[Перевод] Модифицируем Python за 6 минут
Всем доброго и неумолимо наступающего!
Этот крайне насыщенный год подходит к своему завершению и у нас остался последний курс, который мы запускаем в этом году — «Разработчик full-stack на Python», чему, собственно, и посвящаем заметку, которая хоть и проскочила мимо основной программы, но показалась небезынтересной в целом.
Поехали
На этой неделе я сделал мой первый pull-request в основной проект CPython. Его отклонили :-(Но чтобы не тратить полностью свое время, я поделюсь своими выводами о том, как работает CPython и покажу вам как легко изменить синтаксис Python.
Я собираюсь показать вам как добавить новую фичу в синтаксис Python. Эта фича — оператор инкремента/декремента, стандартный оператор для большинства языков. Чтобы убедиться — откройте REPL и попробуйте:
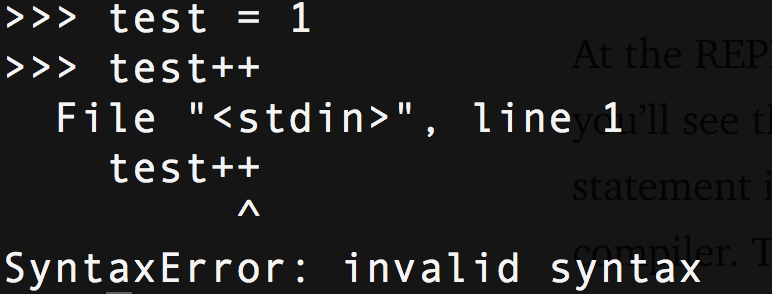
Уровень 1: PEP
Изменению синтаксиса Python предшествует заявка с описанием причин, дизайна и поведения вносимых изменений. Все изменения языка обсуждаются основной командой Python и одобряются BDFL. Операторы инкремента не утверждены (и, вероятно, никогда не будут), что даёт нам хорошую возможность потренироваться.
Уровень 2: Грамматика
Файл Grammar — это простой текстовый файл, описывающий все элементы языка Python. Его использует не только CPython, но и другие реализации, такие как PyPy, чтобы сохранить последовательность и согласовать типы языковой семантики.
Внутри эти ключи образуют токены, которые разбираются лексером. Когда вы вводите make -j, команда преобразует их в набор перечислений и констант в C-хедерах. Это позволяет ссылаться на них в дальнейшем.
stmt: simple_stmt | compound_stmt
simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE
# ...
pass_stmt: 'pass'
flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt
break_stmt: 'break'
continue_stmt: 'continue'
# ..
import_as_name: NAME ['as' NAME]
Таким образом, simple_stmt — это простое выражение, оно может иметь точку с запятой или не иметь, например, когда вы вводите import pdb; pdb.set_trace(), и заканчиваться в новой строке NEWLINE. Pass_stmt — пропуск слова, break_stmt — прерывание работы. Просто, не так ли?
Давайте добавим выражения инкремента и декремента: то, чего не существует в языке. Это был бы еще один вариант структуры выражения, наряду с операторами yield, расширенным и стандартным присвоением, т.е. foo=1.
# Добавляем выражения инкремента и декремента
expr_stmt: testlist_star_expr (annassign | augassign (yield_expr|testlist) |
('=' (yield_expr|testlist_star_expr))* | incr_stmt | decr_stmt)
annassign: ':' test ['=' test]
testlist_star_expr: (test|star_expr) (',' (test|star_expr))* [',']
augassign: ('+=' | '-=' | '*=' | '@=' | '/=' | '%=' | '&=' | '|=' | '^=' |
'<<=' | '>>=' | '**=' | '//=')
# Для нормальных и аннотированных присвоений, дополнительных ограничений навязываемых интерпретатором
del_stmt: 'del' exprlist
# Новые выражения
incr_stmt: '++'
decr_stmt: '--'Мы добавляем его в список возможных малых выражений (это станет очевидным в AST). Incr_stmt будет нашим методом инкремента и decr_stmt будет декрементом. Оба следуют за NAME (имя переменной) и образуют малое автономное выражение. Когда мы соберем проект Python, он сгенерирует компоненты для нас (не сейчас).
