[Перевод] Не так-то просто обнулять массивы в VC++ 2015
 В чем разница между двумя этими определениями инициализированных локальных переменных С/С++?
В чем разница между двумя этими определениями инициализированных локальных переменных С/С++? char buffer[32] = { 0 };
char buffer[32] = {};Одно отличие состоит в том, что первое допустимо в языках С и С++, а второе — только в С++.
Что ж, давайте тогда сосредоточимся на С++. Что означают эти два определения?
Первое гласит: компилятор должен установить значение первого элемента массива в ноль и затем (грубо говоря) инициализировать нулями оставшиеся элементы массива. Второе означает, что компилятор должен инициализировать нулями весь массив.
Эти определения несколько различаются, но по факту результат один — весь массив должен быть инициализирован нулями. Поэтому согласно правилу «as-if» в С++ они одинаковы. То есть любой достаточно современный оптимизатор должен генерировать идентичный код для каждого из этих фрагментов. Верно?
Но иногда различия в этих определениях имеют значение. Если (гипотетически) компилятор примет эти определения в высшей степени буквально, то для первого случая будет сгенерирован такой код:
алгоритм 1: buffer[0] = 0;
memset(buffer + 1, 0, 31);в то время как для второго случая код будет таким:
алгоритм 2: memset(buffer, 0, 32);И если оптимизатор не заметит, что эти два утверждения могут быть совмещены, то компилятор может сгенерировать для первого определения менее эффективный код, чем для второго.
Если компилятор буквально реализовал алгоритм 1, то нулевое значение будет присвоено первому байту данных, затем (если процессор 64-разрядный) будут выполнены три операции записи по 8 байтов. Для заполнения оставшихся семи байтов могут потребоваться еще 3 операции записи: сначала запись 4 байтов, потом 2 и затем еще 1 байта.
Ну, это гипотетически.
Именно так и работает VC++. Для 64-разрядных сборок типичный код, сгенерированный для »= {0}», выглядит так:
xor eax, eax
mov BYTE PTR buffer$[rsp+0], 0
mov QWORD PTR buffer$[rsp+1], rax
mov QWORD PTR buffer$[rsp+9], rax
mov QWORD PTR buffer$[rsp+17], rax
mov DWORD PTR buffer$[rsp+25], eax
mov WORD PTR buffer$[rsp+29], ax
mov BYTE PTR buffer$[rsp+31], alГрафически это выглядит так (почти все операции записи не выровнены):

Но если опустить ноль, VC++ сгенерирует следующий код:
xor eax, eax
mov QWORD PTR buffer$[rsp], rax
mov QWORD PTR buffer$[rsp+8], rax
mov QWORD PTR buffer$[rsp+16], rax
mov QWORD PTR buffer$[rsp+24], raxЧто выглядит примерно так:

Вторая последовательность команд короче и выполняется быстрее. Разницу в скорости обычно трудно измерить, но вам в любом случае следует отдавать предпочтение более компактному и быстрому коду. Размер кода влияет на производительность на всех уровнях (сеть, диск, кэш-память), поэтому лишние байты кодов нежелательны.
Это в общем-то не важно, вероятно, это даже не окажет сколько-нибудь заметного влияния на размер реальных программ. Но лично я считаю код, сгенерированный для »= { 0 };», довольно забавным. Равносильным постоянному употреблению «эээ» при публичном выступлении.
Впервые я заметил такое поведение и сообщил о нем шесть лет назад, а недавно обнаружил, что эта проблема всё ещё присутствует в VC++ 2015 Update 3. Мне стало любопытно, и я написал небольшой скрипт на Python, чтобы скомпилировать код, указанный ниже, используя различные размеры массива и разные варианты оптимизации для платформ х86 и х64:
void ZeroArray1()
{
char buffer[BUF_SIZE] = { 0 };
printf("Не оптимизируйте пустой буфер.%s\n”, buffer);
}
void ZeroArray2()
{
char buffer[BUF_SIZE] = {};
printf("Не оптимизируйте пустой буфер.%s\n”, buffer);
}Представленный ниже график демонстрирует размер этих двух функций в одной конкретной конфигурации платформы — оптимизация размера для 64-разрядной сборки — в сопоставлении со значениями BUF_SIZE, колеблющимися от 1 до 32 (когда значение BUF_SIZE превышает 32, размеры вариантов кода одинаковы):

