[Перевод] Мониторим ресурсы кластеров Kubernetes
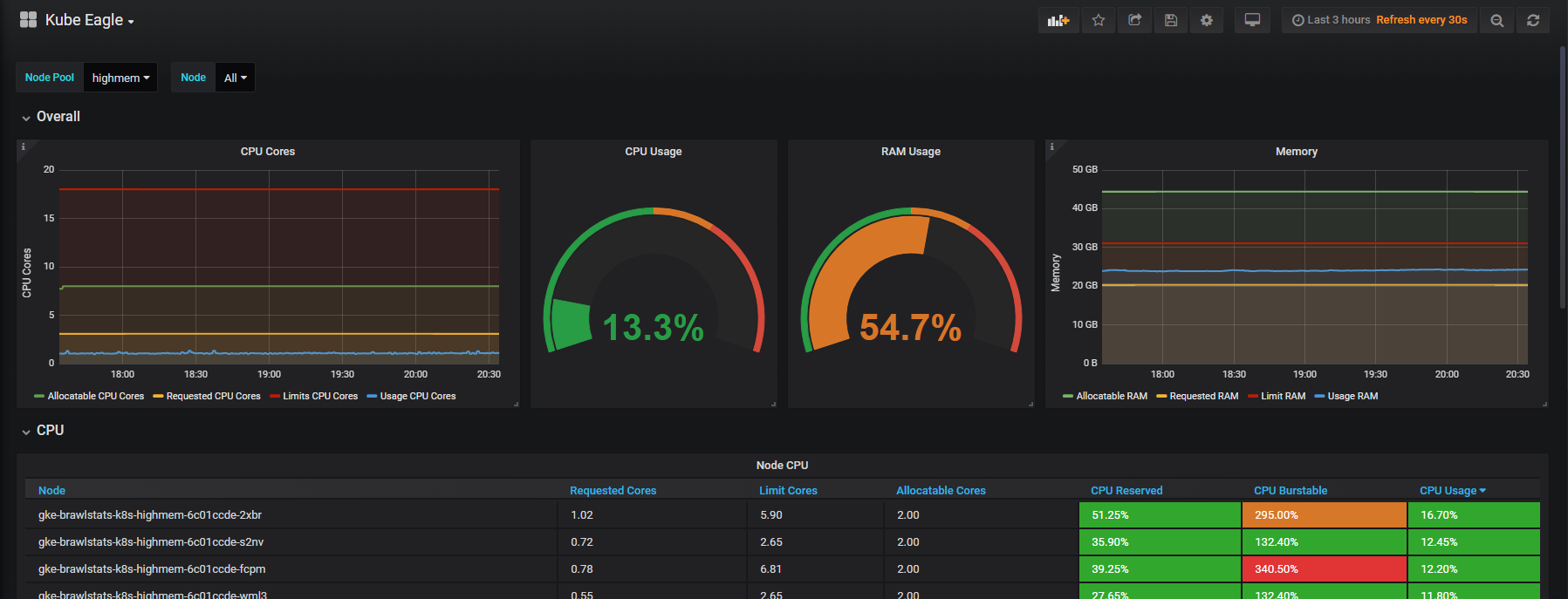
Я создал Kube Eagle — экспортер Prometheus. Оказалось, крутая штука, которая помогает лучше разбираться в ресурсах маленьких и средних кластеров. В итоге я сэкономил не одну сотню долларов, потому что подбирал правильные типы машин и настраивал ограничения ресурсов приложений под рабочие нагрузки.
Я расскажу о преимуществах Kube Eagle, но сначала объясню, из-за чего вышел сыр-бор и для чего понадобился качественный мониторинг.
https://github.com/google-cloud-tools/kube-eagle
Я управлял несколькими кластерами по 4–50 нод. В каждом кластере — до 200 микросервисов и приложений. Чтобы эффективнее использовать имеющееся железо, большинство деплоев были настроены с burstable- оперативной памятью и ресурсами ЦП. Так поды могут брать доступные ресурсы, если надо, и при этом не мешают другим приложениям на этой ноде. Ну, разве не здорово?
