[Перевод] Конференция QCon. Овладение хаосом: руководство Netflix для микросервисов. Часть 2
Джош Эванс рассказывает о хаотичном и ярком мире микросервисов Netflix, начиная с самых основ — анатомии микросервисов, проблем, связанных с распределенными системами и их преимуществ. Опираясь на этот фундамент, он исследует культурные, архитектурные и операционные методы, которые ведут к овладению микросервисами.
Конференция QCon. Овладение хаосом: руководство Netflix для микросервисов. Часть 1
Для защиты приложений от неполадок такого рода мы разработали HYSTRIX — имплементацию корпоративного шаблона Circuit Breaker, предохранитель, который контролирует задержки и ошибки при сетевых вызовах.

HYSTRIX представляет собой библиотеку отказоустойчивости, которая будет терпеть сбои до порогового значения, оставляя цепь открытой. Это означает, что HYSTRIX будет перенаправлять все последующие вызовы в резерв, чтобы предотвратить будущие сбои, и создаст временной буфер для соответствующего сервиса, который можно будет восстановить после сбоя. Это что-то вроде запасного варианта: если сервис А не может вызвать сервис В, он все равно отправит клиенту резервный ответ, который позволит ему продолжить использование сервиса вместо того, чтобы просто получить сообщение об ошибке.
Таким образом, преимущество HYSTRIX — это изолированные пулы потоков и понятие цепи. Если несколько вызовов сервиса В безуспешны, сервис А перестанет их совершать и будет ждать восстановления. В свое время HYSTRIX был инновационным решением, но при его использовании возникал вопрос: у меня есть вся история настроек, я уверен, что все сделано правильно, но как узнать, что он действительно работает?
Лучший способ узнать это (вспомним наши биологические аналогии) — вакцинация, когда вы берете мертвый вирус и вводите его в организм, чтобы стимулировать борьбу антител с живым вирусом. В продакшене роль прививки играет фреймворк Fault Injection Testing (FIT) — тестирование, которое позволяет находить проблемы микросервисов путем создания искусственных сбоев. С его помощью выполняются синтетические транзакции на уровне устройств или аккаунтов, либо увеличивается объем «живого» трафика вплоть до 100%. Таким образом проверяется надежность микросервисов под стрессовой нагрузкой.
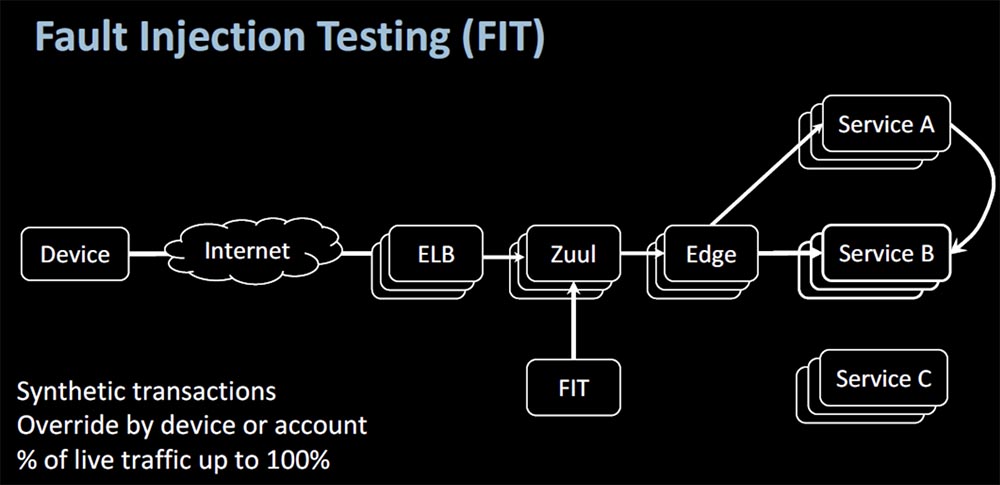
Конечно же, вы захотите протестировать вызов сервиса, прямой или косвенный, захотите убедиться, что ваши запросы декорированы правильным контекстом. То есть с помощью FIT вы можете «обрушить» сервис и проанализировать причины неполадок без реального сбоя в продакшене.
Это хорошо, если рассматривать соединения «точка-точка». Но представьте, что ваша система состоит из сотни микросервисов, и каждый из них зависит от других. Как проверить такую систему, не проводя миллионов тестов, во время которых сервисы вызывают друг друга?
Допустим, у вас имеется 10 сервисов в цельной структуре микросервиса, и каждый из них обладает 99,99% доступностью. Это означает, что на протяжение года каждый сервис может быть не доступным 53 минуты.

