[Перевод] Краткое введение в MLOps

Возможно, вы слышали, что 90% моделей ML не добираются до стадии продакшена. На самом деле, любой человек из сферы ИТ знает, что внедрение ПО в продакшен — долгий и сложный процесс. Однако с того момента, как люди впервые написали условный оператор, происходили постоянные совершенствования процессов, способов разработки, развёртывания и обслуживания. Это привело к появлению процессов и инструментов, называемых DevOps. Сегодня они стали неотъемлемой частью практически любой компании, создающей серьёзное ПО, будь то в игровой, производственной, финансовой или медицинской отрасли. По этой теме написаны сотни, если не тысячи веб-страниц и статей.
Однако в последние годы в мире появилось новое подмножество типов ПО, а именно системы на основе AI. Они используют существенно отличающийся подход к решению задач, основанный на статистике, вероятности и, что самое важное, большом объёме данных. Это создаёт новые сложности, которые невозможно эффективно устранять при помощи стандартных методологий DevOps (потому что процессы тем или иным образом различаются). Многие компании, пытавшиеся использовать их, потерпели поражение.
Так как это гораздо более комплексная и сложная область, в мире ИТ появилась новая специализация — MLOps. К сожалению, эта профессия всё ещё очень молода. Это легко можно увидеть, проверив популярность терминов «MLOps» и «DevOps» в Google Trends. До 2019 года упоминаний MLOps, по сути, не существовало.
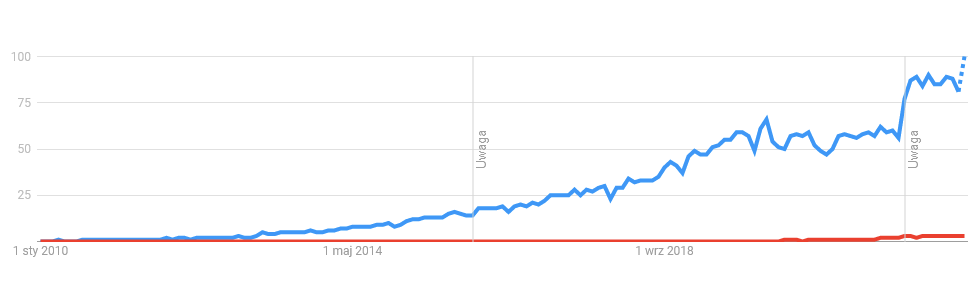
Синий график — DevOps, красный — MLOps
Из-за этого существует не так много определений, строгих правил или проверенных методологий, которые можно легко использовать. Каждая компания, в основе которой лежит AI, продолжает экспериментировать, стремясь найти наилучший способ решения задачи эффективного создания и развёртывания систем AI. Однако если вы любите определения, могу привести найденное на сайте Google Cloud Platform, посвящённом MLOps:
MLOps — это культура разработки ML, нацеленная на унификацию разработки (Dev) и эксплуатации (Ops) систем ML.
То есть дело не только в ускорении разработки моделей, а в ситуации в целом и в оптимизации процессов. Именно поэтому я написал эту статью — чтобы вкратце познакомить вас со сферой MLOps. В ней рассказывается о моём личном опыте, подкреплённом исследованиями этой темы. Статью следует использовать как пищу для размышлений, если вы думаете о внедрении MLOps в своей компании или о начале карьеры в области MLOps.
▍ Сложности MLOps
Во-первых, рассмотрим сложности, отличающие MLOps от DevOps. Стоит воспринимать MLOps как расширенную версию DevOps, поскольку оно решает те же задачи, плюс несколько дополнительных.

Сферы деятельности MLOps и DevOps
Давайте рассмотрим некоторые из сложностей:
- Во-первых, модели ML сильно зависят от статистики и вероятности. Их внутренние параметры задаются не напрямую разработчиками (называемыми инженерами ML или дата-сайентистами), а косвенно, заданием так называемых гиперпараметров, управляющих поведением алгоритма.
