[Перевод] Мониторинг и профилирование Spring Boot приложения
Мониторинг очень важен для современных приложений, современные приложения по своей природе сильно распределены и имеют разные зависимости, такие как база данных, службы, кеширование и многое другое. Поэтому все более важны отслеживание и мониторинг этих служб, чтобы приложение придерживалось условий SLA ( Service Level Agreement). SLA — это соглашение между клиентом и поставщиком услуг, в нем учитываются надежность, скорость отклика и другие показатели уровня обслуживания.
Мы всегда стараемся не нарушать никаких SLA, нарушение любой части SLA может иметь множество последствий. Если услуга не соответствует условиям, определенным в SLA, она можкт нанести ущерб репутации бренда и привести к потери дохода. Хуже всего то, что компания может потерять клиента в пользу конкурента из-за своей неспособности удовлетворить требования клиента к уровню обслуживания.
Какие показатели нужно отслеживать?
Доступность услуги : время, в течение которого услуга доступна для использования. Это может быть измерено с точки зрения времени отклика, например, процентиль X, сокращенно обозначаемый как pX, например, p95, p99, p99.999. Не для всех сервисов требуется p99,999, системы с гарантированной высокой доступностью, такие как электронная коммерция, поиск, оплата и т. д., должны иметь более высокое SLA.
Уровень дефектов: несмотря на все усилия по разработке системы, ни одна система не является идеальной на 100%. Мы должны подсчитывать процент ошибок в основных потоках. В эту категорию могут быть включены производственные сбои, такие как ошибка сервера, ошибка запроса базы данных, ошибка соединения, сетевые ошибки и пропущенные сроки.
Безопасность: в наши сверх регулируемые времена нарушения безопасности приложений и сети могут быть дорогостоящими. В эту категорию можно включить измерение контролируемых мер безопасности, таких как доступ к системе, несанкционированный доступ к базе данных, массовая загрузка записей базы данных или перемещение больших объемов данных.
Бизнес-результаты: ИТ-клиенты все чаще хотят включать метрики бизнес-процессов в свои SLA, чтобы можно было принимать более правильные бизнес-решения. В этой категории могут быть собраны различные данные, такие как количество пользователей, посетивших страницу, активность входа, эффективность купона и т. д.
Вначале выбор набора показателей может быть нетривиальной задачей, также мы можем столкнуться с дилеммой того, сколько показателей нам следует отслеживать. Мы можем начать с самого минимума и добавить столько, сколько понадобится позже.
Настройка мониторинга
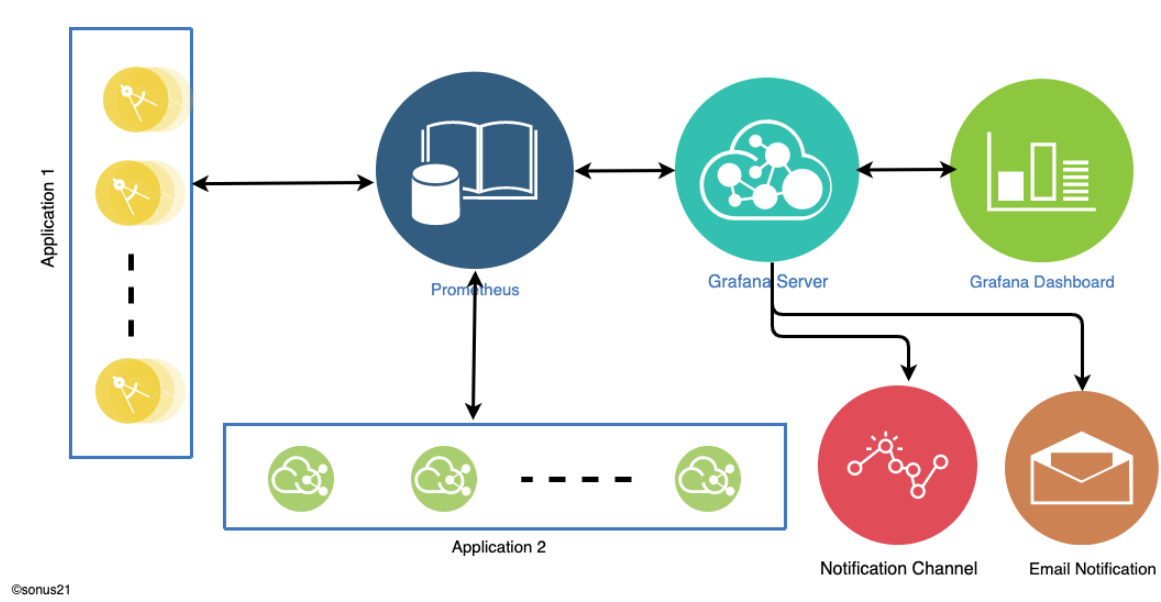
Типичная система настройки мониторинга будет состоять из трех компонентов
Хранилища метрик (как правило, база данных временных рядов), такое как InfluxDB, TimescaleDB, Prometheus и т. д.
