[Перевод] Node.js в бою (создание кластера)
Когда вы используете приложения на node.js в продакшене, вам приходится задумываться о стабильности, производительности, безопасности и удобстве поддержки. Данная статья описывает мои мысли о лучших практиках использования node.js в бою.
К окончанию данного руководства вы получите систему из 3 серверов: балансировщик (lb) и 2 сервера приложений (app1 и app2). Балансировщик будет следить за доступностью серверов и распределять между ними траффик. Серверы приложений будут использовать комбинацию systemd и кластеризации node.js для балансировки траффика между несколькими процессами ноды на сервере. Вы сможете выкатывать код с помощью одной команды со своей машины, и при этом не будет перерывов в обслуживании или необработанных запросов.
Все это можно представить в виде схемы:
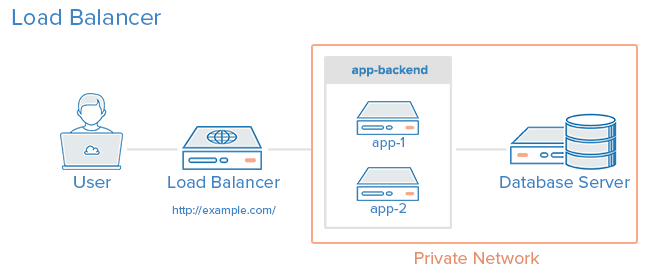
Фото предоставлено: Digital Ocean
От переводчика: с распространением изоморфного подхода к построению веб-приложений все больше разработчиков сталкиваются с необходимостью использования Node.js в продакшене. Эта статья Jeff Dickey понравилась мне практичным подходом и обзорным взглядом на эту широкую тему.
Об этой статье
Данная статья адресована тем, кто только начинает заниматься вопросами настройки серверов в боевую эксплуатацию. Однако, вы должны иметь общее представление о данном процессе, знать, что такое upstart, systemd или init, и что такое сигналы процессов в unix. Я предлагаю вам попробовать данное руководство на своих серверах (но все же использовать мой демо-код). Кроме этого, я приведу несколько полезных настроек конфигурации и скриптов, которые будут служить хорошей отправной точкой при настройке собственного окружения.
Итоговый вариант приложения находится здесь: https://github.com/dickeyxxx/node-sample.
В этом руководстве я буду использовать Digital Ocean и Fedora. Тем не менее, статья написана как можно более независимой от стека технологий.
Я буду использовать серверы Digital Ocean с ванильными образами Fedora 20. Я протестировал руководство несколько раз, поэтому у вас не должно возникнуть проблем при воспроизведении этих действий.
Почему Fedora?
Все дистрибутивы Linux (кроме Gentoo) переезжают c различных систем инициализации на systemd. Так как Ubuntu (пожалуй, самый популярный дистрибутив в мире) пока не перешел на него (но они это уже анонсировали), я считаю, что будет неправильно обучать вас использованию Upstart.
systemd предлагает несколько значительных преимуществ по сравнению с Upstart, включая продвинутое централизованное журналирование, упрощенную конфигурацию, производительность, и еще много каких возможностей.
Установка Node.js
Сначала вам необходимо установить node.js на свежий сервер. На Digital Ocean мне хватило всего 4 команд.
bootstrap.sh
yum update -y
yum install -y git nodejs npm
npm install -g n
n stable
Здесь мы устанавливаем ноду через yum (который может поставить нам устаревшую версию), потом ставим отличный пакет n, который умеет устанавливать и переключать различные версии ноды. Им мы и воспользуемся для обновления node.js.
Теперь запуститие # node --version и вы увидите информацию о последней версии ноды.
Позднее я покажу, как можно автоматизировать этот шаг с помощью Ansible.
Создайте пользователя web
Так как небезопасно запускать приложения от root, мы создадим отдельного пользователя web.