- Входные данные системы гибки и неконтролируемы. Под этим я подразумеваю, что внутреннее поведение системы оптимизируется на основании исторических данных (этап ML/Dev), но после развёртывания она работает с данными реального времени (этап Ops). Например, если изменилось поведение клиента, то система всё равно продолжит следовать старым паттернам принятия решений, которым она обучилась на старых данных. Это приведёт к её стремительному обесцениванию. Лежащий в основе этого процесс называется дрейфом данных (data drift). Он является одной из самых больших сложностей этапа Ops систем на основе AI. Возьмём пример: если в системе заказа пиццы вы заказали пеперони, а получили гавайскую пиццу, то можете легко сопоставить и выявить проблему в коде, а потом устранить её. В системах ML это сделать совсем не так просто.
- Ещё одна сложность часто связана со знаниями и образованием разработчиков. Так как системы ML основаны на таких знаниях, как, например, сложная линейная алгебра, байесовская статистика и вероятности, специалисты по ML в процессе обучения делали упор на другие темы. Сравните их с типичными фронтенд-инженерами (как часто им приходится использовать, например, разложение матриц?). На практике это означает, что при разработке они часто используют фреймворки, скрывающие сложные подробности ради простоты использования (например, Keras, sklearn). Эти фреймворки и библиотеки обычно находятся в состоянии непрерывной разработки, и вероятность появления новой версии алгоритма ML довольно высока (например, вызванного прогрессом в сфере операторов преобразования). Если вкратце, то инженеры ML:
- часто не имеют полного контроля над используемыми ими алгоритмами,
- любят и обязаны экспериментировать с новыми алгоритмами и методами,
- гораздо более связаны с математикой, чем классические разработчики ПО.
Как видите, в целом проблема в гибкости и данных, и алгоритмов. Это самое большое преимущество, но в то же время и самый большой недостаток.
▍ Реализация MLOps
MLOps нацелено на организованный контроль проблем разработки и продакшена. Чтобы достичь этой цели, необходимо использовать важные функциональные строительные блоки, показанные на изображении ниже. В зависимости от специфики отрасли или компании их может быть больше, но эти наиболее распространены среди различных областей применения.
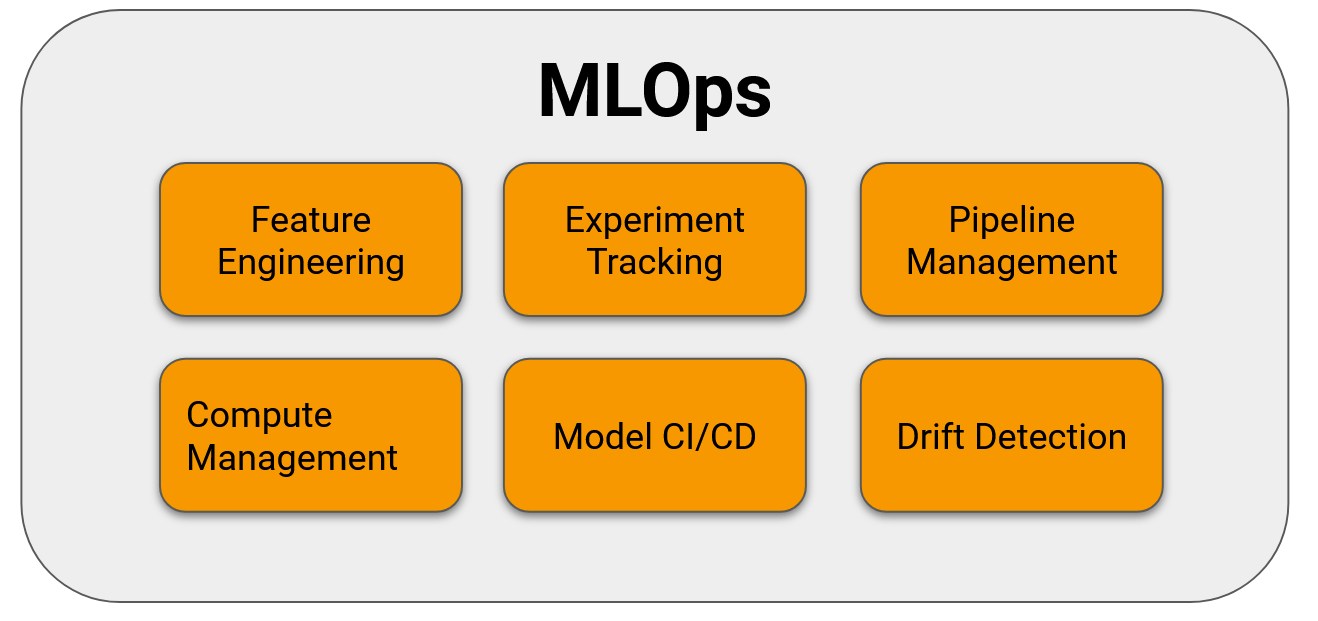
Базовые высокоуровневые компоненты MLOps
Давайте вкратце рассмотрим каждый из них.
