|---|---|---|---|---|
| Topic | - | - | List / Stream |
List / Stream [(Array[Byte], Array[Byte])] |
[] |
| Stream | KStream |
STREAM |
List / Stream |
List / Stream [(K, V)] |
[] |
| Table | KTable |
TABLE |
HashMap |
mutable.Map[K, V] |
{} |
Но это резюме на таком уровне может оказаться малополезным для вас. Итак, давайте рассмотрим поближе.
Пристальный взгляд на Kafka Streams, KSQL и аналоги в Scala
Я начну каждый из следующих разделов с аналогией в Scala (представьте, что потоковая обработка осуществляется на одной машине) и Scala REPL, чтобы вы могли скопировать код и поиграться с ним самостоятельно, затем я объясню, как то же самое сделать в Kafka Streams и KSQL (гибкую, масштабируемую и отказоустойчивую потоковую обработку на распределённых машинах). Как я уже упоминал в начале я немного упрощаю объяснения ниже. Например, я не буду рассматривать влияние партицирования в Kafka.
Если вы не знаете Scala: Не смущайтесь! Вам не нужно понимать Scala-аналоги во всех деталях. Достаточно обратить внимание на то, какие операции (например,map()) соединяются вместе, чем они являются (например,reduceLeft()представляет собой агрегацию), и как «цепочка» стримов соотносится с «цепочкой» таблиц.
Топики
Топик в Kafka состоит из сообщений «ключ-значение». Топик не зависит от формата сериализации или «типа» сообщений: ключи и значения в сообщениях трактуются как обычные массивы байтов byte[]. Другими словами, с этой точки зрения у нас нет никого представления, что внутри данных.
В Kafka Streams и KSQL нет понятия «топик». Они только знают о стримах и таблицах. Поэтому я покажу здесь только аналог топика в Scala.
// Scala analogy
scala> val topic: Seq[(Array[Byte], Array[Byte])] = Seq((Array(97, 108, 105, 99, 101),Array(80, 97, 114, 105, 115)), (Array(98, 111, 98),Array(83, 121, 100, 110, 101, 121)), (Array(97, 108, 105, 99, 101),Array(82, 111, 109, 101)), (Array(98, 111, 98),Array(76, 105, 109, 97)), (Array(97, 108, 105, 99, 101),Array(66, 101, 114, 108, 105, 110)))Стримы
Теперь мы читает топик в стрим, добавляя информацию о схеме (схему на чтение [schema-on-read]). Другими словами, мы превращаем сырой, нетипизированный топик в «типизированный топик» или стрим.
Схема на чтение vs Схема на запись [schema-on-write]: Kafka и её топики не зависят от формата сериализации ваших данных. Поэтому вы должны указать схему, когда захотите прочитать данные в стрим или таблицу. Это называется схемой на чтение. У схемы на чтение есть как плюсы, так и минусы. К счастью, вы можете выбрать промежуточное звено между схемой на чтение и схемой на запись, определив контракт для ваших данных — подобно тому, как вы, вероятно, определяете контракты API в ваших приложениях и сервисах. Это может быть достигнуто путём выбора структурированного, но расширяемого формата данных, такого как Apache Avro с разворачиванием реестра для ваших Avro-схем, например Confluent Schema Registry. И да, и Kafka Streams, и KSQL поддерживают Avro, если вам интересно.
