[Перевод] Kонференция NDС London. Предотвращение катастрофы микросервисов. Часть 1
Вы потратили месяцы, переделывая свой монолит в микросервисы, и наконец, все собрались, чтобы щелкнуть выключателем. Вы переходите на первую веб-страницу… и ничего не происходит. Перезагружаете ее — и снова ничего хорошего, сайт работает так медленно, что не отвечает в течение нескольких минут. Что же случилось?
В своем выступление Джимми Богард проведет «посмертное вскрытие» реальной катастрофы микросервиса. Он покажет проблемы моделирования, разработки и производства, которые обнаружил, и расскажет, как его команда медленно трансформировала новый распределенный монолит в окончательную картину здравомыслия. Хотя полностью предотвратить ошибки проекта невозможно, можно, по крайней мере, выявить проблемы на ранней стадии проектирования, чтобы конечный продукт превратился в надежную распределенную систему.

Приветствую всех, я Джимми, и сегодня вы услышите, как можно избежать мегакатастроф при создании микросервисов. Эта история компании, в которой я проработал около полутора лет, чтобы помочь предотвратить столкновение их корабля с айсбергом. Чтобы рассказать эту историю должным образом, придется вернуться в прошлое и поговорить о том, с чего начиналась эта компания и как со временем росла ее ИТ-инфраструктура. Чтобы защитить имена невиновных в этой катастрофе, я изменил название этой компании на Bell Computers. На следующем слайде показано, как выглядела IT инфраструктура таких компаний в середине 90-х. Это типичная архитектура большого универсального отказоустойчивого сервера HP Tandem Mainframe для функционирования магазина компьютерной техники.

Им нужно было построить систему управления всеми заказами, продажами, возвратом, каталогами продуктов, клиентской базой, так что они выбрали самое распространенное на то время решение мейнфрейма. Эта гигантская система содержала в себе каждую крупицу информации о компании, все, что только можно, и любая транзакция проводилась через этот мейнфрейм. Они держали все свои яйца в одной корзине и считали, что это нормально. Единственное, что сюда не вошло — это каталоги почтовых заказов и оформление заказов по телефону.
Со временем система становилась все больше и больше, в ней накапливалось огромное количество мусора. Кроме того, COBOL не самый выразительный язык в мире, так что в конечном итоге система превратилась в большой монолитный ком мусора. К 2000 году они увидели, что множество компаний имеют сайты, с помощью которых ведут абсолютно весь бизнес, и решили построить свой первый коммерческий дотком-сайт.
Первоначальный дизайн выглядел довольно симпатично и состоял из сайта верхнего уровня bell.com и ряда поддоменов для отдельных приложений: каталога catalog.bell.com, аккаунтов account.bell.com, заказов orders.bell.com, поиска товаров search.bell.com. Каждый поддомен использовал фреймворк ASP.Net 1.0 и собственные базы данных, и все они общались с бэкендом системы. Однако все заказы продолжали обрабатываться и выполняться внутри единственного огромного мейнфрейма, в котором оставался весь мусор, зато фронтенд представлял собой отдельные веб-сайты с индивидуальными приложениями и отдельными базами данных.
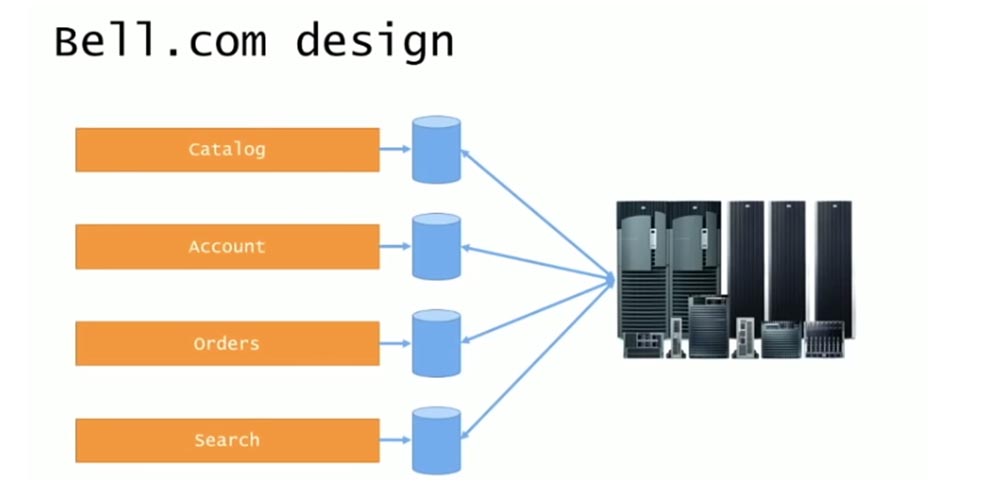
Итак, дизайн системы выглядел упорядоченным и логичным, но реальная система была такой, как показано на следующем слайде.