И хотя кластер потреблял относительно мало ЦП (8%) и оперативки (40%), у нас постоянно возникали проблемы с вытеснением подов, когда они пытались выделить больше памяти, чем доступно на ноде. Тогда у нас была всего одна панель для мониторинга ресурсов Kubernetes. Вот такая:
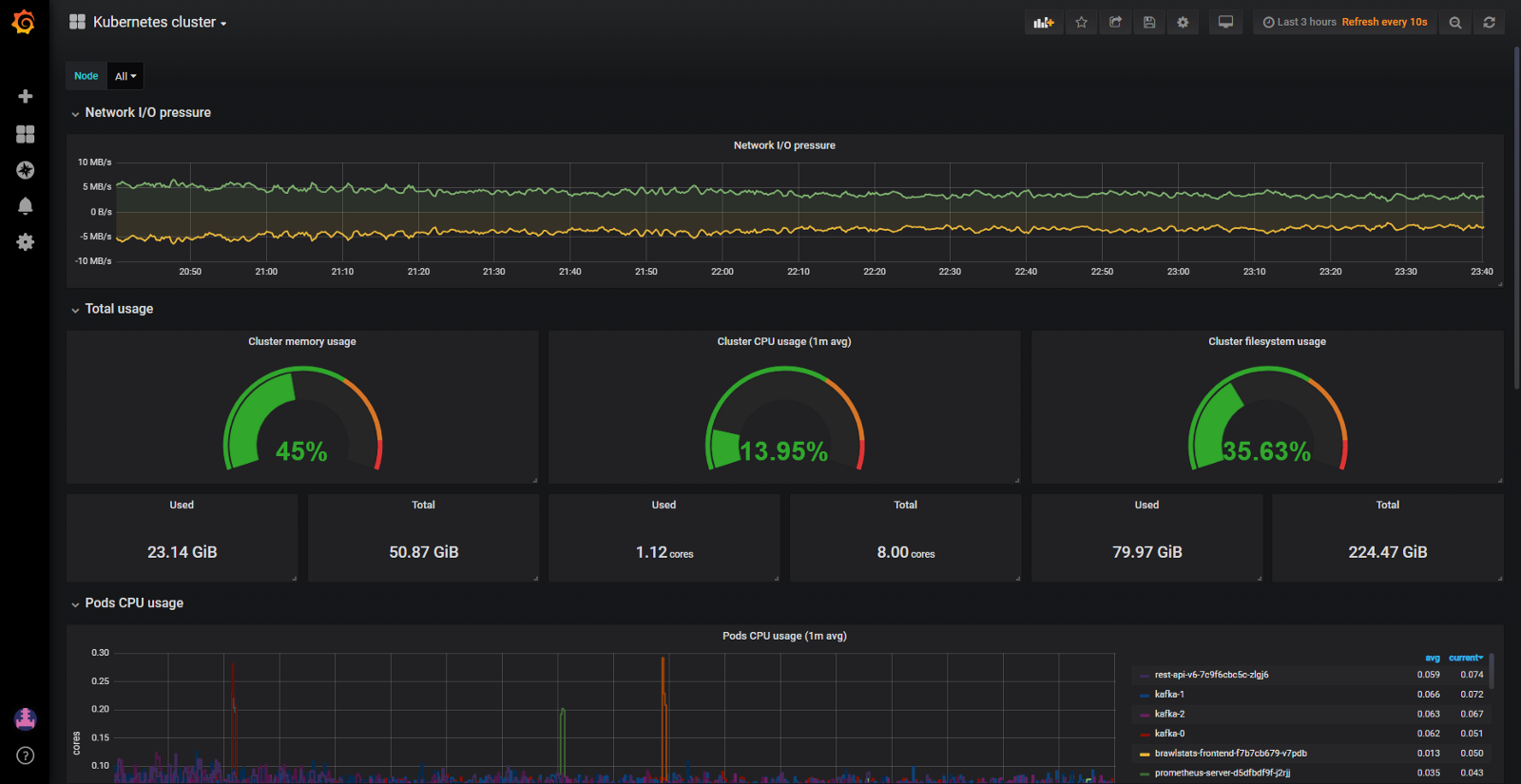
Панель Grafana только с метриками cAdvisor
С такой панелью ноды, которые едят много памяти и ЦП, увидеть не проблема. Проблема — разобраться, в чем причина. Чтобы поды оставались на месте, можно было, конечно, настроить гарантированные ресурсы на всех подах (запрошенные ресурсы равны лимиту). Но это не самое умное использование железа. На кластере было несколько сотен гигов памяти, при этом некоторые ноды голодали, а у других оставалось в запасе по 4–10 ГБ.
