[Перевод] Масштабируем стриминг c помощью Kubernetes и RabbitMQ
Подробное описание проблем, с которыми сталкиваются стриминг сайты, и то, как они могут спроектировать свою инфраструктуру для управления нагрузкой.

Стриминг. Это слово мы сегодня часто слышим. Большинство из нас ежедневно используют Netflix или YouTube. Это настолько стало частью жизни каждого, может быть, даже слишком для нас самих.
Но люди редко останавливаются и задаются вопросом: как это вообще работает? С моей точки зрения разработчика, это чистое безумие. В сети нужно хранить и передавать так много данных, люди во всем мире должны иметь доступ к ним без задержек и проблем, и это должно работать на всех устройствах.
Я не буду притворяться, что знаю, как эти приложения работают внутри. Вероятно, они используют концепции, о которых я даже не мечтал, чтобы оптимизировать каждый дюйм.
Но не уходите пока; есть еще причина, по которой я пишу эту статью. Я хочу использовать свой непосредственный опыт работы техническим руководителем решения для стриминга в Skeepers, чтобы объяснить, как нам удается создавать высококачественные видео и транслировать их непосредственно на веб-сайт нашего клиента, как если бы вы смотрели видео на YouTube.
Я буду обсуждать технические темы, такие как Kubernetes, RabbitMQ и балансировщики нагрузки. Для прочтения статьи необходимы базовые знания по этим темам.
Уточнение, я говорю о стриминге как о просмотре онлайн-видео, которое не является прямой трансляцией. Обычное видео на YouTube еще называют видеостримингом.
Жизненный цикл видео: от загрузки до воспроизведения
Я возьму вас в путешествие от момента, когда пользователь загружает видео на наш сайт, до момента, когда вы воспроизводите его на своем устройстве, и о проблемах, которые с этим связаны.

Шаг первый: загрузка видео
Хорошо, первый шаг — загрузка видео. Нам еще предстоит определить, в каком формате, кодеке или даже в каком разрешении будет видео.
Сначала оно будет нормализовано, то есть мы преобразуем все видео в один и тот же формат (сначала mp4), стабилизируем видео и гармонизируем звук, чтобы уменьшить тряску или громкие звуки.
Затем мы разбиваем видео на несколько небольших частей; результирующим форматом будет формат стриминга с адаптивным битрейтом, называемый MPEG-Dash или HLS.
Эта задача требует много времени, поэтому пользователь не может просто синхронно ждать ответа API. Это должно быть асинхронно.
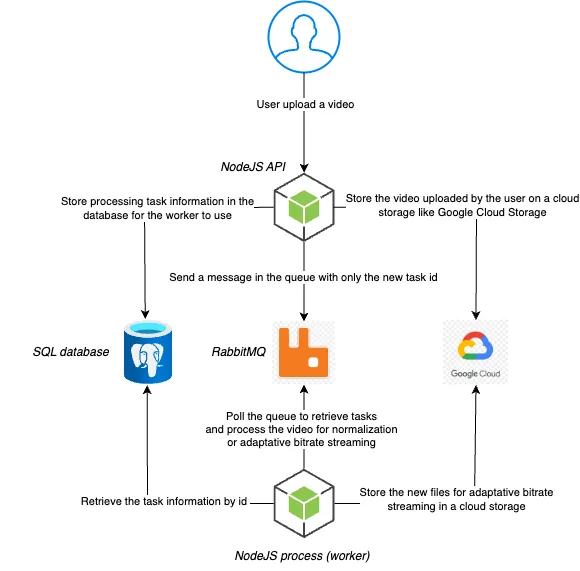
Специально разработанная схема, представляющая упрощенную архитектуру.
Вы можете увидеть асинхронную реализацию с использованием RabbitMQ на этой схеме. Когда пользователь загружает новое видео, оно сначала загружается в облачное хранилище. Мы используем Google Cloud Storage, но это может быть любое хранилище. После завершения загрузки мы создаем задачу по обработке в базе данных и отправляем идентификатор задачи в очередь. Пользователю будет показано сообщение о том, что обработка продолжается и нужно подождать несколько минут.
