[Перевод] Когда TCP-сокеты отказываются умирать
В поисках причин, почему установленные соединения не разрываются в некоторых случаях, я набрёл на отличную статью в блоге Cloudflare. Которая, в итоге помогла найти не только решение моей проблемы, но и помогла лучше понять как работают таймауты TCP соединений в Linux
Надеюсь перевод этой статьи будет полезен многим читателям хабра.
Начало
Работая над нашим сервером Spectrum, мы заметили нечто странное: TCP-сокеты, которые, как мы думали, должны были быть закрыты, оставались на месте. Мы поняли, что не совсем понимаем, когда TCP-сокеты должны завершать работу!
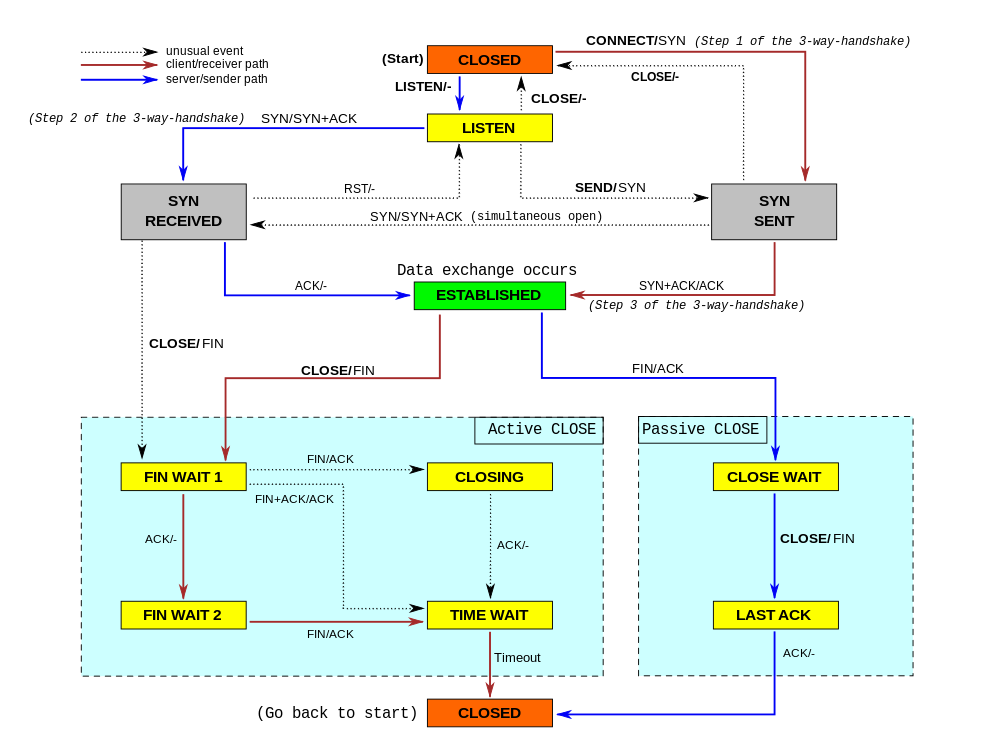 Image by Sergiodc2 CC BY SA 3.0
Image by Sergiodc2 CC BY SA 3.0
В нашем коде мы хотели убедиться, что мы не держим соединения с мертвыми хостами. В нашем раннем коде мы наивно полагали, что включения TCP keepalives будет достаточно…, но это не так. Оказалось, что довольно современная опция сокета TCP_USER_TIMEOUT не менее важна. Более того, она тонко взаимодействует с TCP keepalives. Многих это ставит в тупик.
В этой статье блога мы постараемся показать, как работают эти опции. Мы покажем, как TCP сокет может прерваться по времени на различных этапах своего существования, и как на это влияют TCP keepalives и пользовательский таймаут. Чтобы лучше проиллюстрировать внутреннее устройство TCP-соединений, мы смешаем результаты команд tcpdump и ss -o. Это наглядно показывает передаваемые пакеты и изменяющиеся параметры TCP-соединений.