Получается, планировщик Kubernetes распределял рабочие нагрузки по доступным ресурсам неравномерно. Планировщик Kubernetes учитывает разные конфигурации: правила affinity, taints и tolerations, селекторы нод, которые могут ограничивать доступные ноды. Но в моем случае ничего такого не было, и поды планировались в зависимости от запрошенных ресурсов на каждой ноде.
Для пода выбиралась нода, у которой больше всего свободных ресурсов и которая удовлетворяет условиям запроса. У нас получалось, что запрошенные ресурсы на нодах не совпадают с фактическим использованием, и здесь на помощь пришел Kube Eagle и его возможности мониторинга ресурсов.
У меня почти все кластеры Kubernetes отслеживались только с Node exporter и Kube State Metrics. Node Exporter дает статистику по вводу-выводу и использованию диска, ЦП и оперативной памяти, а Kube State Metrics показывает метрики объектов Kubernetes, например, запросы и лимиты на ресурсы ЦП и памяти.
Нам нужно объединить метрики об использовании с метриками запросов и лимитов в Grafana, и тогда получим всю информацию о проблеме. Звучит просто, но на деле в этих двух инструментах метки называются по-разному, а у некоторых метрик вообще нет меток метаданных. Kube Eagle все делает сам и панель выглядит вот так:
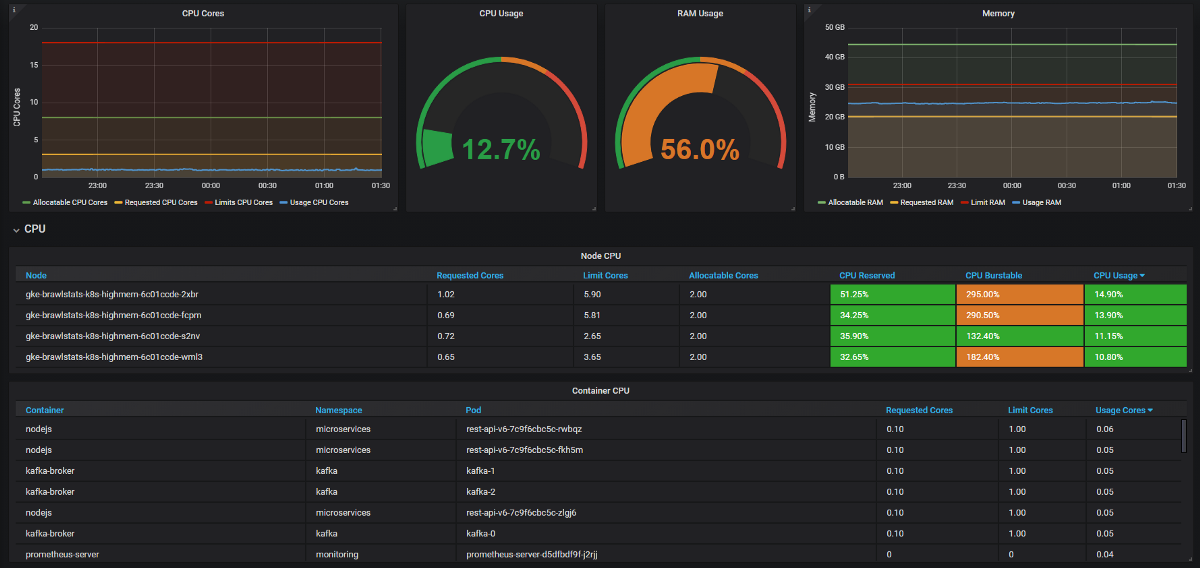
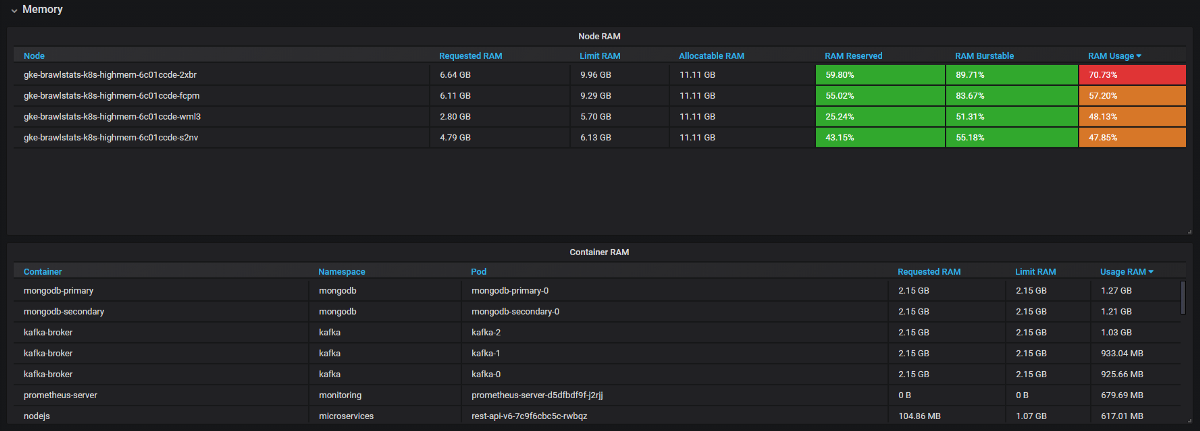
Панель мониторинга Kube Eagle (https://grafana.com/dashboards/9871)
У нас получилось решить много проблем с ресурсами и сберечь оборудование:
