[Перевод] Миф развенчан: распределённые транзакции можно масштабировать
В сборнике VLDB'17 вышла такая статья. В ней представлена NAM-DB, масштабируемая распределённая система баз данных, использующая удалённый прямой доступ к памяти (RDMA) — в основном, однонаправленный вариант RDMA — и инновационную технологию диспетчера временных меток (timestamp oracle) для поддержки транзакций с изоляцией мгновенного снимка (SI). NAM в данном случае означает архитектуру с прикреплением памяти к сети (network-attached-memory), где благодаря активному использованию RDMA вычислительные узлы получают возможность напрямую общаться с пулом узлов памяти.
Удалённый прямой доступ к памяти (RDMA) позволяет передавать данные с одной машины на другую, не задействуя при этом ЦП. Так снижается нагрузка по одному из важнейших факторов, участвующих в масштабируемости распределённых транзакций: речь об издержках ЦП при работе со стеком TCP/IP. Когда ЦП получает на обработку слишком много сообщений, большую часть времени он может потратить на сериализацию/десериализацию сетевой коммуникации, а ресурса на реальную работу почти не остаётся. Эти феномены описаны в исследовании производительности протоколов Paxos и возникающих при работе узких мест.
Это статья напомнила «Is Scalable OLTP in the Cloud a Solved Problem? (CIDR 2023)», которую мы недавно рецензировали. Один из авторов у двух этих статей совпадает. Думаю, более ранняя статья по NAM получилась более зрелой в том, что касается интерпретации и деталей реализации. В статье же CIDR'23, напротив, в основном объясняется, почему выгодно использовать разделяемую память со множеством записывающих агентов. Вторая статья читается как меморандум, обсуждается в некоторой степени только идея ScaleStore. В обеих статьях RDMA понимается как ключевой механизм для воплощения масштабируемых распределённых транзакций, но подход к использованию RDMA в этих статьях отличается. В NAM-DB удалённый прямой доступ к памяти применяется в основном для однонаправленных операций при доступе к удалённым серверам памяти. В свою очередь, при модели с разделяемой записью и когерентным кэшем RDMA используется в основном для двунаправленных операций при внедрении протоколов когерентности кэша. Обе статьи нацелены на поддержку транзакций с изоляцией мгновенных снимков (SI), но в этих статьях отличаются подходы к контролю над конкурентностью и к управлению версиями: в NAM-DB используется сравнение с заменой для блокировки и последующей установки новых версий записей на серверах памяти, тогда как в версии с разделяемой записью и когерентным кэшем задействуется протокол инвалидации кэша, обеспечивающий согласованность кэшированных записей на вычислительных серверах.
Как устроена система
Сеть с поддержкой RDMA преобразует систему в гибридную архитектуру, в которой сочетается работа с разделяемой памятью и передача сообщений. Это ни распределённая система с разделяемой памятью (поскольку в ней сосуществуют несколько адресных пространств и нет протокола когерентности кэша), ни классическая система с передачей сообщений, ведь при операциях записи и чтения RDMA открывается прямой доступ к памяти удалённой машины.
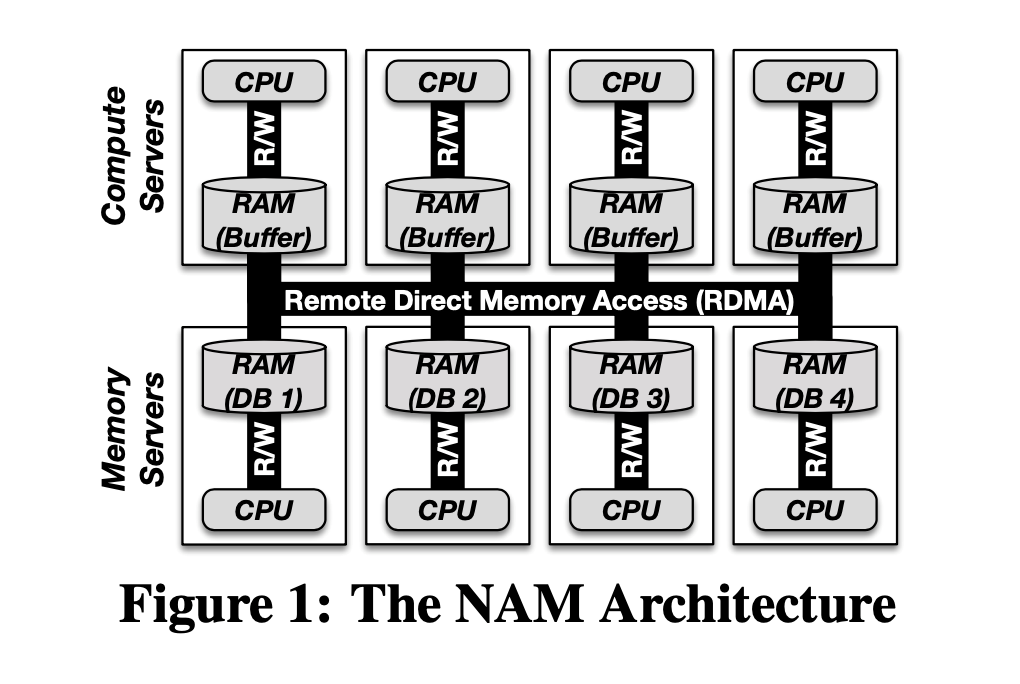
Рис. 1. Архитектура NAM
