[Перевод] Лучший Способ Программирования (Better way To Code)
От переводчика:
Я не являюсь ни профессиональным программистом ни профессиональным переводчиком, но появление описанного в статье инструмента от создателя популярной библиотеки D3.js произвело на меня сильное впечатление.
С удивлением обнаружил, что на Хабре, да и вообще в русскоязычном интернете, более года несправедливо игнорируют данный инструмент. Поэтому решил, что просто обязан внести свой вклад в развитие искусства программирования, в JavaScript в частности.
Знакомьтесь, d3.express, интегрированная исследовательская среда.
(с 31 января 2018 г d3.express зовется Observable и живет на beta.observablehq.com)
Если вам когда-либо приходилось тупить над своим кодом или разбираться в чужом, тогда вы не одиноки. Эта статья для вас.
Последние лет восемь я разрабатывал инструменты для визуализации информации. Самым удачным результатом моих усилий стала js-библиотека D3. Однако опасность столь долгой разработки инструментария в том, что ты забываешь зачем ты это делаешь: инструмент становится самоцелью, польза от его применения уходит на второй план.
Предназначение инструмента визуализации — построение визуализаций. Но в чем же цель визуализации? Слово Бену Шнейдерману (Per Ben Shneiderman):
«Результат визуализации — это озарение, а не картинки»
Визуализация — это ключ. Ключ к озарению. Способ подумать, понять, раскрыть и донести что-то об этом мире. Если мы видим в визуализации только задачу нахождения визуальной расшифровки, то мы игнорируем массу других задач: нахождение значимых данных, их очистка, трансформация в эффективные структуры, статистический анализ, моделирование, объяснение наших расследований…
Эти задачи часто решаются с помощью кода. Увы, но программирование чертовски сложно! Само название уже предполагает непостижимость. Слово «программирование» («Code») происходит от машинного кода: низкоуровневых инструкций, выполняемых процессором. С тех пор код стал более дружелюбным, но предстоит еще долгий путь.

Призрак в доспехах (Ghost in the Shell) (1995)
В качестве яркого примера вот Баш-команда для генерации фоновой картограммы плотности населения Калифорниии. Она всего лишь возвращает упрощенную геометрию. Еще несколько команд нужно для получения SVG.

Это не машинный код. С точки зрения машины это очень даже высокоуровневое программирование. С другой стороны это не назовешь человеческим языком: странные знаки препинания, непонятные аббревиатуры, уровни вложенности. И два языка: JavaScript неуклюже вплетенный в Bash.
Брет Виктор дает нам такое краткое определение программирования:
Программирование — это слепое манипулирование символами
Под «слепым» он имеет в виду невозможность видеть результаты наших манипуляций. Мы можем отредактировать программу, перезапустить ее и увидеть результат. Но программы сложны и динамичны, мы не имеем возможность прямого, непосредственного наблюдения за результатами нашего редактирования.
Под «символами» он имеет в виду то, что мы не прямо манипулируем выводом нашей программы, а вместо этого работаем с абстракциями. Эти абстракции могут могут быть эффективными, но они также могут быть сложными в плане контроля. В определении Дональда Нормана это пропасть оценки и пропасть исполнения (Gulf of Evaluation and Gulf of Execution).
Но очевидно, что некоторые скрипты легче читаются, чем другие. Один из симптомов нечеловеческого кода — это «спагетти»: код без структуры и модульности, где для того, чтобы понять одну часть программы ты должен понимать всю программу в целом. Это часто вызвано общим изменяемым состоянием (shared mutable state). Там где часть структуры модифицирована различными частями программы, очень трудно предположить каково его значение.
Ну в самом деле, откуда мы знаем что именно делает программа? Если мы не можем отследить все состояния среды в наших головах, чтения кода недостаточно. Мы используем логи, дебаггеры и тесты, но эти инструменты ограничены. Дебаггер, например, может показывать только несколько значений на определенный момент времени. Мы продолжаем испытывать огромнейшие трудности в понимании кода, и можем воспринимать как чудо, если что-то в принципе работает.
Несмотря на эти проблемы мы все же пишем код для для бессчетного количества приложений, больше, чем когда либо. Почему? Может мы мазохисты? (Может быть) Мы не можем поменяться? (Частично.) Неужели не существует лучшего решения?
В общем — и это критическое определение — нет. Код — часто наилучший инструмент в нашем арсенале, потому что он самый общедоступный (general) из того, что мы имеем; у кода есть почти неограниченная выразительность. Альтернативы коду, так же как и высокоуровневые программные интерфейсы и языки, нормально себя чувствуют в специфических областях. Но эти альтернативы приносят в жертву универсальность, ради лучшей эффективности в этих областях.
Если вы не можете определить область (constrain the domain) вероятнее всего вы не сможете найти жизнеспособную альтернативу коду. Не существует универсального замещения, по крайней мере пока люди главным образом думают и общаются посредством языка. Очень тяжело определить область науки. Наука фундаментальна: изучать мир, выводить смысл из эмпирических наблюдений, моделировать системы, рассчитывать количественные величины.
Инструмент для содействия открытиям должен быть способен выражать новые, оригинальные мысли. Как мы не используем фразовые шаблоны для составления написанного слова, так мы не можем быть ограничены в графических шаблонах для визуализации или ограниченным списком формул для статистического анализа. Нам нужно больше, чем конфигурация. Нам нужна композиция примитивов в формировании нашего собственного дизайна.
Если наша цель — помочь людям обрести озарение от наблюдения, мы должны рассмотреть проблему того как люди пишут код. То, что Виктор высказывал о математике можно применить и к коду:
Весь арсенал для понимания и прогнозирования количественных показателей нашего мира не должен быть ограничен нелепыми (freakish) трюками по манипулированию абстрактными символами
Улучшать нашу способность программировать — это не только делать рабочие процессы более удобными или эффективными. Это давать возможность людям лучше понимать их мир.
Представляем Observable
Если мы не можем избавиться от кода, можем ли мы хотя бы сделать его легче для людей, с нашими сосископодобными пальцами и граничного размера мозгами?
Для выяснения этого вопроса я занимаюсь построением интегрированной исследовательской среды, называемой Observsable. Она служит для анализа данных, для понимания систем и алгоритмов, для обучения и представления различных техник программирования, а также для шаринга интерактивных наглядных объяснений. Для того, чтобы легче делать визуализации и, в свою очередь, легче делать наши открытия мы сперва должны сделать легче процесс программирования.
Я не могу претендовать на то, что сделаю процесс программирования легче. Идеи, которые мы хотим выразить, исследовать и объяснить могут быть несокращаемо сложными. Но сокращая когнитивную нагрузку при программировании, мы можем делать анализ количественных явлений доступных для более широкой аудиенции.
1. Реактивность
Первый принцип Observable — это реактивность. Вместо того, чтобы выдавать команды для изменения общего состояния, каждая часть состояния в реактивной программе определяет как она рассчитывается, а среда управляет их оценкой; среда выполнения распространяет полученное состояние. Вместо того, чтобы выдавать команды для изменения общего состояния, каждая часть состояния в реактивной программе определяет, как она рассчитывается, а среда сама управляет их оценкой. Среда сама распространяет производное состояние. Если вы пишите формулы в Excel, вы осуществляете реактивное программирование.
Вот простой блокнот в Observable чтобы проиллюстрировать реактивное программирование. Немного напоминает консоль разработчика в браузере кроме того, что наша работа сохраняется автоматически и мы можем побывать здесь в будущем или поделиться работой с другими. И еще оно реактивное.

в императивном программировании c=a+b устанавливает c равным a+b. Это присвоение значения. Если a или b меняются, c остается в прежнем значении пока мы не выполним новое присвоение значения для c. В реактивном программировании c=a+b — это описание переменной. Это значит, что c всегда равно a+b, даже если a или b поменяется. Среда сама поддерживает актуальное значение c.
Как программисты, мы теперь заботимся только о текущем состоянии. Среда сама управляет изменениями состояния. Это может показаться незначительной вещью здесь, но в больших программах это снимает с вас существенное бремя.
Исследовательская среда должна делать больше, чем складывать несколько чисел, давайте попробуем поработать с данными. Что бы загрузить данные — нескольколетняя статистика цен на акции Apple — будем использовать d3.csv. Оно использует Fetch API для загрузки файла с GitHub и потом парсит его чтобы выдать нам массив объектов.

require ('d3') и запрос данных — асинхронны. Императивный код мог бы стать проблемой, но здесь мы четко заметили: ячейки, которые ссылаются на «d3» не вычисляются пока данные не будут загружены.
Реактивность означает, что мы можем писать большинство асинхронного кода как если бы он был синхронным.
Как же выглядят данные? Давайте посмотрим:

d3.csv — консервативно и не делает вывод о типах данных таких как числа и строки, поэтому все поля являются строками. Нам нужны более точные типы. Мы можем конвертировать поле «close» в число, применив к нему оператор (+) и тут же увидим эффект: фиолетовая строка становится зеленым числом.

Что бы пропарсить дату нужно немного больше работы, поскольку JavaScript нативно не поддерживает такой формат.
Представим у нас есть функция parseTime, которая парсит строку и возвращает сущность «Date». Что случится, если мы вызовем ее?

Оп! Выкинуло ошибку. Но ошибка одновременно и локальная и временная: другие ячейки не затронуты и она пропадет когда мы определим pareseTime. Поэтому блокноты в Observable не только реактивные, они еще и структурированы. Глобальных ошибок больше не существует.
При определении parseTime мы снова видим эффект: данные перезагружены, пропарсены и отображены. Мы все еще манипулируем абстрактными символами, но по крайней мере делаем это менее слепо.

Теперь мы можем запросить данные, скажем для вычисления временнОго диапазона:

Ой, мы забыли дать имя данным! Давайте исправим:

Тут мы обнаруживаем другую «человеческую» фичу: ячейки могут быть написаны в любом порядке.
Визуальный вывод
Как и в консоли разработчика, результат выполнения ячейки в Observable видно сразу же под кодом. Но в отличие от консоли ячейки Observable могут выводить графические пользовательские интерфейсы! Давайте визуализируем наши данные на простом линейном графике.
Сначала мы определим размер графика: width, height и margin.

Теперь масштаб: временнОй для x и линейный для y.

И наконец SVG элемент. Поскольку это определение сложнее, чем наши предыдущие ячейки, мы можем использовать фигурные скобки ({и}) для определения его как блока, а не выражения:

DOM.svg — метод для удобного вызова document.createElementNS. Он возвращает новую SVG ноду с определенной шириной и высотой. Давайте расширим его, чтобы использовать d3-selection для манипуляции DOM: 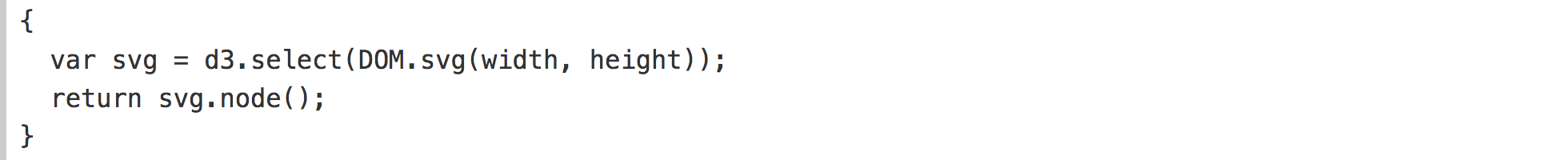
Я не могу показать код и график одновременно из-за ограниченого размера экрана, поэтому давайте сначала посмотрим на график по мере его сборки. Это дает ощущение визуальной обратной связи, которую вы получаете по мере определения трех основных компонентов графика: осей x, y и линии.

Эта анимация была сделана путем ввода каждой строки кода по порядку (кроме return-а, поскольку он нужен для того, чтобы все видеть):