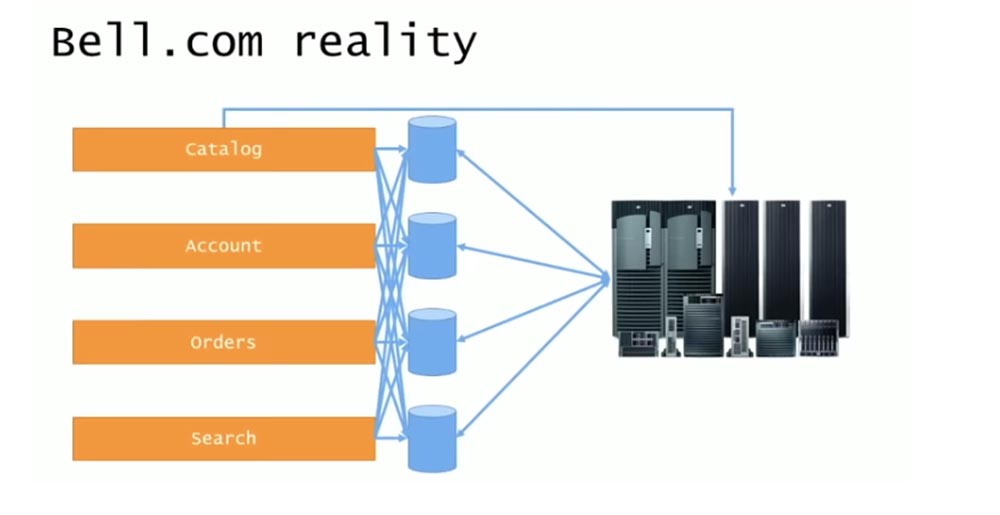
Все элементы адресовали вызовы друг другу, обращались к API, встраивали сторонние библиотеки dll и тому подобное. Часто случалось, что системы управления версиями хватали чужой код, запихивали его внутрь проекта, и затем все ломалось. MS SQL Server 2005 использовал концепцию линк-серверов, и хотя я не показал стрелками на слайде, каждая из баз данных также общалась друг с другом, потому что как бы нет ничего плохого в том, чтобы строить таблицы на основании данных, полученных из нескольких БД.
Поскольку теперь у них были некоторые разделения между различными логическими областями системы, это превратилось в распределенные комья грязи, а самый большой кусок мусора по-прежнему оставался в бэкенде мейнфрейма.
Самое смешное было то, что этот мейнфрейм был построен конкурентами Bell Сomputers и до сих пор обслуживался их техническими консультантами. Убедившись в неудовлетворительной работе своих приложений, компания решила от них избавиться и сделать редизайн системы.
Существующее приложение было в продакшене на протяжении 15 лет, что является рекордным для приложений на базе ASP.Net. Сервис принимал заказы со всего мира, и ежегодная прибыль от этого единственного приложения достигала миллиарда долларов. Значительную часть прибыли формировал именно веб-сайт bell.com. По «черным пятницам» число заказов, сделанных через сайт, достигало несколько миллионов. Однако существующая архитектура не позволяла никакого развития, поскольку жесткие взаимосвязи элементов системы практически не позволяли вносить в сервис никаких изменений.