В Scala это достигается с помощью операции map() ниже. В этом примере мы получаем стрим из пар
// Scala analogy
scala> val stream = topic
| .map { case (k: Array[Byte], v: Array[Byte]) => new String(k) -> new String(v) }
// => stream: Seq[(String, String)] =
// List((alice,Paris), (bob,Sydney), (alice,Rome), (bob,Lima), (alice,Berlin))
В Kafka Streams вы читаете топик в KStream через StreamsBuilder#stream(). Здесь вы должны определить желаемую схему с помощью параметра Consumed.with() при чтении данных из топика:
StreamsBuilder builder = new StreamsBuilder();
KStream stream =
builder.stream("input-topic", Consumed.with(Serdes.String(), Serdes.String()));
В KSQL вы должны сделать что-то вроде следующего, чтобы прочитать топик как STREAM. Здесь вы определяете желаемую схему, указав имена и типы колонкам при чтении данных из топика:
CREATE STREAM myStream (username VARCHAR, location VARCHAR)
WITH (KAFKA_TOPIC='input-topic', VALUE_FORMAT='...')Таблицы
Теперь мы читает этот же топик в таблицу. Во-первых, нам нужно добавить информацию о схеме (схему на чтение). Во-вторых, вы должны преобразовать стрим в таблицу. Семантика таблицы в Kafka гласит, что итоговая таблица должна отображать каждый ключ сообщений из топика в последнее значение для этого ключа.
Давайте сначала используем первый пример, где итоговая таблица отслеживает последнее местоположение каждого пользователя:
В Scala:
// Scala analogy
scala> val table = topic
| .map { case (k: Array[Byte], v: Array[Byte]) => new String(k) -> new String(v) }
| .groupBy(_._1)
| .map { case (k, v) => (k, v.reduceLeft( (aggV, newV) => newV)._2) }
// => table: scala.collection.immutable.Map[String,String] =
// Map(alice -> Berlin, bob -> Lima)
Добавление информации о схеме достигается использованием первой операции map() — точно так же, как в примере со стримом выше. Преобразование стрима в таблицу [stream-to-table] осуществляется с помощью этапа агрегации (подробнее об этом будет позже), который в этом случае представляет собой операцию (без состояния) UPSERT на таблице: это шаг groupBy().map(), который содержит операцию reduceLeft() по каждому ключу. Агрегация означает, что для каждого ключа мы сжимаем множество значений в одно. Обратите внимание, что эта конкретная агрегация reduceLeft() без состояния — предыдущее значение aggV не используется при вычислении нового значения для заданного ключа.
Что интересно касательно отношения между стримами и таблицами, так это то, что команда выше создаёт таблицу, эквивалентную короткому варианту ниже (помните о ссылочной прозрачности [referential transparency]), где мы строим таблицу напрямую из стрима, что позволяет нам пропустить задание схемы / типа, потому что стрим уже типизирован. Мы можем увидеть, что таблица является выводом [derivation], агрегацией стрима:
// Scala analogy, simplified
scala> val table = stream
| .groupBy(_._1)
| .map { case (k, v) => (k, v.reduceLeft( (aggV, newV) => newV)._2) }
// => table: scala.collection.immutable.Map[String,String] =
// Map(alice -> Berlin, bob -> Lima)
В Kafka Streams вы обычно используете StreamsBuilder#table() для чтения топика Kafka в KTable простым однострочником:
KTable table = builder.table("input-topic", Consumed.with(Serdes.String(), Serdes.String()));
Но для наглядности вы также можете прочитать топик сперва в KStream, а затем выполнить такой же этап агрегации, как показано выше, чтобы превратить KStream в KTable.
KStream stream = ...;
KTable table = stream
.groupByKey()
.reduce((aggV, newV) -> newV);
В KSQL вы должны сделать что-то вроде следующего, чтобы прочитать топик как TABLE. Здесь вы должны определить желаемую схему, указав при чтении из топика имена и типы для колонок:
CREATE TABLE myTable (username VARCHAR, location VARCHAR)
WITH (KAFKA_TOPIC='input-topic', KEY='username', VALUE_FORMAT='...')
Что это означит? Это означает, что таблица на самом деле является агрегированным стримом [aggregated stream], как мы уже говорили в самом начале. Мы видели это непосредственно в специальном случае выше, когда таблица создавалась напрямую из топика. Однако, на самом деле это общий случай.
