[Перевод] Наглядно о том, почему трансформеры работают настолько хорошо

Трансформеры за последние несколько лет штурмом захватили мир NLP, а сегодня они с успехом применяются в выходящих за рамки NLP приложениях. Они обладают такими возможностями благодаря модулю внимания, который схватывает отношения между всеми словами последовательностей. Но самый важный вопрос — как именно трансформеры делают это? Попытаемся ответить и понять, почему трансформеры способны выполнять такие вычисления. Итак, цель статьи, чуть сокращённым переводом которой мы делимся к старту курса о машинном и глубоком обучении, — разобраться не только с тем, как что-то работает, но и почему работает так. Чтобы понять, что движет трансформерами, мы должны сосредоточиться на модуле внимания. Начнём с входных данных и посмотрим, как они обрабатываются.
Как входная последовательность попадает в модуль внимания
Модуль внимания присутствует в каждом энкодере внутри стека каждого энкодера, а также внутри стека каждого декодера. Сначала внимательно посмотрим на энкодер.
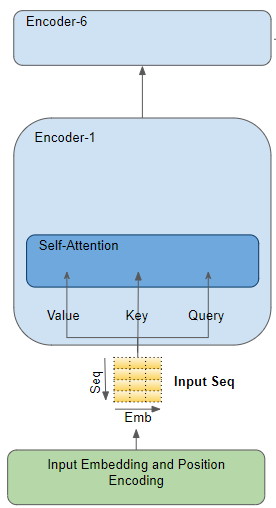 Модуль внимания в энкодере
Модуль внимания в энкодереДля примера предположим, что мы работаем над задачей перевода с английского на испанский, где исходная последовательность слов — «The ball is blue», а целевая последовательность — «La bola es azul».
Исходная последовательность сначала проходит через слой векторного представления и позиционного кодирования, генерирующего векторы векторного представления для каждого слова последовательности. Векторное представление передаётся в энкодер, где вначале попадает в модуль внимания.
Внутри модуля внимания последовательность векторного представления проходит через три линейных слоя, создающих три отдельные матрицы — запроса (Query), ключа (Key) и значения (Value). Именно эти три матрицы используются для вычисления оценки внимания [прим. перев. —оценка определяет, сколько внимания нужно уделить другим частям входного предложения, когда мы кодируем слово в определённой позиции]. Важно помнить, что каждая «строка» этих матриц соответствует одному слову исходной последовательности.
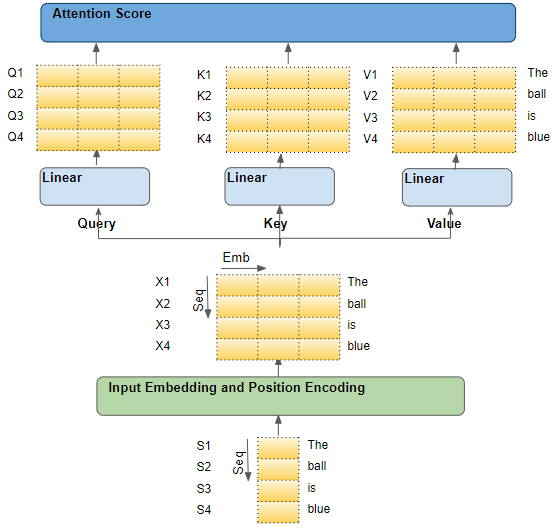 Поток исходной последовательности
Поток исходной последовательностиКаждая входная строка — это слово из последовательности
Чтобы понять, что происходит с модулем внимания, мы начнём с отдельных слов исходной последовательности, проследив их путь через трансформер. Если конкретнее, мы хотим сосредоточиться на происходящем внутри модуля внимания. Это поможет нам чётко увидеть, как каждое слово в исходной и целевой последовательностях взаимодействует с другими словами этих последовательностей.
Пока вы разбираетесь с этим объяснением, сосредоточьтесь на том, какие операции выполняются с каждым словом и как каждый вектор отображается на исходное входное слово. Не нужно думать о множестве других деталей, таких как формы матриц, особенности арифметических вычислений, множественное внимание и так далее, если эти детали не относятся напрямую к тому, куда направляется каждое слово. Итак, чтобы упростить объяснение и визуализацию, давайте проигнорируем размерность векторного представления и будем отслеживать только строки для каждого слова.