Это простой график, но уже топология программы стает более сложной. Вот направленный ациклический граф ссылок, сам сделанный в Observable, используя GraphViz:
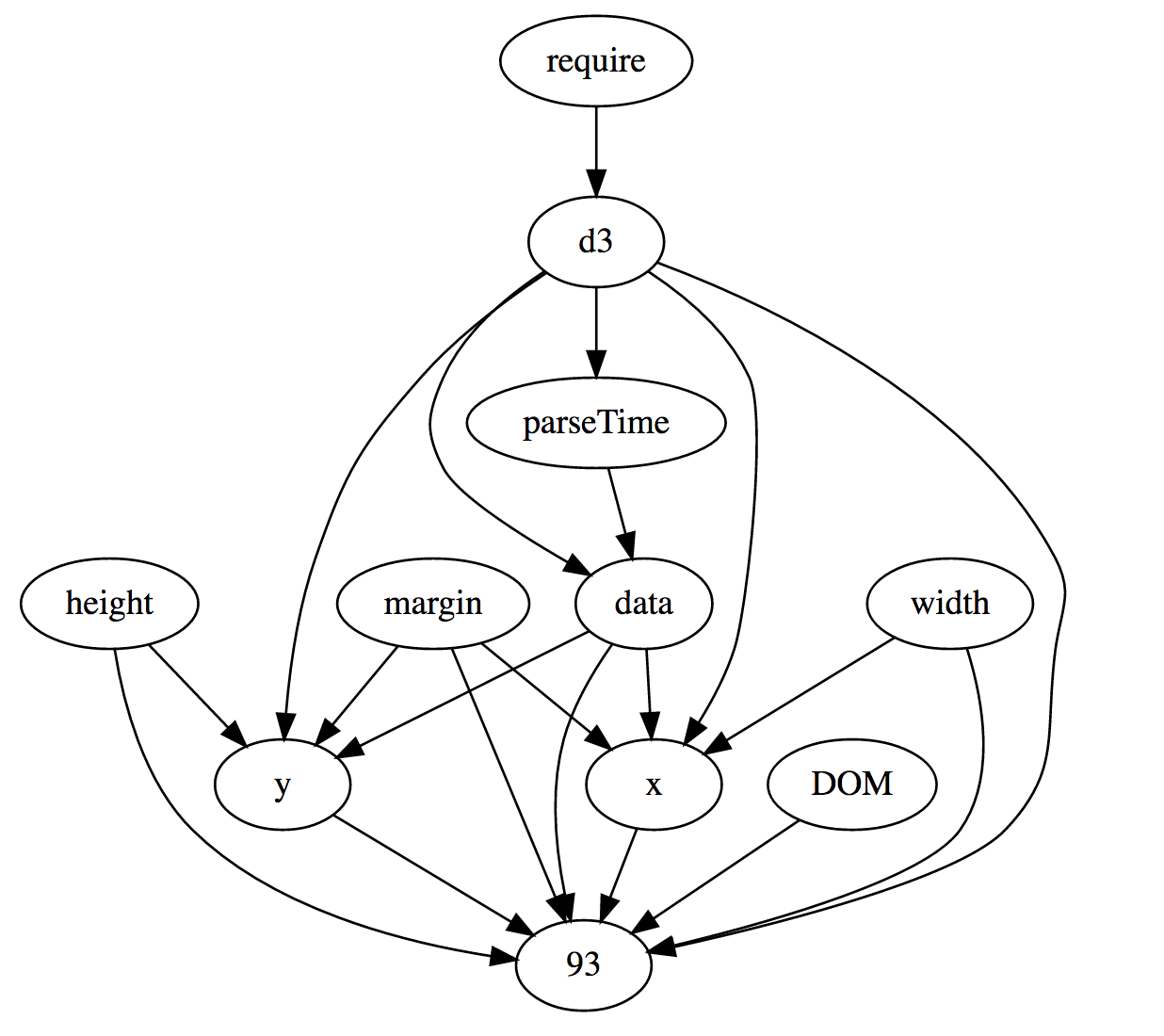
Узел 93 — это SVG элемент. Несколько наблюдений: Cейчас очень легко сделать этот график отзывчивым. Объекты width, height и margin являются константами, но если бы они были динамическими, оси и сам график обновлялись бы автоматически. Похожим способом также легко сделать график динамическим переопределив данные (data). Мы скоро увидим это на примере с потоковыми данными.
Но давайте поближе взглянем на реактивный код. В императивном программировании определения переменных размазывается по всему коду, а не делается в одном месте. Например мы можем собрать масштабирование для шкалы x сразу после загрузки страницы, но отложить определение домена до получения данных.
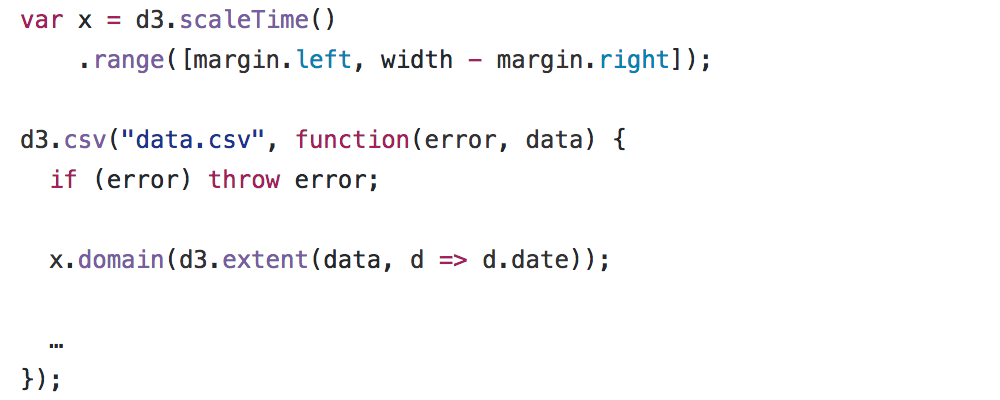
Такое фрагментированное определение может перетасовываться с другими данными и влиять на чистоту кода. Также это благоприятсвует повторному использованию: самодостаточные, бесстатусные определения легче копировать/импортировать в другие документы.
Вы можете создавать какие угодно DOM — HTML, canvas, WebGL, использовать какие угодно библиотеки.
Вот график, сделанный с помощью Vega Lite:

Анимация
Как насчет Canvas? Скажем нам нужен глобус. Мы можем загрузить границы стран мира и применить ортогональную проекцию.

(Mesh, если интересно, это комбинированные границы, представленные как ломаная прямая. Я использую метод mesh, потому что этот набор данных содержит многоугольники, и он немного быстрее и красивее для рендеринга таких объектов.)

Мощной особенностью реактивного программирования является то, что мы можем быстро заменить статическое определение, такое как ортогональная проекция фиксированного размера, динамическим определением, например вращающаяся проекция. Среда сама будет перерисовывать canvas всякий раз, когда изменяется проекция.

Динамические переменные в Obsesrvable реализованы как генераторы, функции, возвращающие множественные значения. Например, генератор с циклом while-true выдает бесконечный поток значений. Среда извлекает новое значение из каждого активного генератора до шестидесяти раз в секунду.
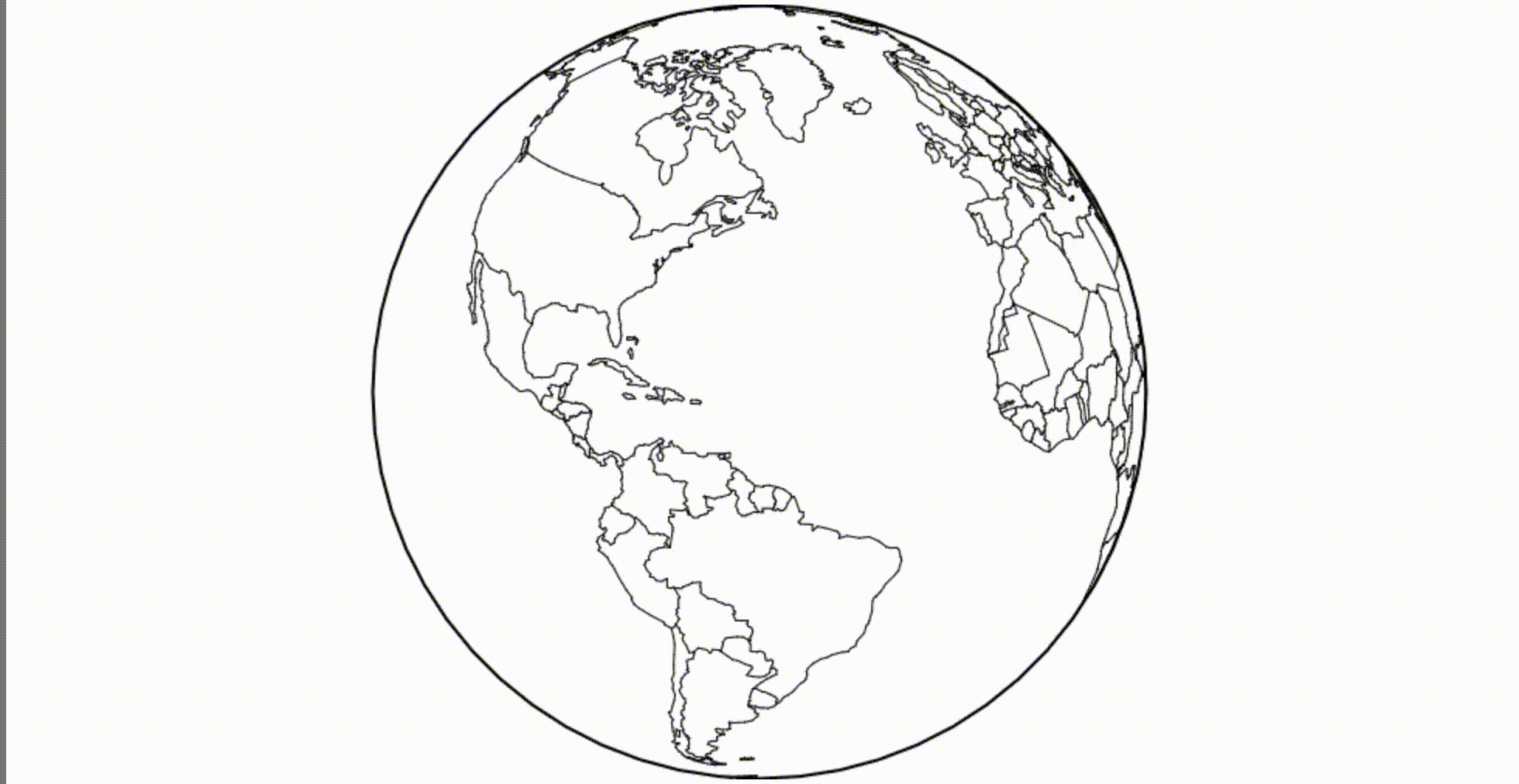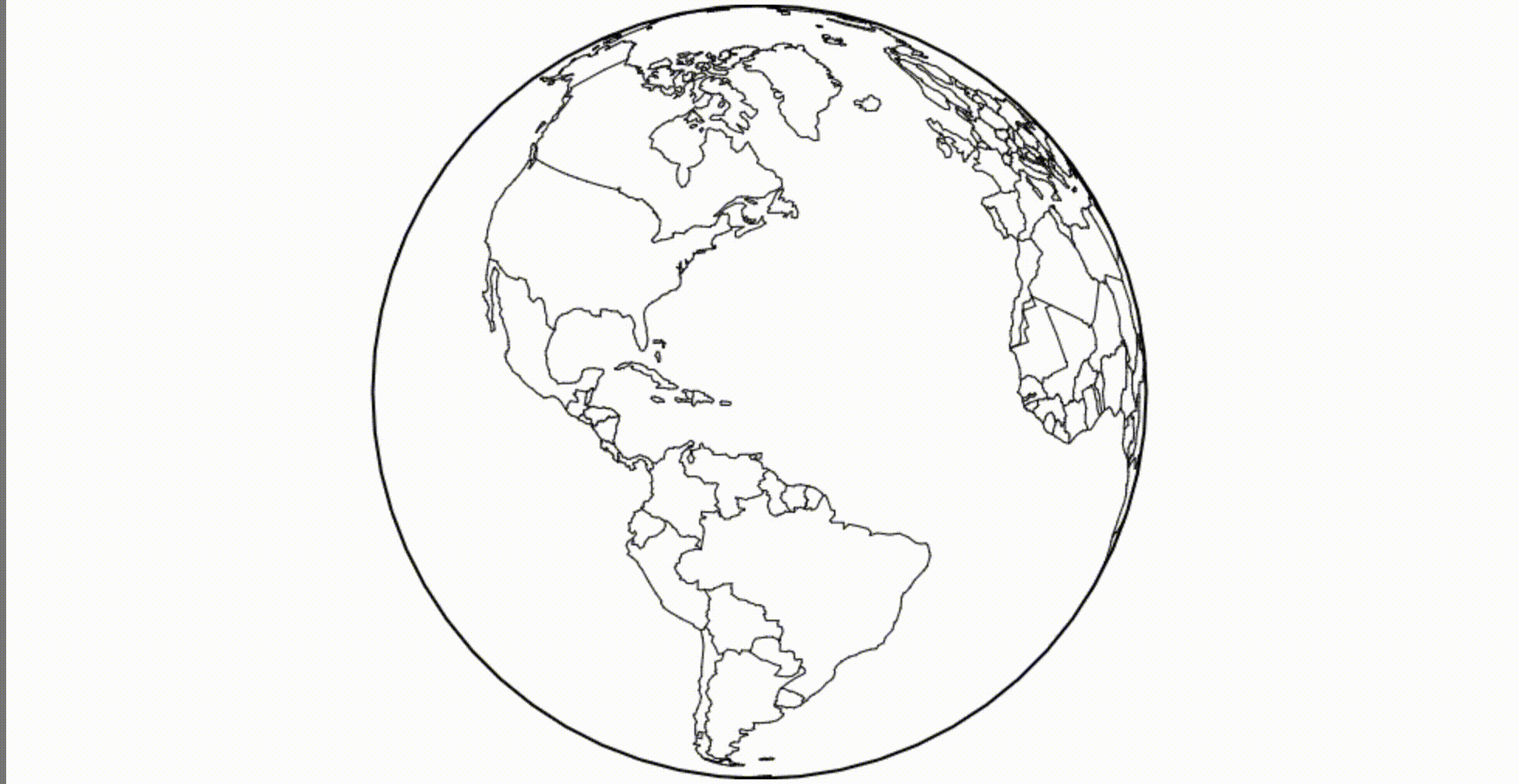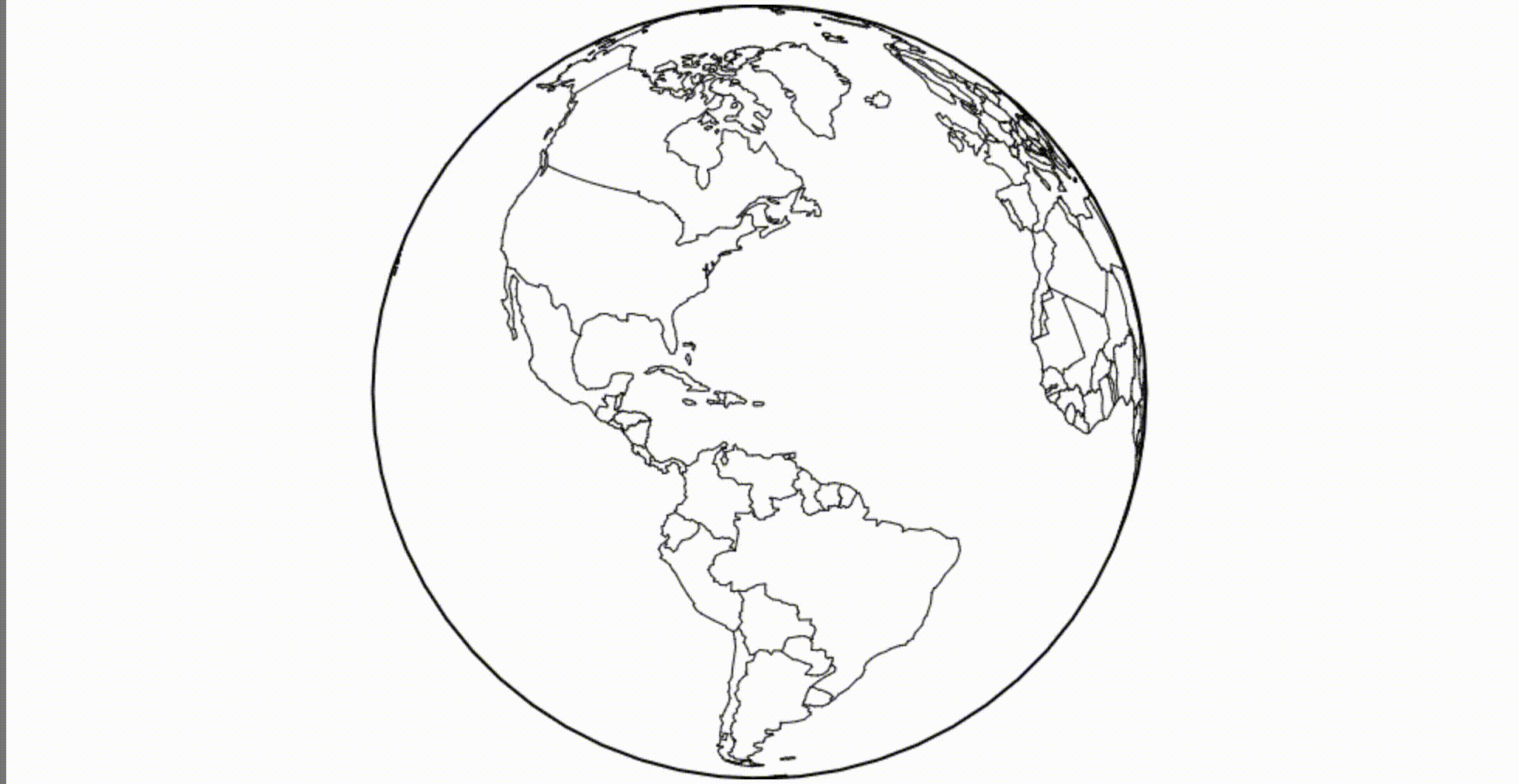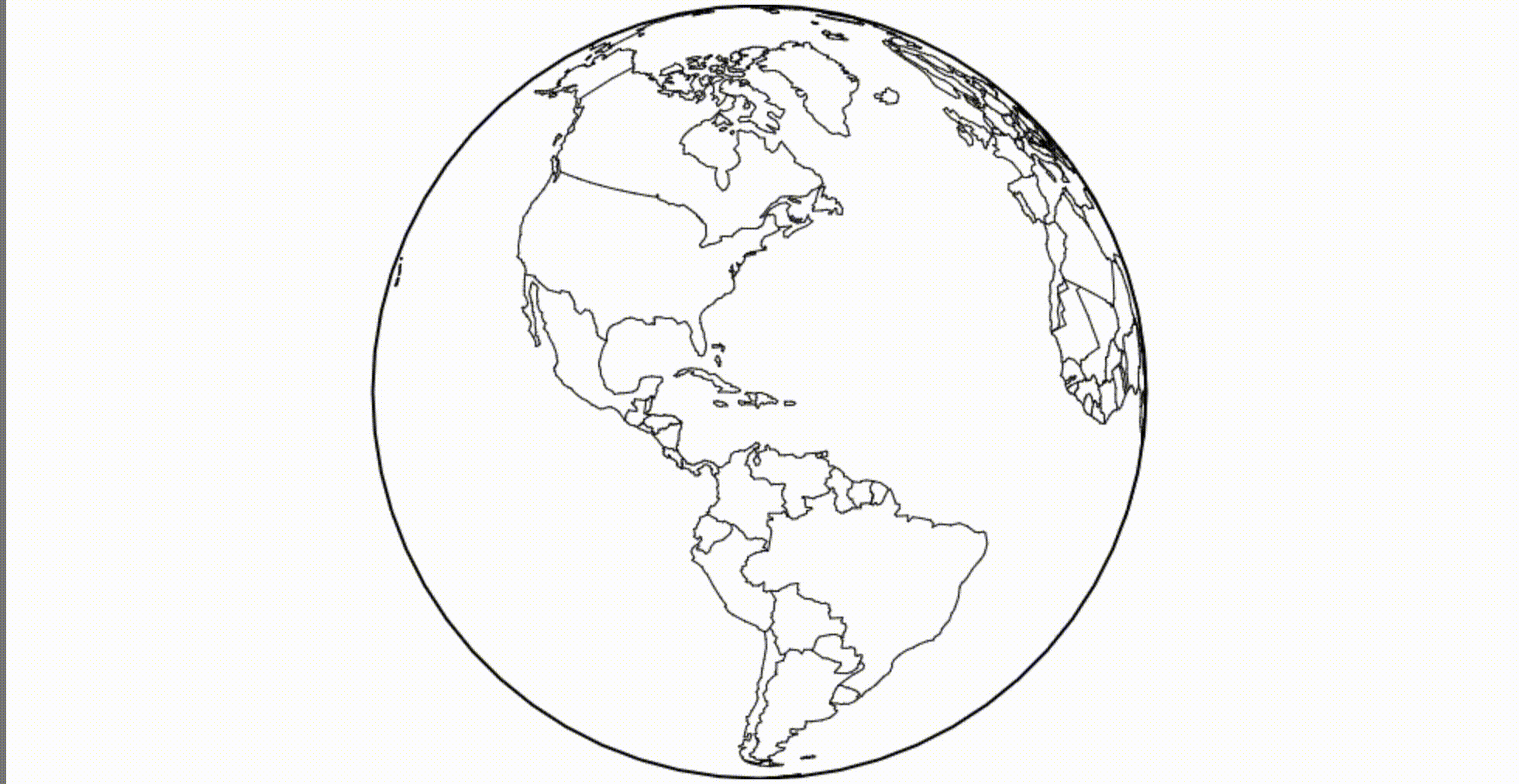
(смотрится лучше на 60 FPS)
Определение нашего canvas создает новый canvas каждый раз, когда он запускается. Это может быть приемлемым, но мы можем получить лучшую производительность, обработав холст повторно. Предыдущее значение переменной отображается как this.