На рис. 1 показана архитектура с прикреплением памяти к сети (NAM). Обратите внимание, что здесь два разных типа серверов: серверы памяти и вычислительные серверы. Архитектура NAM логически открепляет вычислительные узлы от узлов-хранилищ, а при помощи RDMA обеспечивает коммуникацию между всеми узлами. Серверы памяти предоставляют разделяемый распределённый пул памяти, в котором и содержатся все данные. К этому пулу можно обратиться через RDMA с вычислительных серверов, на которых выполняются транзакции. На серверах памяти содержится вся информация, записанная в системе баз данных, как то: таблицы, индексы и все прочие детали состояния, необходимые для выполнения транзакций (например, логи и метаданные). Основная задача вычислительных серверов — выполнять транзакции над теми элементами данных, что сохранены на серверах памяти. Это первый принцип проектирования, заложенный в NAM: разделение вычислений и памяти.
Предполагается, что данные случайным образом распределены на узлах памяти в разделяемом пуле памяти. Любой узел памяти равноудалён от всех вычислительных узлов, и для выполнения транзакции вычислительный узел должен обратиться сразу к многим узлам памяти. Все транзакции по умолчанию являются распределёнными. Оптимизация в NAM-архитектуре не слишком зависит от того, где именно расположены конкретные данные. Это второй принцип проектирования NAM: независимость от расположения данных. Эта идея независимости от расположения данных близка мне, поскольку в неё вплетена устойчивость к неравномерным рабочим нагрузкам.
Локальность — это всего лишь настраиваемый параметр для опциональной/дополнительной оптимизации. Локальность достижима, например, если использовать конкретный вычислительный сервер и конкретный сервер памяти на одной и той же физической машине.
Выполнение транзакций с изоляцией мгновенных снимков (SI)

Листинг 1. Выполнение транзакции на вычислительном сервере
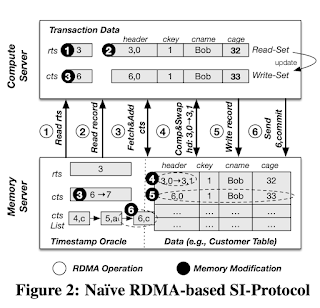
Рис. 2. Упрощённая реализация SI-протокола на основе удалённого прямого доступа к памяти
На рис. 1 показана архитектура с прикреплением памяти к сети (NAM). Обратите внимание, что здесь два разных типа серверов: серверы памяти и вычислительные серверы. Архитектура NAM логически открепляет вычислительные узлы от узлов-хранилищ, а при помощи RDMA обеспечивает коммуникацию между всеми узлами. Серверы памяти предоставляют разделяемый распределённый пул памяти, в котором и содержатся все данные. К этому пулу можно обратиться через RDMA с вычислительных серверов, на которых выполняются транзакции. На серверах памяти содержится вся информация, записанная в системе баз данных, как то: таблицы, индексы и все прочие детали состояния, необходимые для выполнения транзакций (например, логи и метаданные). Основная задача вычислительных серверов — выполнять транзакции над теми элементами данных, что сохранены на серверах памяти. Это первый принцип проектирования, заложенный в NAM: разделение вычислений и памяти.
Предполагается, что данные случайным образом распределены на узлах памяти в разделяемом пуле памяти. Любой узел памяти равноудалён от всех вычислительных узлов, и для выполнения транзакции вычислительный узел должен обратиться сразу к многим узлам памяти. Все транзакции по умолчанию являются распределёнными. Оптимизация в NAM-архитектуре не слишком зависит от того, где именно расположены конкретные данные. Это второй принцип проектирования NAM: независимость от расположения данных. Эта идея независимости от расположения данных близка мне, поскольку в неё вплетена устойчивость к неравномерным рабочим нагрузкам.
Локальность — это всего лишь настраиваемый параметр для опциональной/дополнительной оптимизации. Локальность достижима, например, если использовать конкретный вычислительный сервер и конкретный сервер памяти на одной и той же физической машине.