Таблицы стоят на плечах гигантов (на стримах)
Концептуально, только стрим является конструкцией данных первого порядка в Kafka. С другой стороны, таблица либо (1) выводится из существующего стрима посредством поключевой [per-key] агрегации, либо (2) выводится из существующей таблицы, которая всегда разворачивается до агрегированного стрима (мы могли бы назвать последние таблицы «прото-стримами» [«ur-stream»]).
Таблицы часто также описываются как материализованное представление [materialized view] стрима. Представление стрима — это не что иное, как агрегация в этом контексте.
Из двух случаем более интересным для обсуждения является (1), поэтому давайте сосредоточимся на этом. И это, вероятно, означает, что мне нужно сперва выяснить, как работают агрегации в Kafka.
Агрегации в Kafka
Агрегации — это одна из разновидностей потоковой обработки. К другим типам, например, относятся фильтрация [filters] и объединения [joins].
Как мы выяснили ранее, данные в Kafka представлены в виде пар ключ-значение. Далее, первое свойство агрегаций в Kafka заключается в том, что все они вычисляются по ключу. Вот почему мы должны сгруппировать KStream до этапа агрегации в Kafka Streams через groupBy() или groupByKey(). По этой же причине нам пришлось использовать groupBy() в примерах на Scala выше.
Партицирование [partition] и ключи сообщений: Не менее важный аспект Kafka, который я игнорирую в этой статье, состоит в том, что топики, стримы и таблицы партицированы. Фактически, данные обрабатываются и агрегируются по ключу по партициям. По умолчанию, сообщения / записи распределяются по партициям на основании их ключей, поэтому на практике упрощение «агрегация по ключу» вместо технически более сложного и более правильного «агрегация по ключу по партиции» вполне допустимо. Но если вы используете кастомный алгоритм партицирования [custom partitioning assigners], тогда вы должны учитывать это в свой логике обработки.
Второе свойство агрегаций в Kafka заключается в том, что агрегации непрерывно обновляются как только новые данные поступают во входящие стримы. Вместе со свойством вычисления по ключу это требует наличия таблицы или, более точно, это требует изменяемую таблицу [mutable table] в качестве результата и, следовательно, типа возвращаемых агрегаций. Предыдущие значения (результаты агрегаций) для ключа постоянно перезаписываются новыми значениями. И в Kafka Streams и в KSQL агрегации всегда возвращают таблицу.
Вернёмся к нашему второму примеру, в котором мы хотим подсчитать по нашему потоку количество посещённых каждым пользователем мест:
Подсчёт [counting] — это тип агрегации. Чтобы подсчитать значения, нам нужно только заменить этап агрегации из предыдущего раздела .reduce((aggV, newV) -> newV) with .map { case (k, v) => (k, v.length) }. Обратите внимание, что возвращаемый тип является таблицей / мапой (и, пожалуйста, проигнорируйте то, что в коде на Scala, map неизменна [immutabler map], потому что в Scala по умолчанию используются неизменяемые map).
// Scala analogy
scala> val visitedLocationsPerUser = stream
| .groupBy(_._1)
| .map { case (k, v) => (k, v.length) }
// => visitedLocationsPerUser: scala.collection.immutable.Map[String,Int] =
// Map(alice -> 3, bob -> 2)
Код на Kafka Streams, эквивалентный примеру на Scala выше:
KTable visitedLocationsPerUser = stream
.groupByKey()
.count();
В KSQL:
CREATE TABLE visitedLocationsPerUser AS
SELECT username, COUNT(*)
FROM myStream
GROUP BY username;Таблицы — агрегированные стримы (input stream → table)
Как мы видели выше, таблицы — это агрегации их входных стримов или, короче говоря, таблицы — это агрегированные стримы. Всякий раз, когда вы выполняете агрегацию в Kafka Streams или KSQL, результатом всегда является таблица.