Воркер NodeJS постоянно опрашивает очередь, ожидая новых задач, как хороший солдат. Когда будет доступно новое видео, он получит информацию о задаче по обработке из базы данных. Под капотом он использует FFmpeg для выполнения необходимой работы (например, нормализация или создание формата стриминга с адаптивным битрейтом), сохраняет полученные файлы в хранилище и обновляет статус задачи в базе данных.
Вы, вероятно, думаете: «Подождите, в заголовке вашей статьи есть Kubernetes, но его нет в схеме» или «Он не масштабируется как есть. Если видео будет много, произойдет сбой».
Я двигаюсь туда! Схема, которую я представил, была всего лишь введением. Я постепенно знакомлю с каждым понятием.
Здесь действительно есть несколько проблем. Если есть только один API и один воркер, он быстро перегрузится. В первую очередь потому, что FFmpeg требует много ресурсов. Давайте сделаем это лучше!

Специально разработанная схема, представляющая более сложную архитектуру с Kubernetes.
Хорошо, мы добавили Kubernetes. NodeJS API, обрабатывающий пользовательские вызовы, получит множество HTTP-вызовов с пользовательскими файлами. Таким образом, вместо одного экземпляра API теперь имеется неограниченное количество подов Kubernetes. Мы настроили автоматическое масштабирование таким образом, что если объем оперативной памяти или процессора модулей достигнет определенного предела (70% от их емкости), он запустит новый под для того же API.
Ссылка на «узел Kubernetes» для упрощения схемы отсутствует, но это также можно масштабировать между узлами. Если количество подов (фактически требуемая емкость подов) достигает предела мощности для текущего узла, он автоматически масштабирует новый узел и начинает запускать новые поды внутри этого узла.
Балансировщик нагрузки перед API будет случайным образом распределять HTTP-вызовы между всеми существующими подами, чтобы разделить нагрузку.
Воркер, опрашивающий RabbitMQ, также выполняет автоматическое масштабирование, но не по ресурсам; он масштабируется по количеству сообщений, ожидающих в очереди. Чем больше сообщений ожидает, тем быстрее нам нужно их обрабатывать, поэтому запуск новых воркеров — это наш путь.
Намного лучше, но мы хотим, когда это возможно, сэкономить, поэтому позвольте мне представить вытесняемые узлы!
Вытесняемые виртуальные машины — это экземпляры виртуальных машин Compute Engine, стоимость которых ниже, чем у стандартных виртуальных машин, и которые не предоставляют никаких гарантий доступности — документация Google Cloud
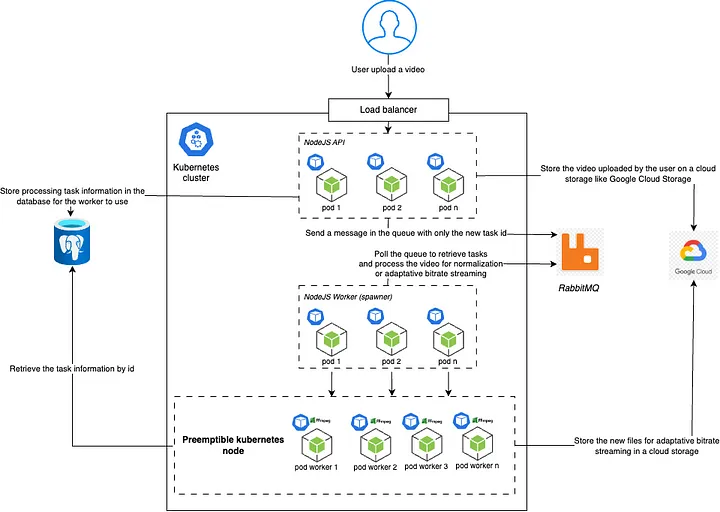
Специально разработанная схема, представляющая более сложную архитектуру с Kubernetes и вытесняемыми узлами.
