[Перевод] Когда вызовы функций через внешний интерфейс быстрее нативных вызовов C
Дополнено: хорошая дискуссия на Hacker News
Дэвид Ю на GitHub разработал интересный тест производительности для вызовов функций через разные внешние интерфейсы (Foreign Function Interfaces, FFI).
Он создал файл общего объекта (.so) с одной простой функцией C. Затем написал код для многократного вызова этой функции через каждый FFI с измерением времени.
Для C «FFI» он использовал стандартную динамическую компоновку, а не dlopen(). Это различие очень важно, так как действительно сказывается на результатах теста. Можно спорить, насколько честно такое сравнение с фактическим FFI, но всё равно его интересно измерить.
Самый удивительный результат бенчмарка — то, что FFI от LuaJIT существенно быстрее, чем C. Он примерно на 25% быстрее, чем нативный вызов C для функции общего объекта. Как смог слабо и динамически типизированный скриптовый язык обогнать в бенчмарке C? Точен ли результат?
На самом деле это вполне логично. Тест запущен на Linux, поэтому задержка идёт от таблицы компоновки процедур (Procedure Linkage Table, PLT). Я подготовил действительно простой эксперимент, чтобы продемонстрировать эффект в простом старом C:
https://github.com/skeeto/dynamic-function-benchmark
Вот результаты на Intel i7–6700 (Skylake):
plt: 1.759799 ns/call
ind: 1.257125 ns/call
jit: 1.008108 ns/call
Здесь три разных типа вызовов функций:
- Через PLT.
- Косвенный вызов функции (через
dlsym(3)) - Прямой вызов функции (через JIT-скомпилированную функцию)
Как видим, последний самый быстрый. Обычно он не используется в программах на C, но это естественный вариант в присутствии JIT-компилятора, включая, очевидно, и LuaJIT.
В моём бенчмарке вызывается функция empty():
void empty(void) { }
Компиляция в общий объект:
$ cc -shared -fPIC -Os -o empty.so empty.c
Как и в предыдущем сравнении ГПСЧ, бенчмарк сколько может многократно вызывает эту функцию, прежде чем сработает сигнал тревоги.
Когда программа или библиотека вызывает функцию в другом общем объекте, компилятор не может знать, где в памяти будет находиться эта функция. Информация выясняется только во время выполнения, когда программа и её зависимости загружены в память. Обычно функция располагается в случайных местах, например, в соответствии с рандомизацией адресного пространства (Address Space Layout Randomization, ASLR).
Как решать такую проблему? Ну, есть несколько вариантов.
Один из них — отмечать каждый вызов в метаданных двоичного файла. Динамический компоновщик рантайма затем вставляет правильный адрес при каждом вызове. Конкретный механизм зависит от кодовой модели, которая использовалась при компиляции.
Недостатком такого подхода является замедление загрузки, увеличение размера двоичных файлов и уменьшение обмена кодовыми страницами между различными процессами. Загрузка замедляется, потому что все динамические точки вызова нужно запатчить правильным адресом, прежде чем начать выполнение программы. Бинарник раздувается, потому что для каждой записи нужно место в таблице. А отсутствие общего доступа связано с изменением кодовых страниц.
С другой стороны, издержки на вызов динамических функций можно устранить, что даёт JIT-подобную производительность, как показано в бенчмарке.
Второй вариант — маршрутизация всех динамических вызовов через таблицу. Оригинальная точка вызова обращается к заглушке в этой таблице, а оттуда к фактической динамической функции. При таком подходе код не нужно патчить, что приводит к тривиальному обмену между процессами. На каждую динамическую функцию нужно запатчить только одну запись в таблице. Более того, эти исправления можно вносить лениво, при первом вызове функции, что ещё более ускоряет загрузку.
В системах с двоичными файлами ELF эта таблица называется таблицей компоновки процедур (Procedure Linkage Table, PLT). Сама PLT в реальности не исправляется — она отображается как read-only для остального кода. Вместо этого исправляется глобальная таблица смещения (Global Offset Table, GOT). Заглушка PLT извлекает адрес динамической функции из GOT и косвенно переходит на этот адрес. Чтобы лениво загрузить адреса функций, эти записи GOT инициализируются с адресом функции, которая находит целевой символ, обновляет GOT этим адресом, а затем переходит к данной функции. Последующие вызовы используют лениво обнаруженный адрес.
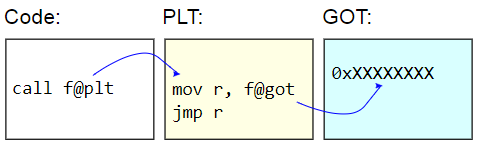
Недостатком PLT являются дополнительные накладные расходы на вызов динамической функции, что и проявилось в бенчмарке. Поскольку бенчмарк измеряет только вызовы функций, то разница кажется довольно значительной, но на практике она обычна близка к нулю.
Вот бенчмарк:
/* Cleared by an alarm signal. */
volatile sig_atomic_t running;
static long
plt_benchmark(void)
{
long count;
for (count = 0; running; count++)
empty();
return count;
}
Поскольку empty() находится в общем объекте, то вызов идёт через PLT.