Диспетчер временных меток
В вышеописанном протоколе диспетчер временных меток (timestamp oracle) отвечает за продвижение временной метки считывания, сканируя очередь завершённых транзакций. Диспетчер просматривает список ctsList и пытается найти в нём метку о фиксации с максимальным значением, при условии, что все транзакции до этой временной метки также зафиксированы.
Реализация такого диспетчера временных меток, лишённая узких мест, интересна в качестве следующего примера: вот как глобальный регистр синхронизации/конфликтов можно сегментировать и преобразовать в структуру данных, располагающую к однонаправленной RDMA. Это третий принцип проектирования NAM: применение сегментируемых структур данных.
В протоколе диспетчера используется вектор временных меток (как в векторных часах), чтобы сохранять новейшую временную метку о фиксации для каждого потока, в котором выполняются транзакции с вычислительного сервера.
С началом транзакции вычислительный сервер считывает с сервера памяти весь вектор временных меток и пользуется им как временной меткой при считывании.
Когда транзакция фиксируется, создаётся новая временная метка фиксации — для этого увеличивается на единицу собственный счётчик, содержащийся в векторе временных меток. Затем при помощи операций сравнения с заменой RDMA проверяется, блокируется и заносится на сервера памяти его собственный набор на запись. Если верификация прошла успешно, то набор на запись устанавливается методом RDMA-записей с последующим обновлением счётчика временных меток (для этого тоже используется RDMA-запись. Если верификация не пройдена, то операция отменяется, и снимаются все блокировки, что также делается при помощи RDMA-записей.
Диспетчер временных меток отвечает за продвижение временной метки считывания. Для этого он сканирует вектор временных меток и находит временную метку фиксации с наивысшим значением, которой предшествуют все зафиксированные транзакции. Таким образом другие транзакции могут читать более ранние мгновенные снимки, сохранённые в базе данных.
Думаю, ту задачу, что решена выше при помощи временных меток, удобнее решать при помощи синхронизированных часов. Если вы используете для RDMA специальное аппаратное обеспечение, почему бы не обзавестись и аппаратной поддержкой и для синхронизированных часов (что в наши дни вполне осуществимо). Как же при использовании синхронизированных часов будет продвигаться временная метка на считывание? Очень просто: отсчёт будет начинаться на вычислительном узле с началом транзакции, T-старт. После этого транзакция прочитает всё, что было зафиксировано до её начала, T-старт, и получится самосогласованный мгновенный снимок.
Реализация
Структуры таблицы и индекса проектируются с расчётом на сегментируемость и масштабируемость. В структуре таблицы используется схема сегментирования на основе хеша, отображающая каждую запись на ячейку фиксированного размера в области памяти. В структуре индекса используется дерево B+, сегментируемое по диапазонам ключей, хранимым в разных областях памяти. Обе структуры пользуются операциями RDMA для доступа к данным и обновления их на серверах памяти.
Каталог базы данных реализуется таким образом, что транзакции могут находить конкретные места, в которых хранятся таблицы и индексы. Данные каталога сегментируются по хешу и хранятся на серверах памяти. Все акты доступа с вычислительных серверов реализуются при помощи двунаправленных RDMA-операций, поскольку компиляция запросов не так сильно нагружает сервера памяти по сравнению с фактическим выполнением транзакции. Каталог меняется не так часто, поэтому данные каталога фиксируются на вычислительных серверах.
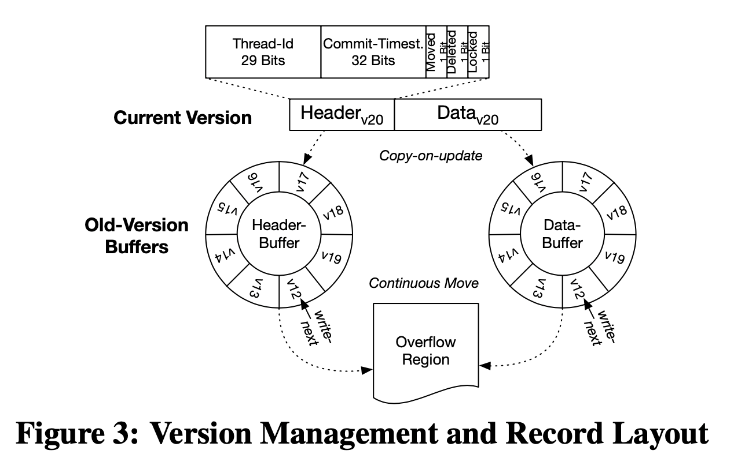
Рис. 3. Управление версиями и топология записей
Благодаря системе с множественным версионированием, вычислительные серверы могут обращаться к различным версиям записей (и обновлять их) при помощи операций RDMA. Схема хранит самую свежую версию каждой записи в выделенной области памяти, а более старые версии перемещает в специальный буфер и область переполнения. Также для каждой записи здесь используется заголовочная секция, в которой содержатся метаданные — например, информация о версии и блокирующие биты.