Ой! Используя старый canvas мы размываем свой глобус: 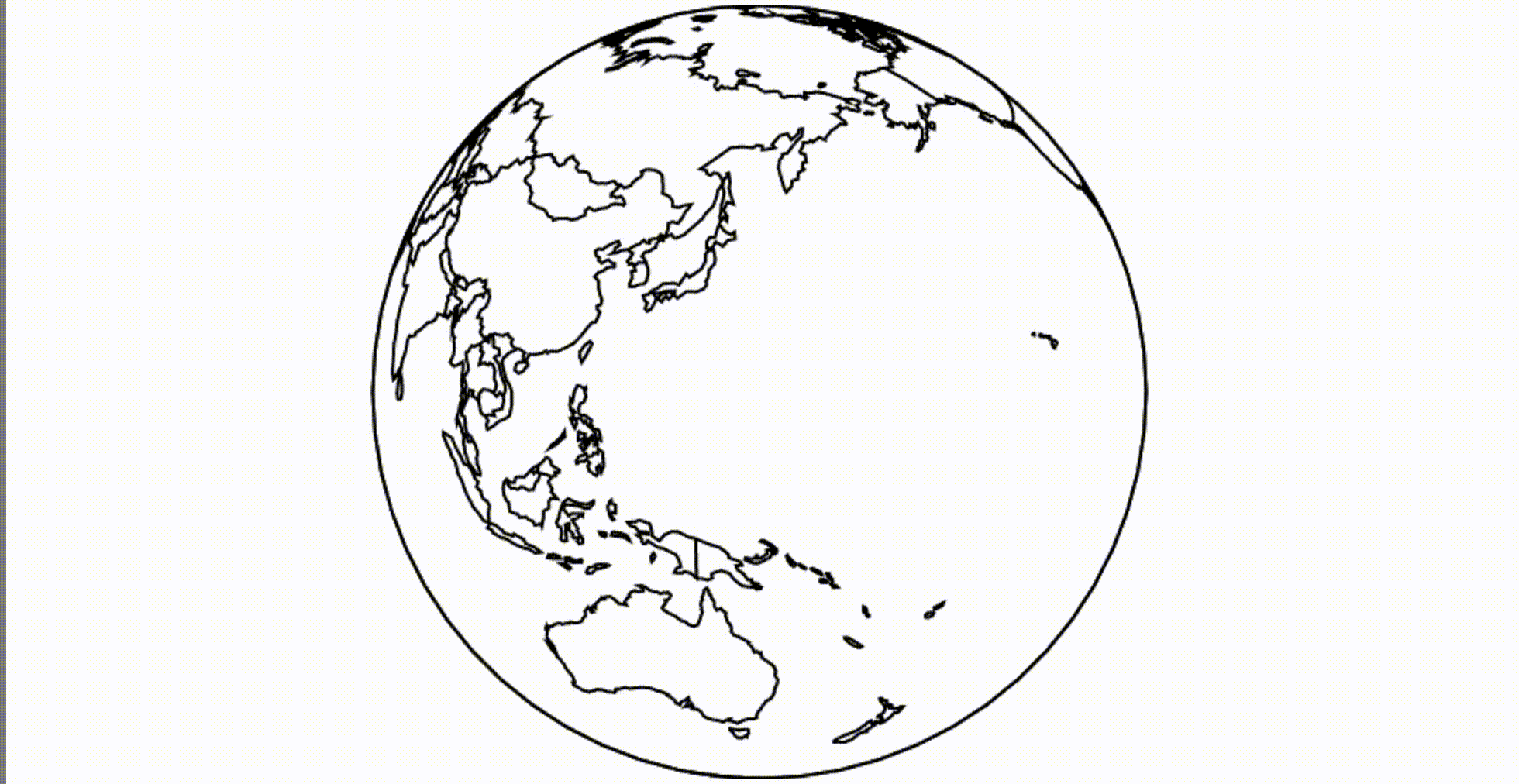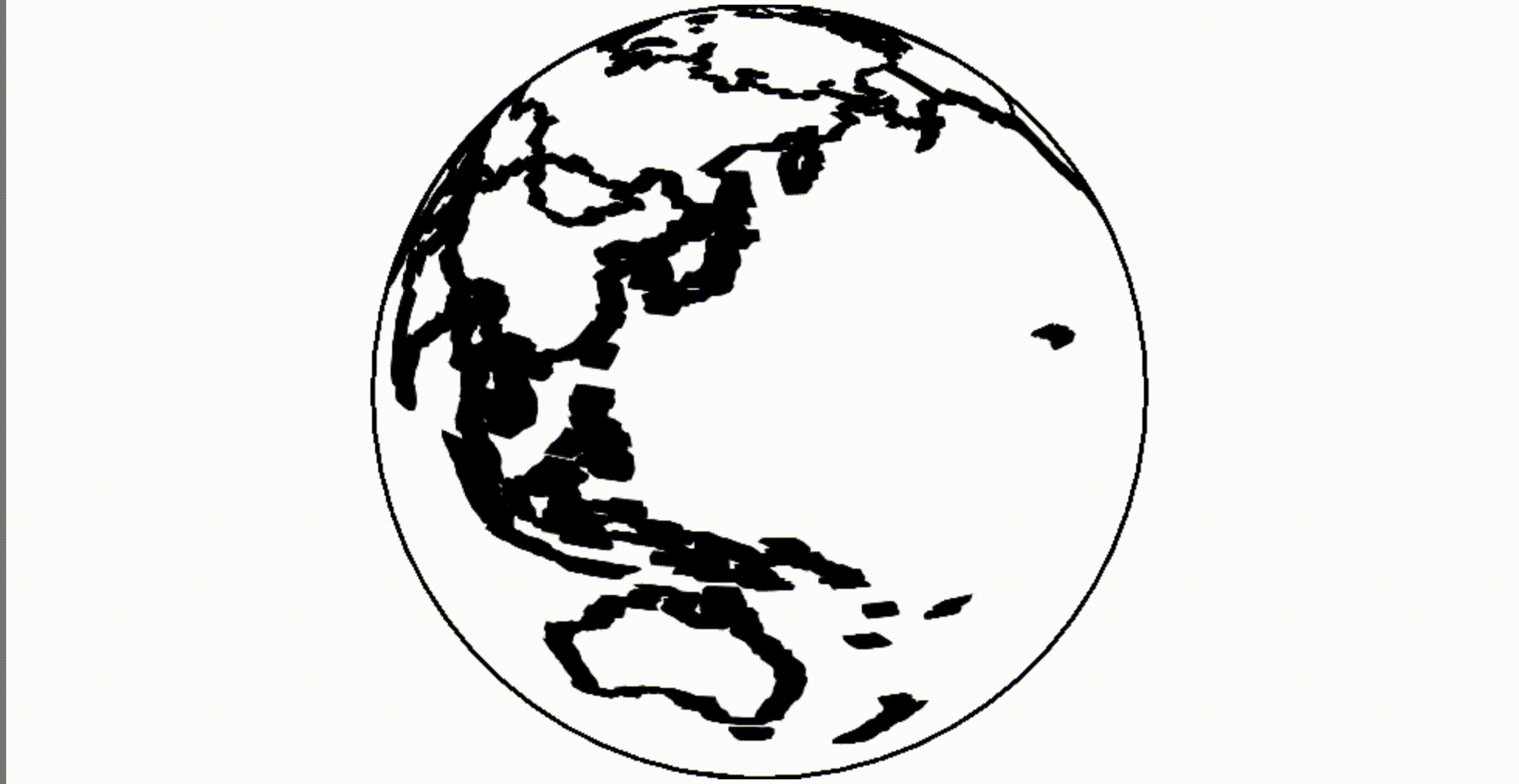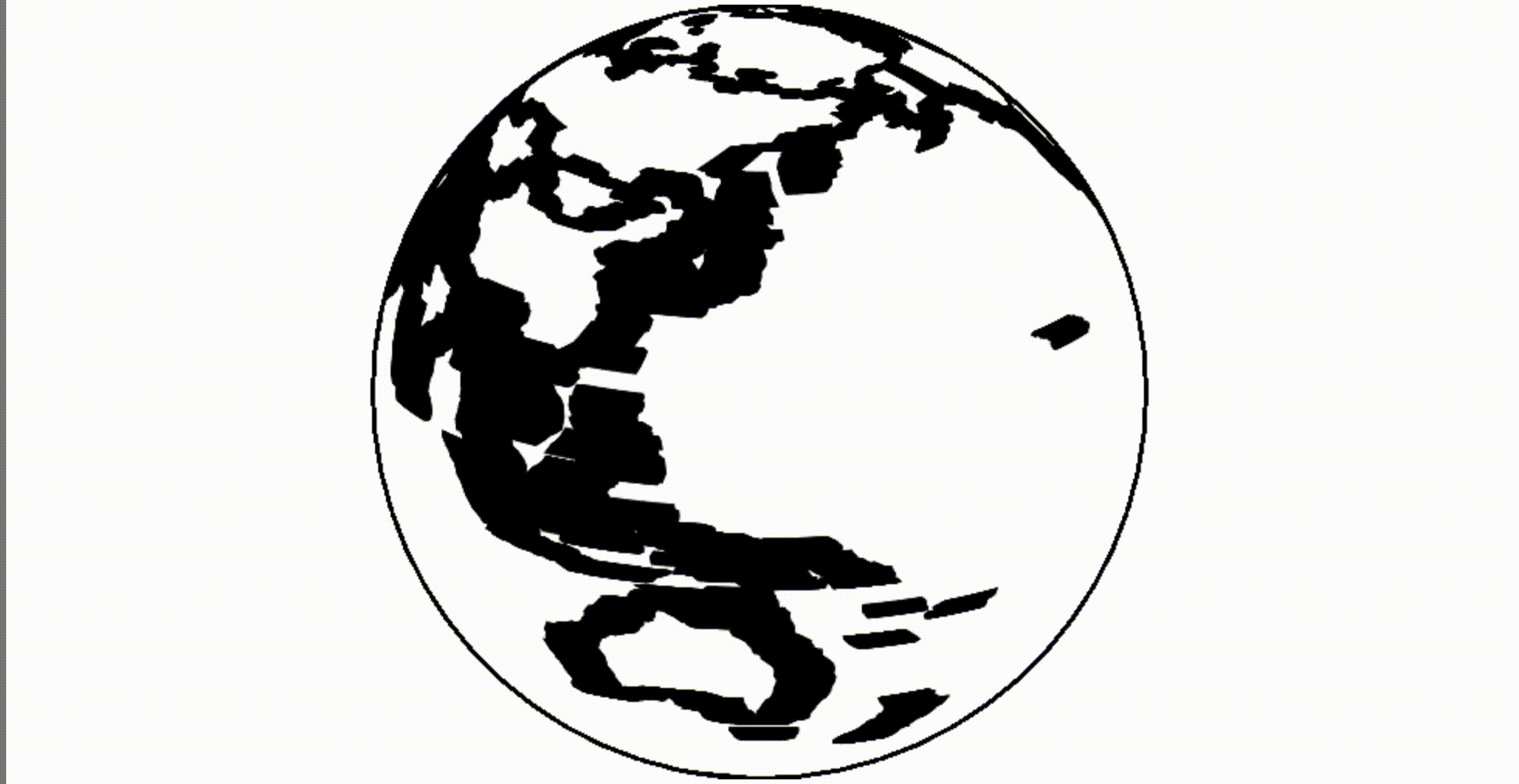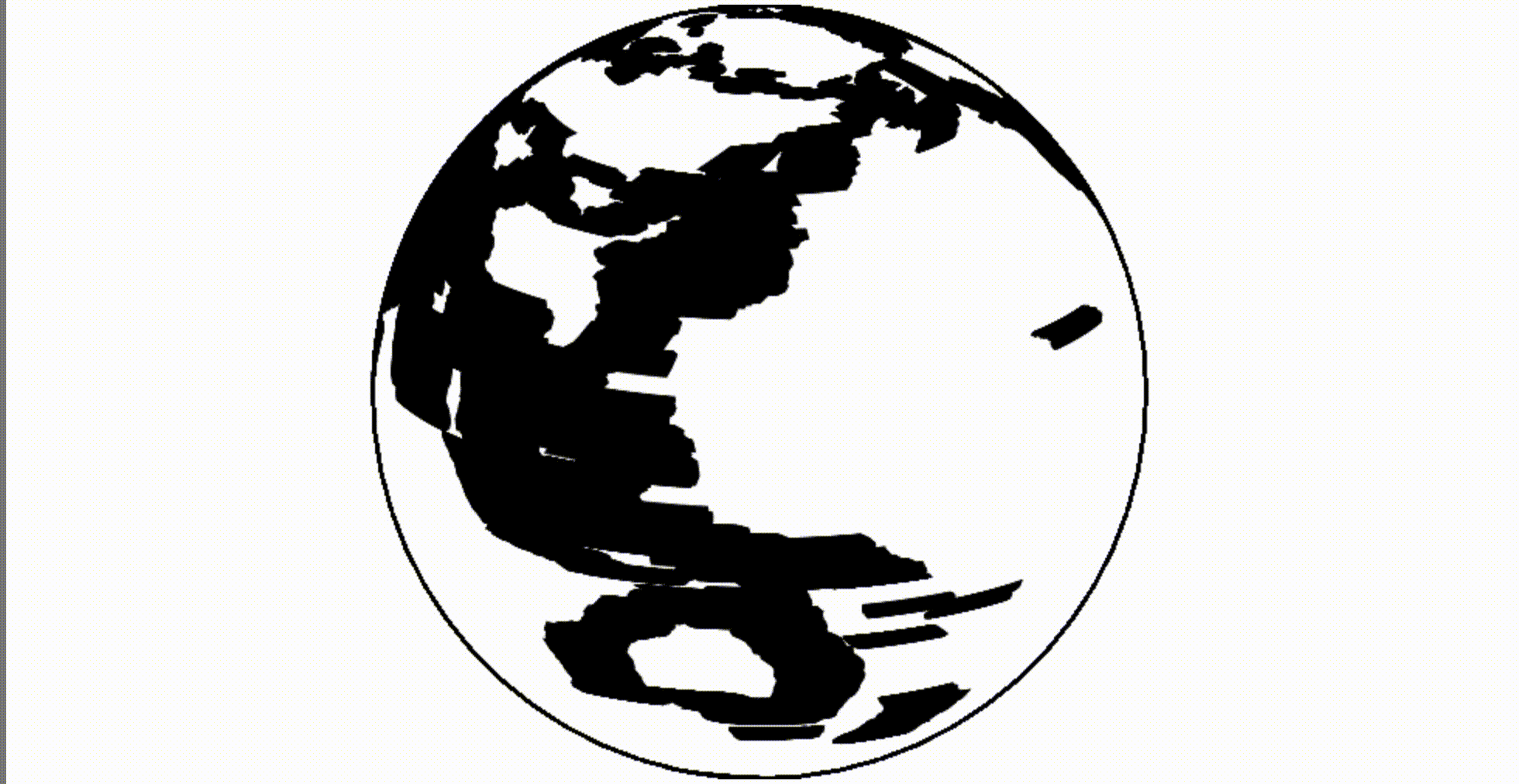
Глюк легко исправляется очисткой canvas перед перерисовкой.