Самой серьезной проблемой стала невозможность сделать заказ из одной страны, оплатить его в другой и отправить в третью при том, что подобная схема торговли весьма распространена в глобальных компаниях. Существующий веб-сайт не позволял ничего подобного, поэтому они вынуждены были принимать и оформлять такие заказы по телефону. Это приводило к тому, что компания все больше задумывалась о смене архитектуры, в частности о переходе на микросервисы.
Они поступили разумно, изучив опыт других компаний, чтобы посмотреть, как те решили аналогичную проблему. Одним из таких решений была архитектура сервиса Netflix, представляющая собой микросервисы, соединенные через API, и внешнюю базу данных.
Руководство Bell Сomputers приняло решение построить именно такую архитектуру, придерживаясь неких основных принципов. Во-первых, они отказались от дублирования данных, используя подход общего доступа к БД. Никакие данные не пересылались, напротив, все, кто в них нуждался, должны были обращаться к централизованному источнику. Далее следовали изолированность и автономность — каждый сервис был независим от других. Они решили использовать Web API абсолютно для всего — если вы хотели получить данные или внести изменения в другую систему, все это делалось через Web API. Последней важной вещью был новый главный мейнфрейм под названием «Bell on Bell» в отличие от мейнфрейма «Bell», основанного на «железе» конкурентов.
Итак, в течение 18 месяцев они создавали систему, руководствуясь этими основными принципами, и довели ее до стадии предпродакшена. Вернувшись на работу после выходных, разработчики собрались вместе и включили все сервера, к которым была подключена новая система. 18 месяцев работы, сотни разработчиков, самое современное аппаратное обеспечение Bell — и никакого положительного результата! Это разочаровало множество людей, потому что они неоднократно запускали эту систему на своих ноутбуках, и все было нормально.
Они поступили разумно, кинув все деньги на решение этой проблемы. Они установили самые современные серверные стойки со свитчами, использовали гигабитное оптоволокно, самое мощное серверное «железо» с сумаcшедшим объемом RAM, соединили все это, настроили — и снова ничего! Тогда они начали подозревать, что причина может быть в таймаутах, поэтому зашли во все веб-настройки, все настройки API и обновили всю конфигурацию таймаутов до максимальных значений, так что оставалось только сидеть и ждать, когда с сайтом что-то произойдет. Они ждали, ждали и ждали в течение 9 с половиной минут, пока веб-сайт наконец-то загрузился.
После этого до них дошло, что сложившаяся ситуация нуждается в тщательном разборе, и они пригласили нас. Первое, что мы выяснили — в течение всех 18 месяцев разработки так и не было создано ни одного реального «микро» — все становилось только еще больше. После этого мы приступили к написанию post-mortem, известного также как «regretrospective», или «печальная ретроспектива», она же «blame storm» — «обвинительный штурм» по аналогии с мозговым штурмом «brain storm», чтобы разобраться в причине катастрофы.
У нас было несколько улик, одной из которых являлось полное насыщение трафиком в момент вызова API. Когда вы используете монолитную архитектуру сервиса, то сразу можете понять, что именно пошло не так, потому что у вас имеется трассировка к единственному стеку, которая сообщает обо всем, что могло вызвать сбой. В случае, когда куча сервисов одновременно обращаются к одному API, нет никакой возможности отследить трассировку, кроме как использовать дополнительные инструменты сетевого мониторинга типа WireShark, благодаря которым можно рассмотреть отдельный запрос и выяснить, что произошло при его реализации. Поэтому мы взяли одну веб-страницу и на протяжение почти 2-х недель складывали кусочки мозаики, совершая к ней самые различные вызовы и анализируя, к чему приводит каждый из них.
Посмотрите на эту картинку. Она показывает, что один внешний запрос побуждает сервис совершать множество внутренних вызовов, которые возвращаются обратно. Получается, что каждый внутренний вызов совершает дополнительные хопы, чтобы быть способным самостоятельно обслужить этот запрос, потому что не может больше никуда обратиться за получением нужной информации. Эта картинка выглядит бессмысленным каскадом вызовов, поскольку внешний запрос вызывает дополнительные сервисы, которые вызывают другие дополнительные сервисы, и так практически до бесконечности.