Если вы запустите Python с опцией -d и попробуете это, вы должны получить:
Token /’++’ … Illegal token
Что такое токен? Давайте выясним…
Уровень 3: Лексер
Есть четыре шага, которые делает Python, когда вы вызываете return: лексический анализ, синтаксический анализ, компиляция и интерпретация. Лексический анализ разбивает строку кода, которую вы только что ввели, на токены. Лексер CPython называется tokenizer.c. Он имеет функции, которые читают из файла (например, python file.py) строку (например, REPL). Он также обрабатывает специальный комментарий для кодировки в верхней части файлов и анализирует ваш файл как UTF-8 и т. д. Он обрабатывает вложенность, ключевые слова async и yield, обнаруживает наборы и кортежи присвоений, но только грамматически. Он не знает, что это за вещи или что с ними делать. Его волнует только текст.
Например, код, который позволяет использовать o-нотацию для восьмеричных значений, находится в токенизаторе. Код, который на самом деле создает восьмеричные значения, находится в компиляторе.
Давайте добавим две вещи в Parser/tokenizer.c: новые токены INCREMENT и DECREMENT, — это ключи, которые возвращаются токенизатором для каждой части кода.
/* Имена токенов */
const char *_PyParser_TokenNames[] = {
"ENDMARKER",
"NAME",
"NUMBER",
...
"INCREMENT",
"DECREMENT",
...
Затем мы добавляем проверку, чтобы вернуть токен INCREMENT или DECREMENT, каждый раз, когда видим ++ или --. Уже существует функция для двухсимвольных операторов, поэтому мы расширяем ее в соответствии с нашим случаем.
@@ -1175,11 +1177,13 @@ PyToken_TwoChars(int c1, int c2)
break;
case '+':
switch (c2) {
+ case '+': return INCREMENT;
case '=': return PLUSEQUAL;
}
break;
case '-':
switch (c2) {
+ case '-': return DECREMENT;
case '=': return MINEQUAL;
case '>': return RARROW;
}Они определены в token.h
#define INCREMENT 58
#define DECREMENT 59Теперь, когда мы запускаем Python с -d и пытаемся выполнить наш оператор, мы видим:

It’s a token we know - Успех!Уровень 4: Парсер
Парсер принимает эти токены и генерирует структуру, которая показывает их взаимосвязь друг с другом. Для Python и многих других языков это абстрактное синтаксическое дерево (или AST). Затем компилятор принимает AST и превращает его в один (или более) объект кода. Наконец, интерпретатор принимает каждый объект кода, который выполняет код, представляемый им.
Представьте свой код в виде дерева. Верхний уровень — это корень, функция может быть веткой, класс — тоже ветка и методы класса ответвляются от нее. Выражения — это листья на ветке.
AST определяется в ast.py и ast.c. ast.c — это файл, который нам нужно изменить. Код AST разбит на методы, которые обрабатывают типы токенов, ast_for_stmt обрабатывает операторы, ast_for_expr обрабатывает выражения. Мы помещаем incr_stmt и decr_stmt как возможные выражения. Они почти идентичны расширенным выражениям, например, test += 1, но нет правого выражения (1), оно неявно.
Это код, который нам нужно добавить для инкремента и декремента.
static stmt_ty
ast_for_expr_stmt(struct compiling *c, const node *n)
{
...
else if ((TYPE(CHILD(n, 1)) == incr_stmt) || (TYPE(CHILD(n, 1)) == decr_stmt)) {
expr_ty expr1, expr2;
node *ch = CHILD(n, 0);
operator_ty operator;
switch (TYPE(CHILD(n, 1))){
case incr_stmt:
operator = Add;
break;
case decr_stmt:
operator = Subtract;
break;
}
expr1 = ast_for_testlist(c, ch);
if (!expr1) {
return NULL;
}
switch (expr1->kind) {
case Name_kind:
if (forbidden_name(c, expr1->v.Name.id, n, 0)) {
return NULL;
}
expr1->v.Name.ctx = Store;
break;
default:
ast_error(c, ch,
"illegal target for increment/decrement");
return NULL;
}
// Создаем PyObject для числа 1
PyObject *pynum = parsenumber(c, "1");
if (PyArena_AddPyObject(c->c_arena, pynum) < 0) {
Py_DECREF(pynum);
return NULL;
}
// Создаем это как выражение в той же строке и смещении как ++/--
expr2 = Num(pynum, LINENO(n), n->n_col_offset, c->c_arena);
return AugAssign(expr1, operator, expr2, LINENO(n), n->n_col_offset, c->c_arena);Это возвращает расширенное присваивание — вместо нового типа выражения с постоянным значением 1. Оператором является либо Add, либо Sub (tract) в зависимости от типа токена incr_stmt или decr_stmt. Возвращаясь к Python REPL после компиляции, мы можем увидеть наш новый оператор!