Если бы сервисы работали независимо, в этом не было бы ничего критичного, но когда они зависят друг от друга, суммарное время отказа всего микросервиса может достигать 8–9 часов в год, а это уже большая разница.
Из вышесказанного возникает концепция критических микросервисов — это минимальный уровень обслуживания, который клиент хотел бы получить в случае сбоев, т. е. базовая возможность просмотра контента, например, из списка только популярных фильмов. Клиенты будут мириться с потерей некоторых дополнительных услуг, таких как персонализация, пока они могут достичь хотя бы этого. Используя данный подход, мы идентифицировали такие сервисы и сгруппировали их, создав «FIT рецепт». Фактически это «черный список», в который входят все остальные сервисы, не являющиеся критическими.

После этого мы протестировали продукт и убедились, что таким образом обеспечили постоянную доступность критически важных сервисов в случае потери других функций. Так нам удалось избавиться от жестких зависимостей.
Поговорим о клиентских библиотеках. Мы достаточно остро дискутировали по их поводу, когда начали переход к облачным технологиям. В то время к нам в команду пришло много людей из Yahoo, которые были категорически против клиентских библиотек, выступая за максимальное упрощение сервиса до «голого железа».
Представьте, что у меня есть общая логика и общие шаблоны доступа для вызова моего сервиса и есть 20 или 30 разных зависимостей. Действительно ли я захочу, чтобы каждая отдельная команда разработчиков писала один и тот же или немного отличающийся код снова и снова, или же захочу объединить все в общую бизнес-логику и общие шаблоны доступа? Это было настолько очевидно, что мы внедрили именно такое решение.
Проблема состояла в том, что фактически мы откатились назад, создав новый вид монолитной структуры. В данном случае API-шлюз, взаимодействующий с сотней сервисов, запускал огромное количество кода, что приводила нас к ситуации 2000 года, когда такая же куча кода использовала общую кодовую базу.
Эта ситуация похожа на паразитарную инфекцию. Гадкое существо на слайде не имеет размеров Годзиллы и не способно разрушить Токио, но оно заразит ваш кишечник, к которому подходят кровеносные сосуды, и начнет пить вашу кровь как вампир. Это приведет к анемии и сильно ослабит ваш организм.

Аналогично клиентские библиотеки могут делать то, о чем вы не узнаете, и что может ослабить ваш сервис. Они могут потреблять больше тепла, чем вы рассчитываете, они могут иметь логические дефекты, приводящие к сбоям. Они могут иметь транзитные зависимости, притягивающие другие библиотеки конфликтующих версий и ломающие систему аккаунтов. Все это происходит в реальности, особенно в команде API, потому что они используют библиотеки других команд разработчиков.
Здесь не может быть однозначного решения, поэтому в результате споров и обсуждений мы достигли консенсуса, который состоял в попытке упростить эти библиотеки.

У нас не было желания оставить один «голый металл», мы хотели использовать простую логику с общими шаблонами. В результате был найден баланс между крайне простой каркасной моделью REST API и максимально упрощенными клиентскими библиотеками.
Давайте поговорим о Persistence — живучести системы. Мы выбрали верный путь, взяв за основу теорему CAP. Вижу, что с ней незнакомы всего несколько присутствующих. Эта теорема говорит о том, что при наличии сетевых партиций приходится выбирать между согласованностью и доступностью. Согласованность означает, что каждое чтение дает самую последнюю запись, а доступность — что каждый работающий узел всегда успешно выполняет запросы на чтение и запись. Это касается сценариев, в которых одна конкретная база данных в зоне доступности может быть недоступна, в то время как другие базы будут доступны.
На слайде показан сетевой сервис А, который записывает в 3 базы данных копии одинаковых данных. Каждая из баз работает с одной из 3 сетей, обеспечивая доступность. Вопрос в том, что делать, если вы потеряете связь с одной из БД — у вас возникнет сбой и сообщение об ошибке, либо вы продолжите работу с двумя остальными БД, пока неполадка не будет устранена.

В качестве решения этого вопроса Netflix предложил подход «конечной согласованности». Мы не ожидаем, что каждая отдельная запись будет немедленно прочитана из любого источника, в которые мы записали данные, мы пишем дальше и позже осуществляем полную репликацию, чтобы достичь согласованности данных. С этой задачей Cassandra справляется на «отлично».