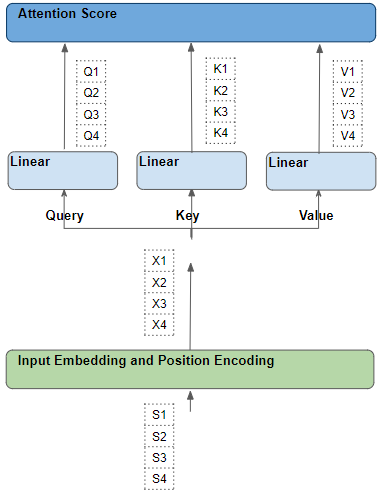 Расположение каждого слова в исходной последовательности
Расположение каждого слова в исходной последовательностиКаждое слово проходит серию обучаемых преобразований (трансформаций)
Каждая такая строка была сгенерирована из соответствующего исходного слова посредством серии трансформаций — векторного представления, позиционного кодирования и линейного слоя. Все эти трансформации возможно обучить; это означает, что используемые в этих операциях веса не определены заранее, а изучаются моделью таким образом, чтобы они давали желаемые выходные прогнозы.
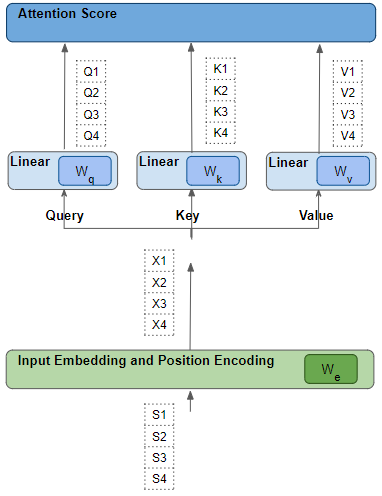 Линейные веса и веса векторного представления обучены
Линейные веса и веса векторного представления обученыКлючевой вопрос заключается в том, как трансформер определяет, какой набор весов даст ему наилучшие результаты? Держите этот момент в памяти — мы вернёмся к нему немного позже.
Оценка внимания — это скалярное произведение матрицы ключа и матрицы запроса слов
Модуль внимания выполняет несколько шагов, но здесь мы сосредоточимся только на линейном слое и на оценке внимания.
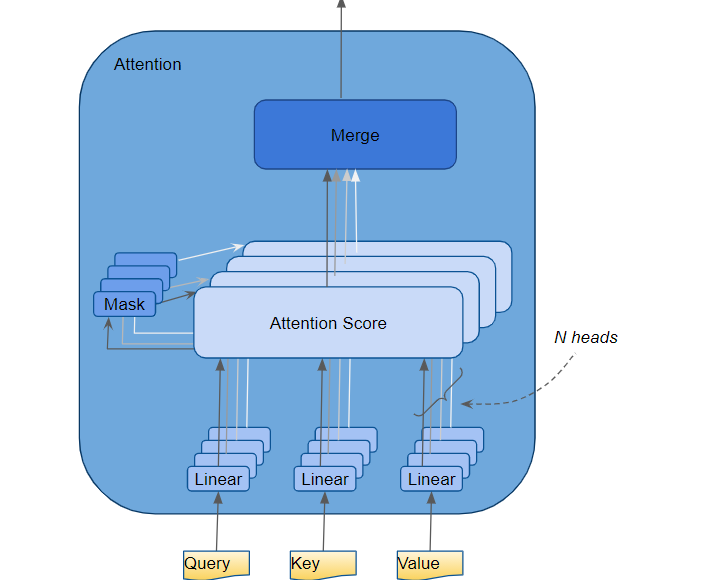 Многоголовое внимание
Многоголовое внимание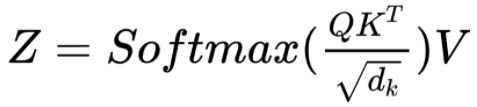 Расчёт оценки внимания
Расчёт оценки вниманияКак видно из формулы, первый шаг в рамках модуля внимания — умножение матрицы, то есть скалярное произведение между матрицей Query (Q) и транспонированием матрицы ключа Key (K). Посмотрите, что происходит с каждым словом. Итог — промежуточная матрица (назовём её «факторной» матрицей [матрицей множителей]), где каждая ячейка — это результат матричного умножения двух слов.
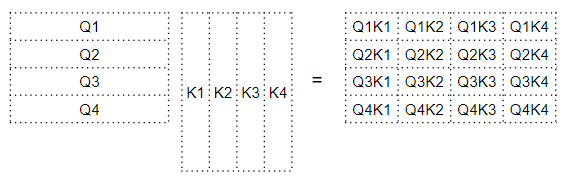 Скалярное произведение матрицы запроса и матрицы ключа
Скалярное произведение матрицы запроса и матрицы ключаНапример, каждый столбец в четвёртой строке соответствует скалярному произведению между четвёртым словом запроса и каждым ключевым словом.