Для этого запустите: # useradd -mrU web
Добавляем приложение
У нас есть сервер ноды, и мы можем перейти к добавлению нашего приложения:
Создайте каталог: # mkdir /var/www
Установите ему владельца web: # chown web /var/www
А также группу web: # chgrp web /var/www
Войдите в него: # cd /var/www/
Переключитесь на нашего пользователя: $ su web
Клонируйте репозиторий с приложением Hello world: $ git clone https://github.com/dickeyxxx/node-hello-world
Это простейшее приложение для ноды:
app.js
var http = require('http');
var PORT = process.env.PORT || 3000;
http.createServer(function (req, res) {
console.log('%d request received', process.pid);
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello world!\n');
}).listen(PORT);
console.log('%d listening on %d', process.pid, PORT);
Запустите его: $ node app.js.
Можете зайти на сервер по IP, используя браузер, и вы увидите, что приложение работает:

Примечание: возможно вам понадобится запустить # iptables -F чтобы очистить таблицы iptables или открыть порт на файрволле firewall-cmd --permanent --zone=public --add-port=3000/tcp.
Еще примечание: По умолчанию приложение запускается на порту 3000. Чтобы запустить его на 80 порту вам понадобится прокси-сервер (наподобие nginx), но для нашей конфигурации необходимо запускать сервер приложения на порту 3000, а балансировщик (на другом сервере) будет работать на порту 80.
systemd
После того, как мы научились запускать сервер приложения нам нужно добавить его в systemd, чтобы он перезапускался в случае аварии.
Мы будем использовать следующий systemd скрипт:
node-sample.service
[Service]
WorkingDirectory=/var/www/node-hello-world
ExecStart=/usr/bin/node app.js
Restart=always
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=node-hello-world
User=web
Group=web
Environment='NODE_ENV=production'
[Install]
WantedBy=multi-user.target
Скопируйте этот файл (из-под root) в /etc/systemd/system/node-sample.service
Активируйте его: # systemctl enable node-sample
Запустите его: # systemctl start node-sample
Проверьте статус: # systemctl status node-sample
Посмотрите логи: # journalctl -u node-sample
Попробуйте убить процесс ноды по pid и посмотрите как он запустится снова!
Кластеризация процессов
Теперь, когда мы можем запускать один процесс с нашим приложением, нам нужно воспользоваться встроенными методами кластеризации ноды, которые позволят автоматически распределять траффик по нескольким процессам.
Вот скрипт, который можно использовать для запуска приложения Node.js.
Просто положите этот файл рядом с app.js и запустите: $ node boot.js
Этот скрипт запустит 2 экземпляра приложения, и будет перезапускать их при необходимости. Также он производит бесшовный перезапуск при получении сигнала SIGHUP.
Давайте попробуем это. Для этого сделаем изменения в том, что возвращает app.js . Запустите $ kill -hup [pid] и после этого в браузере вы сможете посмотреть новые данные. Скрипт перезапускает по одному процессу за один раз, обеспечивая этим бесшовный перезапуск.
Для работы кластеризованной версии приложения необходимо обновить конфигурацию systemd. Также, можно добавить настройку ExecReload=/bin/kill -HUP $MAINPID , чтобы systemd мог самостоятельно выполнять бесшовный перезапуск, когда получает команду # systemctl reload node-sample.
Вот пример файла для кластеризованной версии:
node-sample.service
[Service]
WorkingDirectory=/var/www/node-hello-world
ExecStart=/usr/bin/node boot.js
ExecReload=/bin/kill -HUP $MAINPID
Restart=always
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=node-sample
User=web
Group=web
Environment='NODE_ENV=production'
[Install]
WantedBy=multi-user.target
Балансировка
В боевой эксплуатации вам необходимо как минимум 2 сервера на случай если один из них упадет. Я бы не стал поднимать реальную систему всего с одним. Имейте в виду: серверы выключаются не только когда сломались, но и когда может понадобиться выключить один для обслуживания. Балансировщик проверяет доступность серверов и если замечает проблему, то исключает этот сервер из ротации.
