[Перевод] Метрики производительности для исследования невероятно быстрых веб-приложений
Есть одно высказывание: «Что ты не можешь измерить, то ты не можешь улучшить». Автор статьи, перевод которой мы сегодня публикуем, работает в компании Superhuman. Он говорит, что эта компания занимается разработкой самого быстрого в мире почтового клиента. Здесь речь пойдёт о том, что такое «быстро», и о том, как создавать инструменты для измерения производительности невероятно быстрых веб-приложений.

Измерение скорости приложений
Мы, в стремлении улучшить нашу разработку, потратили очень много времени на измерение её скорости. И, как оказалось, метрики производительности — это показатели, которые на удивление сложны для понимания и применения.
С одной стороны — сложно проектировать метрики, которые точно описывают те ощущения, которые пользователь испытывает, работая с системой. С другой стороны — непросто создавать метрики, которые точны настолько, что их анализ позволяет принимать обоснованные решения. В результате многие команды разработчиков не могут доверять собираемым ими данным о производительности их проектов.
Даже если у разработчиков есть достоверные и точные метрики, пользоваться ими нелегко. Как определить понятие «быстро»? Как найти баланс между скоростью и непротиворечивостью? Как научиться оперативно обнаруживать ухудшения производительности или научиться оценивать воздействие оптимизаций на систему?
Здесь мы хотим поделиться некоторыми соображениями, касающимися разработки средств анализа производительности веб-приложений.
1. Использование правильных «часов»
В JavaScript имеются два механизма для получения временных меток: performance.now() и new Date().
Чем они различаются? Для нас принципиальными являются следующие два различия:
- Метод
performance.now()гораздо точнее. Точность конструкцииnew Date()— ± 1 мс, в то время как точностьperformance.now()— это уже ± 100 мкс (да, речь идёт именно о микросекундах!). - Значения, возвращаемые методом
performance.now(), всегда возрастают с постоянной скоростью и не зависят от системного времени. Этот метод просто отмеряет промежутки времени, не ориентируясь на системное время. А наnew Date()системное время влияет. Если переставить системные часы, то изменится и то, что возвратитnew Date (), а это испортит данные мониторинга производительности.
Хотя те «часы», которые представлены методом performance.now(), очевидно, гораздо лучше подходят для замера временных интервалов, они тоже не идеальны. И performance.now(), и new Date() страдают от одной и той же проблемы, проявляющейся в том случае, если система находится в состоянии сна: измерения включают в себя и то время, когда машина даже не была активна.
2. Проверка активности приложения
Если вы, измеряя производительность веб-приложения, переключитесь с его вкладки на какую-то другую — это нарушит процесс сбора данных. Почему? Дело в том, что браузер ограничивает приложения, находящиеся в фоновых вкладках.
Имеются две ситуации, в которых метрики могут быть искажены. В результате приложение будет казаться гораздо более медленным, чем на самом деле.
- Компьютер переводится в режим сна.
- Приложение выполняется в фоновой вкладке браузера.
Возникновение обеих этих ситуаций — не редкость. У нас, к счастью, есть два варианта их решения.
Во-первых, мы можем просто игнорировать искажённые метрики, отбрасывая результаты измерений, слишком сильно отличающиеся от неких разумных значений. Например, код, вызываемый при нажатии на кнопку, просто не может выполняться в течение 15 минут! Возможно, это — единственное, что вам нужно для того, чтобы справиться с двумя вышеописанными проблемами.
Во-вторых, можно воспользоваться свойством document.hidden и событием visibilitychange. Событие visibilitychange вызывается тогда, когда пользователь переключается с интересующей нас вкладки браузера на другую вкладку или возвращается на интересующую нас вкладку. Оно вызывается тогда, когда окно браузера сворачивается или разворачивается, когда компьютер начинает работу, выходя из режима сна. Другими словами, это именно то, что нам нужно. Кроме того, до тех пор, пока вкладка находится в фоновом режиме, свойство document.hidden равно true.