Таким образом, немного усложняя, вы можете повысить производительность, а получившаяся анимация имеет незначительные накладные расходы по сравнению с ванильным JavaScript.
Взаимодействие
Если генераторы хороши для сценариев анимации, как насчет взаимодействия? Генераторы снова в помощь! Только теперь наши генераторы асинхронны, возвращая промисы, которые разрешается всякий раз, когда появляется новый ввод.
Чтобы сделать вращение интерактивным, давайте сначала определим ввод диапазона. Затем мы подключаем его к генератору, который выдает текущее значение входа всякий раз, когда он изменяется. Мы могли бы реализовать этот генератор вручную, но есть удобный встроенный метод, называемый Generators.input.

Теперь мы подставляем значение в качестве долготы для вращения интерактивного глобуса:
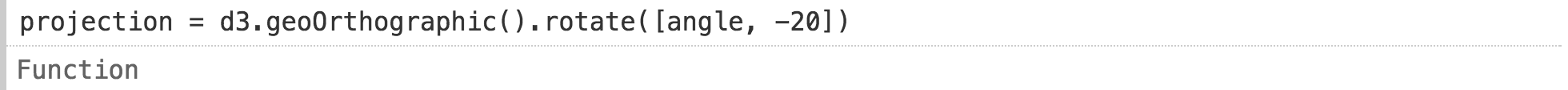
Это уже краткое определение пользовательского интерфейса. Но мы его можем еще уменьшить, сворачивая определения range и angle в одну ячейку, используя оператор Observable viewof. Оно показывает ввод для пользователя, но для кода представляется текущее значением.

Способность отображать произвольные DOM и выставлять произвольные значения коду делает интерфейсы в Observable очень, ну… яркими. Вы не ограничены ползунками и выпадающими меню. Вот колор пикер Cubehelix, реализованный как таблица слайдеров, по одному для каждого цветового канала.

Когда вы тащите ползунок, его значение обновляется на соответствующем выходе, а затем генератор выводит текущий цвет.