Зеленым цветом на этой схеме показан полукруг, в котором сервисы вызывают друг друга — сервис А вызывает сервис В, сервис В вызывает сервис С, а тот снова вызывает сервис А. В результате мы получаем «распределенный тупик». Единственный запрос создавал тысячу сетевых вызовов API, и поскольку система не обладала встроенной отказоустойчивостью и защитой от зацикливания, то запрос оканчивался неудачей, если хотя бы один из этих API-вызовов давал сбой.
Мы сделали некоторые математические вычисления. Каждый API-вызов имел SLA не более 150 мс и 99,9% аптайм. Один запрос вызывал 200 различных вызовов, и в наилучшем случае страница могла быть показана через 200×150 мс = 30 секунд. Естественно, это никуда не годилось. Перемножив 99,9% аптайм на 200, мы получали 0% доступность. Получается, что эта архитектура была обречена на провал с самого начала.
Мы обратились к разработчикам с вопросом, как же они не сумели разглядеть эту проблему на протяжение 18 месяцев работы? Оказалось, что они подчитывали SLA только для запущенного ими кода, но если их сервис вызывал другой сервис, они не считали это время в своих SLA. Все, что запускалось в пределах одного процесса, придерживалось значения 150 мс, но обращение к другим сервисным процессам многократно увеличивало суммарную задержку. Первый извлеченный из этого урок формулировался так: «Распоряжаетесь ли вы своим SLA или же SLA распоряжается вами»? В нашем случае выходило второе.
Следующее, что мы обнаружили — они знали про существование концепции заблуждений о распределенных вычислениях, сформулированной Питером Дейчем и Джеймсом Гослингом, но проигнорировали ее первую часть. В ней говорится, что утверждения «сеть надежна», «латентность нулевая» и «пропускная способность бесконечна» являются заблуждениями. Заблуждениями также являются утверждения «сеть безопасна», «топология никогда не меняется», «администратор всегда только один», «цена передачи данных нулевая» и «сеть однородна».
Они допустили ошибку, потому что обкатывали свой сервис на локальных машинах и никогда не «подцепляли» внешние сервисы. При локальной разработке и использовании локального кэша они никогда не сталкивались с сетевыми хопами. За все 18 месяцев разработки они ни разу не задались вопросом, что может случиться, если затронуть внешние сервисы.

Если посмотреть на границы сервисов на предыдущей картинке, видно, что все они неправильные. Существует масса источников, которые советуют, как определять границы сервисов, и большинство делают это неправильно, как например, Microsoft на следующем слайде.

Эта картинка из блога MS на тему «Как строить микросервисы». Здесь показано простое веб-приложение, блок бизнес-логики и база данных. Запрос поступает напрямую, вероятно, здесь имеется один сервер для веб, один сервер для бизнеса и один для БД. Если увеличить трафик, картинка немного поменяется.
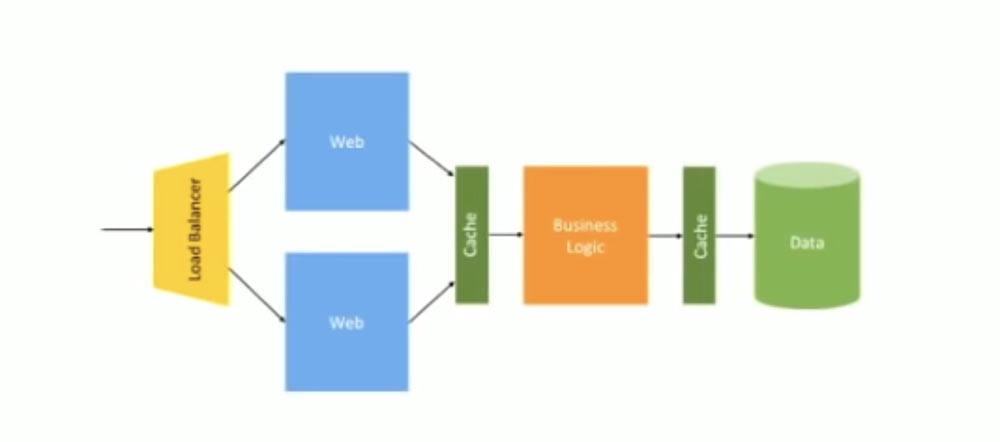
Здесь появляется балансировщик нагрузки для распределения трафика между двумя веб-серверами, кэш, расположенный между веб-сервисом и бизнес-логикой и еще один кэш между бизнес-логикой и базой данных. Именно такую архитектуру использовала компания Bell для своего приложения — балансировку нагрузки и blue/green развертывание, выполненное в середине 2000-х. До некоторого времени все работало хорошо, поскольку данная схема предназначалась для монолитной структуры.