- Некоторые разработчики не знали, сколько ресурсов нужно микросервисам (или просто не заморачивались). Нам нечем было находить неправильные запросы на ресурсы — для этого нужно знать потребление плюс запросы и лимиты. Теперь они видят метрики Prometheus, мониторят фактическое использование и подстраивают запросы и лимиты.
- JVM-приложения берут столько оперативной памяти, сколько унесут. Сборщик мусора освобождает память, только если задействовано больше 75%. А раз у большинства сервисов память burstable, ее всегда занимал JVM. Поэтому все эти Java-сервисы съедали гораздо больше оперативной памяти, чем ожидалось.
- Некоторые приложения запрашивали слишком много памяти, и планировщик Kubernetes не давал эти ноды остальным приложениям, хоть по факту они были свободнее других нод. Один разработчик случайно добавил лишнюю цифру в запросе и захватил большой кусок оперативной памяти: 20 ГБ вместо 2. Никто и не заметил. У приложения было 3 реплики, так что пострадало аж 3 ноды.
- Мы ввели ограничения на ресурсы, перепланировали поды с правильными запросами и получили идеальный баланс использования железа по всем нодам. Пару нод вообще можно было закрыть. А потом мы увидели, что у нас неправильные машины (ориентированные на ЦП, а не на память). Мы сменили тип и удалили еще несколько нод.
Итоги
С burstable ресурсами в кластере вы эффективнее используете имеющееся железо, зато планировщик Kubernetes планирует поды по запросам на ресурсы, а это чревато. Чтобы убить двух зайцев: и проблем избежать, и ресурсы использовать по полной, — нужен хороший мониторинг. Для этого и пригодится Kube Eagle (экспортер Prometheus и панель мониторинга Grafana).
https://github.com/google-cloud-tools/kube-eagle