SYN-SENT
Начнем с самого простого случая — что происходит при попытке установить соединение с сервером, который отбрасывает входящие SYN-пакеты?
Используемые здесь скрипты доступны на нашем Github.
 syn-sent
syn-sent
Хорошо, это было просто. После системного вызова connect () операционная система посылает SYN-пакет. Поскольку она не получила никакого ответа, ОС по умолчанию повторит попытку отправки 6 раз. Это можно настроить с помощью sysctl:
$ sysctl net.ipv4.tcp_syn_retries
net.ipv4.tcp_syn_retries = 6Можно переписать эту настройку для каждого сокета с помощью параметра TCP_SYNCNT setsockopt:
setsockopt(sd, IPPROTO_TCP, TCP_SYNCNT, 6);Повторные попытки выполняются в шахматном порядке с интервалами 1с, 3с, 7с, 15с, 31с, 63с (время между повторными попытками начинается с 2с и затем каждый раз удваивается). По умолчанию весь процесс занимает 130 секунд, пока ядро не сдастся с ошибкой ETIMEDOUT errno. В этот момент времени жизни соединения настройки SO_KEEPALIVE игнорируются, а TCP_USER_TIMEOUT — нет. Например, установка значения 5000 мс приведет к следующему взаимодействию:
 syn-sent-500
syn-sent-500
Несмотря на то, что мы установили время ожидания пользователя равным 5с, мы все еще видели шесть повторов SYN на сокете. Такое поведение, вероятно, является ошибкой (проверено на ядре 5.2): мы ожидали, что будет отправлено только две повторные попытки — на отметках 1с и 3с, а сокет истечет на отметке 5с. Вместо этого мы увидели это, но также мы увидели еще 4 повторно переданных SYN-пакета, выровненных по 5s отметке — что не имеет смысла. Так или иначе, мы узнали одну вещь — TCP_USER_TIMEOUT действительно влияет на поведение connect ().
SYN-RECV
Сокеты SYN-RECV обычно скрыты от приложения. Они живут как мини-сокеты в очереди SYN. В прошлом мы писали об очередях SYN и Accept. Иногда, когда включены файлы cookie SYN, сокеты могут вообще пропустить состояние SYN-RECV.
В состоянии SYN-RECV сокет повторит попытку отправки SYN + ACK 5 раз, это контролируется:
$ sysctl net.ipv4.tcp_synack_retries
net.ipv4.tcp_synack_retries = 5Вот как это выглядит в кабеле:
 syn-recv
syn-recv
С настройками по умолчанию SYN+ACK повторно передается с отметками 1с, 3с, 7с, 15с, 31с, а сокет SYN-RECV исчезает с отметкой 64с.
Ни SO_KEEPALIVE, ни TCP_USER_TIMEOUT не влияют на время жизни сокетов SYN-RECV.
Заключительное рукопожатие ACK (Final handshake ACK)
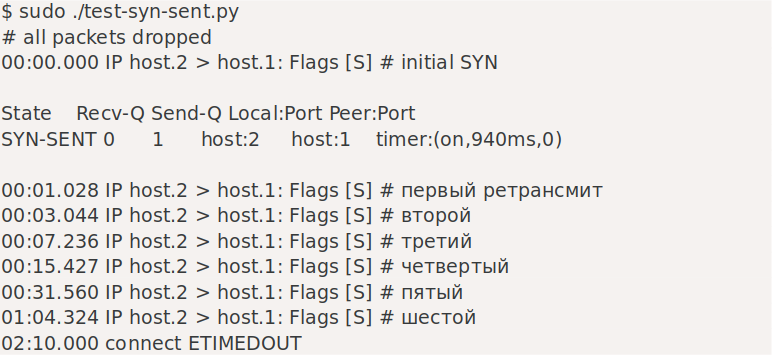
После получения второго пакета в TCP-рукопожатии — SYN+ACK — клиентский сокет переходит в установленное состояние. Серверный сокет остается в SYN-RECV до тех пор, пока не получит окончательный пакет ACK.