- Feature engineering (конструирование признаков) связано с автоматизацией конвейеров ETL и контролем их версий. В идеале это должно быть что-то в стиле feature store. Если вам незнакома эта концепция, то изучите этот веб-сайт. Некоторые из имеющихся на рынке инструментов: Databricks Feature Store, Feast, Tecton.
- Experiment tracking (учёт экспериментов) — крупный и по-настоящему критически важный компонент, потому что он связан с экспериментами инженеров ML (как с успешными, так и с неудачными). Когда настанет время, он позволяет вернуться к предыдущим идеям (например, к другим алгоритмам или признакам) без необходимости изобретать велосипед. В зрелой системе ML может также существовать способ сохранения набора гиперпараметров (прошлых и текущих), а также соответствующие KPI качества системы, обычно называемые реестром модели (инструменты наподобие MLflow, Neptune или Weight&Biases).
- Pipeline management (управление конвейерами) позволяет выполнять контроль версий конвейера, управляющего потоком данных от ввода до вывода. Также оно должно журналировать каждый прогон и выдавать осмысленные ошибки в случае возникновения проблем. Можно рассмотреть следующие инструменты: Vertex AI Pipelines, Kedro, PipelineX, Apache Airflow.
- Compute management (управление вычислительными ресурсами) решает задачу масштабируемости в системах ML. Некоторые алгоритмы требуют огромных вычислительных мощностей при обучении и повторном обучении, но малых при вычислении результатов. Поскольку часто эти две задачи соединены цепью обратной связи, система должна уметь увеличивать и уменьшать свои масштабы. Иногда для обучения должны подключаться дополнительные ресурсы наподобие GPU, которые не требуются при вычислении результатов. Публичные поставщики облачных сервисов решают эту проблему, предоставляя функции автоматического масштабирования и балансировки нагрузки.
- Model CI/CD (CI/CD моделей) очень похожи на CI/CD из сферы DevOps, однако при развёртывании модели необходимо выполнять дополнительные проверки. Это выбранные метрики показателей, которые должны находиться в допустимом диапазоне и всегда сравниваться с текущей моделью в продакшене. Одни из самых популярных инструментов — Jenkins и Travis, но есть и множество других наподобие TeamCity или Circle CI.
- Drift detection (выявление дрейфа) — это модуль, отслеживающий характеристики входных данных и поведение системы. Когда характеристики входных данных отклоняются от ожидаемого диапазона, должен выдаваться соответствующий алерт, чтобы можно было запросить повторное обучение системы (автоматическое или ручное). Если это не помогает, то приоритет алерта должен быть повышен, а команда разработчиков должна изучить проблему внимательнее. Инструменты/сервисы: AWS SageMaker Model Monitor, Arize, Evidently AI.

Образцовые примеры для среды MLOps
При внедрении MLOps в своей организации, особенно если она разрабатывала или продолжает разрабатывать ПО, нужно быть очень аккуратными и учитывать уклон в DevOps: многие люди незнакомы со сферой AI и склонны использовать проверенные решения DevOps. Именно поэтому во многих компаниях системы на основе ML разрабатываются отдельными командами или отделами.
▍ Итог
Как видите, эта статья была вводной и обобщённой, она не предлагает вам каких-то конкретных решений. В разных компаниях используются свои внутренние процессы, которые нужно автоматизировать, и есть свои трудности, которые могут потребовать своих методик и инструментов для наиболее оптимального решения. Тем не менее есть отличные материалы про MLOps, написанные с расчётом на конкретный набор инструментов. Крайне рекомендую прочитать их, вот несколько примеров: 