Мы хотим, чтобы наши пользователи получали наилучшие впечатления, но для нас совершенно нормально, если у них нет доступа к видео наилучшего качества в формате стриминга с адаптивным битрейтом прямо во время загрузки своего контента. Доступность вытесняемого узла может занять несколько минут, но это дешевле, чем обычный узел.
В этой новой схеме мы преобразовали нашего NodeJS-воркера с FFmpeg в то, что мы внутренне называем «spawner». Он по-прежнему опрашивает очередь RabbitMQ, но вместо обработки самого видео он запустит новый модуль Kubernetes в вытесняемом узле, и этот новый модуль выполнит обработку.
Этот способ дешевле. Мы перенесли все наши ресурсоёмкие задачи на вытесняемый узел, поэтому нам не нужно так сильно масштабировать наш генератор, как на узле с обычной ценой.
Google Cloud может отключать вытесняемые узлы, если обычному узлу нужны ресурсы. Мы должны гарантировать, что невыполненная задача возвращается в очередь и позже запускается снова на другом узле.
Отключаются, когда Compute Engine требуются ресурсы для запуска стандартных виртуальных машин — документация Google Cloud
Эта новая установка с вытесняемыми узлами требует больше накладных расходов при реализации, но значительно снижает цену. Мы достигли точки, когда могли бесконечно масштабироваться по вертикали.
Шаг второй: воспроизведение видео
Хорошо, на этом этапе мы загрузили и преобразовали наше пользовательское видео для стриминга на нашем сайте. Видео может занимать сотни мегабайт, разделенных на тысячи фрагментов.
HTML-тег video по умолчанию не поддерживает форматы стриминга с адаптивным битрейтом, такие как HLS или MPEG-Dash, поэтому нам необходимо использовать специальный проигрыватель. Два наиболее часто используемых проигрывателя для стриминга — это HLS.js и Skaka Player. Они оба используют расширение Media Source Extension для обработки этого формата. Я не буду вдаваться в подробности о проигрывателях и MSE, поскольку это не является целью данной статьи; Вы можете прочитать больше, нажав на ссылку, которую я предоставил.
Чтобы предотвратить загрузку видеофайлов из облачного хранилища каждый раз, когда кто-то пытается воспроизвести видео и, следовательно, платить большие деньги провайдеру облака, мы используем сеть доставки контента (CDN).

Специально разработанная схема, показывающая процесс использования CDN
Пользователь попадает на сайт для просмотра видео. Все вызовы для получения видео проходят через нашего провайдера CDN, Cloudflare. CDN будет кэшировать контент на конечных устройствах, это означает, что если запрашиваемый вами контент отсутствует в их кеше, он потребует его по указанному вами URL-адресу.
«Периферийная» часть означает, что в зависимости от того, где вы находитесь в мире, он будет хранить его на сервере, который ближе к вам (регионально), так что, если пользователь в вашем регионе запрашивает тот же контент, он получает его невероятно быстро. Если пользователь из другой части мира запрашивает тот же контент, он выполнит тот же процесс и сохранит его рядом с этим пользователем.
Каждый видеофрагмент представляет собой отдельный файл, поэтому время ожидания для неудачливого пользователя, которому придется создавать кэш, все еще относительно невелико. Не тысячи мегабайт для скачивания за раз.
Я пропустил некоторые важные части нашей архитектуры, такие как микросервисы, WebSockets, Redis pub/sub или веб-хуки, чтобы сосредоточиться на возможностях автоматического масштабирования Kubernetes в сочетании с асинхронными очередями RabbitMQ. Наверное, скоро напишу еще одну статью про «коммуникацию» в нашей архитектуре.
У YouTube, вероятно, есть реализация, существенно отличающаяся от нашей, но это уже хорошее представление о том, как может выглядеть сложная система с Kubernetes.
Мне бы хотелось побыть маленькой мышкой и взглянуть на всю архитектуру YouTube, чтобы увидеть, насколько мы от них далеки. Возможно, мне захочется связаться с создателем фильма «Рататуй»; это реальная история, да?