Другой способ динамического вызова функций — обход вокруг PLT и получение адреса целевой функции в программе, например, через dlsym(3).
void *h = dlopen("path/to/lib.so", RTLD_NOW);
void (*f)(void) = dlsym("f");
f();
Если адрес функции получен, то издержки меньше, чем на вызовы функции через PLT. Нет промежуточной функции заглушки и доступа к GOT. (Предостережение: если программа имеет запись PLT для данной функции, тогда dlsym(3) в реальности может фактически вернуть адрес заглушки).
Но это по-прежнему косвенный вызов. На обычных архитектурах прямые вызовы функции получают её непосредственный относительный адрес. То есть целью вызова является некоторое жёстко закодированное смещение от точки вызова. CPU может гораздо раньше понять, куда пойдёт вызов.
У косвенных вызовов больше издержек. Во-первых, адрес нужно где-то хранить. Даже если это просто регистр, его использование увеличивает дефицит регистров. Во-вторых, косвенные вызовы провоцируют предсказатель ветвлений в CPU, накладывая дополнительную нагрузку на процессор. В самом худшем случае вызов может даже привести к остановке конвейера.
Вот бенчмарк:
volatile sig_atomic_t running;
static long
indirect_benchmark(void (*f)(void))
{
long count;
for (count = 0; running; count++)
f();
return count;
}
Переданная этому бенчмарку функция извлекается с помощью dlsym(3), поэтому компилятор не может сделать что-то хитрое, вроде преобразования этого косвенного вызова обратно в прямой.
Если тело цикла достаточно сложное, чтобы вызвать дефицит регистров и тем самым выдавая адрес на стек, то этот бенчмарк тоже нельзя честно сравнивать с бенчмарком PLT.
Первые два типа вызовов динамических функций просты и удобны в использовании. Прямые вызовы для динамических функций сложнее организовать, поскольку они требуют изменения кода во время его выполнения. В своём бенчмарке я собрал небольшой JIT-компилятор для генерации прямого вызова.
Хитрость в том, что на x86–64 явные переходы ограничены диапазоном 2 ГБ из-за 32-разрядного непосредственного операнда со знаком (signed immediate). Это означает, что JIT-код следует разместить практически рядом с целевой функцией, empty(). Если JIT-код должен вызвать две разные динамические функции, разделённые более чем на 2 ГБ, то невозможно сделать два прямых вызова.
Чтобы упростить ситуацию, мой бенчмарк не беспокоится о точном или очень осторожном выборе адреса JIT-кода. После получения адреса целевой функции он просто вычитает 4 МБ, округляет до ближайшей страницы, выделяет немного памяти и записывает в неё код. Если же всё делать как следует, то для поиска места нужно проверить собственные представления программы в памяти, и это невозможно сделать чистым портируемым способом. В Linux требуется разбор виртуальных файлов под /proc.
Вот как у меня выглядит выделение памяти JIT. Оно предполагает разумное поведение для приведения типов uintptr_t:
static void
jit_compile(struct jit_func *f, void (*empty)(void))
{
uintptr_t addr = (uintptr_t)empty;
void *desired = (void *)((addr - SAFETY_MARGIN) & PAGEMASK);
/* ... */
unsigned char *p = mmap(desired, len, prot, flags, fd, 0);
/* ... */
}
Здесь выделяется две страницы: одна для записи, а другая с незаписываемым кодом. Как и в моей библиотеке для замыканий, здесь нижняя страница доступна для записи и содержит переменную running, которая обнуляется по сигналу тревоги. Эта страница должна находиться рядом с JIT-кодом, чтобы предоставлять эффективный доступ относительно RIP, как функции в двух остальных бенчмарках. Верхняя страница содержит такой ассемблерный код:
jit_benchmark:
push rbx
xor ebx, ebx
.loop: mov eax, [rel running]
test eax, eax
je .done
call empty
inc ebx
jmp .loop
.done: mov eax, ebx
pop rbx
ret
call empty — единственная динамически генерируемая инструкция, она необходима для правильного заполнения относительного адреса (минус 5 указано относительно конца инструкции):
// call empty
uintptr_t rel = (uintptr_t)empty - (uintptr_t)p - 5;
*p++ = 0xe8;
*p++ = rel >> 0;
*p++ = rel >> 8;
*p++ = rel >> 16;
*p++ = rel >> 24;
Если функция empty() находится не в общем объекте, а в том же двоичном файле, то это по сути прямой вызов, который компилятор сгенерирует для plt_benchmark(), предполагая, что почему-то не встроил empty().
По иронии судьбы, вызов JIT-скомпилированного кода требует косвенного вызова (например, через указатель функции), и это никак не обойти. Что тут сделать, JIT-скомпилировать другую функцию для прямого вызова? К счастью, это не имеет значения, потому что в цикле измеряется только прямой вызов.
С учётом этих результатов становится понятно, почему LuaJIT генерирует более эффективные вызовы динамических функций, чем PLT, даже если они остаются косвенными вызовами. В моём бенчмарке непрямые вызовы без PLT были на 28% быстрее, чем с PLT, а прямые вызовы без PLT на 43% быстрее, чем с PLT. Это маленькое преимущество JIT-программ перед простыми старыми нативными программами достигается за счёт абсолютного отказа от обмена кода между процессами.