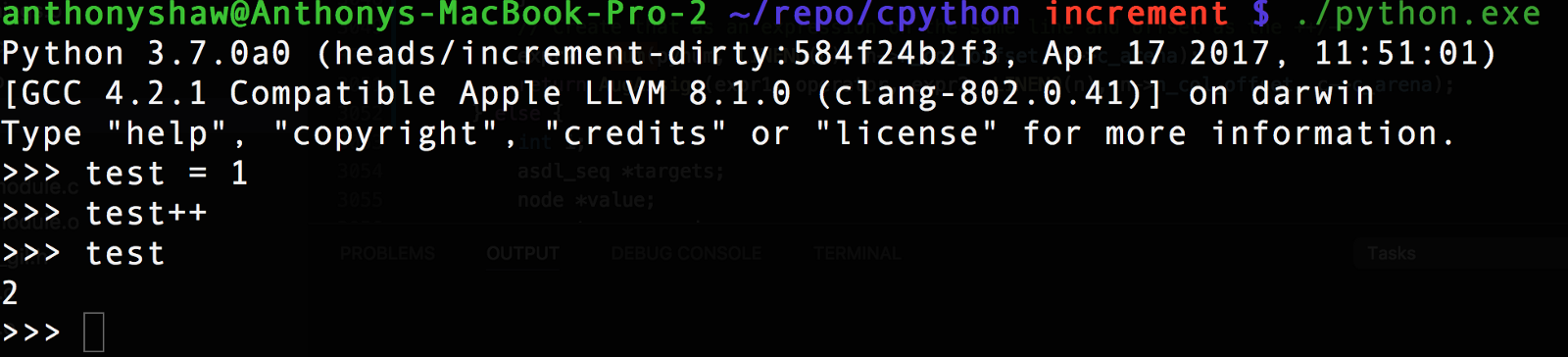
В REPL вы можете попробовать ast.parse ("test=1; test++).body[1], и вы увидите возвращаемый тип AugAssign. AST только что преобразовал оператор в выражение, которое может быть обработано компилятором. Функция AugAssign устанавливает поле Kind, которое используется компилятором.
Уровень 5: Компилятор
Затем компилятор берет дерево синтаксиса и «посещает» каждую ветвь. У компилятора CPython есть метод для посещения оператора, который называется compile_visit_stmt. Это просто большой оператор switch, определяющий вид оператора. У нас был тип AugAssign, поэтому он обращается к compiler_augassign для обработки деталей. Затем эта функция преобразует наше утверждение в набор байт-кодов. Это промежуточный язык между машинным кодом (01010101) и деревом синтаксиса. Последовательность байтового кода — это то, что кэшируется в .pyc-файлах.
static int
compiler_augassign(struct compiler *c, stmt_ty s)
{
expr_ty e = s->v.AugAssign.target;
expr_ty auge;
assert(s->kind == AugAssign_kind);
switch (e->kind) {
...
case Name_kind:
if (!compiler_nameop(c, e->v.Name.id, Load))
return 0;
VISIT(c, expr, s->v.AugAssign.value);
ADDOP(c, inplace_binop(c, s->v.AugAssign.op));
return compiler_nameop(c, e->v.Name.id, Store);Результатом будет VISIT (значение нагрузки — для нас 1), ADDOP (добавить операцию двоичного операционного кода в зависимости от оператора (вычесть, добавить)) и STORE_NAME (сохранить результат ADDOP для имени). Эти методы отвечают более конкретными байт-кодами.
Если вы загрузите модуль dis, вы сможете увидеть байт-код:

Уровень 6: Интерпретатор
Финальным уровнем является интерпретатор. Он берет последовательность байт-кодов и преобразует ее в машинные операции. Вот почему Python.exe и Python для Mac и Linux — все отдельные исполняемые файлы. Некоторым байт-кодам нужна конкретная обработка и проверка ОС. API-интерфейс потоковой обработки, например, должен работать с API-интерфейсом GNU/Linux, который очень отличается от потоков Windows.
Вот и все!Для дальнейшего чтения
Если вас интересуют интерпретаторы, я рассказал о Pyjion, архитектуре плагина для CPython, которая стала PEP523
Если вы все еще хотите поиграть, я запушил код на GitHub вместе с моими изменениями в токенизаторе ожидания.
THE END
Как всегда ждём вопросы, комментарии, замечания.