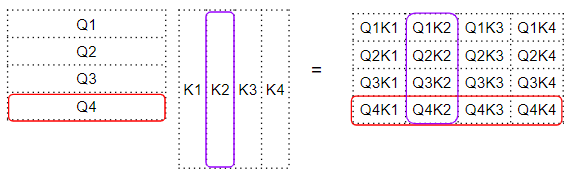 Скалярное произведение между матрицами запроса и ключа
Скалярное произведение между матрицами запроса и ключаОценка внимания — скалярное произведение между запросом-ключом и значением слов
Следующим шагом является матричное умножение между этой промежуточной матрицей «множителей» и матрицей значений (V), чтобы получить оценку внимания, который выводится модулем внимания. Здесь мы можем видеть, что четвёртая строка соответствует четвёртой матрице слов запроса, умноженной на все остальные ключевые слова и значения.
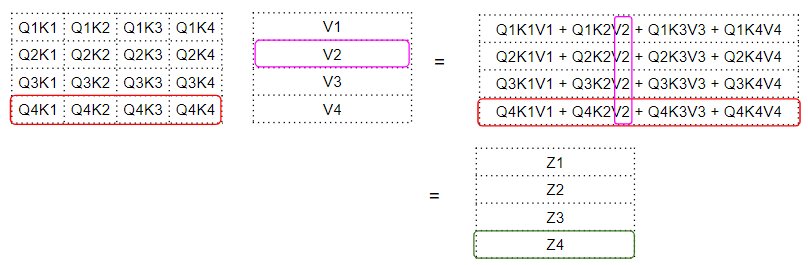 Скалярное произведение между матрицами ключа запроса и значения
Скалярное произведение между матрицами ключа запроса и значенияПолучается вектор оценки внимания (Z), который выводится модулем внимания. Выходной результат можно представить следующим образом: для каждого слова это закодированное значение каждого слова из матрицы «Значение», взвешенное матрицей множителей. Матрица множителей представляет собой точечное произведение значения запроса для данного конкретного слова и значения ключа для всех слов.
 Оценка внимания — это взвешенная сумма значения слов
Оценка внимания — это взвешенная сумма значения словКакова роль слов запроса, ключа и значения?
Слово запроса — это слово, для которого мы рассчитываем внимание. В свою очередь слово ключа и значения — это слово, на которое мы обращаем внимание, то есть определяем, насколько это слово соответствует слову запроса.
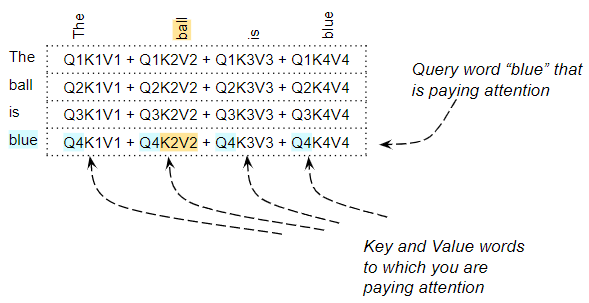 Оценка внимания для слова «blue» обращает внимание на каждое слово
Оценка внимания для слова «blue» обращает внимание на каждое словоНапример, для предложения «The ball is blue» строка для слова «blue» будет содержать оценку внимания для слова «blue» с каждым вторым словом. Здесь «blue» — это слово запроса, а другие слова — «ключ/значение». Выполняются и другие операции, такие как деление и softmax, но мы можем проигнорировать их в этой статье. Они просто изменяют числовые значения в матрицах, но не влияют на положение каждой строки слов в ней. Они также не предполагают никаких взаимодействий между словами.
Скалярное произведение сообщает нам о сходстве слов
Итак, мы увидели, что оценка внимания отражает некоторое взаимодействие между определённым словом и каждым другим словом в предложении путём скалярного произведения с последующим их сложением. Но как матрица умножения помогает трансформеру определять релевантность между двумя словами?
Чтобы понять это, вспомните, что строки запроса, ключа и значения на самом деле являются векторами с размерностью векторного представления. Давайте посмотрим, как умножаются матрицы между этими векторами.