Вот простой пример, демонстрирующий использование свойства document.hidden и события visibilitychange.
let lastVisibilityChange = 0
window.addEventListener('visibilitychange', () => {
lastVisibilityChange = performance.now()
})
// не логируйте никаких метрик, собранных до последнего изменения видимости страницы,
// или метрик, собираемых на странице, находящейся на фоновой вкладке
if (metric.start < lastVisibilityChange || document.hidden) return
Как видите, некоторые данные мы отбрасываем, но это хорошо. Дело в том, что это данные, относящиеся к тем периодам работы программы, когда она не может полноценно пользоваться ресурсами системы.
Сейчас мы говорили о показателях, которые нас не интересуют. Но существует множество ситуаций, данные, собранные в которых, нам весьма интересны. Посмотрим на то, как собирать эти данные.
3. Поиск показателя, который позволяет наилучшим образом зафиксировать время начала события
Одна из наиболее спорных возможностей JavaScript — это то, что цикл событий этого языка является однопоточным. В некий момент времени способен выполняться лишь один фрагмент кода, выполнение которого не может быть прервано.
Если пользователь нажимает на кнопку во время выполнения некоего кода — программа не узнает об этом до тех пор, пока выполнение этого кода не завершится. Например, если приложение потратило 1000 мс в непрерывном цикле, а пользователь нажал кнопку Escape через 100 мс после начала цикла, событие не будет зарегистрировано ещё в течение 900 мс.
Это может сильно исказить метрики. Если нам нужна точность в измерении того, как именно пользователь воспринимает работу с программой, то это — огромная проблема!
К счастью, решить эту проблему не так уж и сложно. Если речь идёт о текущем событии, то мы можем, вместо использования performance.now() (времени, когда мы увидели событие), воспользоваться window.event.timeStamp (время, когда было создано событие).
Временная метка события устанавливается главным процессом браузера. Так как этот процесс не блокируется тогда, когда заблокирован цикл событий JS, event.timeStamp даёт нам гораздо более ценные сведения о том, когда событие было на самом деле запущено.
Тут надо отметить, что и этот механизм не идеален. Так, между моментом, когда нажата физическая кнопка, и моментом, когда соответствующее событие прибывает в Chrome, проходит 9–15 мс неучтённого времени (вот превосходная статья, из которой можно узнать о том, почему это происходит).
Однако даже если мы можем измерить время, необходимое событию на то, чтобы добраться до Chrome, нам не следует включать это время в наши метрики. Почему? Дело в том, что мы не можем внести в код такие оптимизации, которые способны значительно повлиять на подобные задержки. Мы никак не можем их улучшить.
В результате, если говорить о нахождении временной метки начала события, то показатель event.timeStamp выглядит тут наиболее адекватно.
Как лучше всего оценить момент завершения события?
4. Выключение таймера в requestAnimationFrame ()
Из особенностей устройства цикла событий в JavaScript вытекает ещё одно следствие: некий код, не имеющий отношения к вашему коду, может выполняться после него, но до того, как браузер отобразит на экране обновлённый вариант страницы.
Рассмотрим, например, React. После выполнения вашего кода React обновляет DOM. Если вы выполняете измерения времени только в вашем коде, это значит, что вы не измерите время, которое ушло на выполнение кода React.
Для того чтобы измерить это дополнительное время, мы, для выключения таймера, используем requestAnimationFrame(). Делается это только тогда, когда браузер готов к выводу очередного кадра.
requestAnimationFrame(() => { metric.finish(performance.now()) })
Вот жизненный цикл кадра (диаграмма взята из этого замечательного материала, посвящённого requestAnimationFrame).
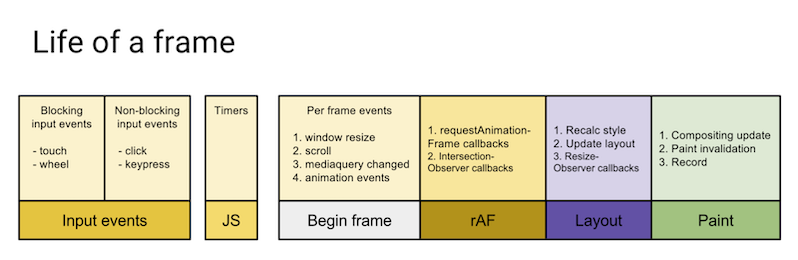
Жизненный цикл кадра
Как можно видеть на этом рисунке, requestAnimationFrame() вызывается после того, как будет завершена работа процессора, прямо перед выводом кадра на экран. Если мы выключим таймер именно здесь, это значит, что мы можем быть совершенно уверены в том, что в собранные данные о временном промежутке включено всё, что заняло время до обновления экрана.