Панель инструментов (панель будет использоваться для визуализации данных, хранящихся в хранилище метрик).
Приложения, которые будут продолжать отправлять метрики в хранилище метрик или хранилище метрик, периодически извлекают данные из локального состояния приложения.
У нас могут быть и другие компоненты, например, оповещение, где каналами оповещения могут быть электронная почта, Slack или любые другие. Компонент оповещения будет отправлять оповещения владельцам приложений или подписчикам событий. Мы собираемся использовать Grafana как панель управления и систему оповещений, Prometheus как систему хранения метрик.
Нам понадобятся:
Любая IDE
Платформа Java
Gradle
Создайте проект с помощью инициализатора Spring Boot, добавьте столько зависимостей, сколько нам нужно. Мы собираемся использовать библиотеку Micrometer, это инструментальный фасад, который обеспечивает привязки для многих хранилищ метрик, таких как Prometheus, Datadog и New Relic, и это лишь некоторые из них.
Из коробки Micrometer обеспечивает
HTTP-запрос
JVM
База данных
Метрики, относящиеся к системе кэширования и т. д.
Некоторые метрики включены по умолчанию, тогда как другие можно включить, отключить или настроить. Мы будем использовать файл application.properties для включения, отключения и настройки метрик. Нам также нужно использовать Spring boot actuator, так как он откроет доступ к конечной точке Prometheus.
Добавьте эти зависимости в файл build.gradle:
io.micrometer: micrometer-registry-prometheus
org.springframework.boot: spring-boot-starter-actuator
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
providedRuntime 'org.springframework.boot:spring-boot-starter-tomcat'
implementation 'io.micrometer:micrometer-registry-prometheus'
implementation 'org.springframework.boot:spring-boot-starter-actuator'
// https://mvnrepository.com/artifact/com.h2database/h2
compile group: 'com.h2database', name: 'h2', version: '1.4.200'
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
}Мы можем включить экспорт Prometheus, добавив следующую строку в файл свойств.
management.metrics.export.prometheus.enabled = trueПосле добавления этой строки Micrometer начнет накапливать данные о приложении, и эти данные можно будет просмотреть, перейдя на конечную точку actuator/Prometheus. Эта конечная точка будет использоваться в скрипте Prometheus для получения данных с наших серверов приложений.
Несмотря на то, что мы добавили эту строку в свойствах, мы не можем просматривать конечную точку Prometheus, поскольку она отключена по умолчанию, мы можем открыть ее, используя конечную точку управления, включив Prometheus в список.
management.endpoints.web.exposure.include=prometheusПРИМЕЧАНИЕ. Не включайте все конечные точки actuator, так как это может открыть лазейку в системе безопасности. Мы должны выбирать их выборочно, особенно в производственной системе, даже если мы хотим, не раскрывать конечную точку для всего мира, так как она может раскрыть большой объем данных о приложении, использовать какой-то прокси или какое-то правило, чтобы скрыть данные от внешнего мира.
Различные части HTTP-запросов настраиваются, например SLA, настройка признака должна быть вычислена или нет гистограмма процентилей делается с помощью свойств metrics.distribution.
В примере application.properties могут быть такие строки
# Включить экспорт prometheus
management.metrics.export.prometheus.enabled = true
# Включить конечную точку Prometheus
management.endpoints.web.exposure.include = Прометей
# включить гистограмму на основе процентилей для http запросов
management.metrics.distribution.percentiles-histogram.http.server.requests = true
# сегментов гистограммы http SLA
management.metrics.distribution.sla.http.server.requests = 100 мс, 150 мс, 250 мс, 500 мс, 1 с
# включить метрики JVM
management.metrics.enable.jvm = trueТеперь, если мы запустим приложение и перейдем на страницу http://locahost:8080/actator/prometheus, будет отображаться чертовски много данных.

