[Перевод] Машинное обучение в разработке игр
В последние годы мы наблюдаем взрывной рост популярности многопользовательских онлайн-игр, которые покоряют сердца миллионов игроков во всем мире. В результате этого многократно растут требования к гейм-дизайнерам, потому что игроки хотят видеть продуманную механику и баланс. Ведь нет никакого интереса, если одна стратегия заметно превосходит все остальные.
При разработке игрового процесса баланс обычно настраивается по следующей схеме:
Проводятся тысячи игровых партий с участием тестировщиков.
Собираются отзывы и на их основании в игру вносятся корректировки.
Шаги 1 и 2 повторяются, пока результат не устроит и тестировщиков, и гейм-дизайнеров.
Этот процесс не только времязатратный, но и несовершенный. Чем сложнее игра, тем вероятнее, что незначительные недостатки останутся незамеченными. Когда в играх много разных ролей с десятками взаимосвязанных навыков, добиться правильного баланса оказывается очень сложно.
Сегодня мы представляем механизм на базе машинного обучения, который помогает адаптировать игровой баланс за счет обучения моделей, выступающих в роли тестировщиков. Мы продемонстрируем подход на примере экспериментальной компьютерной карточной игры Chimera. Мы уже показывали ее в качестве опытной системы для графики, сгенерированной алгоритмом машинного обучения. При таком тестировании обученные программные агенты проводят между собой миллионы партий. Из их результатов собирается статистика, которая помогает гейм-дизайнерам улучшать баланс, совершенствовать игру и приближать ее к первоначальному замыслу.
Chimera
Мы задумывали Chimera как экспериментальную игру, при разработке которой будет активно использоваться машинное обучение. Для нее мы сознательно предложили такие правила, которые расширяют возможности и серьезно усложняют создание традиционных игровых ИИ-алгоритмов.
В Chimera игроки из других существ создают химер, которых нужно развивать и делать сильнее. Цель игры — победить химеру противника. Игровой процесс включает в себя основные моменты, описанные ниже.
Игроки могут использовать:
существ, которые атакуют (урон зависит от показателя атаки) или защищаются (теряя показатель здоровья);
заклинания, которые дают особые эффекты.
Существа вызываются в биомы ограниченной вместимости, которые размещаются на игровом поле. У каждого существа есть предпочтительный биом, и оно получает постоянный урон, если окажется в неподходящем или перенаселенном биоме.
В самом начале игрок получает зародыш химеры, который нужно развивать и делать сильнее, добавляя фрагменты других существ. Для этого игрок должен набрать достаточное количество энергии связи из разных источников.
Игра заканчивается, когда игрок доводит здоровье химеры противника до нуля.
Обучение игре в Chimera
Chimera — это карточная игра с неполной информацией и большим пространством состояний, поэтому мы думали, что модели будет сложно научиться в нее играть. Особенно учитывая то, что мы собирались применять относительно простую модель. На вооружение был взят подход, использовавшийся в ранних игровых агентах, таких как AlphaGo, когда сверточную нейронную сеть (CNN) обучают предсказывать вероятность выигрыша по произвольному игровому состоянию. Первую модель мы обучили на играх с произвольными ходами, а затем заставили агента играть против самого себя, собирая данные для обучения последующих его итераций. С каждым разом качество данных повышалось, как и игровые навыки агента.
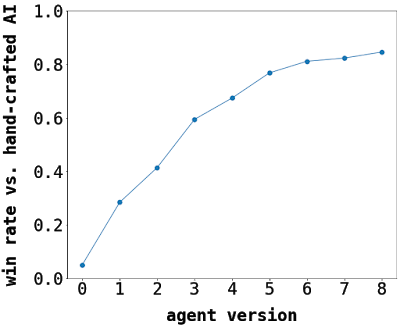 Результаты игры агента против лучшего написанного вручную ИИ-алгоритма по мере обучения. Исходная нулевая версия агента делала ходы случайно.
Результаты игры агента против лучшего написанного вручную ИИ-алгоритма по мере обучения. Исходная нулевая версия агента делала ходы случайно.В качестве игрового состояния, которое подается на вход CNN, мы выбрали кодированное изображение. Такой подход оказался эффективнее всех процедурных агентов и нейронных сетей других типов (например, полносвязных). Выбранная архитектура модели достаточно компактная, чтобы ее можно было выполнять на ЦП за разумное время. Поэтому мы загрузили веса модели и запускали агент в реальном времени в клиенте игры Chimera на платформе Unity Barracuda.
 Пример кодированного игрового состояния, на котором обучалась нейронная сеть.
Пример кодированного игрового состояния, на котором обучалась нейронная сеть. Помимо принятия игровых решений модель использовалась, чтобы показывать приблизительную вероятность выигрыша игрока во время игры.
Помимо принятия игровых решений модель использовалась, чтобы показывать приблизительную вероятность выигрыша игрока во время игры.Настройка баланса в Chimera
Наш подход помог смоделировать на много миллионов больше матчей, чем живые игроки смогли бы сыграть за тот же период времени. Собрав данные из игр самых успешных агентов, мы проанализировали результаты и нашли дисбаланс между двумя придуманными нами игровыми колодами.
Первая, Evasion Link Gen, состояла из заклинаний и существ со способностями, которые давали дополнительную энергию связи, необходимую для развития химеры. В ней также были заклинания, позволявшие существам уклоняться от атак. В колоде Damage-Heal находились существа с разными показателями силы и заклинаний, лечившие и наносившие незначительный урон. Мы думали, что эти колоды будут примерно равносильны, однако Evasion Link Gen побеждала в 60% случаев при игре против Damage-Heal.