Сначала установите второй сервер приложений, повторяя предыдущие шаги. Потом создайте новый сервер в Digital Ocean (или еще где-то) и подключитесь к нему через ssh.
Установите HAProxy: # yum install haproxy
Замените файл /etc/haproxy/haproxy.cfg на следующий (подставьте IP своих серверов):
haproxy.cfg
defaults
log global
mode http
option httplog
option dontlognull
option http-server-close
option forwardfor
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
frontend main *:80
stats enable
stats uri /haproxy?stats
stats auth myusername:mypass
default_backend app
backend app
balance roundrobin
server app1 107.170.145.120:3000 check
server app2 192.241.205.146:3000 check
Теперь перезагрузите HAProxy: systemctl restart haproxy
Вы должны увидеть на балансировщике запущенное приложение на 80 порту. Можете зайти на /haproxy?stats чтобы посмотреть страницу статуса HAProxy. Для входа используйте myusername/mypass.
Для дополнительной информации по настройке HAProxy предлагаю ознакомиться с руководством, которое я использовал, или с официальной документацией.
Деплой кода с помощью Ansible
Большинство руководств по настройке сервера на этом заканчиваются, но я думаю, что инструкция не будет полной без организации деплоя! Без автоматизации процесс выглядит не очень страшно:
- Подключиться по SSH на app1
cd /var/www/node-hello-world- Получить последнюю версию кода
git pull - И перезагрузить приложение
systemctl reload node-sample
Но главный минус в том, что это придется проделать на каждом сервере, а это трудоемко. Используя Ansible, мы можем выкатить наш код прямо со своей машины и должным образом перезагрузить приложение.
Люди боятся Ansible. Многие считают, что он похож на сложные инструменты вроде Chef или Puppet, но на самом деле он ближе к Fabric или Capistrano. В самом простом случае он просто подключается по ssh к серверу и выполняет команды. Без клиентов, мастер-серверов, сложных cookbooks — просто команды. У него есть отличные возможности для развертывания серверов (provisioning), но вы можете их не использовать.
Вот файл Ansible, который просто деплоит код:
deploy.yml
---
- hosts: app
tasks:
- name: update repo
git: repo=https://github.com/dickeyxxx/node-hello-world version=master dest=/var/www/node-hello-world
sudo: yes
sudo_user: web
notify:
- reload node-sample
handlers:
- name: reload node-sample
service: name=node-sample state=reloaded
production
[app]
192.241.205.146
107.170.233.117
Запустите его на своей машине для разработки (убедитесь, что вы установили Ansible):ansible-playbook -i production deploy.yml
Файл production в Ansible называется инвентарным файлом (inventory file). Он просто перечисляет адреса всех серверов и их роли.
Файл с расширением yml называется сценарий (playbook). Он определяет задачи для запуска. У нас он получает свежий код с github. Если есть изменения, то запускается задача «notify», которая перезагружает сервер приложений. Если изменений не было, то обработчик не запустится. Если вы, скажем, захотите установить npm пакеты, это можно сделать здесь же. Кстати, убедитесь, что вы используете npm shrinkwrap, если не фиксируете файлы зависимостей в репозитории.
Примечание: если вы хотите использовать личный git репозиторий, вам понадобится установить Перенаправление агента авторизации в SSH.
