[Перевод] Не потерял ли GraphQL актуальности в эпоху HTTP/2?
Недавно Фил Стерджен опубликовал твит, который сильно задел любителей GraphQL. В этом твите речь шла о том, что GraphQL — это, по определению, технология, которая противоречит сущности HTTP/2. О том, что уже вышел стандарт HTTP/3, и о том, что автор твита не очень понимает тех, кто, выбирая GraphQL, идёт путём несовместимости. Для того чтобы лучше понять причины такого отношения Фила к GraphQL — взгляните на этот материал.

Примерно в то же самое время было сделано сообщение о появлении проекта Vulcain. В это сообщение входили такие слова: «TL/DR: GraphQL вам больше не нужен!». И наконец — вышла замечательная статья Марка Ноттингема, посвящённая мощным возможностям HTTP/2, и тому, что эти возможности означают для тех, кто проектирует API. Ссылкой на эту статью поделился со своими подписчиками Даррел Миллер.
Происходящее заставило меня задуматься о GraphQL и об HTTP/2. Если всё вокруг начнёт работать с использованием HTTP/2 (и HTTP/3), будет ли это значить, что у нас не останется причин использовать GraphQL? Вот это мне и хотелось бы сегодня выяснить.
Новшества HTTP/2
Для начала давайте разберёмся с тем, что в технологии HTTP/2 способно повлиять на ценность GraphQL в глазах разработчиков. В HTTP/2 имеется много нового. Это, например, новый бинарный формат и улучшение сжатия заголовков. Но в нашем случае главную роль играет то, как при использовании HTTP/2 обрабатывается доставка запросов и ответов.
Открытие TCP-соединения — это ресурсозатратная операция. Клиенты, использующие HTTP/1, стремятся к тому, чтобы не выполнять её слишком часто. По этой причине, из-за большой дополнительной нагрузки на системы, разработчики часто пытались ограничить число запросов, прибегая к самым разным технологиям. Это, например, выполнение пакетных запросов, использование языков запросов, встраивание CSS/JS-кода в код страниц, использование спрайт-листов вместо отдельных изображений, и так далее. В HTTP/1.1. сделана попытка решить некоторые из этих проблем с использованием постоянных соединений и конвейерной обработки данных. Эти две технологии позволяли браузерам отправлять, в рамках одного соединения, несколько запросов, и получать ответы на них. Недостаток такой схемы обмена данными заключался в том, что она подвержена проблеме блокировки начала очереди (Head-of-line blocking). Эта проблема выражается в том, что один медленный запрос может замедлить обработку всех запросов, следующих за ним. Специалисты, которые занимались работой над HTTP/2, предложили разные способы решения этой проблемы. Вместе с новым бинарным протоколом HTTP/2 представляет и новую стратегию доставки данных. В ходе взаимодействия систем по протоколу HTTP/2 открывается единственное соединение, в рамках которого выполняется мультиплексирование запросов и ответов с использованием нового бинарного уровня, предназначенного для работы с кадрами, когда каждый кадр является частью потока. Клиенты и серверы, при использовании этого механизма, могут воссоздавать потоки запросов и ответов на основе сведений о них, которые есть в кадрах. Это позволяет HTTP/2 очень эффективно поддерживать обработку множества запросов, выполняемых в рамках единственного соединения.
Но это ещё не всё. В HTTP/2 имеется новая концепция, называемая Server Push. Если не вдаваться в детали, то можно сказать, что эта технология позволяет серверам заранее отправлять клиентам данные, выполняя это до того, как клиенты эти данные запрашивают. Наиболее яркие примеры подобного поведения — это заблаговременная отправка клиентам таблиц стилей и JavaScript-ресурсов. В ходе формирования ответа на HTTP-запрос сервер может выяснить, что для рендеринга HTML-страницы нужен некий CSS-файл, и заранее узнать о том, что клиент скоро обратится к нему за этим файлом. Это позволяет серверу отправить клиенту данный файл ещё до того, как клиент его запросит. Именно так работает вышеупомянутый проект Vulcain, используя эту технологию для организации эффективной загрузки связанных ресурсов.