Приведенные выше данные отображают детали HTTP-запроса, exception=None означает, что исключение не произошло, если оно есть, мы можем использовать это для фильтрации количества запросов, которые не удалось выполнить из-за этого исключения, method=GET имя метода HTTP. status=200 HTTP статус равен 200, uri=/actator/prometheus отображает путь URL, le=xyz отображает время обработки, N.0 отображает количество вызовов этой конечной точки.
Эти данные представляют собой гистограмму, которую можно построить в Grafana, например, чтобы построить график p95 за 5 минут, мы можем использовать следующий запрос.
histogram_quantile(0.95,sum(rate(http_server_requests_seconds_bucke[5m])) by (le))В Grafana можно построить и другие графики показателей, например круговую диаграмму и т. д.
Пользовательские показатели
Часто нам нужны специальные метрики, некоторые из сценариев использования — это количество вошедших в систему пользователей, сведения о запасах доступных, в настоящее время, количество заказов в очереди и т. д. Некоторые из бизнес сценариев использования могут быть решены с использованием пользовательских метрик, микрометра. поддерживает различные типы показателей, такие как таймер, датчик, счетчик, сводки распределения, таймеры для длительных задач и т. д. В основном мы сосредоточимся на датчике и счетчике. Датчик дает нам мгновенные данные, такие как длина очереди, тогда как счетчик похож на монотонно увеличивающееся число, начинающееся с единицы.
Для демонстрации этого мы собираемся создать пример менеджера запасов, который будет хранить детали в памяти и обеспечит две функции:
Добавить товары
Получить товары
Для этого мы создадим один счетчик и одну метрику в методе init, при каждом вызове getItems мы увеличиваем счетчик, а также измеряем размер запаса, тогда как при вызове addItems мы только обновляем метрику.
@Component
public class StockManager {
@Autowired private MeterRegistry meterRegistry;
private List orders = new Vector<>();
private Counter counter;
private Gauge gauge;
@PostConstruct
public void init() {
counter =
Counter.builder("order_created")
.description("number of orders created")
.register(meterRegistry);
gauge =
Gauge.builder("stock.size", this, StockManager::getNumberOfItems)
.description("Number of items in stocks")
.register(meterRegistry);
}
public int getNumberOfItems() {
return orders.size();
}
public void addItems(List items) {
orders.addAll(items);
// measure gauge
gauge.measure();
}
public List getItem(int count) {
List items = new ArrayList<>(count);
while (count < 0) {
try {
items.add(orders.remove(0));
} catch (ArrayIndexOutOfBoundsException e) {
break;
}
count -= 1;
}
// increase counter
counter.increment();
// measure gauge
gauge.measure();
return items;
}
} В демонстрационных целях мы добавим две конечные точки для добавления товаров и получения товаров.
@RestController
@RequestMapping(path = "stocks")
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
public class StockController {
@NonNull private StockManager stockManager;
@GetMapping
@ResponseBody
public List getItems(@RequestParam int size) {
return stockManager.getItem(size);
}
@PostMapping
@ResponseBody
public int addItems(@RequestParam List items) {
stockManager.addItems(items);
return stockManager.getNumberOfItems();
}
}
@PostMapping
@ResponseBody
public int addItems(@RequestParam List items) {
stockManager.addItems(items);
return stockManager.getNumberOfItems();
}
} Давайте сначала добавим десять товаров, используя два вызова API:
Curl -X POST http://localhost:8080/stocks? Items = 1,2,3,4
Curl -X POST http://localhost:8080/stocks? Items = 5,6,7,8,9,10
Теперь, если мы перейдем к конечным точкам Prometheus, то увидим следующие данные, которые показывают, что в настоящее время у нас есть 10 товаров на складе.
# HELP stock_size Количество товаров на складе
# TYPE stock_size gauge
stock_size 10.0Теперь мы собираемся разместить заказ на 3 товара:
http://localhost:8080/stocks? size=3
Теперь, если мы посмотрим конечную точку Prometheus, мы получим следующие данные, которые показывают, что размер запаса был изменен до семи.
# HELP stock_size Количество товаров на складе
# TYPE stock_size gauge
stock_size 7.0Кроме того, мы видим, что на счетчике добавлено значение 1, это означает, что размещен один ордер.
# HELP order_created_total количество созданных заказов
# TYPE order_created_total counter
order_created_total 1.0ordercreated_total 1.0Профилирование
В программной инженерии профилирование («профилирование программы», «профилирование программного обеспечения») — это форма динамического анализа программы, который измеряет, например, объем (память) или временную сложность программы, использование определенных инструкций или частоту и продолжительность вызовов функций.
