[Перевод] Мифы об асинхронном PHP: он не по-настоящему асинхронный
В последнее время появляется достаточно много обсуждений проблемы производительности в PHP. И даже несмотря на то, что у нас есть PHP8, JIT и куча других улучшений, многие по-прежнему продолжают жаловаться на то, что PHP «недостаточно производительный». Что PHP — это язык, подходящий только для модели запрос-ответ. Что PHP слишком медленный и его не нужно использовать для высоконагруженных систем. С одной стороны от части всё это правда. Если мы строим какую-то систему, для которой вопрос производительности критичен, то использовать классический блокирующий PHP явно не стОит. Большая часть функций и библиотек PHP созданы для работы в традиционном блокирующем окружении, что уже подразумевает собой не самую высокую производительность. Однако PHP может работать быстро, более того, он может работать очень быстро. Как? Обычно у нас может быть две причины, из-за чего будет проседать производительность: мы либо совершаем какие-то сложные вычисления, либо у нас есть блокирующй ввод-вывод. Первое к сожалению (или к счастью) мы не можем решить в PHP. Но блокирующий ввод-вывод для PHP совсем не проблема. В PHP-сообществе есть люди, которые пишут асинхронный код уже на протяжении несколько лет. Конечно одновременно с этим бОльшая часть сообщества по-прежнему считает асинхронный PHP — дикостью. Я часто слышал: «Ты наверно совсем отчаянный, если собираешься писать что-то асинхронное на PHP». По правде говоря, у нас у всех есть это предубеждение, что PHP не подходит для подобного рода задач. И в большинстве случаев это предубеждение основано на неверных представлениях о самой «асинхронности». Неверные предубеждения в свою очередь ведут к неправильным ожиданиям, что в свою очередь приводит к разочарованию и обвинениям в том, что PHP «не по-настоящему асинхронный».
В этой статье я хочу обсудить некоторые базовые вещи про асинхронность и в итоге понять, действительно ли однопоточный PHP может выполняться асинхронно или нас всех обманывают.

Конкурентность и параллелизм
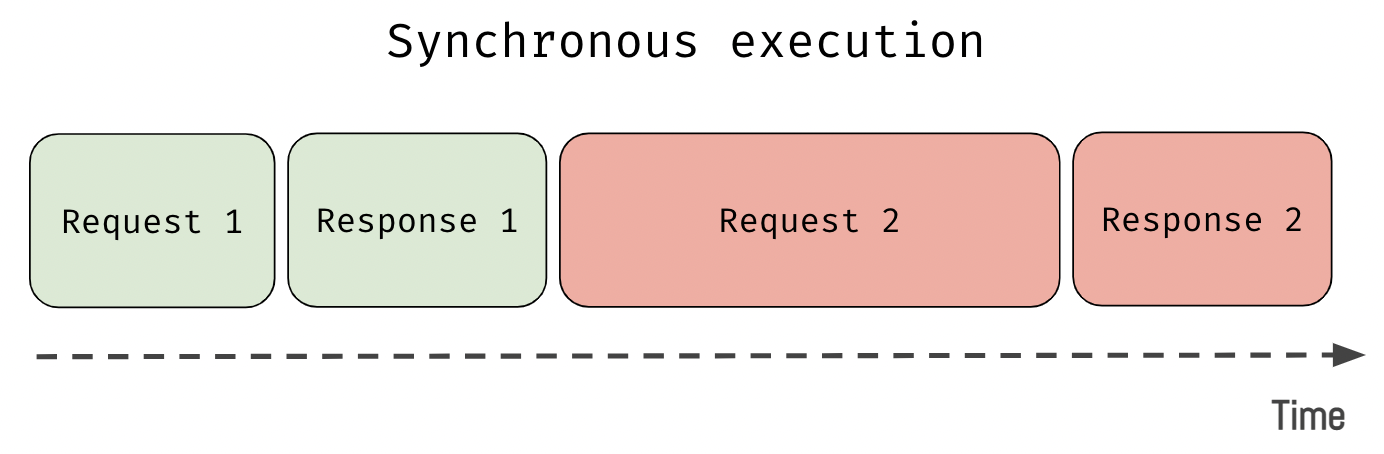
Для начала нам нужно понять вообще разницу между синхронным и асинхронным выполнением. Быстро разберём эту деталь, и затем перейдём к уже более сложным вопросам. Представим программу, которая выполняет два сетевых запроса. При традиционном синхронном подходе код будет выполняться последовательно:
Отправляем первый запрос.