Мы можем создать любые графические интерфейсы, которые мы захотим. И мы можем задизайнить умные программные интерфейсы, чтобы представить их значения коду. Это позволяет быстро создавать мощные интерфейсы для изучения данных. Вот гистограмма, показывающая поведениенескольких сотен акций за пятилетний период. (Я сократил код, но он похож на этот.)
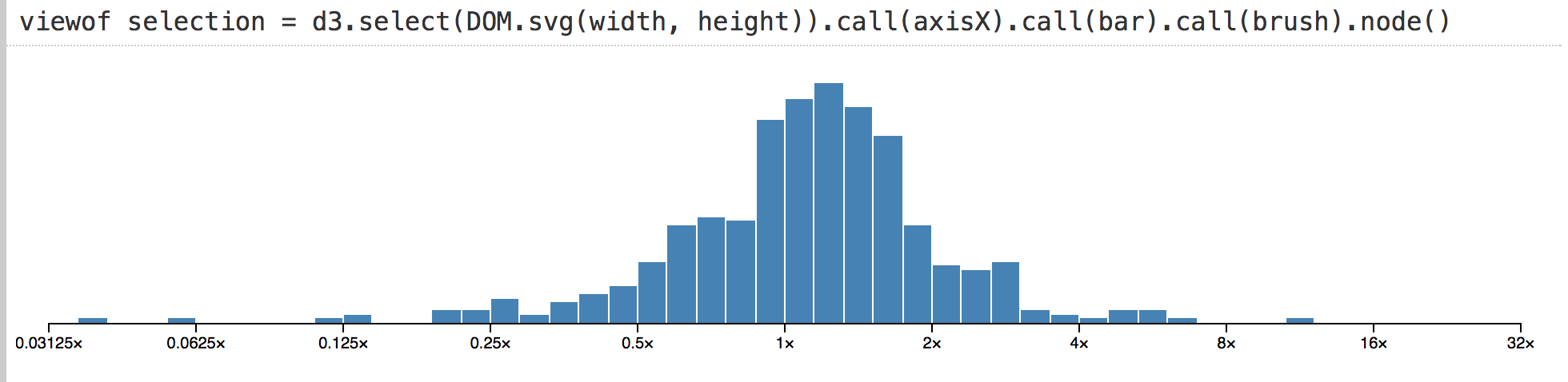
В других средах гистограмма, подобная этой, может быть визуальным тупиком. Вы можете посмотреть на него, но для проверки базовых значений требуется отдельно запрашивать данные в коде. В Obsesrvable мы можем быстро дополнить визуализацию, и показать выборку в интерактивном режиме. Затем мы можем видеть данные под курсором путем непосредственной манипуляции.
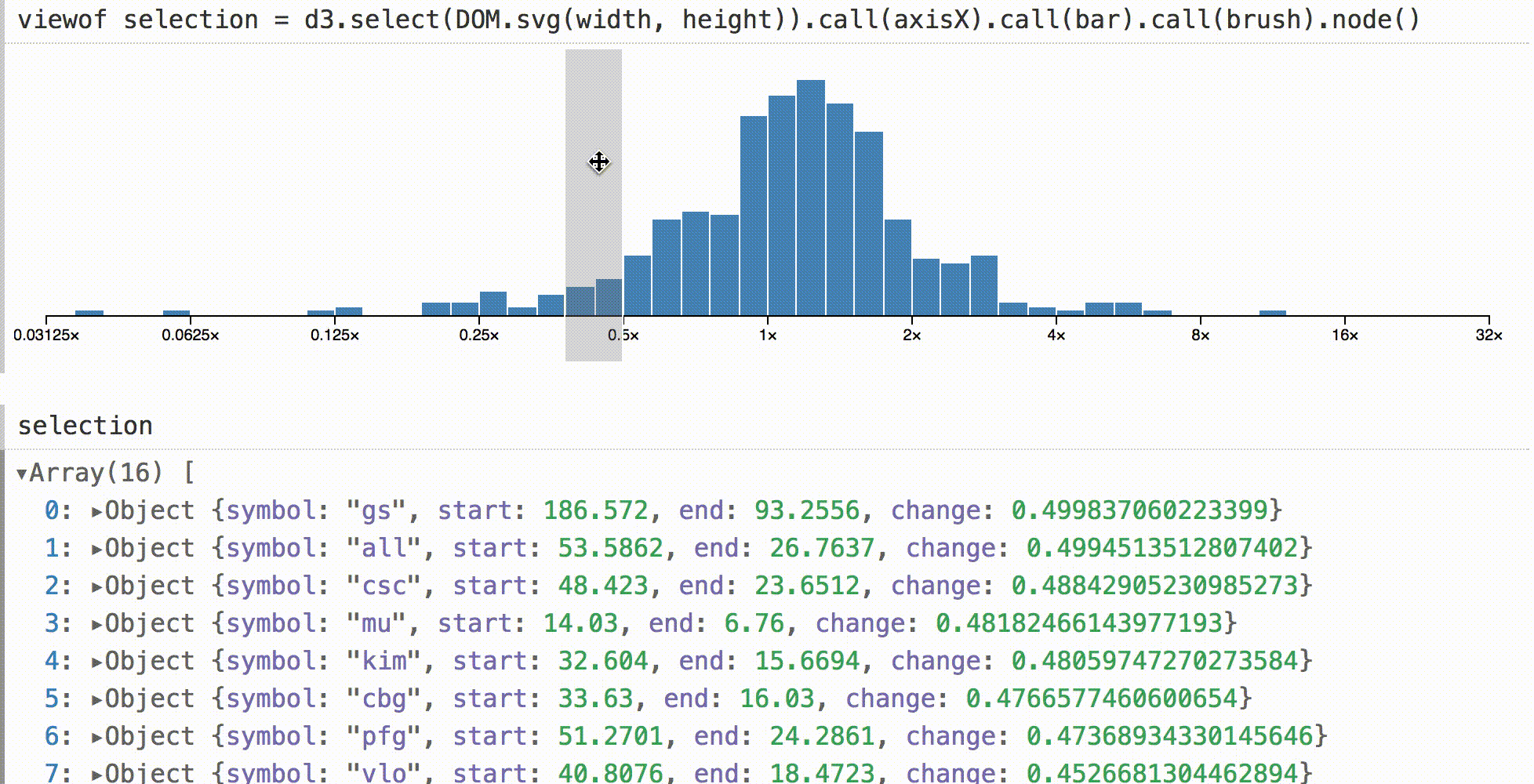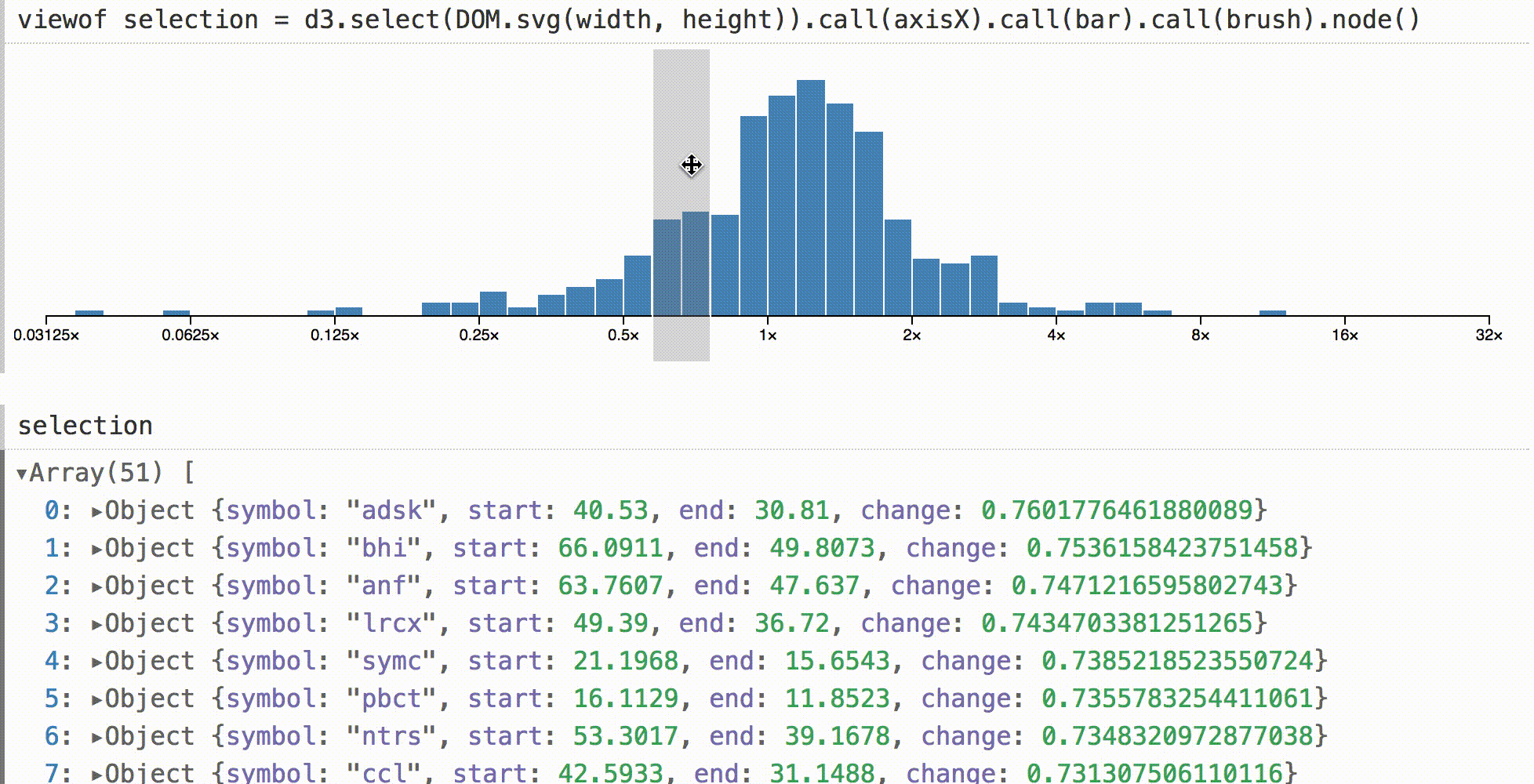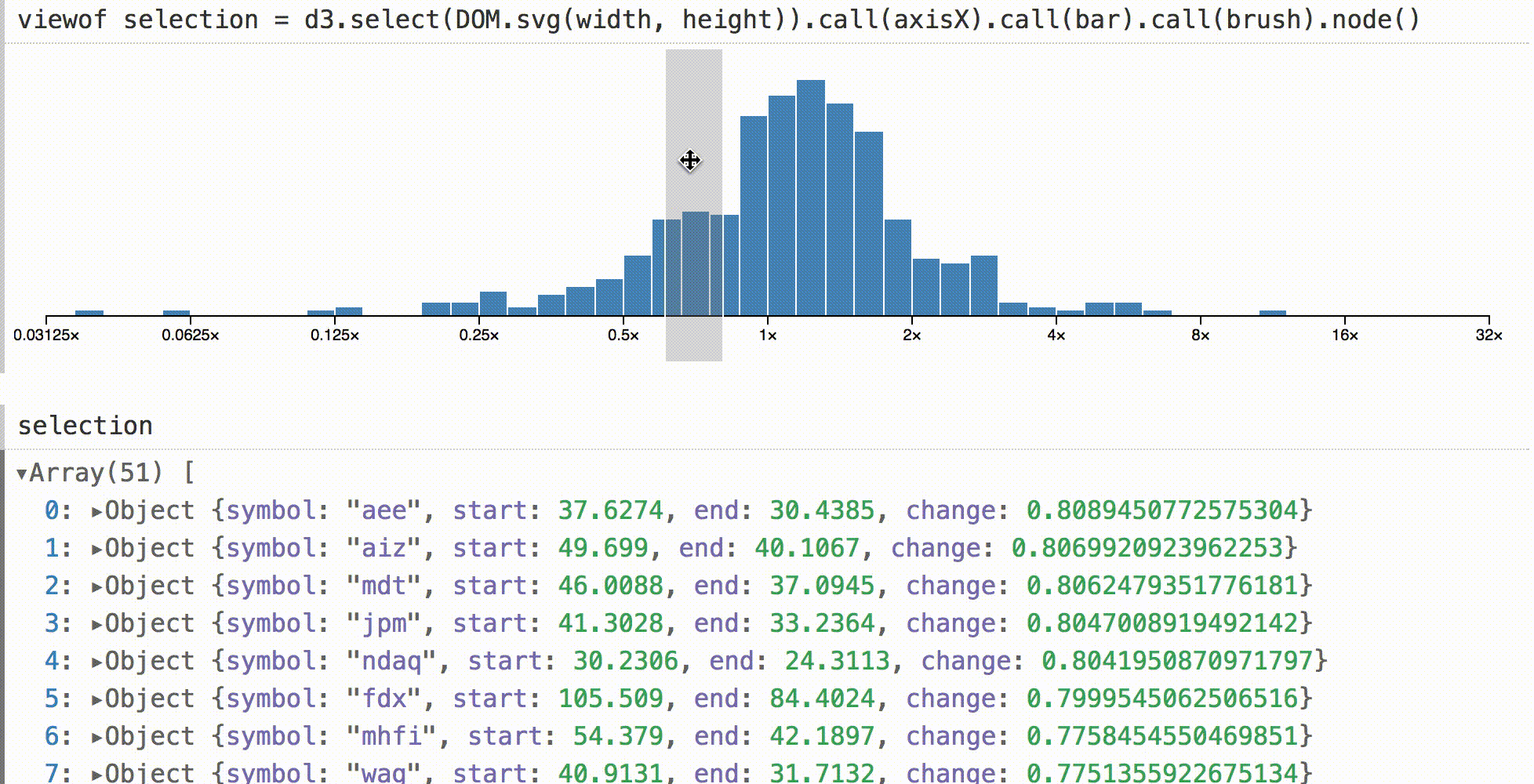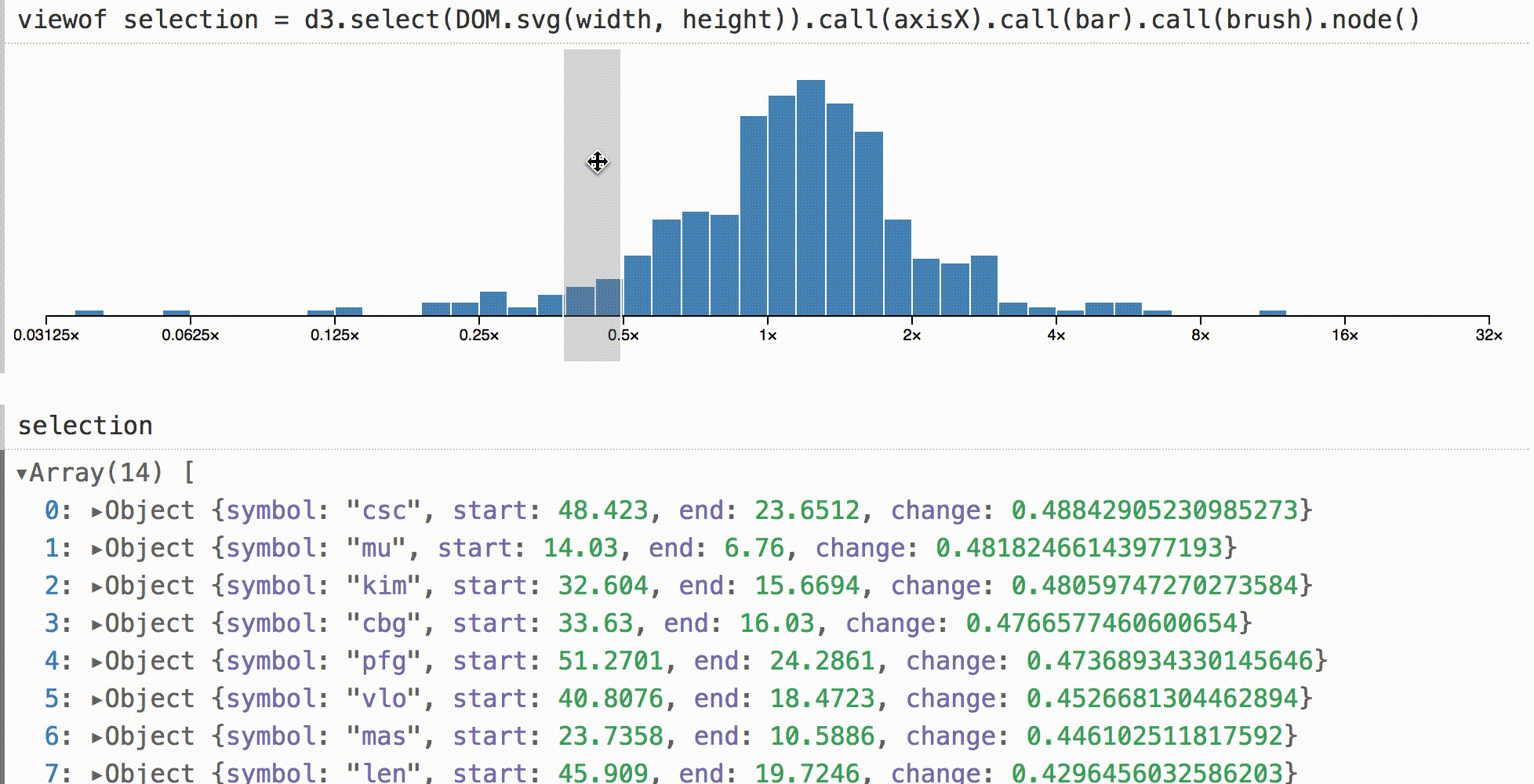
Здесь используется дефолтный инспектор объектов, но вы можете делать что угодно в интерактивном режиме, например, живые итоги, статистику в реальном времени или даже связанные визуализации.

Чтобы показать, что это не волшебство, выше приведен код для адаптации d3-brush к Obsesrvable. По событию brush, мы вычисляем новые отфильтрованные данные, устанавливаем его как значение SVG-узла и отправляем событие ввода.
Анимированные переходы
По умолчанию реакции происходят мгновенно: при изменении значения переменной среда выполнения пересчитывает производные переменные и тут же обновляет отображение. Но такая неотложность не всегда требуется и иногда полезно анимировать переходы для ощущения реальности объекта. Здесь, например, мы можем следить за столбцами, по мере их пересортировки:

Понимание реализации этой диаграммы требует знакомства с D3, а именно: привязанные к ключам данные и шаговый переход, но даже если этот код непрозрачен, он, надеюсь, демонстрирует, что сегодняшние библиотеки с открытым исходным кодом с легкостью используются в Obsesrvable.