Пока всё хорошо, но теперь ситуация становится довольно-таки сложной…
5. Игнорирование времени, необходимого на создание макета страницы и её визуализацию
Предыдущая диаграмма, демонстрирующая жизненный цикл кадра, иллюстрирует ещё одну проблему, с которой мы столкнулись. В конце жизненного цикла кадра имеются блоки Layout (формирование макета страницы) и Paint (вывод страницы на экран). Если не учесть время, необходимое на выполнение этих операций, то измеренное нами время будет меньше чем то время, которое нужно для того, чтобы некие обновлённые данные появились бы на экране.
К нашему счастью у requestAnimationFrame есть ещё один туз в рукаве. При вызове функции, переданной requestAnimationFrame, этой функции передаётся отметка времени, указывающая на время начала формирования текущего кадра (то есть — на то, что находится в самой левой части нашей диаграммы). Эта отметка времени обычно находится очень близко к времени окончания предыдущего кадра.
В результате вышеописанный недостаток можно исправить, измерив общее время, прошедшее с момента event.timeStamp до времени начала формирования следующего кадра. Обратите внимание на вложенные requestAnimationFrame:
requestAnimationFrame(() => {
requestAnimationFrame((timestamp) => { metric.finish(timestamp) })
})
Хотя то, что показано выше, и выглядит как отличное решение проблемы, мы, в итоге, решили этой конструкцией не пользоваться. Дело в том, что, хотя эта методика и позволяет получить более достоверные данные, точность таких данных снижается. Кадры в Chrome формируются с периодичностью 16 мс. Это значит, что наивысшая доступная нам точность составляет ±16 мс. А если браузер перегружен и пропускает кадры, то точность будет ещё ниже, причём это её ухудшение окажется непредсказуемым.
Если вы реализуете это решение, то серьёзное улучшение производительности вашего кода, такое, как ускорение задачи, которая раньше выполнялась 32 мс, до 15 мс, может никак не отразиться на результатах измерения производительности.
Не учитывая время, необходимое на формирование макета страницы и на её вывод, мы получаем гораздо более точные метрики (±100 мкс) для кода, который находится под нашим контролем. В результате мы можем получить числовое выражение любого улучшения, внесённого в этот код.
Мы, кроме того, исследовали похожую идею:
requestAnimationFrame(() => {
setTimeout(() => { metric.finish(performance.now()) }
})
Сюда попадёт время рендеринга, но при этом точность показателя не будет ограничена ±16 мс. Однако мы и этот подход решили не использовать. Если система столкнётся с длительным событием ввода, то вызов того, что передано setTimeout, может быть значительно задержан и выполнен уже после обновления пользовательского интерфейса.
6. Выяснение «процента событий, которые находятся ниже целевого показателя»
Мы, разрабатывая проект и ориентируясь на высокую производительность, пытаемся оптимизировать его по двум направлениям:
- Скорость. Время выполнения самой быстрой задачи должно быть как можно ближе к 0 мс.
- Единообразие. Время выполнения самой медленной задачи должно быть как можно ближе к времени выполнения самой быстрой задачи.
Из-за того, что эти показатели меняются с течением времени, их сложно визуализировать и непросто обсуждать. Можно ли создать систему визуализации подобных показателей, которая вдохновляла бы нас на оптимизацию и скорости, и единообразия?
Типичный подход заключается в измерении 90-го перцентиля задержки. Этот подход позволяет нарисовать линейный график, по оси Y которого откладывают время в миллисекундах. Этот график позволяет увидеть, что 90% событий находятся ниже линейного графика, то есть выполняются быстрее, чем за то время, на которое указывает линейный график.
Известно, что 100 мс — это граница между тем, что воспринимается как «быстрое» и «медленное».