Особенность этапа агрегирования определяет, является ли таблица напрямую получаемой из стрима через семантику UPSERT без состояния (таблица отображает ключи в их последнее значение в стриме, который является агрегацией при чтении топика Kafka напрямую в таблицу), через подсчёт количества увиденных значений для каждого ключа с сохранением состояния [stateful counting] (см. наш последний пример), или более сложные агрегации, такие как суммирование, усреднение и так далее. При использовании Kafka Streams и KSQL у вас есть много вариантов для агрегирования, включая оконные агрегации [windowed aggregations] с «переворачивающимися» окнами [tumbling windows], «прыгающими» окнами [hopping windows] и «сессионными» окнами [session windows].
В таблицах есть стримы изменений (table → output stream)
Хотя таблицах является агрегацией входного стрима, она также имеет свой стрим вывода! Подобно записи данных об изменении (CDC) в базах данных, каждое изменение в таблице в Kafka заносится во внутренний стрим изменений называемый changelog stream таблицы. Много вычислений в Kafka Streams и KSQL фактически выполняются на changelog stream. Это позволяет Kafka Streams и KSQL, например, правильно перерабатывать исторические данные в соответствии с семантикой обработки времени события [event-time processing semantics] — помните, что поток представляет и настоящее, и прошлое, тогда как таблица может представлять только настоящее (или, более точно, фиксированный момент времни [snapshot in time]).
Примечание: В Kafka Streams вы можете явно преобразовывать таблицу в стрим изменений [changelog stream] через KTable#toStream().
Вот первый пример, но уже с changelog stream:

Обратите внимание, что changelog stream таблицы является копией входного стрима этой таблицы. Это связано с природой соответствующей функции агрегации (UPSERT). И если вам интересно: «Подождите, разве это не 1 к 1 копирование, расходующее место на диске?» — Под капотом Kafka Streams и KSQL выполняется оптимизация, чтобы свести к минимуму ненужные копирования данных и локальный / сетевой IO. Я игнорирую эти оптимизации на диаграмме выше для лучшей иллюстрации того, что в принципе происходит.
И, наконец, второй пример использования, включающий changelog stream. Здесь стрим изменений таблицы отличается, потому что здесь другая функция агрегации, которая выполняет поключевой [per-key] подсчёт.

Но эти внутренние changelog stream'ы также имеют архитектурное и эксплуатационное влияние. Стримы изменений непрерывно бэкапятся и сохраняются как топики в Kafka, и тема самым являются частью магии, которая обеспечивает эластичность [elasticity] и отказоустойчивость в Kafka Streams и KSQL. Это связано с тем, что они позволяют перемещать задачи по обработке между машинам / виртуалками / контейнерами без потери данных и на протяжении всех операций, независимо от того, обработка с состоянием [stateful] или без [stateless]. Таблица является частью состояния [state] вашего приложения (Kafka Streams) или запроса (KSQL), поэтому для Kafka является обязательным возможность переноса не только кода обработки (что легко), но и состояния обработки, включая таблицы, между машинами быстрым и надёжным способом (что намного сложнее). Всякий раз, когда таблица должна быть перемещена с клиентской машины A на машину B, то на новом назначении B таблица реконструируется из её changelog stream в Kafka (на стороне сервера) точно такое же состояние, какое было на машине A. Мы можем увидеть это на последней диаграмме выше, где «таблица подсчётов» [«counting table»] может быть легко востановлена из её changelog stream без необходимости переработки входного стрима.
Двойственность Стрим-Таблица
Термин stream-table duality относится к вышеуказанной взаимосвязи между стримами и таблицами. Это означает, например, что вы можете превратить стрим в таблицу, эту таблицу в другой стрим, полученный стрим в ещё одну таблицу и так далее. Для получения дополнительной информации см. пост в блоге Confluent: Введение в Kafka Streams: Stream Processing Made Simple.
Turning the Database Inside-Out
В дополнение к тому, что мы рассмотрели в предыдущих разделах, вы, возможно, сталкивались со статьёй Turning the Database Inside-Out, и теперь вам может быть интересно взглянуть на это целиком? Поскольку я не хочу сейчас вдаваться в детали, позвольте мне кратко сопоставить мир Kafka и потоковой обработки с миром баз данных. Будьте бдительны: далее серьёзные упрощения [black-and-white simplifications].