Ждём ответа.
Отправляем второй запрос.
Ждём ответа.
Здесь каждая операция блокирует поток выполнения. В большинстве случаев для PHP это нормально. Проблемы могут возникнуть только тогда, когда таких блокирующих вызовов много, а производительность для этой программы критична. Такая программа не будет использовать все доступные ей ресурсы, и бОльшую часть времени будет простаивать. Пока выполняются сетевые запросы, CPU ничем не занят. И наоборот, когда CPU вычисляет что-то сложное вся программа «замирает» и не отвечает на ввод.
Асинхронный подход предлагает решение этой проблемы: можно начать выполнение сразу нескольких задач, и при этом не нужно дожидаться окончания одной задачи, чтобы начать другую. При асинхронном выполнении мы только лишь стартуем какую-либо операцию. В примере с сетевыми запросами можно выполнить их конкурентно и при этом будет казаться, что они выполняются параллельно (на самом деле нет).
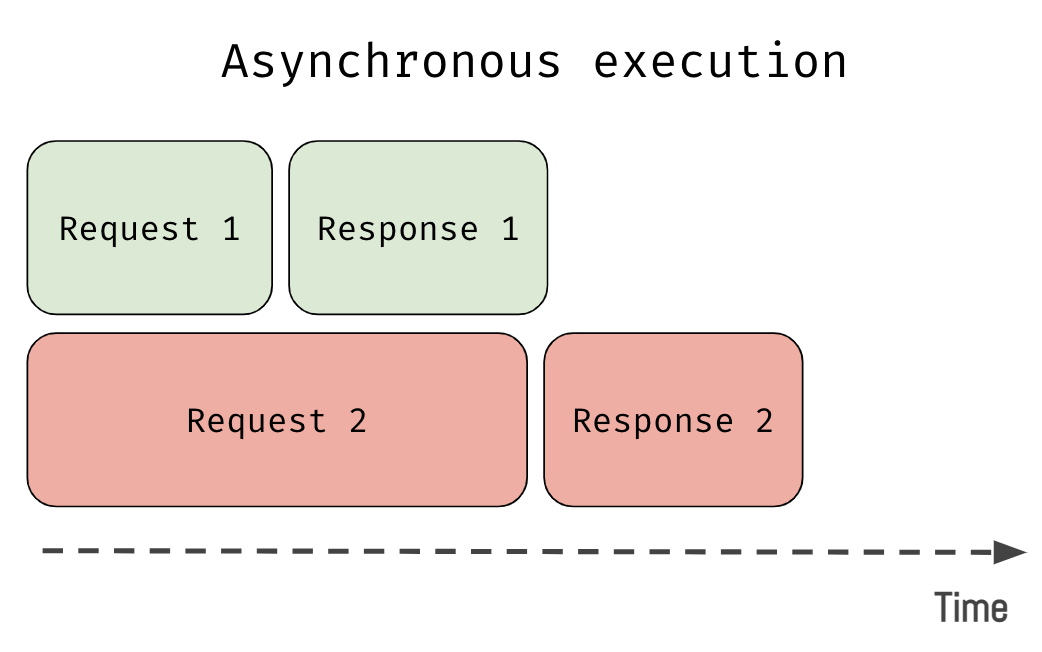
Основная причина всех споров вокруг асинхронного PHP — это непонимание того, что значит конкурентность. Очень часто мы путаем асинхронное выполнение с параллельным. Я много раз слышал довод: «PHP не по-настоящему асинхронный потому что в нём нельзя выполнять несколько задач параллельно». Здесь важно понять, что «асинхронность» — это гораздо более широкое понятие, чем «параллелизм».