Она обладает большой гибкостью, поэтому клиент может писать только на один узел, который затем с помощью оркестровки пишет на несколько других узлов. Здесь возникает понятие локального кворума, при котором вы можете сказать: «мне нужно, чтобы несколько узлов ответили и сказали, что действительно совершили это изменение, прежде чем я начну предполагать, что оно записано». Если вы готовы рискнуть надежностью, это может быть один узел, обеспечивающий очень высокую доступность, или же вы можете вызвать все узлы и заявить, что хотите записывать на каждый из них.
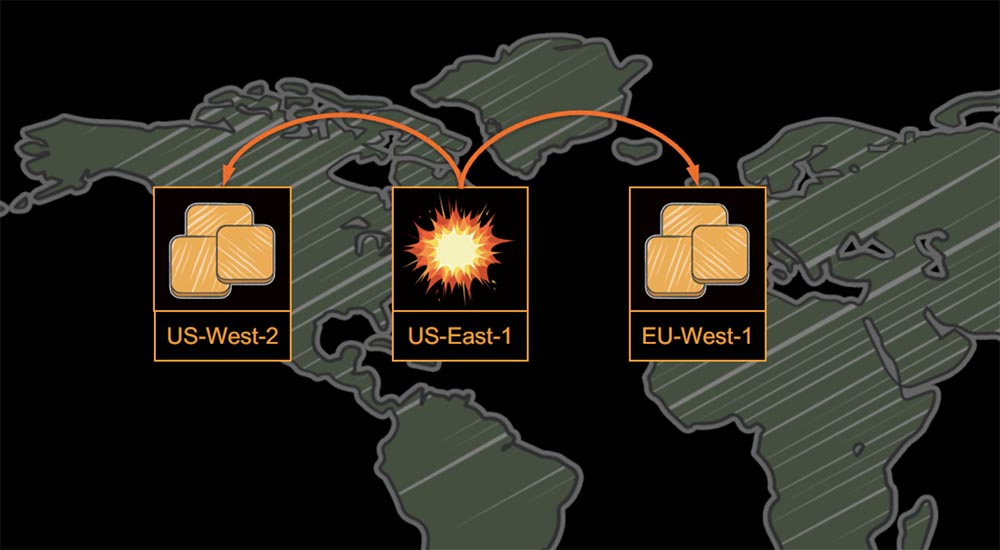
Теперь поговорим об инфраструктуре, потому что это отдельная важная тема. Когда-нибудь ваша инфраструктура, будь то AWS, Google или ваша собственная разработка, может отказать, потому что отказать может все что угодно. Вы видите заголовок статьи Forbes о том, что Amazon AWS обвалил Netflix в канун Рождества 2012 года.

Было бы ошибкой, если бы я попытался возложить вину за это на кого-либо другого, потому что мы сами положили все яйца в одну корзину.

Мы поместили все свои сервисы на сервер US-East-1, и когда там произошел сбой, нам было некуда отступать. После этого случая мы внедрили мультирегиональную стратегию с тремя регионами AWS так, что если один из них давал сбой, мы могли перевести весь трафик на два других региона.
Ранее в этом году я уже выступал на QСon London с докладом о глобальной архитектуре Netflix, так что вы можете просмотреть это выступление, если хотите вникнуть в тему достаточно глубоко.
Перейдем к масштабированию и рассмотрим три его составляющих: stateless-сервисы, stateful-сервисы и гибридные сервисы. Что же такое stateless-сервис? Кто-нибудь из присутствующих может дать определение? Начну с того, что это не кеш или база данных, где вы храните массивный объем информации. Вместо этого у вас есть часто используемые метаданные, кэшируемые в энергонезависимой памяти.
Обычно у вас нет привязки к конкретному экземпляру, то есть вы не ожидаете, что клиент постоянно будет привязан к определенному сервису. Наиболее важным является то, что потеря узла не является критическим событием, о котором следует беспокоиться. Такая сеть восстанавливается очень быстро, и вышедший из строя узел практически мгновенно заменяется новым. Самая подходящая для этого стратегия — репликация. Возвращаясь к биологии, можно сказать, что мы имеем с митозом, когда клетки постоянно умирают и постоянно рождаются.
26:30 мин
Продолжение будет совсем скоро…
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5–2697v3 2.6GHz 14C 64GB DDR4 4×960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5–2430 2.2Ghz 6C 128GB DDR3 2×960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?