2. Видимость
Визуальный вывод программы помогает лучше воспринимать текущее состояние программы. Интерактивное программирование помогает тщательней анализировать поведение программы методом тыка: изменение, удаление, изменение порядка и наблюдение за происходящим.
Например, убирая в комменты связывающие силы в приведенном ниже графике мы лучше понимаем их вклад в общее расположение фигур.
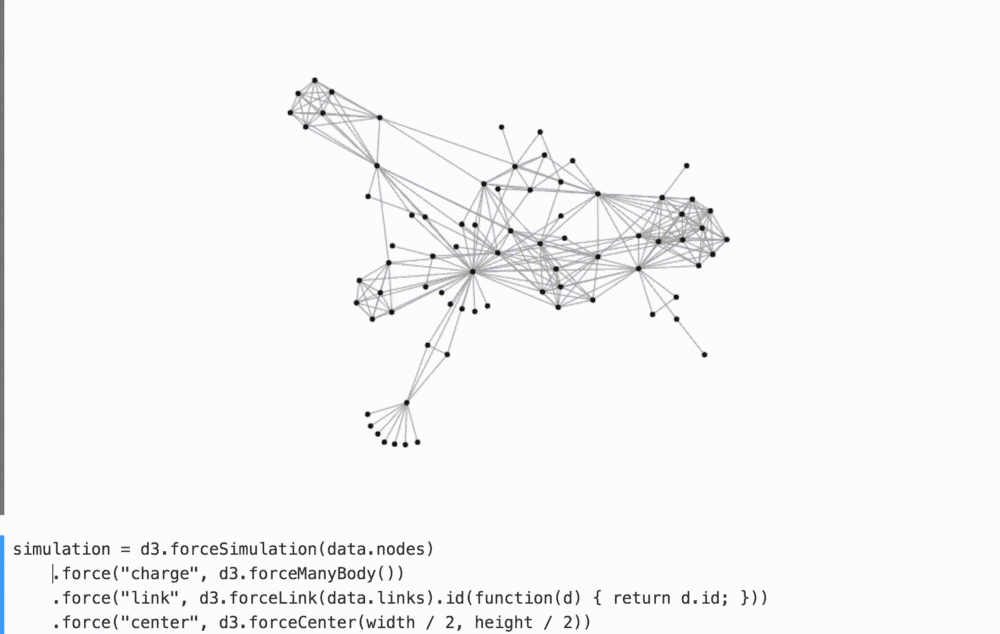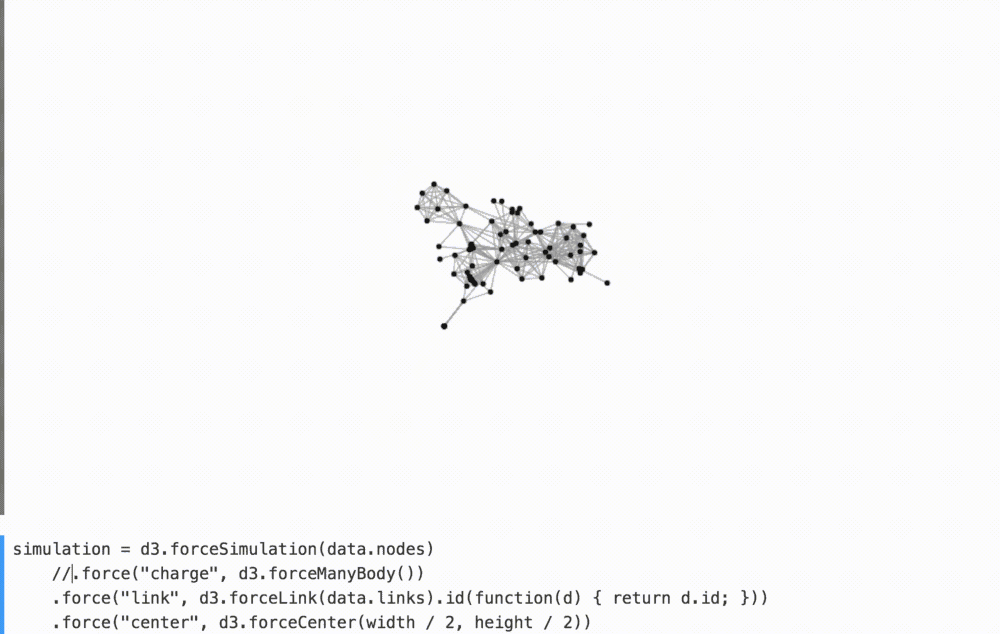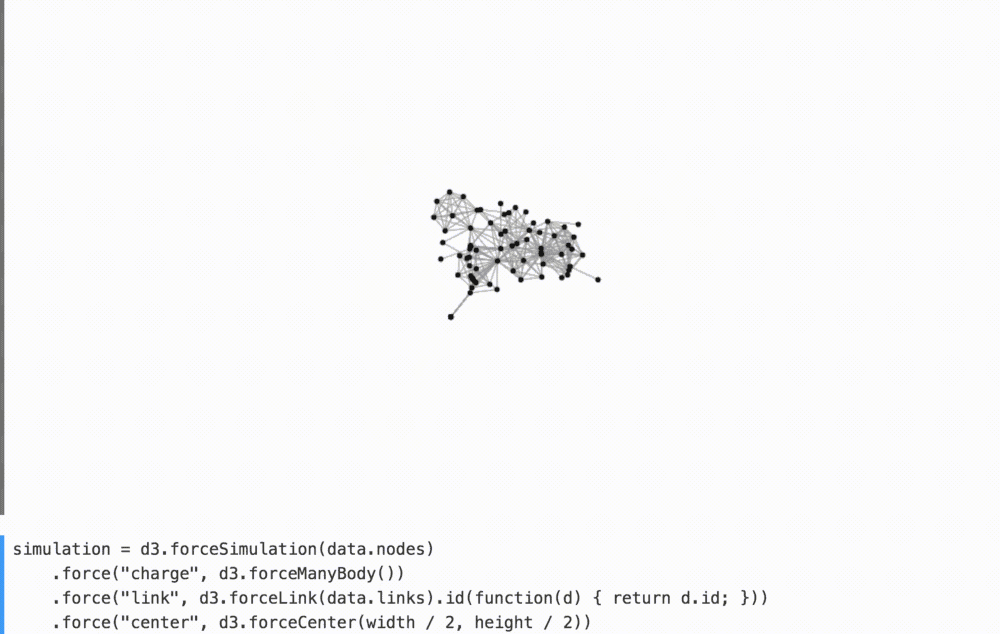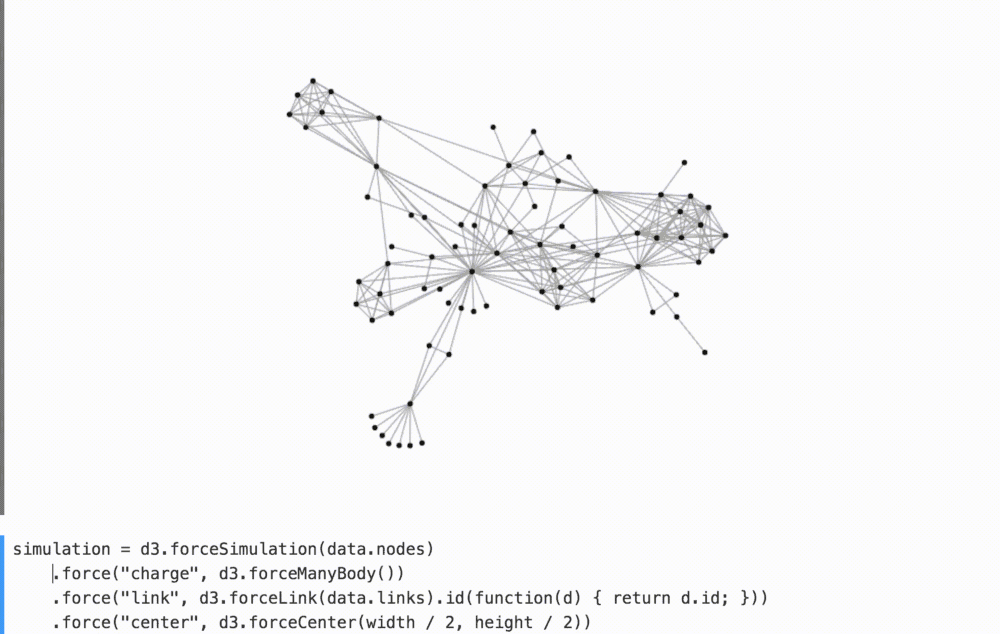
(смотрите на YouTube как я играюсь с этим.)
Вы, должно быть, видели похожие игрушки, — например, Стив Хароз имеет замечательную песочницу для d3-force. Здесь вам не нужно создавать пользовательский интерфейс для воспроизведения; он идет бесплатно с интерактивным программированием!
Визуализация алгоритмов
Более подробный подход к изучению поведения программы заключается в дополнении кода для отображения внутреннего состояния. Здесь также помогают генераторы. Мы можем взять нормальную функцию, подобную этой, для суммирования массива чисел:
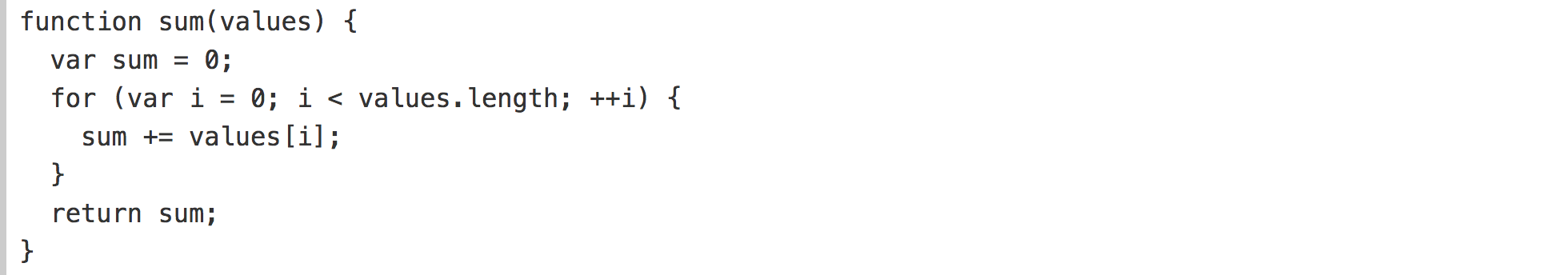
И превратить ее в генератор, который выдает локальное состояние во время выполнения, в дополнение к нормальному возвращаемому значению в конце:

Затем, для понимания поведения, мы можем визуализировать или проверить внутреннее состояние. Этот подход обеспечивает чистое разделение между нашей реализацией алгоритма и его изучением, а не внедрением кода визуализации непосредственно внутри алгоритма.

В качестве примера давайте рассмотрим иерархическую структуру упаковки кругов D3.

У нас есть набор кругов, которые мы хотим упаковать в как можно меньшем пространстве без наложения, как скопление пингвинов в Антарктиде. Наша задача — размещать круги по одному, пока все круги не будут размещены.
Поскольку мы хотим, чтобы круги были упакованы как можно сильнее, довольно очевидно, что каждый круг, который мы размещаем, должен касаться как минимум одного (на самом деле двух) кругов, которые мы уже разместили. Но если мы выбираем существующий круг случайным образом в качестве касательного круга, мы потратим много времени на то, чтобы поместить новый круг в середину пакета, где он будет перекрывать другие круги. В идеале мы рассматриваем только круги, которые находятся снаружи пакета. Но как мы можем эффективно определить, какие круги находятся снаружи?

Алгоритм Ванга поддерживает «внешнюю цепь», показанную здесь красным цветом, которая представляет эти самые внешние круги. При размещении нового круга он выбирает круг в передней цепи, который ближе всего к началу. Новый круг расположен рядом с этим кругом и его соседом по передней цепи.
Если это место размещения не перекрывается с каким-либо другим кругом в передней цепочке, алгоритм переходит к следующему кругу. Если он перекрывается, то мы обрезаем переднюю цепь между касательными кругами и перекрывающимся кругом, а перекрывающийся круг становится новой касающейся окружностью. Мы повторяем этот процесс до тех пор, пока не будет перекрытия.


Я нахожу эту анимацию завораживающей. Если вы внимательно присмотритесь, вы увидите краткие моменты, когда большой круг выжимается из упаковки, когда передняя цепь вырезана. Это не просто радует глаз, но и чрезвычайно полезно для выявления давней ошибки в реализации D3, где очень редко она перекрывала бы неправильную сторону передней цепи, а круги бы перекрывались.
После того, как мы собрали наши круги, нам нужно вычислить окружность для упаковки, чтобы круговая запаковка могла повторяться по иерархии. Обычный способ сделать это — сканировать переднюю цепь для круга, который находится дальше всего от начала координат. Это вполне приличное предположение, но не точное. К счастью, существует простое расширение алгоритма Вельца (Welzl) для вычисления наименьшей замкнутой окружности в линейном времени.

Чтобы увидеть, как работает алгоритм Вельца, предположим, что мы уже знаем внешнюю окружность для некоторых кругов и хотим включить в нее новый круг. Если новый круг находится внутри текущего окружного круга, мы можем перейти к следующему кругу. Если новый круг находится за пределами замкнутого круга, мы должны расширить окружность.