Для того, чтобы справляться с отказами серверов памяти, в каждом потоке выполнения транзакций вычислительный сервер ведёт приватный лог, записываемый на серверы памяти методом записей RDMA. Записи по всем транзакционным инструкциям заносятся в лог базы данных перед тем, как на сервера памяти будет занесён набор для записи. В случае, если сервер памяти откажет, NAM-DB стопорит всю систему и восстанавливает все серверы памяти до согласованного состояния, соответствующего новейшей уцелевшей контрольной точке. Процедуру восстановления выполняет специально выделенный вычислительный сервер, который воспроизводит общий лог, полученный слиянием со всех серверов памяти.
Такой глобальный останов в продакшене представлял бы проблему, но пока система NAM — это исследовательский рабочий прототип. Возможно, эта проблема могла бы решаться при помощи избыточности или кворума, но в таком случае привносились бы серьёзные проблемы с согласованностью. Не всё так просто.
Оценка
В представленной экспериментальной конфигурации участвует кластер из 56 машин, объединённых в сеть InfiniBand FDR, а с разными конфигурациями и рабочими нагрузками проверялась контрольная точка TPC-C.
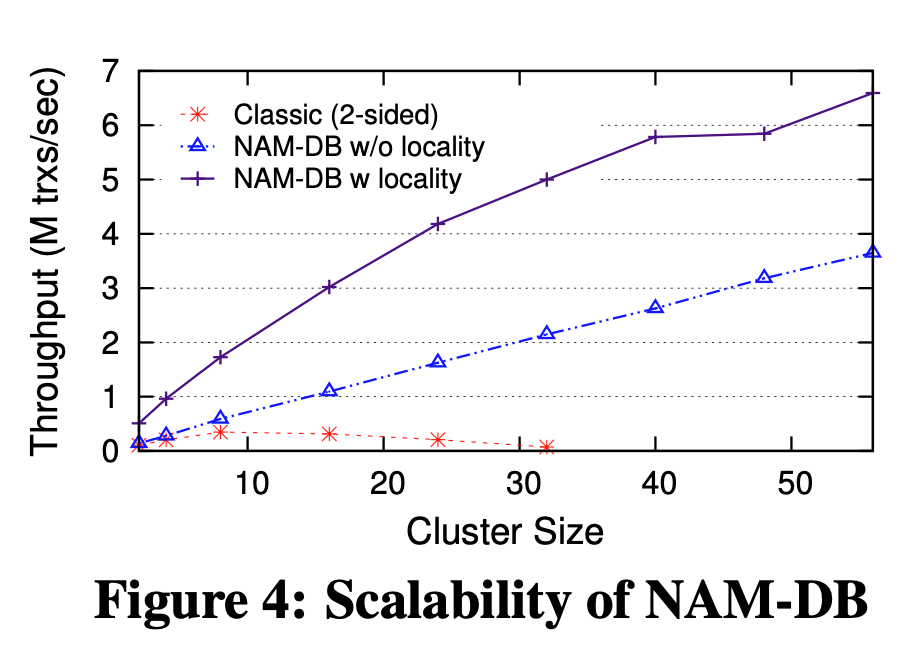
Рис. 4. Масштабируемость NAM-DB
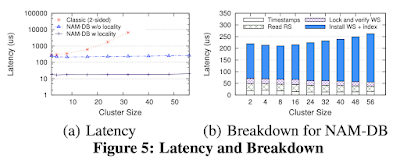
Рис. 5. Задержка и разбивка
В результате наблюдаем, как NAM-DB позволяет добиться линейного горизонтального масштабирования с сохранением имеющейся пропускной способности и низких задержек, а также обставляет другие системы на основе RDMA, например. FaRM. При стандартной конфигурации контрольной точки TPC-C наблюдается, NAM-DB линейно масштабируется более чем до 3,6 миллионов новых транзакций в секунду на 56 машинах и до 6,5 миллионов новых транзакций с оптимизацией расположения. Это на 2 миллиона транзакций в секунду больше, чем FARM достигает на 90 машинах.
Обсуждение
1. Почему в NAM важна изоляция мгновенных снимков? Почему такой подход не работал бы с сериализуемой изоляцией? Я не жалуюсь на то, как используется SI, такой подход целесообразен и повсеместно используется в мире. Думаю, этот вопрос помогает многое прояснить в проектировании и реализации распределённых транзакций.
2. Понятия не имею, почему активнее не использовать новое аппаратное обеспечение при работе с распределёнными системами и базами данных. Не думаю, что вопрос в стоимости оборудования. Достаточно ли зрелой (крепкой/надёжной) технологией является RDMA, чтобы обслуживать с её помощью распределённые транзакции? В чём её изъяны? По каким причинам она не слишком быстро усваивается?