На следующей картинке показано, как MS рекомендует осуществлять переход от монолита к микросервисам — просто разделить каждый из основных сервисов на отдельные микросервисы. Именно при внедрении этой схемы Bell и совершили ошибку.
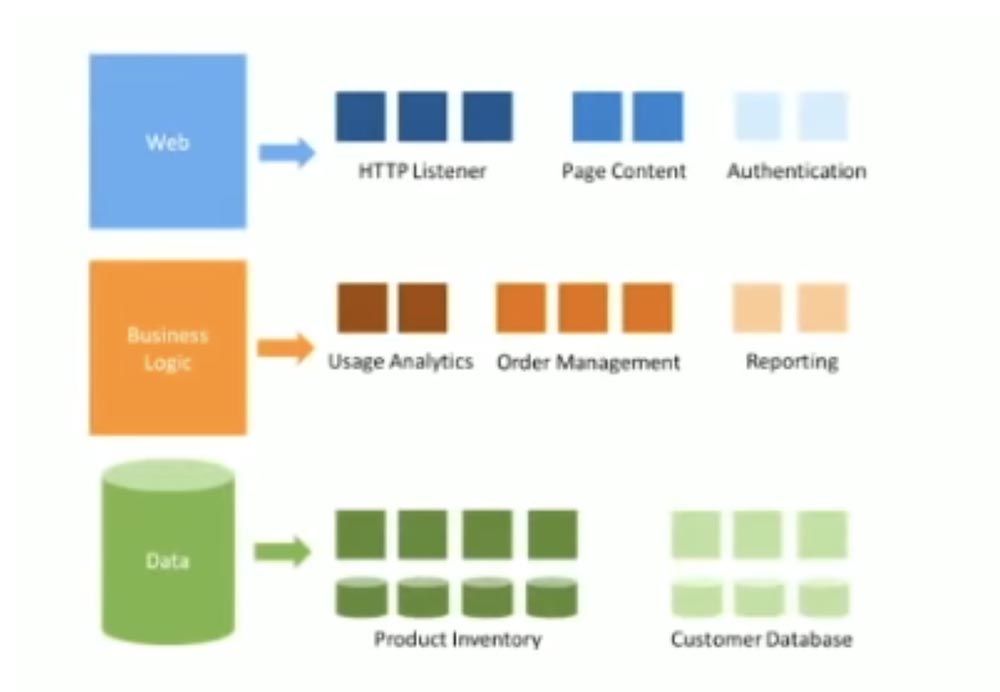
Они разбили все свои сервисы на разные уровни, каждый из которых состоял из множества индивидуальных сервисов. Например, веб-сервис включал в себя микросервисы для рендеринга контента и аутентификации, сервис бизнес-логики состоял из микросервисов для обработки заказов и информации об аккаунтах, база данных была разделена на кучу микросервисов со специализированными данными. И веб, и бизнес-логика, и БД представляли собой stateless-сервисы.
Однако эта картинка была абсолютно неправильной, потому что не картировала никакие бизнес-единицы вне IT-кластера компании. Данная схема не учитывала никакой связи с внешним миром, так что было непонятно, как, например, получать стороннюю бизнес-аналитику. Замечу, что у них к тому же было несколько сервисов, придуманных просто для развития карьеры отдельных сотрудников, которые стремились управлять как можно большим числом людей, чтобы получать за это больше денег.