В случаях когда значение BUF_SIZE равно 4, 8 и 32, экономия памяти впечатляющая — размер кода уменьшается на 23,8%, 17,6% и 20,5% соответственно. Средний объем сэкономленной памяти составляет 5,4%, и это довольно существенно, учитывая, что все эти функции имеют общий код эпилога, пролога и вызов printf.
Здесь я хотел бы порекомендовать всем программистам С++ при инициализации структур и массивов отдавать предпочтение »= {};» вместо = »= { 0 };». На мой взгляд, он лучше с эстетической точки зрения, и, кажется, почти всегда генерирует более короткий код.
Но именно «почти». Результаты, приведенные выше, демонстрируют, что есть несколько случаев, когда »= {0};» генерирует более оптимальный код. Для одно- и двухбайтовых форматов »= { 0 };» немедленно записывает ноль в массив (согласно команде), в то время как »= {};» обнуляет регистр и уже потом создает такую запись. Для 16-байтного формата »= { 0 };» использует регистр SSE, чтобы обнулить все байты одновременно — не знаю, почему в компиляторах этот метод не используется чаще.
Итак, прежде чем что-либо порекомендовать, я счел своим долгом испытать разнообразные настройки оптимизации для 32-разрядной и 64-разрядной систем. Основные результаты:
32-разрядная с /O1/Oy-: Средняя экономия памяти от 1 до 32 составляет 3,125 байта, 5,42%.
32-разрядная с /О2/Оу-: Средняя экономия памяти от 1 до 40 составляет 2,075 байта, 3,29%.
32-разрядная с /О2: Средняя экономия памяти от 1 до 40 составляет 1,150 байт, 1,79%.
64-разрядная с /О1: Средняя экономия памяти от 1 до 32 составляет 3,844 байта, 5,45%
64-разрядная с /О2: Средняя экономия памяти от 1 до 32 составляет 3,688 байта, 5,21%.
Проблема в том, что результат для 32-разрядной /О2/Оу-, где »= {};» в среднем на 2,075 байта больше, чем при »= { 0 };». Это справедливо для значений от 32 до 40, где код »= {};» обычно на 22 байта больше! Причина в том, что для обнуления массива код »= {};» использует команды «movaps» вместо «movups». Это означает, что ему приходится использовать массу команд только для того, чтобы обеспечить выравнивание стека по 16 байтам. Вот незадача.
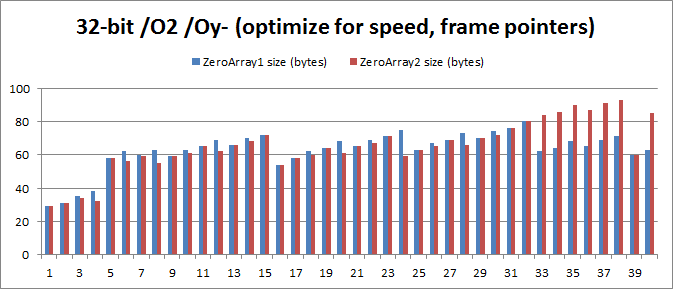
Я все же рекомендую программистам С++ отдавать предпочтение »= {};», хоть несколько противоречивые результаты и показывают, что предоставляемое этим вариантом преимущество является незначительным.
Было бы неплохо, если бы оптимизатор VC++ генерировал идентичный код для этих двух компонентов, и было бы великолепно, если бы этот код был идеальным всегда. Может быть, когда-нибудь так и будет?
Хотелось бы мне знать, почему оптимизатор VC++ столь непоследователен при принятии решения о том, когда следует использовать 16-байтовые регистры SSE для обнуления памяти. В 64-битных системах этот регистр используется только для 16-байтовых буферов, инициализированных с помощью »= { 0 };», несмотря на то, что с SSE обычно генерируется более компактный код.
Думаю, эти трудности с генерацией кода характерны и для более серьезной проблемы, связанной с тем, что смежные инициализаторы агрегатов не объединяются. Однако я уже достаточно много времени уделил этому вопросу, так что оставлю его на уровне теории.
Здесь я сообщил об этом баге, а скрипт на Python можно найти тут.
Обратите внимание, что представленный ниже код, который также должен быть эквивалентным, в любом случае генерирует даже худший код, чем ZeroArray1 и ZeroArray2.
char buffer[32] = "”;Хотя сам я не проводил тестирование, я слышал, что компиляторы gcc и clang не попались на удочку »= { 0 };».
В более ранних версиях VC++ 2010 проблема была серьезнее. В некоторых случаях использовался вызов memset, и »= { 0 };» при любых обстоятельствах гарантировал неверное выравнивание адреса. В более ранних версиях VC++ 2010 CRT при неверном выравнивании последние 128 байт данных записывались в четыре раза медленнее (команда stosb вместо stosd). Это быстро исправили.
Перевод выполнен ABBYY LS