Потеря этого ACK ничего не меняет — сокету сервера просто потребуется немного больше времени, чтобы перейти от SYN-RECV к ESTAB. Вот как это выглядит:
 test-syn-ack
test-syn-ack
Как вы можете видеть, SYN-RECV имеет таймер «on», такой же, как в предыдущем примере. Мы могли бы возразить, что этот окончательный ACK на самом деле не имеет большого веса. Это мышление привело к разработке функции TCP_DEFER_ACCEPT — она в основном приводит к тому, что третий ACK автоматически отбрасывается. С установленным этим флагом сокет остается в состоянии SYN-RECV до тех пор, пока не получит первый пакет с фактическими данными:
 test-syn-ack2
test-syn-ack2
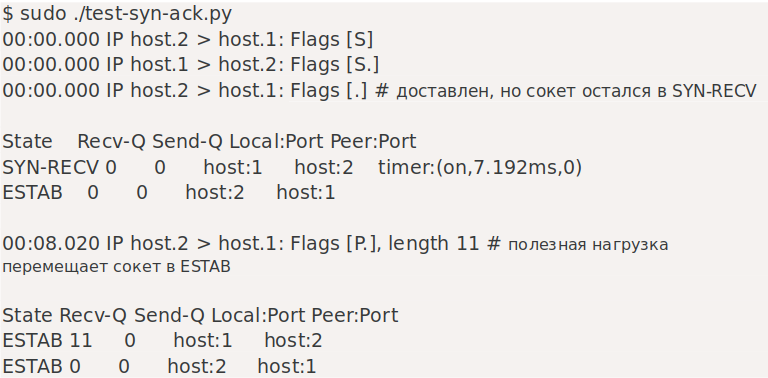
Серверный сокет оставался в состоянии SYN-RECV даже после получения окончательного подтверждения TCP-рукопожатия. У него забавный таймер «on», счетчик застревает на 0 повторных попытках. Он преобразуется в ESTAB — и перемещается из SYN в очередь приема — после того, как клиент отправляет пакет данных или по истечении таймера TCP_DEFER_ACCEPT. По сути, при ОТЛОЖЕННОМ ПРИНЯТИИ мини-сокет SYN-RECV отбрасывает входящий ACK без данных.
Простаивающий ESTAB — это навсегда (Idle ESTAB is forever)
Давайте продолжим и обсудим полностью установленный сокет, подключенный к нездоровому (мертвому) узлу. После завершения рукопожатия сокеты с обеих сторон переходят в установленное состояние, например:
 ESTABLISHED
ESTABLISHED
По умолчанию у этих сокетов нет таймера запуска — они останутся в этом состоянии навсегда, даже если связь прервана. Стек TCP заметит проблемы только тогда, когда одна сторона попытается что-то отправить. В связи с этим возникает вопрос — что делать, если вы не планируете отправлять какие-либо данные по соединению? Как вы можете убедиться, что незанятое соединение исправно, не отправляя по нему никаких данных?
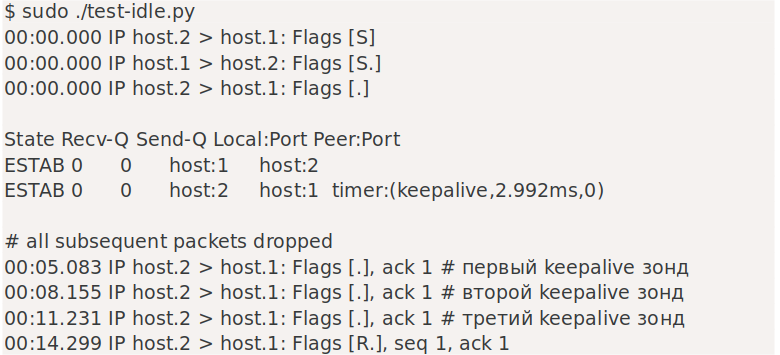
Вот тут-то и пригодятся TCP keepalives. Давайте посмотрим на это в действии — в этом примере мы использовали следующие переключатели:
SO_KEEPALIVE = 1 — Давайте включим keepalives.