Они считали, что для перехода на микросервисы достаточно просто взять их внутреннюю инфраструктуру физического уровня N-tier и вставить в нее Docker. Давайте взглянем, как же выглядит традиционная архитектура N-tier.
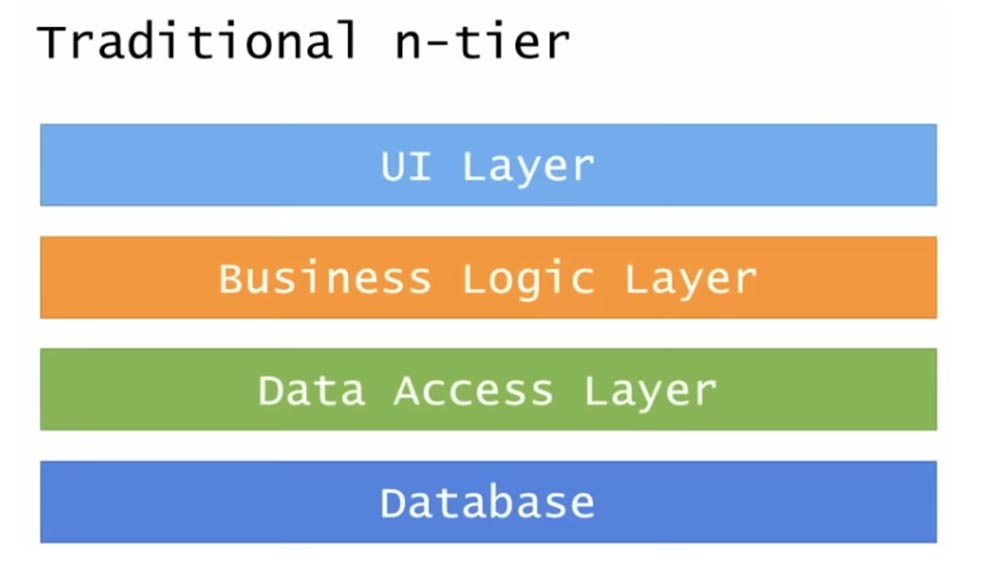
Она складывается из 4 уровней: уровень пользовательского интерфейса UI, уровень бизнес-логики, уровень доступа к данным и база данных. Более прогрессивна DDD (Domain-Driven Design), или программно-ориентированная архитектура, где два средних уровня представляют собой доменные объекты и репозиторий.
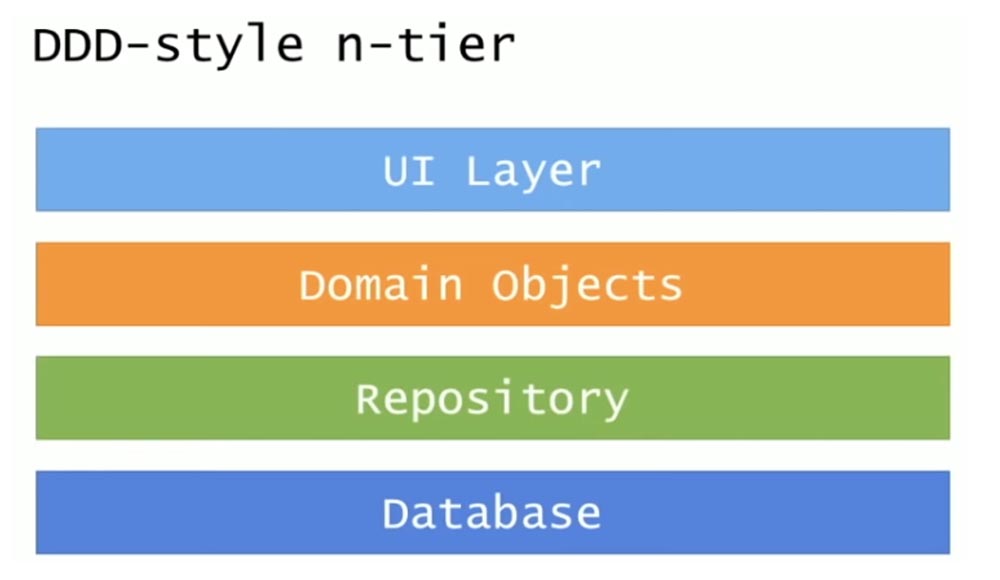
Я попытался рассмотреть в этой архитектуре различные области изменений, различные области ответственности. В обычном N-tier приложении классифицируются различные области изменений, которые пронизывают структуру вертикально сверху вниз. Это Catalog, настройки Config, выполняемые на индивидуальных компьютерах и проверки Checkout, которыми занималась моя команда.