Чаще всего профилирующая информация помогает оптимизировать программу. Профилирование достигается путем сбора характеристик работы программы, таких как время выполнения отдельных фрагментов (обычно подпрограмм), число верно предсказанных условных переходов, число кэш-промахов и т. д. Инструмент, используемый для анализа работы, называют профилировщиком или профайлером (profiler). Профилировщики могут использовать ряд различных методов, таких как методы, основанные на событиях, статистические, инструментальные методы и методы моделирования. — Википедия
Профилирование очень полезно при диагностике системных проблем, например, сколько времени занимает HTTP-вызов, если он занимает N секунд, а затем, где все это время было потрачено, каково распределение N секунд между различными запросами к базе данных, вызовами последующих служб и т. д. Мы можем использовать гистограмму для построения графика распределения на панели инструментов, также мы можем использовать счетчик для измерения количества запросов к БД и т. д. Для профилирования нам необходимо внедрить код во многие функции, которые будут выполняться как часть выполнения метода.
Важно то, что внедряемая часть кода профилирования одинакова для профилировщиков аналогичных типов, что означает, что нам нужно скопировать и вставить аналогичный код в тысячи мест, если нам нужно что-то изменить, нам нужно обновить то же самое. Код профилировщика в каждом файле и, вероятно, в каждой функции, требующей профилирования, повысит сложность и может стать создать полный беспорядок, впрочем мы можем избежать этого беспорядка, используя аспектно-ориентированное программирование (АОП).
Короче говоря, АОП работает по шаблону проектирования прокси, хотя его можно реализовать и с помощью модификации байтового кода.

Всякий раз, когда вызывается метод, мы ожидаем, что вызываемый метод будет вызываться напрямую без каких-либо промежуточных шагов, но когда AOP помещается на место, тогда вызов метода перехватывается прокси-методом, а прокси-метод вызывает целевой метод, прокси-метод возвращает результат для вызывающего абонента, как показано на рисунке ниже.

Система зависит от других систем, поэтому мы можем быть заинтересованы в профилировании различных компонентов по-разному, например, вызовов базы данных, HTTP-запросов, последующих вызовов служб или некоторых конкретных методов, которые являются критическими или хотели бы увидеть, что происходит в некоторых конкретных методах. Мы можем использовать ту же библиотеку Micrometer для профилирования, но это может быть не совсем то, что нам нужно, поэтому мы изменим код.
Micrometer поставляется с аннотацией Timed, эту аннотацию можно разместить в любом public методе, так как название предполагает, что она может измерять время выполнения, это будет измерять время выполнения соответствующего метода. Вместо того, чтобы напрямую использовать эту аннотацию, мы расширим эту аннотацию для поддержки других функций, таких как ведение журнала, повторная попытка и т. Д.
Аннотация Timed бесполезна без бина TimedAspect, поскольку мы переопределяем аннотациюTimed, поэтому мы также определим класс TimedAspect в соответствии с потребностями, такими как ведение журнала, массовое профилирование (профилируйте все методы в пакете без добавления каких-либо аннотаций к любому методу или классу), повторить попытку и т. д. В этой истории мы рассмотрим три сценария использования:
Массовое профилирование.
Логирование.
Специфический для профиля метод.
Созадим файл java MonitoringTimed.java, в который мы добавим новое поле с именем loggingEnabled, это поле будет использоваться для проверки, включено ли ведение журнала или нет, если оно включено, а затем регистрировать аргументы метода и возвращаемые значения.
@Target({ElementType.ANNOTATION_TYPE, ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface MonitoringTimed {
/** All fields are same as in {@link io.micrometer.core.annotation.Timed} */
String value() default "";
String[] extraTags() default {};
boolean longTask() default false;
double[] percentiles() default {};
boolean histogram() default false;
String description() default "";
// NEW fields starts here
boolean loggingEnabled() default false;
}Эта аннотация бесполезна без класса аспекта Timed, поэтому будет определен новый класс MonitoringTimedAspect со всеми необходимыми деталями, этот класс будет иметь метод для профилирования любого метода на основе объединенного объекта обработки и объекта MonitoringTimed, , а другой — для профилирования метода на основе в аннотации MonitoringTimed.