TCP_KEEPIDLE = 5 — Отправить первый зонд keepalive после 5 секунд бездействия.
TCP_KEEPINTVL = 3 — отправка последующих пробников keepalive через 3 секунды.
TCP_KEEPCNT = 3 — Тайм-аут после трех неудачных попыток.
 test-idle
test-idle
Действительно! Мы можем ясно видеть первый зонд, отправленный на отметке 5 секунд, два оставшихся зонда на расстоянии 3 секунд друг от друга — точно так, как мы указали. В общей сложности после трех отправленных зондов и еще трех секунд задержки соединение прерывается с помощью ETIMEDOUT, и, наконец, передается RST.
Чтобы keepalives работал, буфер отправки должен быть пустым. Вы можете заметить, что таймер keepalive активен в строке «таймер: (keepalive)».
Keepalives с TCP_USER_TIMEOUT сбивают с толку
Мы уже упоминали параметр TCP_USER_TIMEOUT. Он устанавливает максимальное время, в течение которого переданные данные могут оставаться неопознанными, прежде чем ядро принудительно закроет соединение. Сам по себе он мало что делает в случае неработающих соединений. Сокеты останутся ESTABLISHED, даже если соединение будет разорвано. Однако эта опция сокета изменяет семантику TCP keepalives. Руководство по tcp (7) несколько запутано:
Более того, при использовании с опцией TCP keepalive (SO_KEEPALIVE), TCP_USER_TIMEOUT будет преобладать над keepalive для определения момента закрытия соединения из-за отказа keepalive.
Исходное сообщение коммита содержит немного больше деталей:
To understand the semantics, we need to look at the kernel code in linux/net/ipv4/tcp_timer.c:693:
 tcp-timers.c
tcp-timers.c
Чтобы тайм-аут пользователя имел какой-либо эффект, значение icsk_probes_out не должно быть равно нулю. Проверка тайм-аута пользователя выполняется только после того, как вышел первый зонд. Давайте проверим это. Наши настройки подключения:
TCP_USER_TIMEOUT = 5×1000 — 5 seconds
SO_KEEPALIVE = 1 — enable keepalives
TCP_KEEPIDLE = 1 — быстрая отправка первого зонда — 1 секунда простоя
TCP_KEEPINTVL = 11 — последующие зонды каждые 11 секунд
TCP_KEEPCNT = 3 — отправить три зонда до истечения времени ожидания
 keepalive
keepalive
Что же произошло? Соединение отправило первый зонд keepalive на отметке 1с. Не увидев ответа, стек TCP проснулся через 11 секунд, чтобы послать второй зонд. На этот раз, однако, он выполнил путь кода USER_TIMEOUT, который решил немедленно прервать соединение.
Что, если мы увеличим TCP_USER_TIMEOUT до больших значений, скажем, между вторым и третьим зондом? Затем соединение будет закрыто по таймеру третьего зонда. С TCP_USER_TIMEOUT, установленным на 12,5с:
 keepalive_3_probe
keepalive_3_probe
Мы показали, как TCP_USER_TIMEOUT взаимодействует с keepalives для малых и средних значений. Последний случай — это когда TCP_USER_TIMEOUT необычайно велик. Допустим, мы установим его на 30 секунд:
 keepalive_30s
keepalive_30s
Мы видели шесть зондов keepalive на проводе! При установке TCP_USER_TIMEOUT TCP_KEEPCNT полностью игнорируется. Если вы хотите, чтобы TCP_KEEPCNT имел смысл, единственное разумное значение USER_TIMEOUT немного меньше, чем:
TCP_KEEPIDLE + TCP_KEEPINTVL * TCP_KEEPCNTЗанятый сокет ESTAB не вечен (Busy ESTAB socket is not forever)
До сих пор мы обсуждали случай, когда соединение простаивает. Другие правила применяются, когда соединение имеет не принятые данные в буфере отправки.