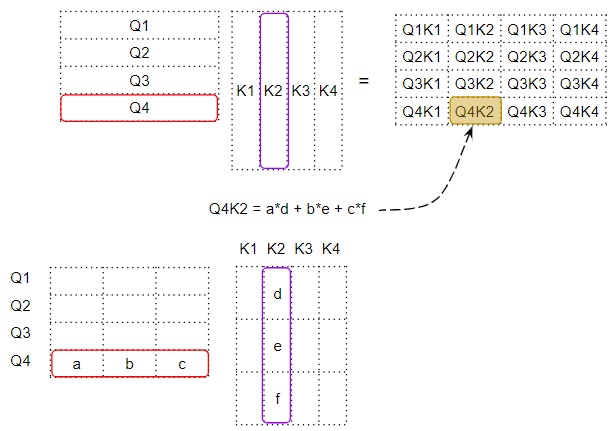 Каждая ячейка представляет собой скалярное произведение двух векторов слов
Каждая ячейка представляет собой скалярное произведение двух векторов словДля получения скалярного произведения двух векторов мы умножаем пары чисел, а затем суммируем их.
Если два парных числа (например, «a» и «d» выше) оба положительны или оба отрицательны, произведение положительно. Произведение увеличит итоговую сумму.
Если одно число положительное, а другое отрицательное, произведение будет отрицательным. Произведение уменьшит итоговую сумму.
Если произведение положительное, то, чем больше два числа, тем больше их вклад в окончательную сумму.
Это означает, что, если знаки соответствующих чисел в двух векторах выровнены, итоговая сумма будет больше.
Как трансформер изучает релевантность между словами?
Скалярное произведение также применимо к оценке внимания. Если векторы для двух слов более выровнены, оценка внимания будет выше. Итак, какого поведения мы хотим от трансформера? Мы хотим, чтобы оценка внимания была высокой для двух релевантных друг другу слов в предложении. И мы хотим, чтобы оценка двух слов, не связанных друг с другом, была низкой.
Например, в предложении «The black cat drank the milk» слово «milk» очень релевантно к «drank», возможно, немного менее релевантно для «cat», и нерелевантно к «black». Мы хотим, чтобы «milk» и «drink» давали высокую оценку внимания, чтобы «milk» и «cat» давали немного более низкую оценку, а для «milk» и «black» — незначительную. Мы хотим, чтобы модель научилась воспроизводить этот результат. Чтобы достичь воспроизводимости, векторы слов «milk» и «drank» должны быть выровнены. Векторы «milk» и «cat» несколько разойдутся. А для «milk» и «black» они будут совершенно разными.
Давайте вернёмся к вопросу, который мы откладывали: как трансформер определяет, какой набор весов даст ему наилучшие результаты? Векторы слов генерируются на основе векторного представления слов и весов линейных слоёв. Следовательно, трансформер может изучить эти векторные представления, линейные веса и так далее, чтобы создать векторы слов, как требуется выше.
Другими словами, он будет изучать эти векторные представления и веса таким образом, что если два слова в предложении релевантны друг другу, то их векторы слов будут выровнены, следовательно, получат более высокe. оценку внимания. Для слов, которые не имеют отношения друг к другу, их векторы не будут выровнены и оценка внимания будет ниже.
Следовательно, векторные представления слов «milk» и «drank» будут очень согласованными и обеспечат высокую оценку внимания. Они будут несколько отличаться для «milk» и «cat», производить немного более низкую оценку и будут совершенно разными в случае «milk» и «black»: оценка внимания будет низкой — вот лежащий в основе модуля внимания принцип.
Итак, как же работает трансформер?
Скалярное произведение между запросом и ключом вычисляет релевантность между каждой парой слов. Эта релевантность затем используется как «множитель» для вычисления взвешенной суммы всех «значений» слов. Эта взвешенная сумма выводится как оценка внимания. Трансформер изучает векторные представления и т. д. таким образом, что релевантные друг другу слова были более согласованы.
В этом кроется одна из причин введения трёх линейных слоёв и создания трёх версий входной последовательности: для запроса, ключа и значения. Такой подход даёт модулю внимания ещё несколько параметров, которые он может изучить, чтобы подстроить процесс создания векторов слов.
Самовнимание энкодера в трансформере
Внимание используется в трансформере в трёх местах:
Самовнимание в энкодере — исходная последовательность обращает внимание на себя.
Самовнимание в декодере — целевая последовательность обращает внимание на себя.
Энкодер-декодер-внимание в декодере — целевая последовательность обращает внимание на исходную последовательность.