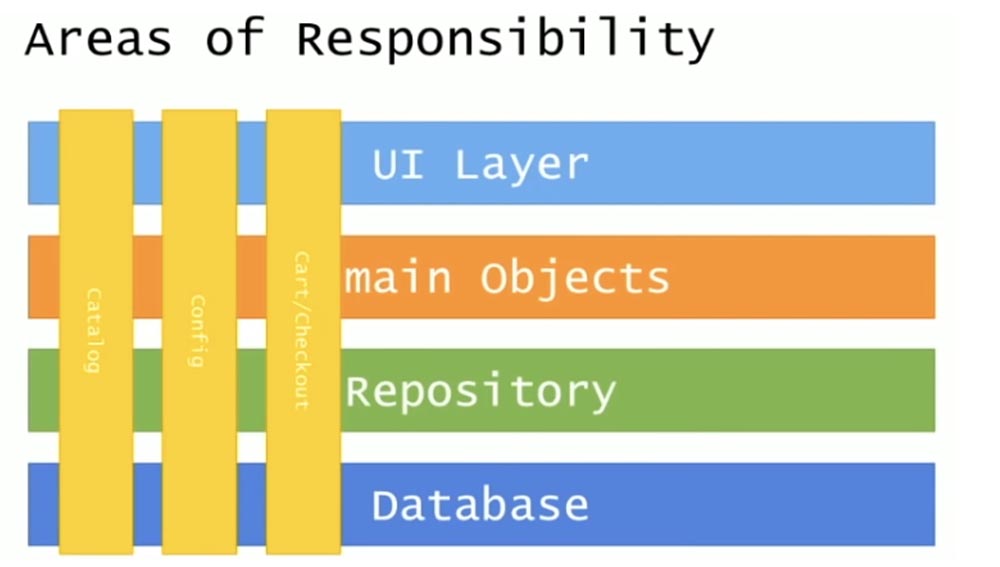
Особенность данной схемы заключается в том, что границы этих областей изменений затрагивают не только уровень бизнес-логики, но и распространяются на базу данных.
Давайте рассмотрим, что означает «быть сервисом». Существует 6 характерных свойств определения сервиса — это программное обеспечение, которое:
- создается и используется конкретной организацией;
- отвечает за содержание, обработку и/или предоставление определенного вида информации в рамках системы;
- может быть создано, развернуто и запущено независимо для удовлетворения определенных операционных задач;
- общается с потребителями и другими сервисами, предоставляя информацию на основе соглашений или договорных гарантий;
- защищает само себя от несанкционированного доступа, а свою информацию — от потери;
- оперирует сбоями таким образом, чтобы они не привели к повреждению информации.
Все эти свойства можно выразить одним словом «автономность». Сервисы работают независимо друг от друга, удовлетворяют определенным ограничениям, определяют контракты, на основе которых люди могут получать нужную им информацию. Я не упомянул специфичные технологии, использование которых подразумевается само собой.
Теперь рассмотрим определение микросервисов:
- микросервис имеет малый размер и предназначен для решения одной конкретной задачи;
- микросервис автономен;
- при создании архитектуры микросервиса используется метафора «городской планировки» town planning metaphor. Это определение из книги Сэма Ньюмана «Создание микросервисов».
Определение Bounded Context взято из книги Эрика Эванса «Domain-Driven Design». Это основной паттерн в DDD, центр проектирования архитектуры, который работает с объемными архитектурными моделями, разделяя их на разные Bounded Context и явно определяя взаимодействие между ними.