При конкурентном выполнении у нас две задачи могут запускаться, выполняться и завершаться в перекрывающиеся периоды времени. Это не означает, что обе они будут выполняться одновременно в один момент времени. Хорошей аналогией здесь может быть ваш компьютер. Когда у нас выполняются две программы на одноядерном CPU, то нет никакой возможности выполнять их параллельно. Им всё равно придётся как-то делить время CPU. Таким образом операционная система решает что нужно сначала запустить одну программу, затем другую. Или операционная система может сначала выполнить небольшую часть одной программы, а затем также небольшую часть другой. Вторая программа может начать выполняться раньше, чем выполнится первая.
Напротив, параллелизм — это когда две задачи выполняются буквально одновременно. Можно продолжить пример с компьютером и здесь представить многопоточную программу, которая выполняется на многоядерном процессоре. Параллельное выполнение требует соответствующего железа, которое способно выполнять сразу несколько задач одновременно. На одноядерном процессоре мы можем получить только конкурентное выполнение задач, но никак не параллельное. Параллелизм можно рассматривать как особый случай конкурентности, при котором задачи действительно выполняются одновременно.

Из всего этого можно сделать выводы, что приложение может выполняться конкурентно, но не параллельно. Это будет означать, что приложение выполняет сразу несколько задач, но никакие две задачи не выполняются одновременно.
Хорошо, надеюсь что теперь разница между конкурентность и параллелизмом более-менее понятна. Но вернёмся к PHP, который является однопоточным языком программирования. Это означает, что в один момент времени может выполняться только одна строчка PHP кода. Является ли это ограничением, которое не позволит выполнять асинхронные задачи на PHP? Или для этого нам и не нужно иметь несколько потоков? Чтобы ответить на эти вопросы, нужно снов немного погрузиться в теорию и понять разницу между процессами и потоками.
Процессы и потоки
Программисты пишут исходный код, который впоследствии будет выполнен компьютером. Неважно на каком языке мы пишем свою программу: C, Lisp или PHP. В конце концов, наш код компилируется или интерпретируется в двоичный файл. Во время выполнения этого бинарного кода программе нужно получить от операционной системе некоторые ресурсы: адресное пространство в памяти, PID (идентификатор процесса) и другие. Может быть запущено несколько инстансов одной программы, каждый при этом будет отдельным процессом внутри операционной системы. Переключение между процессами требует некоторого времени на сохранение/загрузку состояния регистров CPU и памяти. Все процессы изолированы друг от друга. Каждый процесс считает себя единственным запущенным в операционной системе, и что больше никаких программ нет. Часто можно увидеть ситуацию, когда одна программа «зависает», но при этом из неё можно выйти, не оказывая влияния на другие запущенные программы.
Итак, процесс запускает, получает свою собственную память и остальные ресурсы. Все потоки внутри этого процесса делят эту память и ресурсы. У каждого процесса есть как минимум один основной поток выполнения. После того как этот поток заканчивает выполнение, сам процесс и программа завершаются. Процесс можно рассматривать как контейнер с бинарным кодом, памятью и другими ресурсами операционной системы.

Однопоточная конкурентность
Когда у нас есть несколько потоков внутри одного процесса, то можно сразу обрабатывать несколько задач одновременно. Более того, в большинстве случаев мы имеем системы с несколькими процессорами или многоядерными процессорами. Это позволяет реализовать конкурентность в наших программах.