Ansible для развертывания (provisioning)
В идеале, мы должны автоматизировать сборку сервера приложений, чтобы не приходилось вручную повторять все шаги каждый раз. Для этого мы можем использовать следующий сценарий Ansible для развертывания сервера приложений:
app.yml
---
- hosts: app
tasks:
- name: Install yum packages
yum: name={{item}} state=latest
with_items:
- git
- vim
- nodejs
- npm
- name: install n (node version installer/switcher)
npm: name=n state=present global=yes
- name: install the latest stable version of node
shell: n stable
- name: Create web user
user: name=web
- name: Create project folder
file: path=/var/www group=web owner=web mode=755 state=directory
- name: Add systemd conf
template: src=systemd.service.j2 dest=/etc/systemd/system/node-sample.service
notify:
- enable node-sample
handlers:
- name: enable node-sample
shell: systemctl enable node-sample
systemd.service.j2
[Service]
WorkingDirectory={{project_root}}
ExecStart=/usr/bin/node boot.js
ExecReload=/bin/kill -HUP $MAINPID
Restart=always
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier={{project_name}}
User=web
Group=web
Environment='NODE_ENV=production'
[Install]
WantedBy=multi-user.target
Запускается так: ansible-playbook -i [inventory file] app.yml .
А вот то же самое для балансировщика.
Итоговое приложение
Вот итоговый результат всех этих шагов. Как там говорится, для запуска приложения нужно: обновить инвентарный файл, развернуть наши сервера и запустить деплой приложения.
Тестовая среда?
Создать новое окружение просто. Добавьте еще один инвентарный файл (ansible/production) для тестов и можете ссылаться на него, когда вызываете ansible-playbook .
Тестирование
Тестируйте вашу систему. Даже отбросив другие причины, это реально очень весело — пытаться найти путь обрушить ваш кластер. Используйте Siege для создания нагрузки. Попробуйте посылать kill -9 различным процессам. Выключите сервер совсем. Посылайте произвольные сигналы процессам. Забейте диск. Просто найдите вещи, которые могут развалить ваш кластер и застрахуйте себя от проседания %uptime.
Что можно улучшить
Нет идеальных кластеров, и этот не исключение. Я бы спокойно выложил его в продакшен, но в будущем можно кое-что усилить:
HAProxy Failover
В данный момент HAProxy это единая точка отказа, хотя и надежная. Мы могли бы убрать ее с помощью DNS Failover. Он не мгновенный и даст несколько секунд простоя, пока запись DNS распространяется. Я не переживаю, что HAProxy упадет сам по себе, но есть большая вероятность человеческой ошибки при изменении его конфигурации.
Последовательный деплой (Rolling deploys)
На случай если очередной деплой ломает кластер, я бы настроил последовательный деплой в Ansible, чтобы постепенно выкатывать изменения, проверяя по пути доступность серверов.
Динамические инвентарные файлы
Я думаю, некоторым это будет более важно, чем мне. В данном руководстве нам приходилось сохранять адреса серверов в исходном коде. Можно сконфигурировать Ansible так, чтобы он динамически запрашивал список хостов в Digital Ocean (или другом провайдере). Можно даже так создавать новые серверы. Однако, создание сервера на Digital Ocean это не самая сложная задача.
Централизованное журналирование
JSON журналы отличная вещь, если вы хотите легко агрегировать их и искать по ним. Я бы посмотрел на Bunyan для этого.
Было бы здорово, если бы логи всех серверов стекались в одно место. Можно использовать что-нибудь вроде Loggly, а можно попробовать другие пути.
Отчеты об ошибках и мониторинг
Существует множество решений по сбору ошибок и журналированию. Ни одно из тех, что я пробовал, мне не понравилось, так что я не берусь вам что-нибудь советовать. Если вы знаете хороший инструмент для этого, пожалуйста, напишите об этом в комментариях.
Рекомендую отличное руководство по запуску Node.js в продакшен от Joyent — там много дополнительных советов.
Вот и все! Мы построили простой, стабильный кластер Node.js. Дайте мне знать, если у вас есть идеи, как улучшить его!
От переводчика: спасибо за то, что вы еще здесь. Я впервые пробую себя в роли переводчика. Уверен, что не все перевел правильно, поэтому прошу присылать сообщения об ошибках, а также опечатках и проблемах оформления по внутренней почте.