Так, пока всё понятно. Но какое отношение всё это имеет к GraphQL?
GraphQL: один запрос, решающий все проблемы
Технология GraphQL отчасти обязана своей привлекательностью тем, что она помогает разработчикам справляться с недостатками, характерными для HTTP/1-соединений.
Именно поэтому GraphQL позволяет клиентам, за один сеанс связи с сервером, выполнять запросы на получение практически всего чего угодно. Это можно противопоставить Hypermedia-API, при использовании которых обычно нужно выполнять множество сетевых запросов (иногда, правда, ситуацию может улучшить кэширование).
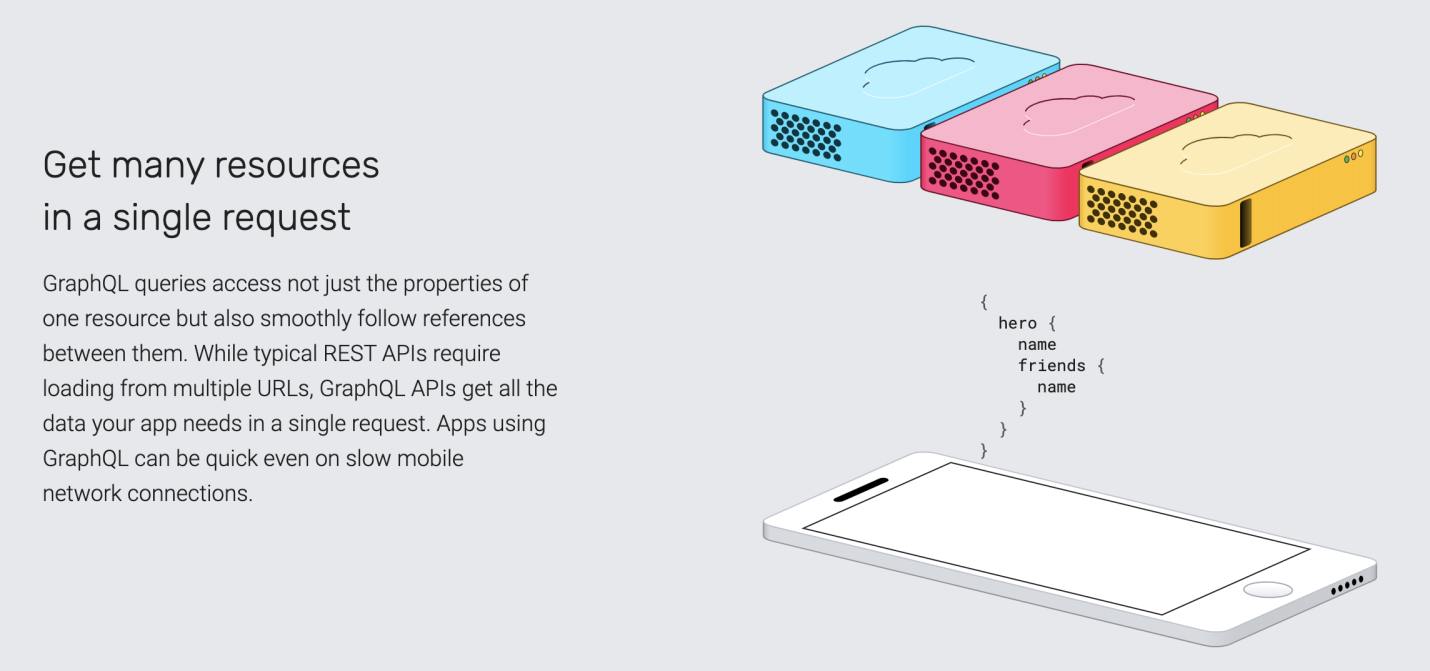
Возможность получения множества ресурсов в рамках единственного запроса — одна из сильных сторон GraphQL, к которой создатели этой технологии привлекают внимание её потенциальных пользователей
Многие из тех, кто говорит о том, что технология GraphQL с приходом HTTP/2 никому больше не нужна, имеют в виду именно эту возможность. Использование пакетных API, языков запросов (таких, как GraphQL), оптимизация отношений, и даже создание укрупнённых конечных точек, выглядят теперь уже не так привлекательно, как раньше. Всё дело в том, что «стоимость» выполнения запросов становится небольшой. И это — чистая правда. Но только ли поэтому мы пользуемся GraphQL? Я так не думаю.