Но, так же важно понимать, что конкурентное выполнение не означает многопоточность. Во многих случаях (на самом деле — в большинстве случаев) однопоточный параллелизм — неплохое решение. Со всеми своими преимуществами потоков, многопоточные программы могут стать (и обязательно станут) неподдерживаемыми монстрами из кучи потоков. Да конечно, коммуникация между потоками достаточно быстрая и дешевая, но при этом нужно помнить, что проблема в одном потоке внутри процесса, может задеть все остальные потоки да и сам процесс (скажем привет синхронизации и дедлокам).
Производительность приложения зависит от того, насколько оптимально оно использует доступные ему ресурсы (CPU, память и другие). Некоторые операции в нашей программе могут потребовать значительного времени для завершения и в это время хотелось бы иметь возможность делать что-то ещё, а не просто ждать. Вот тут то нам и пригодится конкурентность. Давайте рассмотрим две основные причины, почему операции могут долго выполняться:
CPU-bound операции, которые требуют тяжелых вычислений. Они требуют процессорного времени.
I/O-bound операции, которые зависят от сети/оборудования/взаимодействия с пользователем. Они требуют просто времени: нужно дождаться определенного события.
При выполнении CPU-bound задачи поток выполнения блокируется из-за того, что он слишком активно используется. Например, когда нам нужно сделать какие-то сложные вычисления или отрендерить 3д модель. Для таких операций лучше всего подходит многопоточность. На многопроцессорных системах несколько потоков на самом деле могут параллельно проводить какие-то вычисления. Таким образом достигается более высокая общая производительность.
С другой стороны при выполнении I/O-bound операции поток выполнения блокируется потому что ему приходится ждать данные из источника ввода/вывода (сеть, жесткий диск и др.). Когда операционная система видит, что сейчас для этого потока нет никаких данных, то он переводится в «спящий режим». В таком состоянии поток не выполняется, он просто ждёт. И в данной ситуации многопоточность нам ничем не поможет. Ну создадим мы много потоков, которые будут ждать выполнения некоторого события. От этого само событие быстрее не произойдет.
А теперь поговори и PHP. В большинстве случаев это язык для веб-приложений, где у нас очень много разного I/O: ходим в файловую систему, делаем сетевые запросы или обрабатываем команды в терминале. Исходя из этого однопоточный PHP не так уж и плох для реализации конкурентности, и что однопоточность в этом случае — не ограничение, а наоборот возможность.
Неблокирующий I/O
Сам по себе один поток выполнения конечно не делает PHP программу асинхронной. Более того, когда мы говорим про I/O в PHP, то сразу бросается в глаза, что PHP создавался с намерением всегда выполняться синхронно и быть блокирующим. Все нативные функции для работы с I/O в PHP блокируют поток выполнения.
Читаем файл с помощью
fopen()? Приложение будет заблокировано.Делаем запрос в базу с PDO? Приложение заблокировано.
Читаем что-то с
file_get_contents()? Я думаю, что ответ вы уже знаете.
Но сам по себе блокирующий I/O не является чем-то плохим. Да и в PHP мы даже и не задумываемся особо над тем, как выполняется наше приложение: блокируется там поток выполнения или нет. Да и неблокирующий I/O в PHP — очень редкая штука. В модели request-response нам нужно, чтобы поток выполнения блокировался, потому что это единственный способ узнать, когда операция завершена и есть результат. Например, мы получили запрос, сходили в базу данных, как-то обработали результат, отрендерили HTML или собрали JSON, и вернули ответ. По сути здесь нечему выполняться асинхронно. На каждом этапе нам нужно дождаться и получить результаты предыдущего. Неблокирующий I/O больше всего нужен в серверном коде, когда нужно обрабатывать сразу тысячи клиентских запросов. Конечно PHP — это тоже серверный код, но перед ним всегда обычно есть Nginx или Apache. Что и позволяет нам спокойно писать блокирующий синхронный PHP-код. В традиционном PHP мы всегда имеем дело с одним единственным HTTP-запросом и нам в принципе неважно будет заблокирован поток выполнения или нет.