Когда круг находится вне замкнутого круга (слева), он должен касаться нового наружного круга (справа).
Однако мы кое-что знаем об этом новом круге: это единственный круг, который находится вне наружного круга и, следовательно, он должен касаться нового наружного круга. И если мы знаем как найти один касаемый круг для наружного круга, мы можем найти другие рекурсивно!
Тут есть немного геометрии, я немного халтурю, конечно. Нам также необходимо вычислить граничные случаи для рекурсии: наружные окружности для одной, двух или трех касаемых окружностей. (Это проблема Аполлония) Геометрия также диктует, что не может быть больше трех касаемых окружностей, или окружение уже содержит все круги, поэтому мы знаем, что наш рекурсивный подход в конечном итоге закончится.
Вот более полный обзор рекурсивного алгоритма, показывающий стек:

Левый — самый верхний уровень, где набор соприкасающихся окружностей пустой. Алгоритм повторяется каждый раз, когда новый круг находится вне окружности. Во время рекурсии этот новый круг должен быть положен на набор из соприкасающихся с ним кругов. Итак, слева направо, есть нуль, один, два и три соприкасающихся круга, закрашенные черным.
В дополнение к объяснению как работает алгоритм, эта анимация дает ощущение времени, которое алгоритм проводит на разных уровнях рекурсии. Поскольку он обрабатывает круги в случайном порядке, охватывающий круг быстро расширяется, чтобы приблизить окончательный ответ. Но всякий раз, когда он повторяется, он должен повторно установить все предыдущие круги, чтобы убедиться, что они вписываются в новый окружающий круг.
3. Повторное использование (reusability)
Один из способов писать меньше кода — это повторно его использовать. 440 000 или около того пакетов, опубликованных в npm, свидетельствуют о популярности этого подхода.
Но библиотеки являются примером активного повторного использования: они должны быть намеренно разработаны для повторного использования. И это значительный груз. Достаточно сложно разработать эффективную общую абстракцию! (Обратитесь к любому разработчику с открытым исходным кодом.) Внедрение «одноразового» кода, как это обычно бывает в примерах D3, проще, потому что вам нужно учитывать только конкретную задачу, а не абстрактный класс задач.
Я выясняю, можем ли мы иметь лучшее пассивное повторное использование в Observable. Где, используя структуру реактивных документов, мы можем легче перенастроить код, даже если этот код не был специально разработан для повторного использования.
Для начала вы можете рассматривать блокноты де-факто как библиотеки. Скажем, в одном ноутбуке я реализую пользовательскую цветовую шкалу:

В другом блокноте я могу импортировать эту цветовую шкалу и использовать ее.