Но что мы выясним о том, какие ощущения пользователи испытывают от работы, если будем знать, что 90-й перцентиль задержки равен 103 мс? Не особенно много. Какие показатели обеспечат пользователям удобство работы? Нет способа узнать это наверняка.
А что если мы будем знать о том, что 90-й перцентиль задержки равен 93 мс? Возникает такое ощущение, что 93 — это лучше, чем 103, но ничего больше об этих показателях мы сказать не можем, равно как и о том, что они означают в плане восприятия проекта пользователями. На этот вопрос, опять же, нет точного ответа.
Мы нашли решение этой задачи. Оно заключается в том, чтобы измерять процент событий, время выполнения которых не превышает 100 мс. У такого подхода есть три больших преимущества:
- Метрика ориентирована на пользователей. Она может сообщить нам о том, какой процент времени наше приложение является быстрым, и какой процент пользователей воспринимает его как быстрое.
- Эта метрика позволяет нам вернуть измерениям ту точность, которая была потеряна из-за того, что мы не замеряли время, уходящее на выполнение задач, находящихся в самом конце кадра (мы говорили об этом в разделе №5). Благодаря тому, что мы устанавливаем целевой показатель, который укладывается в несколько кадров, результаты измерений, которые близки к этому показателю, либо оказываются меньше его, либо больше.
- Эту метрику легче вычислять. Достаточно просто посчитать количество событий, время выполнения которых находится ниже целевого показателя, а после этого — разделить их на общее количество событий. Перцентили считать гораздо сложнее. Есть эффективные аппроксимации, но для того чтобы сделать всё правильно, нужно учитывать каждое измерение.
У этого подхода есть лишь один минус: если показатели хуже целевого, то непросто будет заметить их улучшение.
7. Использование нескольких пороговых значений при анализе показателей
Для того чтобы визуализировать результат оптимизации производительности, мы ввели в нашу систему несколько дополнительных пороговых значений — выше 100 мс и ниже.
Мы сгруппировали задержки так:
- Менее 50 мс (быстро).
- От 50 до 100 мс (хорошо).
- От 100 до 1000 мс (медленно).
- Более 1000 мс (ужасно медленно).
«Ужасно медленные» результаты позволяют нам видеть то, что мы где-то очень сильно промахнулись. Поэтому мы выделяем их ярко-красным цветом.