А что если мы хотим реализовать HTTP сервер на чистом PHP? Или сервер, слушающий сокет? Что если нам нужно реализовать сервис на PHP, который должен будет обрабатывать тысячи конкурентных запросов? Я имею в виду, что асинхронный PHP открывает возможности для создания целого класса приложений, которые раньше в принципе невозможно было написать на PHP.
Да, я уже слышу типичный ответ «PHP был создан не для этого». Но, что если мы уже можем писать асинхронный код. Для этого есть инструменты. Чтобы начать, даже не нужно устанавливать никаких дополнительных расширений.

Решение в том, чтобы вместо нативных блокирующих PHP функций для работы с I/O (вроде file_get_contents()), мы можем использовать библиотеки (ReactPHP и Amp). Эти библиотеки предоставляют высокоуровневые абстракции для реализации неблокирующего I/O в PHP. С неблокирующим асинхронным I/O нам и не нужно иметь много потоков для реализации конкурентности. Операционная система сама параллельно выполняет весь I/O для нас. Когда наш код вызывает какой-либо неблокирующий API, то он не ждёт ответа. Поток выполнения PHP может сразу продолжить выполнение кода, который находится после этого I/O-вызова. Операционная система сама уведомит наш PHP-код, когда данные будут готовы и доступны для чтения. Конечно звучит немного странно. Особенно когда мы привыкли к модели request-response. Каким образом операционная система свяжется с пользователем неблокирующего API? Какой-нибудь сигнал? Или может есть какой-то механизм, который постоянно проверяет, не пришли ли новые данные? Когда мы рассматриваем CPU, который последовательно выполняет инструкции в нашем коде, то как нам заставить программу слушать события? Обычно это реализуется через колбэки, которые имеют доступ к ожидаемым данным. Большинство операционных систем, на которых мы привыкли работать (Windows, Linux, Mac OS) умеют в такие асинхронные обработчики. То есть мы можем попросить их что-то сделать, а они предоставят итоговый результат через колбэк. Конечно существует много различных способов выразить неблокирующие вызовы — промисы, корутины и прочее. Но под капотом все они основаны на рутине (функции), которая будет вызвана после получения данных для I/O. У операционной системы много потоков, благодаря которым она может иметь доступ к различным системным ресурсам. Операционная система может обращаться к файловой системе или выполнять сетевой запрос в разных потоках. Таким образом наш PHP-скрипт только делегирует выполнение I/O-bound задач операционной системе и затем работает уже с результатами, полученными через колбэки.