@Around("execution (@com.gitbub.sonus21.monitoring.aop.MonitoringTimed * *.*(..))")
public Object timedMethod(ProceedingJoinPoint pjp) throws Throwable {
Method method = ((MethodSignature) pjp.getSignature()).getMethod();
MonitoringTimed timed = method.getAnnotation(MonitoringTimed.class);
if (timed == null) {
method = pjp.getTarget().getClass().getMethod(method.getName(), method.getParameterTypes());
timed = method.getAnnotation(MonitoringTimed.class);
}
final String metricName = generateMetricName(pjp, timed);
return timeThisMethod(pjp, timed, metricName);
}
public Object timeThisMethod(ProceedingJoinPoint pjp, MonitoringTimed timed) throws Throwable {
final String metricName = generateMetricName(pjp, timed);
return timeThisMethod(pjp, timed, metricName);
}Метод TimedMethod с аннотацией Around используется для фильтрации всех вызовов методов, аннотированных с помощью MonitoringTimed.
Для массового профилирования мы определим класс профилировщика, который будет работать с фильтрацией на уровне пакета. Например, для профилирования HTTP-запроса мы можем добавить ControllerProfiler, который будет обрабатывать профилирование всех общедоступных методов, доступных в пакете контроллера.
@Aspect
@Component
public class ControllerProfiler {
private static Map timedAnnotationData = new HashMap<>();
static {
// use percentile data of p90, p95, p99.99
double[] percentiles = {0.90, 0.95, 0.9999};
// set histogram to true
timedAnnotationData.put("histogram", true);
// set percentile
timedAnnotationData.put("percentiles", percentiles);
}
@Autowired private MonitoringTimedAspect timedAspect;
private static final MonitoringTimed timed = Javanna.createAnnotation(MonitoringTimed.class, timedAnnotationData);
private static final Logger logger = LoggerFactory.getLogger(ControllerProfiler.class);
@Pointcut("execution(* com.gitbub.sonus21.monitoring.controller..*.*(..))")
public void controller() {}
@Around("controller()")
public Object profile(ProceedingJoinPoint pjp) throws Throwable {
// here add other logic like error happen then log parameters etc
return timedAspect.timeThisMethod(pjp, timed);
}
} Интересной строкой в приведенном выше коде является @Pointcut («execution (com.gitbub.sonus21.monitoring.controller….*(…))»), котораяопределяет pointcut, выражение pointcut может быть определено с использованием логических операторов вроде not (!), or (||), and (&&). После того, как метод квалифицирован согласно выражению pointcut, он может вызвать соответствующий метод, определенный с помощью аннотации [at]Around. Поскольку мы определили метод profile, который будет вызываться, мы также можем определить другие методы, используя аннотации [at]After, [at]Before и т. д.
После добавления нескольких элементов с помощью метода POST мы можем увидеть следующие данные в конечной точке Prometheus.
method_timed_seconds {class = "com.gitbub.sonus21.monitoring.controller.StockController", exception = "none", method = "addItems", quantile = "0.9",} 0.0
method_timed_seconds_bucket {class = "com.gitbub.sonus21.monitoring.controller.StockController", exception = "none", method = "addItems", le = "0.001",} 3.0
method_timed_seconds_bucket {class = "com.gitbub.sonus21.monitoring.controller.StockController", exception = "none", method = "addItems", le = "0.002446676",} 3.0Мы можем напрямую использовать аннотацию MonitoringTimed также для любого метода для измерения времени выполнения, например, давайте измерим, сколько времени StockManager метод addItems тратит на добавление элементов.
@MonitoringTimed
public void addItems(List items) {
orders.addAll(items);
// measure gauge
gauge.measure();
} Как только мы запустим приложение и добавим несколько элементов, мы увидим следующее в конечной точке Prometheus.
method_timed_seconds_count{class="com.gitbub.sonus21.monitoring.service.StockManager",exception="none",method="addItems",} 4.0
method_timed_seconds_sum{class="com.gitbub.sonus21.monitoring.service.StockManager",exception="none",method="addItems",} 0.005457965
method_timed_seconds_max{class="com.gitbub.sonus21.monitoring.service.StockManager",exception="none",method="addItems",} 0.00615316MonitoringTimed можно дополнительно настроить, например, можно добавить количество повторных попыток для поддержки повторных попыток в случае сбоя, записать аргументы функции в случае сбоя, чтобы позже можно было проанализировать причину сбоя.
Полный код доступен на GitHub.
Дополнительное чтение
Magic With the Spring Boot Actuator
Spring Boot Actuator in Spring Boot 2.0
Spring Boot Admin Client Configuration Using Basic HTTP Authentication