Импорт также полезен, если вы создали много блокнотов для исследования идей и хотите объединить их в один блок.
Более интересно, Observable позволяет пересобирать определения переменных при импорте. Здесь я определяю стрим из данных в реальном времени через WebSocket. (опять же, детали этого кода не критичны, для упрощения вы можете представить себе воображаемую библиотеку…)
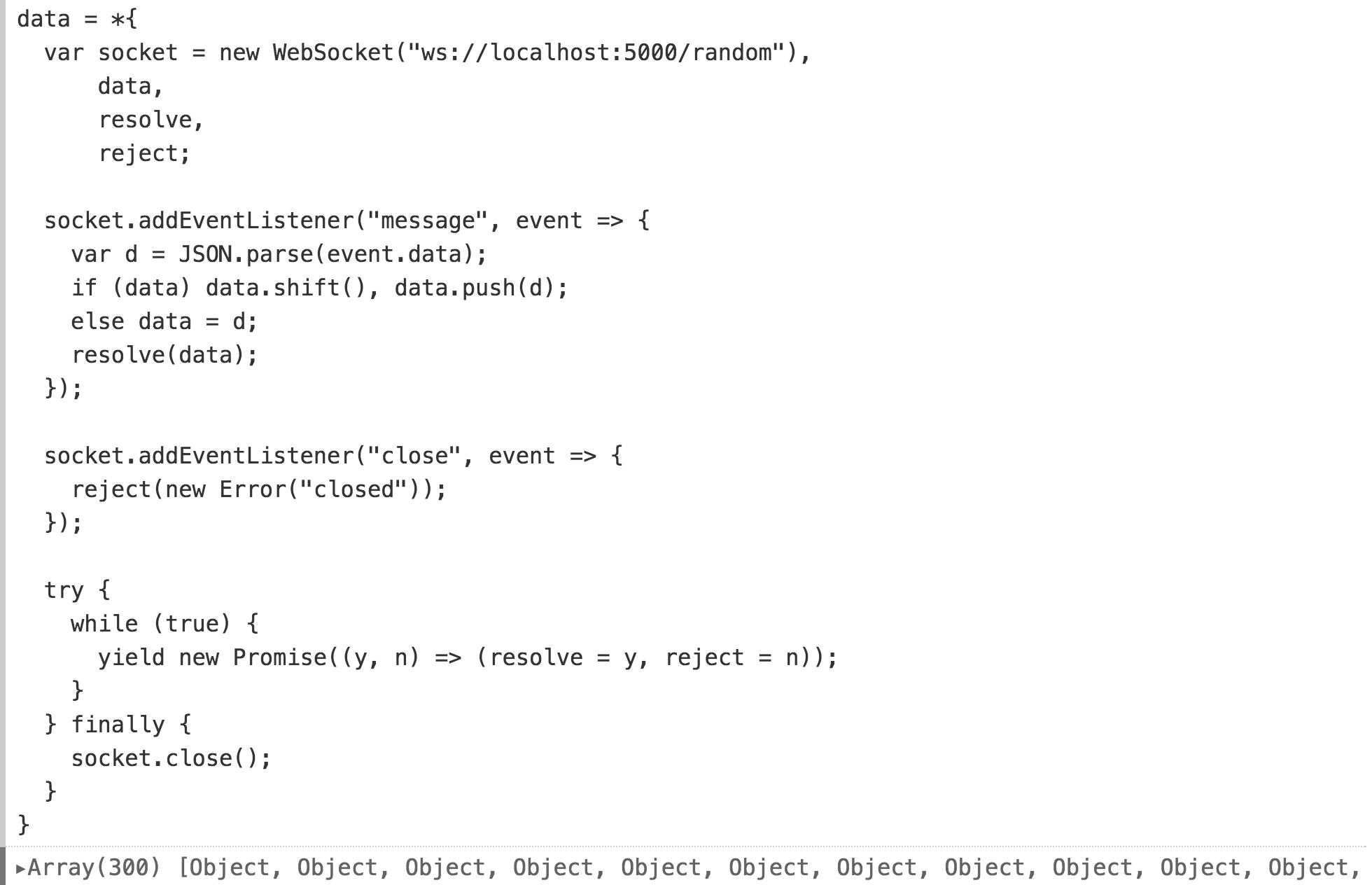
Этот набор данных имеет ту же форму, что и наш предыдущий линейный график: массив объектов со временем и значением. Можем ли мы повторно использовать этот график? Ага! Оператор with позволяет вводить локальные переменные в импортированные переменные, заменяя исходные определения.
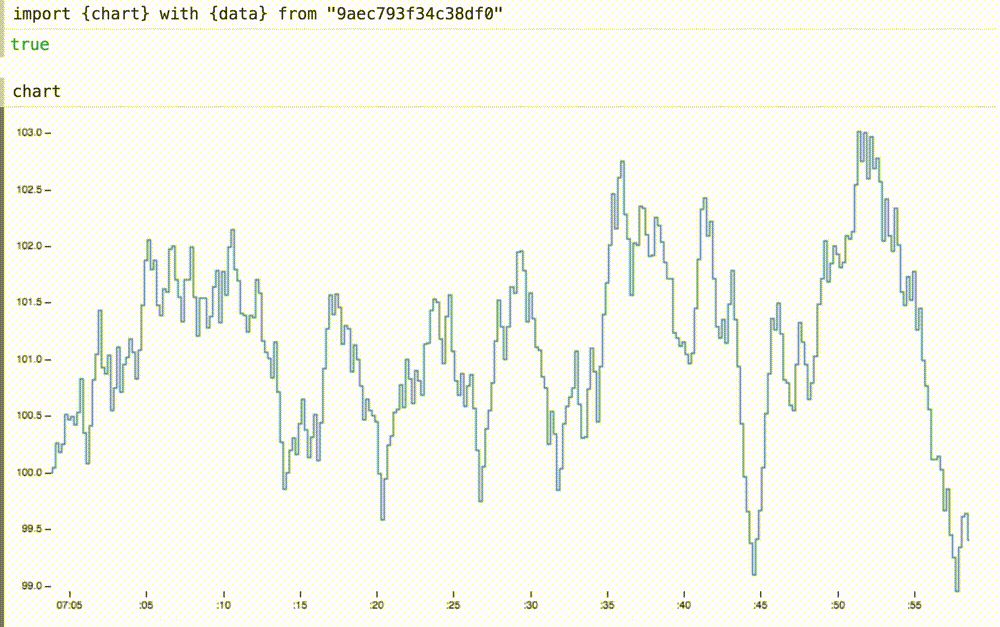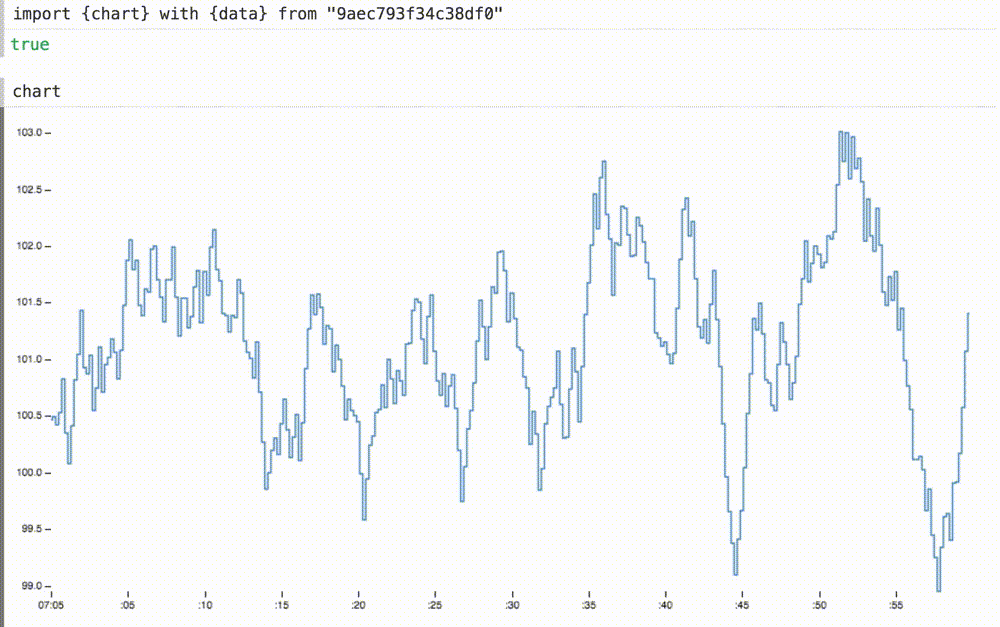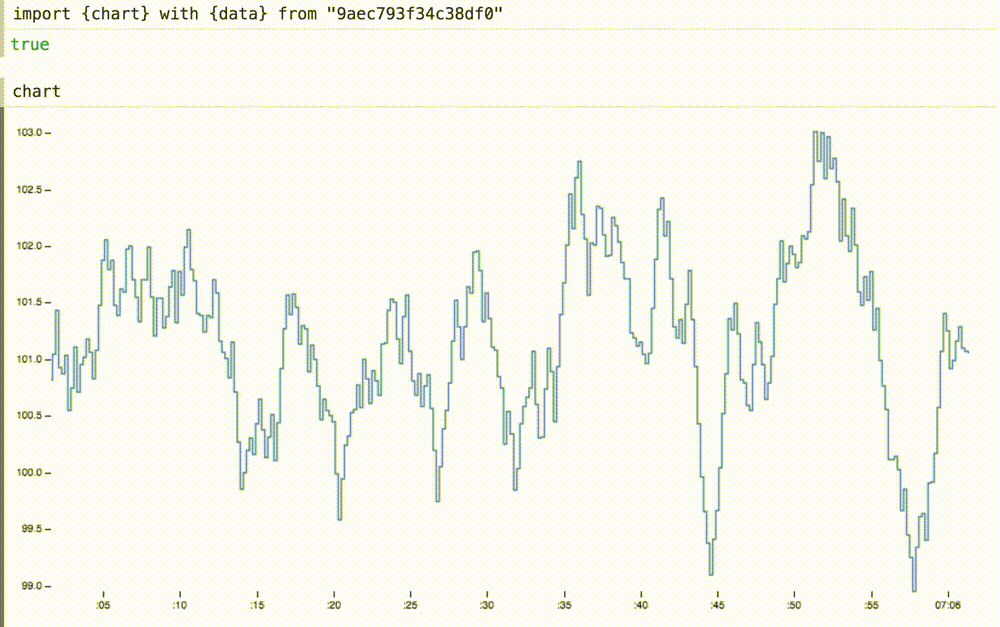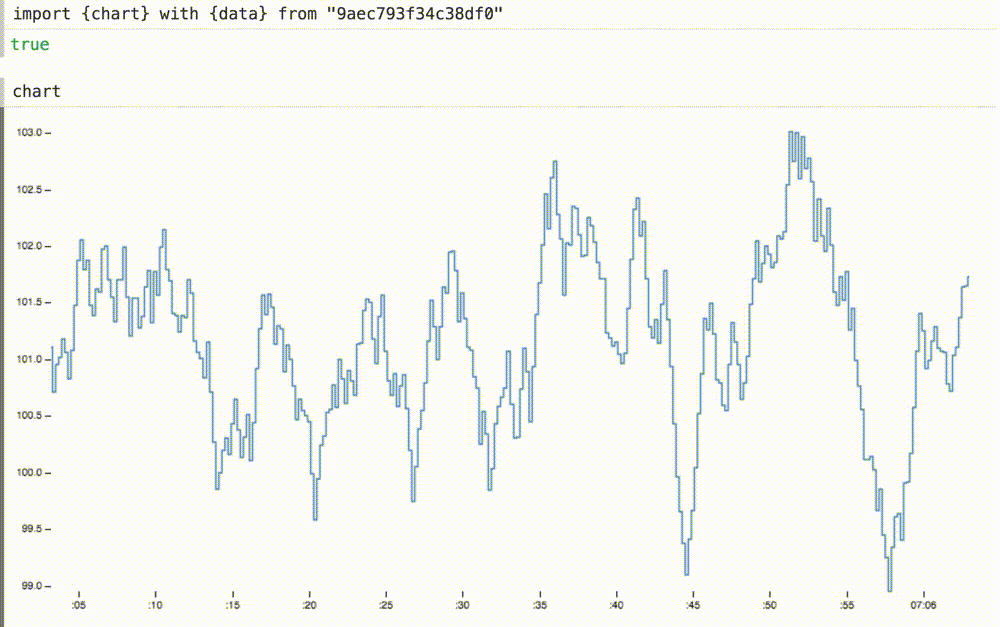
Мы можем не только вставлять наши динамические данные в ранее статичную диаграмму, но и при необходимости масштабировать оси координат. Здесь мы меняем домены для осей x и y на подходящие размеры для этих данных. ось x теперь показывает последние шестьдесят секунд или около того.
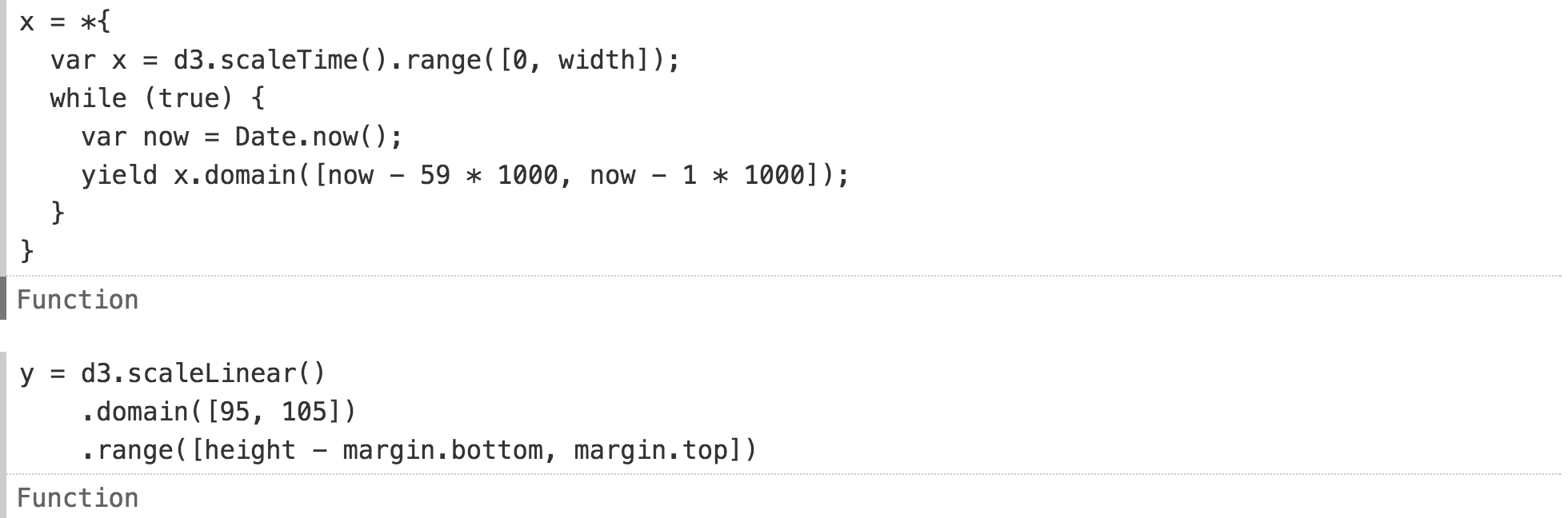
Добавляя новые определения x и y к оператору with, график теперь плавно скользит при 60 FPS, а ось y уже отвлекающе не дергается:
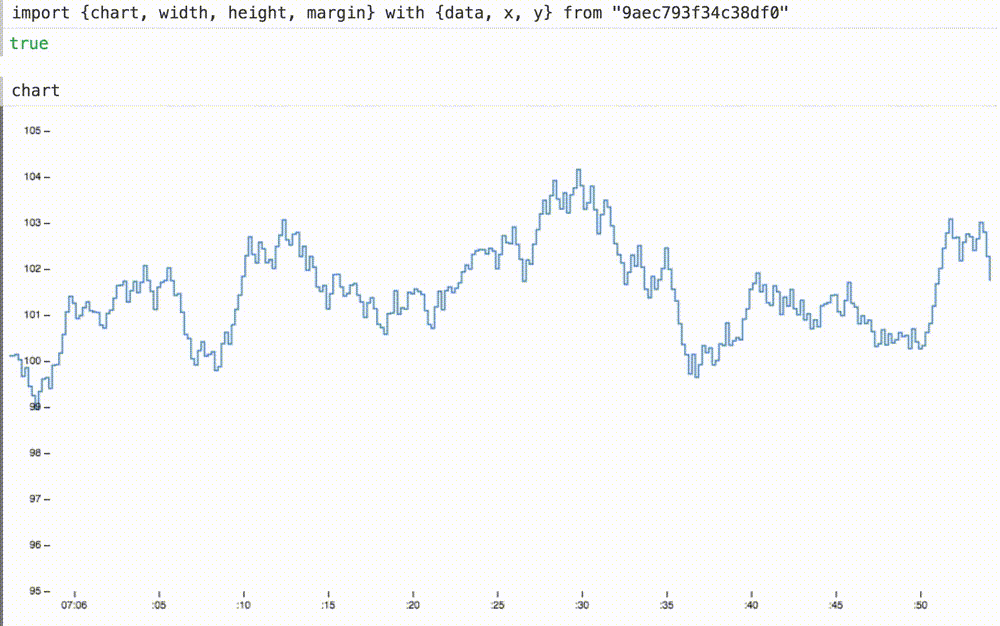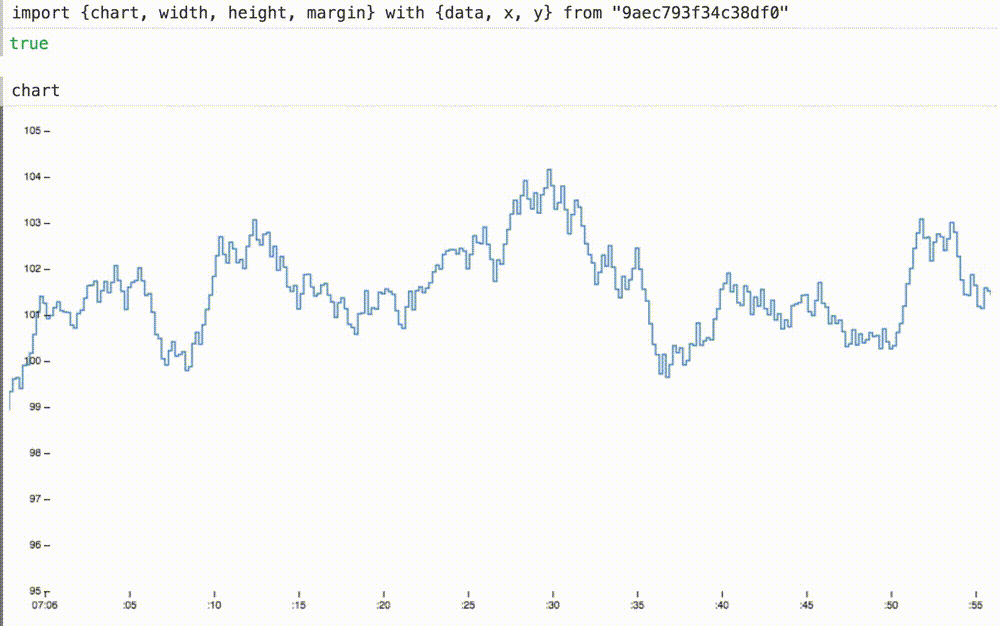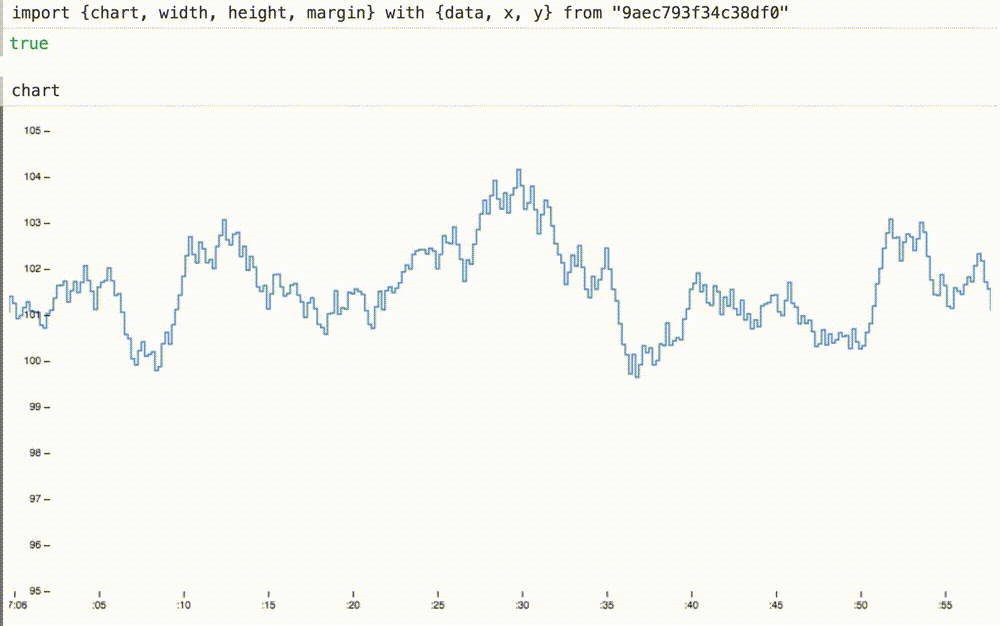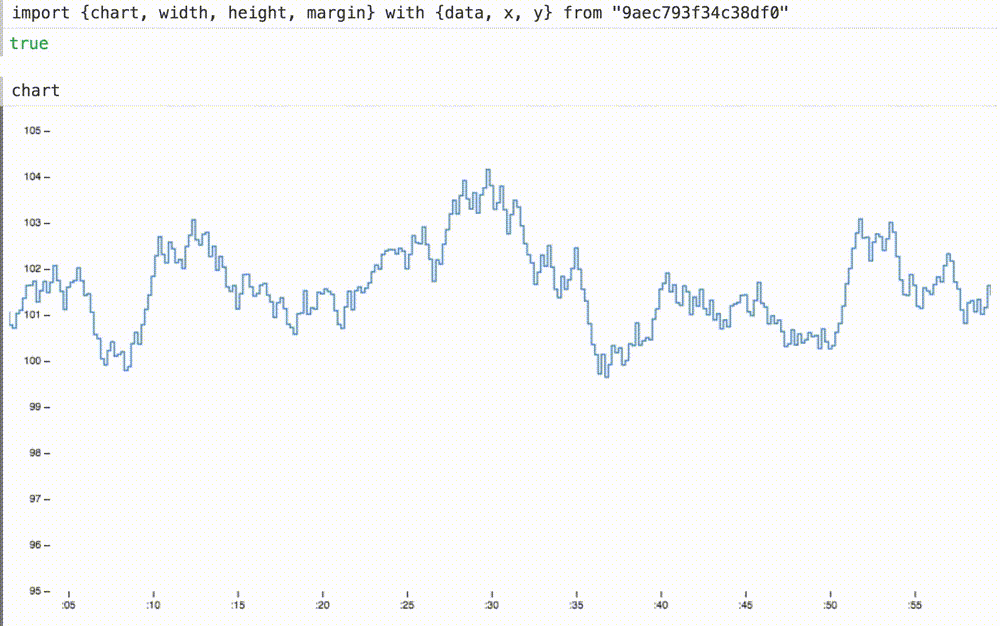
4. Портативность (portability)
Блокноты Observable работают в браузере, а не в настольном приложении или в облаке; есть сервер для сохранения ваших скриптов, но все вычисления и рендеринг происходят локально в клиенте. Что значит иметь исследовательскую среду в вебе?
Веб-среда охватывает веб-стандарты, включая ванильный JavaScript и DOM. Она работает с открытым исходным кодом, будь то фрагменты кода, которые вы найдете в Интернете или в библиотеках, опубликованных в npm. Это сводит к минимуму специализированные знания, необходимые для продуктивной работы в новой среде.
Существует новый синтаксис в Observable для реактивности, но я старался оставить его как можно более меньшим и знакомым, например, используя генераторы. Это четыре формы определения переменных:

Стандартная библиотека также минимальна и не привязана к платформе. Вы должны иметь возможность привести свой существующий код и знания в Observable и наоборот, забрать свой код и знания из Observable.
Веб-среда сначала позволяет вашему коду работать везде, потому что он работает в браузере. Не надо ничего устанавливать. Другим становится легче повторять и проверять ваш анализ. В дополнение, ваш код для исследования может изящно переходить в код для объяснения. Вам не нужно начинать с нуля, когда вы хотите поделиться своими идеями.
Замечательно, что журналисты и ученые расшаривают данные и код. Но код на GitHub не всегда легко запускается: вам нужно воспроизвести необходимую среду, операционную систему, приложение, пакеты и т.д. Если ваш код уже запущен в браузере, то он запускается и в любом другом браузере. И в этом вся прелесть Интернета!
Создание более портативного кода для анализа может иметь влияние на стиль нашего общения. Еще раз процитирую Виктора:
Активный читатель задает вопросы, рассматривает альтернативы, ставит под сомнение допущения и даже ставит под сомнение благонадежность автора. Активный читатель пытается обобщить конкретные примеры и придумать конкретные примеры для обобщений. Активный читатель не пассивно впитывает информацию, а использует аргументы автора как плацдарм для критического мышления и глубокого понимания.
P.S.
Если вы хотите помочь мне разрабатывать Observable, это здорово! Пожалуйста, свяжитесь со мной. Вы можете найти мой адрес электронной почты в моем профиле GitHub и связаться со мной в Twitter.
beta.observablehq.com
Спасибо за чтение!