Здесь проблема в том, что традиционный последовательный PHP-скрипт скорее всего не сможет обработать эти колбэки. Например, нам нужно выполнить два конкурентных HTTP-запроса:
$client = new Browser();
$result1 = $client->get('http://google.com/');
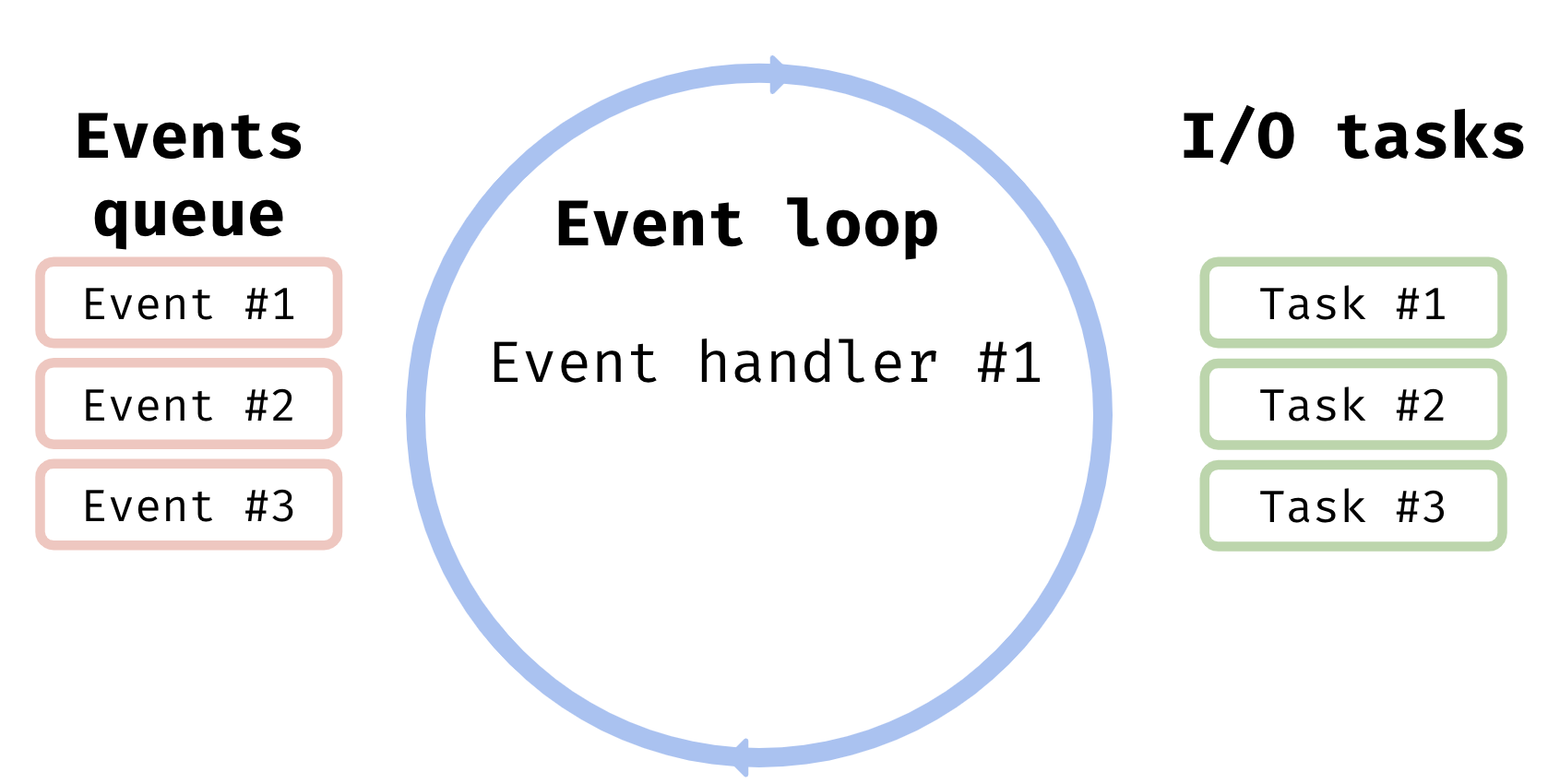
$result2 = $client->get('https://github.com/reactphp');Представим такой код, где мы хотим сделать два конкурентных HTTP-запроса. Сетевые запросы являются I/O-bound операциями, так что их можно смело делегировать операционной системе. Начинаем один запрос, и не дожидаясь пока он выполнится, сразу стартуем следующий. Как только операционная система выполнит эти запросы, она сообщит об этом нашему скрипту. Но… Вы уже видите здесь проблему? В однопоточном PHP код выполняется строчка за строчкой. Велика вероятность, что к тому моменту как сетевые запросы будут выполнены, сам скрипт уже закончит выполнение. Ему же больше просто нечего делать. Мы же не ждём HTTP-ответов, а только лишь стартует запросы. Поэтому если мы хотим получить и обработать ответы, то нам нужно две вещи: — Иметь возможность слушать I/O события. — Продолжать выполнение скрипта до тех пор, пока в фоне выполняются какие-либо I/O задачи. Оба этих условия решаются с помощью цикла событий. Предыдущий пример можно переписать следующим образом:
use React\Http\Browser;
use Psr\Http\Message\ResponseInterface;
$loop = React\EventLoop\Factory::create();
$client = new Browser($loop);
$result1 = $client->get('http://google.com/');
$result2 = $client->get('https://github.com/reactphp');
$loop->run();Мы добавили новый объект — цикл событий. Здесь я использовал реализацию ReactPHP. В самом начале скрипта мы создаём цикл событий, а в конце скрипта вызываем метод run(). Можно сказать, что это и делает PHP-скрипт асинхронным. На самой последней строчке скрипт не заканчивает выполнение, а начинает слушать события. Мы отправили два конкурентных сетевых запроса, так что нам нужно дождаться ответов. Более того, эта строчка на самом деле не отправляет ещё никаких запросов:
$result1 = $client->get('http://google.com/');Здесь мы всего лишь описываем наше намерение отправить запрос. А он в свою очередь будет отправлен, как только запустится цикл событий. Но если на самом деле запрос ещё не отправлен, то что же тогда хранится в переменных $result1 и $result2? Они обе установлены в null? В асинхронном (по крайней мере ReactPHP) мире, когда нам нужно оперировать результатами, которые будут получены в будущем, то мы используем промисы. Промис можно рассматривать как плэйсхолдер для будущего значения. Этот промис будет разрешен в реальный сетевой ответ, как только запрос будет выполнен.