Возможно, дело в том, что сейчас — всё ещё ранние дни HTTP/2-клиентов и некоторых серверных приложений?
Не думаю, что вопрос, вынесенный в заголовок этого раздела, служит достойным объяснением того, что мы всё ещё широко используем GraphQL. Но упомянуть об этом стоит. Использование HTTP/2 на уровне приложения в некоторых экосистемах — задача, которая пока далека от решения. Поищите, например, по словам «Rack/Rails over HTTP/2». Будет интересно. Всё дело в том, что множество серверных частей приложений построены с использованием паттерна запрос/ответ. В результате переход на концепцию потоков HTTP/2 — это не так уж и просто. Особенно — в случае с некоторыми фреймворками. Но это — недостойное оправдание, множество экосистем отлично поддерживают такую схему взаимодействия клиентов и серверов, и, в теории, нам всё ещё стоит стремиться к тому, чтобы усовершенствовать подобное взаимодействие. (Это поддерживает и большинство прокси-серверов, но непросто организовать что-то наподобие отправки данных клиенту по инициативе сервера в том случае, если серверное приложение «застряло» в прошлом, используя паттерн запрос/ответ).
GraphQL — это больше, чем уменьшение времени приёма-передачи данных, или оптимизация объёма передаваемой информации
Хотя уменьшение времени приёма-передачи данных и оптимизация объёма передаваемой информации — это те сильные стороны GraphQL, о которых постоянно приходится слышать, данная технология даёт нам гораздо больше.
Мощь технологии GraphQL заключается в её ориентированности на клиентские системы. Клиент — это та среда, в которой GraphQL идёт на множество компромиссов. В последние годы это многих беспокоило. Так, Даниэль Якобсон 5–7 лет назад написал много хороших статей о некоторых из этих проблем. Вот и вот — пара его публикаций. Он говорит в одной из них: «Наши REST API, хотя они и в состоянии обрабатывать запросы общего характера, не оптимизированы ни под один из подобных запросов».
Обратите внимание на то, что эта мысль справедлива не только в применении к технологии REST. Клиентским приложениям часто приходится выполнять больше запросов к серверу, чем хотелось бы их разработчикам. Приходится этим приложениям и заниматься приёмом от серверов ненужных данных. Это больше относится к проектированию API, которые хорошо было бы создавать так, чтобы они поддерживали бы множество различных вариантов их использования. Обычный способ решения этой проблемы заключается в том, чтобы клиентская логика располагалась бы как можно ближе к серверной логике. Пример такого подхода — клиентские адаптеры Netflix, упомянутые в этом материале 2012 года. С тех пор некоторые команды в Netflix даже перешли на GraphQL. На решение подобных проблем направлен и паттерн BFF.
Технология GraphQL меняет понятие границы между клиентом и сервером, помогая нам создавать серверные системы, способные включать в себя сведения о том, как ими будут пользоваться клиенты. Довольно ярко это проявляется при использовании технологии постоянных запросов, так как тут речь идёт, в сущности, о серверных ресурсах, сгенерированных по инициативе клиента.
При размышлении об актуальности GraphQL в HTTP/2-мире стоит помнить о том, что речь идёт о серверной абстракции. Поддержка различных вариантов использования серверных данных может приводить к проблемам в традиционных API, основанных на конечных точках. GraphQL позволяет тем, кто поддерживает API, сконцентрироваться на том, чтобы дать пользователям этих API широкий набор возможностей. При этом владельцы API могут не беспокоиться о росте нагрузки на существующие клиенты, и о том, что поддержка API значительно усложнится из-за необходимости поддержки множества различных ресурсов. (У поддержки множества различных ресурсов есть свои минусы. Так, подобные схемы усложняют оптимизацию производительности. Такие ресурсы не всегда хорошо поддаются кэшированию. С теми же проблемами сталкиваются и API, поддающиеся серьёзной настройке).