Собрав разные показатели по биомам, существам, заклинаниям и развитию химер, мы сразу увидели две вещи:
Развитие химеры давало явное преимущество — агент, развивший свою химеру больше своего оппонента, побеждал в большинстве игр. При этом среднее число эволюционных этапов на игру не соответствовало нашим ожиданиям. Мы хотели сделать развитие ключевой составляющей игровой механики и увеличить общее среднее количество эволюционных этапов.
Существо Тирекс оказалось чересчур сильным. Его появление в игре тесно коррелировало с победами, и модель всегда старалась играть с Тирексом, невзирая на штрафы за его вызов в неподходящий или перенаселенный биом.
На основании этих наблюдений мы внесли в игру некоторые изменения. Чтобы поощрять развитие химеры, мы сократили количество энергии связи, необходимой для эволюции, с трех до единицы. Мы также добавили период восстановления для Тирекса: теперь после любого действия ему приходилось ждать в два раза дольше, чтобы выполнить следующее действие.
Повторив игру модели против самой себя с обновленными правилами, мы заметили, что игра изменилась в нужном направлении — среднее число эволюционных этапов увеличилось, а Тирекс перестал доминировать.
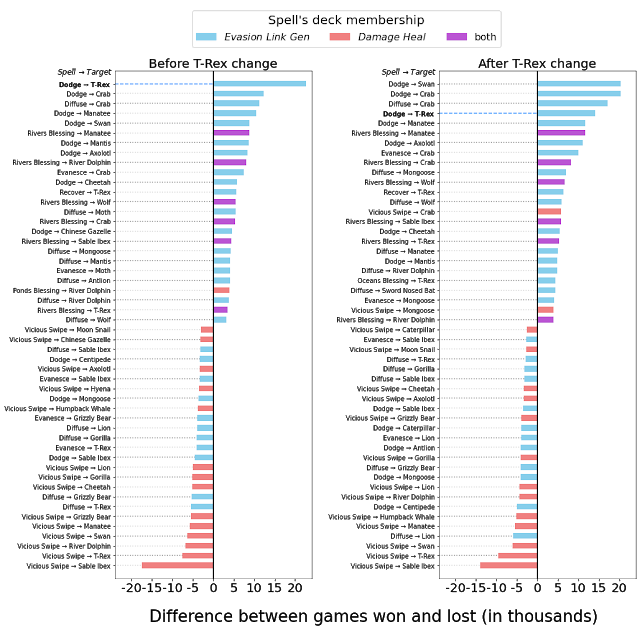 Сравнение влияния Тирекса до и после корректировки баланса. На диаграммах показано количество выигранных (или проигранных) игр, когда в колоде используется определенное заклинание (например, заклинание для уклонения, повышающее характеристики Тирекса). Слева: до изменений Тирекс оказывал серьезное влияние по всем оцениваемым показателям — самый высокий коэффициент выживаемости, наибольшая вероятность вызова даже при штрафах, самое часто поглощаемое существо при победах. Справа: после изменений Тирекс стал гораздо менее мощным.
Сравнение влияния Тирекса до и после корректировки баланса. На диаграммах показано количество выигранных (или проигранных) игр, когда в колоде используется определенное заклинание (например, заклинание для уклонения, повышающее характеристики Тирекса). Слева: до изменений Тирекс оказывал серьезное влияние по всем оцениваемым показателям — самый высокий коэффициент выживаемости, наибольшая вероятность вызова даже при штрафах, самое часто поглощаемое существо при победах. Справа: после изменений Тирекс стал гораздо менее мощным.Ослабив Тирекса, мы снизили зависимость колоды Evasion Link Gen от чрезмерно сильного существа. Но даже при этом соотношение побед сохранилось на уровне 60/40 вместо 50/50. При детальном рассмотрении журналов отдельных игр стало видно, что они часто велись без продуманной стратегии. Проанализировав данные снова, мы обнаружили ряд других областей, где можно было внести изменения.
Мы увеличили начальный уровень здоровья обоих игроков, а также эффективность лечащих заклинаний. Это помогло увеличить продолжительность игр и разнообразить стратегии. В частности, это позволило игроку с колодой Damage-Heal держаться достаточно долго, чтобы получить преимущество от своей стратегии лечения. Чтобы игроки с умом подходили к вызову существ и их размещению, мы увеличили штрафы за использование существ в неподходящих или перенаселенных биомах. Наконец, мы сократили разрыв между самыми сильными и слабыми существами, немного изменив атрибуты.
С новыми корректировками мы получили итоговые сбалансированные показатели для двух колод:

Заключение
Обычно на поиск дисбаланса в новых играх могут уходить месяцы тестирования. Рассмотренный здесь подход помог нам не только выявить возможные недостатки баланса, но и внести корректировки для их устранения за считаные дни. Мы выяснили, что относительно простая нейронная сеть способна обеспечить высокую эффективность при игре против человека и традиционного ИИ. Такие агенты можно использовать и в других целях, например при обучении новых игроков и поиске неочевидных стратегий. Мы надеемся, что эта работа вдохновит на дальнейшее изучение возможностей машинного обучения в разработке игр.
Слова благодарности
Этот проект был реализован при поддержке множества людей. Мы благодарим Райана Поплина, Максвелла Ханнамана, Тейлора Стейла, Адама Принса, Михала Тодоровича, Сюэфан Чжоу, Аарона Каммарата, Эндипа Тура, Транга Ле, Эрин Хоффман-Джон и Колина Бозвела. Спасибо всем, кто участвовал в игровом тестировании, давал советы по игровому дизайну и оставлял ценные отзывы.