$printResponse = fn (ResponseInterface $response) => var_dump((string)$response->getBody());
$promise1 = $client->get('http://google.com/');
$promise2 = $client->get('https://github.com/reactphp');
$promise1->then($printResponse);
$promise2->then($printResponse);Можно добавить обработчики к этим промисам, и например вывести тело ответа. Как это работает? Под капотом цикл событий можно рассматривать как бесконечный цикл, который слушает определенные события и вызывает для них обработчиков. Мы запускаем две неблокирующих задачи, тем самым просим операционную систему выполнить для нас сетевые запросы. Вот и всё. После этого поток выполнения может заняться чем-нибудь другим. Мы запустили задачи и при этом не останавливаемся, ожидая пока они будут выполнены. Как только операционная система выполнит сетевые запросы, она отправит событие о том, что данные готовы. Запись об этом событии попадает в очередь событий. Поток выполнения берёт первое событие из очереди и вызывает для него соответствующий обработчик. В нашем примере для обоих запросов один и тот же обработчик — распечатать тело запроса.
Заключение
Всё вместе: однопоточный PHP, неблокирующий I/O вместе с событийной архитектурой легко превращают классический PHP в асинхронный. Да, к сожалению в языке сейчас нет нативной поддержки для асинхронности. Но есть библиотеки, которые могут помочь. Более того, сам PHP может быть асинхронным сразу из коробки без установки каких-либо расширений (однако расширения помогают улучшить асинхронность). На данный момент основная проблема — отсутствие нативной поддержки для высокоуровневых абстракций (цикл событий, промисы) и I/O-функции. PHP существует в модели request-response уже на протяжении многих лет. Поэтому бОльшая часть библиотек, которые у нас есть, предполагают выполнение в традиционном блокирующем окружении. С другой стороны в последнее время язык стремительно развивается. Возможно очень скоро мы увидим первые шаги в поддержке асинхронности в PHP (например, fiber’ы).

Целью этой статьи не было показать вам, что на PHP можно решить любую задачу. Конечно же не существует серебреной пули и для каждой задачи есть подходящий инструмент. Выбор того, подходит ли PHP для вашей задачи или нужен другой язык — полностью на вашей совести. Моя задача была показать как работает асинхронный PHP. Что на самом деле внутри там нет никакой магии, и что однопоточный PHP действительно может быть асинхронным. Необязательно иметь несколько потоков, чтобы выполнять код конкурентно. Более того, если мы говорим о PHP, то его однопоточность здесь будет скорее преимуществом, чем ограничением.