Разработка клиентских систем и GraphQL
В этом материале я, в основном, говорю о серверах, но важно помнить о том, что технологию GraphQL очень любят разработчики клиентов. Если фрагменты GraphQL соединить с компонентным подходом из современных фронтенд-фреймворков, то получится совершенно потрясающая абстракция. И, опять же, если добавить сюда ещё и постоянные запросы, то можно сказать, что GraphQL значительно облегчает жизнь разработчикам клиентских систем.
GraphQL — это целостная система, отличающаяся замечательными возможностями
GraphQL — это не нечто такое, что обладает совершенно уникальными возможностями. У этой системы есть альтернативы. Типизированная схема? То же самое есть и в OpenAPI! Серверные абстракции, поддерживающие разные варианты использования данных клиентами? Это можно реализовать множеством способов. Интроспекция? Использование Hypermedia позволяет клиентам обнаруживать действия и начинать работу с корневой сущности. Восхитительный инструмент GraphiQL? Уверен, нечто подобное создано и для OpenAPI. Возможности GraphQL всегда можно воссоздать, пользуясь другими технологиями. Однако GraphQL — целостная система. Именно это и привлекает к GraphQL столь обширную аудиторию разработчиков, которые с удовольствием этой системой пользуются. Подозреваю, что в этом кроется и одна из причин быстрого распространения и развития GraphQL. Кроме того, так как построение GraphQL-API хорошо документировано, GraphQL-библиотеки, рассчитанные на различные языки, обычно отличаются высоким качеством и популярностью.
Сеть — это всё ещё ограничивающий фактор (а, может быть, так будет всегда?)
Вот ещё одна мысль, на которой я хочу остановиться. Возникает такое ощущение, что сеть, если говорить о работе с API, всегда будет играть роль некоего ограничивающего фактора. При этом неважно то, насколько быстрыми будут сетевые запросы. Именно поэтому мы и не проектируем веб-API так же, как обычные объекты, используемые в разных языках программирования. Здесь, например, идёт речь о том, почему интерфейсы с высоким уровнем детализации не очень подходят для создания систем, рассчитанных на удалённую работу с ними.
В то время как HTTP/2, определённо, поощряет выполнение запросов с высокой детализацией, я думаю, что и здесь приходится идти на определённые компромиссы.
Может ли HTTP/2 помочь GraphQL?
Итак, GraphQL даёт в руки разработчика множество важных и полезных инструментов, но и HTTP/2 — тоже технология замечательная. Давайте посмотрим в будущее и подумаем о том, какие преимущества GraphQL-системы могут извлечь из использования HTTP/2. Например, это может выглядеть так:
query {
viewer {
name
posts(first: 100) @stream {
title
}
}
}
Получается, что мы вполне можем пользоваться серверной абстракцией GraphQL, декларативным языком запросов этой технологии, и при этом задействовать возможности HTTP/2-потоков. Я так думаю, что тут используются веб-сокеты. Мне нужно ещё в этом разобраться, но я уверен в том, что многие уже исследуют такие GraphQL-директивы, как @defer, @stream и @live.
Итоги
HTTP/2 — это замечательная технология (а примеры, приведённые, здесь — это просто чудо какое-то). GraphQL можно воспринимать лишь как технологию, уменьшающую число сеансов связи клиента с сервером, или помогающую оптимизировать объёмы передаваемых данных. Если так — тогда тот, кто видит GraphQL с подобной точки зрения, будет вполне счастлив, используя API, основанные на возможностях HTTP/2. Однако если видеть в GraphQL совокупность технологий, дающую разработчику много полезного, то становится ясно, что сила GraphQL совсем не ограничивается улучшением использования сетевых ресурсов и экономией трафика.
Уважаемые читатели! Если вы пользуетесь технологией GraphQL — просим рассказать нам о том, что вам больше всего в ней не нравится.