В базах данных, таблица — конструкция первого порядка. Это то, с чем выработаете. «Стримы» также существуют в базах данных, например, в виде binlog в MySQL или GoldenGate в Oracle, но они, как правило, скрыты от вас в том смысле, что вы не можете взаимодействовать с ними напрямую. База данных знает о настоящем, но она не знает о прошлом (если вам нужно прошлое, восстановите данные с ваших ленточных бэкапов [backup tapes], которые, ха-ха, как раз аппаратные стримы).
В Kafka и потоковой обработке, стрим — конструкция первого порядка. Таблицы — производные от стримов [derivations of streams], как мы видели раньше. Стрим знает о настоящем, так и о прошлом. Как пример, New York Times хранит все опубликованные статьи — 160 лет журналистики с 1850-х — в Kafka, источнике достоверных данных [source of truth].
Если коротко: база данных мыслит сперва таблицей, а потом — стримом. Kafka мыслит сперва стримом, а потом — таблицей. Тем не менее, Kafka-сообщество осознало, что в большинстве случаем практического использования стриминга требуются и стримы, и таблицы — даже в пресловутом, но простом WordCount, в котором агрегируется стрим текстовых строк в таблицу со счётчиками слов, как и в нашем втором примере использования выше. Следовательно, Kafka помогает нам соединить миры потоковой обработки и баз данных, предоставляя нативную поддержку стримов и таблиц через Kafka Streams и KSQL, чтобы избавить нас от множества проблем (и предупреждений пейджера). Мы могли бы назвать Kafka и тип стриминговой платформы, которой она является, поточно-реляционной [stream-relational], а не только стриминговой [stream-only].
База данных мыслит сперва таблицей, а потом — стримом. Kafka мыслит сперва стримом, а потом — таблицей.
Заключение
Надеюсь, вы найдёте эти объяснения полезными для того, чтобы лучше понять стримы и таблицы в Kafka и потоковой обработки в целом. Теперь, когда мы закончили с деталями, вы можете вернуться в начало статьи и перечитать ещё раз разделы «Стримы и Таблицы простым языком» и «Стримы и Таблицы в Kafka простым языком».
Если в этой статье вам было интересно попробовать поточно-реляционную обработку с помощью Kafka, Kafka Streams и KSQL, вы можете продолжить изучение:
- Изучение того, как использовать KSQL, стриминговый SQL-движок для Kafka, для обработки данных в Kafka без написания какого-либо кода. Это то, что я рекомендовал бы в качестве отправной точки, особенно если вы новичок в Kafka или потоковой обработке, поскольку вы должны приступить к работе в считанные минуты. Также есть замечательная демка с KSQL clickstream (включая вариант с Docker), где вы можете поиграться с Kafka, KSQL, Elasticsearch и Grafana для создания и настройки real-time dashboard.
- Изучение того, как создавать Java или Scala приложения для потоковой обработки с использованием Kafka Streams API.
- И да, вы, конечно, можете объединить их, например вы можете начать обработку ваших данных с использованием KSQL, затем продолжить работу с Kafka Streams, а затем опять вернуться к KSQL.
Независимо от того, используете вы Kafka Streams или KSQL, благодаря Kafka вы получите гибкую, масштабируемую и отказоустойчивую распределённую потоковую обработку, которая работает повсюду (контейнеры, виртуалки, машины, локально, у заказчика, в облаках, ваш вариант). Просто скажу, если это не очевидно. :-)
Напоследок, я назвал эту статью «Стримы и Таблицы, Часть 1». И хотя у меня уже есть идеи для второй части, я буду благодарен за вопросы и предложения по тому, что я мог быть рассмотреть в следующий раз. О чём вы хотите узнать больше? Дайте мне знать в комментариях или напишите мне по электронной почте!
Если вы заметили неточность в переводе — напишите, пожалуйста, в личном сообщении или оставьте комментарий.