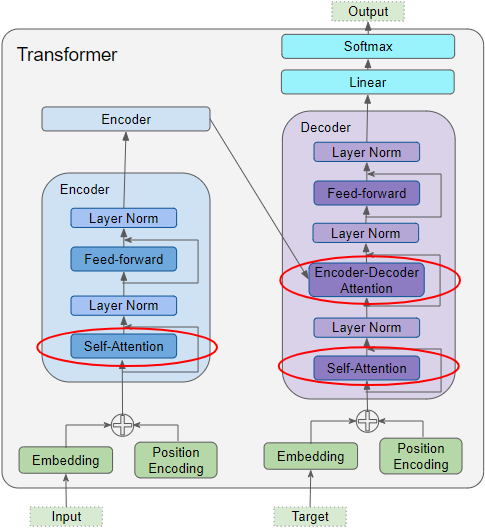 Внимание в Трансформере
Внимание в ТрансформереВ самовнимании энкодера мы вычисляем релевантность каждого слова в исходном предложении каждому другому слову в исходном предложении. Это происходит во всех энкодерах стека.
Декодер самовнимания в трансформере
Большая часть того, что мы только что видели в энкодере самовнимания, применима и к вниманию в декодере, но с некоторыми существенными отличиями.
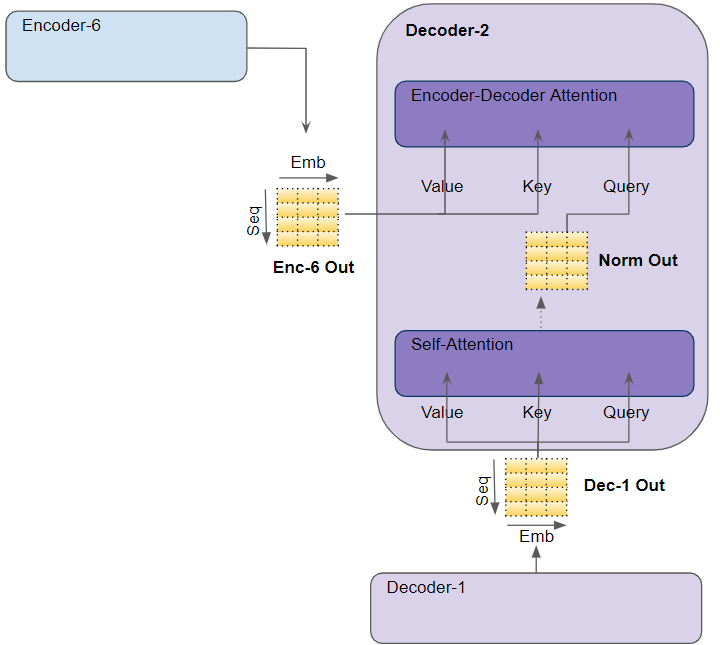 Внимание в декодере
Внимание в декодереВ декодере самовнимания мы вычисляем релевантность каждого слова в целевом предложении каждому другому слову в целевом предложении.
 Самовнимание декодера
Самовнимание декодераЭнкодер-декодер модуля внимания в трансформере
В энкодере-декодере запрос получается из целевого предложения, а ключ/значение — из исходного предложения. Таким образом, он вычисляет релевантность каждого слова в целевом предложении каждому слову в исходном предложении.
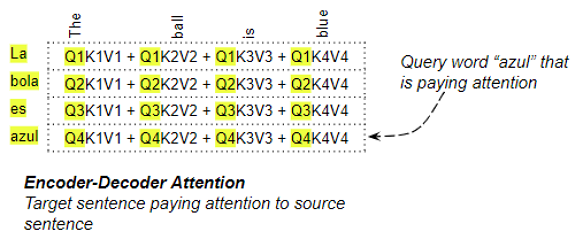 Энкодер-декодер Внимания
Энкодер-декодер ВниманияЗаключение
Надеюсь, статья дала вам хорошее представление об элегантности архитектуры трансформера. Прочтите также другие статьи о трансформере из моей серии, чтобы лучше представлять, почему сегодня трансформер — это предпочтительная архитектура многих приложений глубокого обучения.
Здесь мы видим, что за сложными идеями скрываются простые решения. Более того, есть ощутимая вероятность того, что вскоре понимание внутренних механизмов глубокого обучения станет «второй грамотностью», как сегодня второй грамотностью стало знание ПК в целом — и если вы хотите углубиться в область глубокого и машинного обучения, получить полное представление о современном ИИ, вы можете присмотреться к нашему курсу «Machine Learning и Deep Learning», партнёром которого является компания NVIDIA.

Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
Другие профессии и курсыПРОФЕССИИ
КУРСЫ