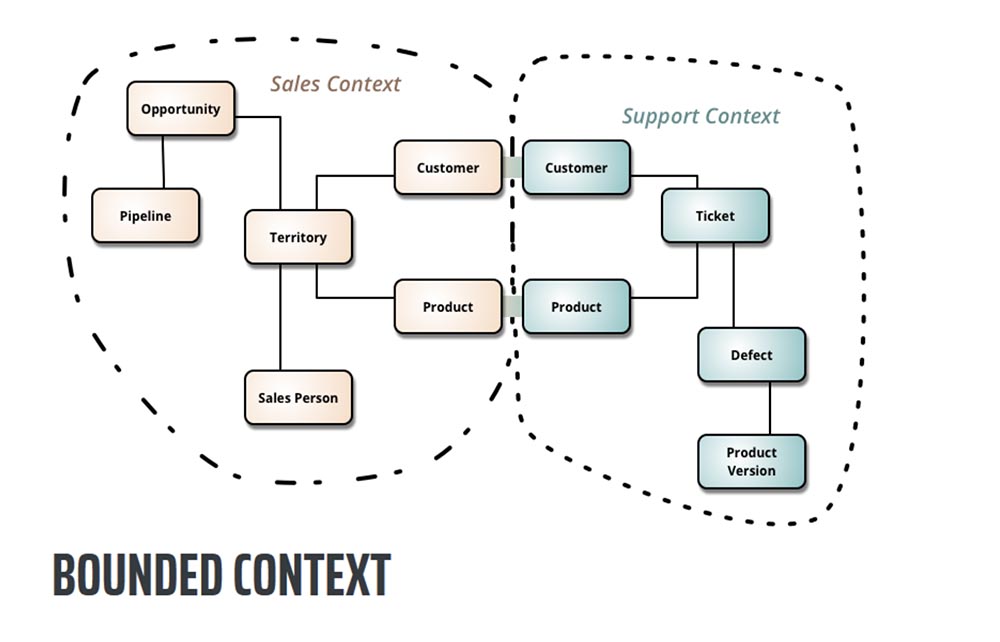
Проще говоря, ограниченный контекст Bounded Context обозначает область, в которой может применяться конкретный модуль. Внутри этого контекста расположена логически унифицированная модель, которую можно увидеть, например, в вашем бизнес-домене. Если вы спросите «кто такой клиент» у персонала, занимающегося заказами, то получите одно определение, если спросите у тех, кто занимается продажами — получите другое, а исполнители выдадут вам третье определение.
Так вот, Bounded Context говорит, что если мы не можем дать однозначного определения тому, что представляет собой потребитель наших услуг, давайте определим границы, в пределах которых можно рассуждать о значении этого термина, а затем определим точки перехода между этими различными определениями. То есть, если мы говорим о клиенте с точки зрения оформления заказов, это означает то-то и то-то, а если с точки зрения продаж — то-то и то-то.
Следующим определением микросервиса является инкапсуляция любого вида внутренних операций, предотвращающая «утечку» составляющих рабочего процесса в окружающую среду. Далее следует «определение явных контрактов для внешних взаимодействий, или внешних связей», которое представлено идеей контрактов, возвращающихся от SLA. Последним определением является метафора клетки, или ячейки, которая означает полную инкапсуляцию набора операций внутри микросервиса и наличие в нем рецепторов для общения с внешним миром.

Итак, мы сказали ребятам из Bell Computers: «Мы не сможем исправить ничего в созданном вами хаосе, потому что у вас просто не хватит для этого денег, но мы исправим всего один сервис, чтобы придать всему этому смысл». С этого места я начну рассказ о том, как мы исправили единственный сервис, чтобы он стал отвечать на запросы быстрее, чем через 9 с половиной минут.
22:30 мин
Продолжение будет совсем скоро…
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5–2697v3 2.6GHz 14C 64GB DDR4 4×960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5–2430 2.2Ghz 6C 128GB DDR3 2×960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?