То, что укладывается в 50 мс, очень чувствительно к изменениям. Здесь улучшения производительности часто видны задолго до того, как они могли бы быть видны в группе, которой соответствует показатель в 100 мс.
Например, следующий график визуализирует производительность просмотра треда в Superhuman.
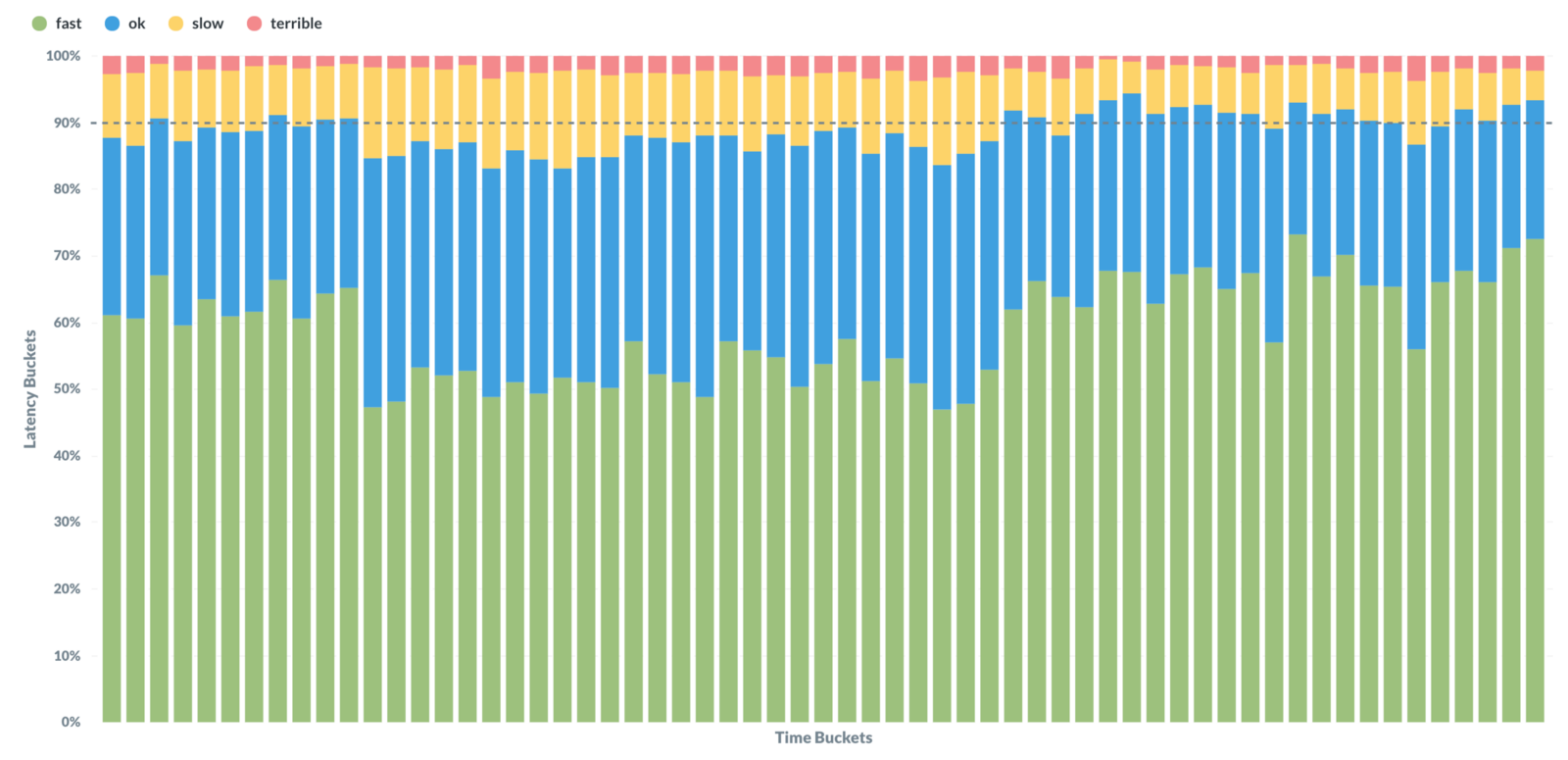
Просмотр треда
Здесь показан период падения производительности, а потом — результаты улучшений. Трудно оценить падение производительности в том случае, если смотреть лишь на показатели, соответствующие 100 мс (верхние части синих столбцов). При взгляде же на результаты, укладывающиеся в 50 мс (верхние части зелёных столбцов), проблемы с производительностью видны уже гораздо отчётливее.
Если бы мы использовали традиционный подход к исследованию метрик производительности, то, вероятно, не заметили бы проблему, влияние которой на систему показано на предыдущем рисунке. Но благодаря тому, как мы проводим измерения, и тому, как визуализируем наши метрики, мы смогли очень быстро проблему обнаружить и решить её.
Итоги
Оказалось, что найти правильный подход к работе с метриками производительности на удивление сложно. Нам удалось выработать методику, позволяющую создавать качественные инструменты для измерения производительности веб-приложений. А именно, речь идёт о следующем:
- Время начала события измеряется с помощью
event.timeStamp. - Время окончания события измеряется с помощью
performance.now()в коллбэке, передаваемомrequestAnimationFrame(). - Игнорируется всё, что происходит с приложением в то время, когда оно находится на неактивной вкладке браузера.
- Данные агрегируются с использованием показателя, который можно описать как «процент событий, которые находятся ниже целевого показателя».
- Данные визуализируются с выделением нескольких уровней пороговых значений.
Эта методика даёт вам инструменты для создания достоверных и точных метрик. Вы можете строить графики, на которых чётко видно падение производительности, можете визуализировать результаты оптимизаций. А самое важное — у вас появляется возможность сделать быстрые проекты ещё быстрее.
Уважаемые читатели! Как вы анализируете производительность своих веб-приложений?