Давайте подготовим другой эксперимент — после трехстороннего рукопожатия настроим брандмауэр на отбрасывание всех пакетов. Затем выполним отправку на одном конце, чтобы иметь несколько отброшенных пакетов в полете. Эксперимент показывает, что отправляющий сокет умирает через ~16 минут:
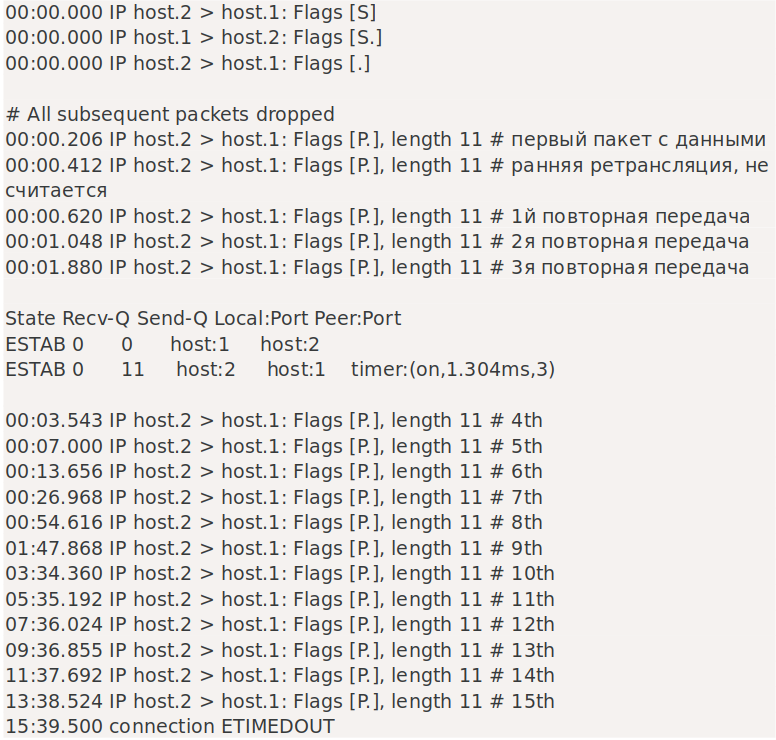 tcp_retries2
tcp_retries2
Пакет данных повторно передается 15 раз, что контролируется:
$ sysctl net.ipv4.tcp_retries2
net.ipv4.tcp_retries2 = 15Из документации ip-sysctl.txt:
Значение по умолчанию, равное 15, дает гипотетический тайм-аут в 924,6 секунды и является нижней границей эффективного тайм-аута. TCP фактически отключит время ожидания при первом RTO, которое превышает гипотетический тайм-аут.
Соединение действительно прервалось через ~ 940 секунд. Обратите внимание, что в сокете запущен таймер «on». Если мы установим SO_KEEPALIVE — не будет иметь никакого значения — когда таймер «on» запущен, keepalives не задействованы.
TCP_USER_TIMEOUT продолжает работать до конца. Соединение будет прервано точно по истечении указанного пользователем времени ожидания с момента последнего полученного пакета. При установленном таймауте пользователя значение tcp_retries2 игнорируется.
Нулевое окно ESTAB — это… навсегда?(Zero window ESTAB is… forever?)
Есть последний случай, о котором стоит упомянуть. Если у отправителя много данных, а приемник медленный, то включается TCP flow control. В какой-то момент получатель попросит отправителя прекратить передачу новых данных. Это несколько иное состояние, чем описанное выше.
В этом случае, когда включено управление потоком, нет никаких летящих или не подтвержденных данных. Вместо этого приемник дросселирует отправителя уведомлением о «нулевом окне». Затем отправитель периодически проверяет, действительно ли это условие, с помощью «зондов окна». В этом эксперименте мы уменьшили размер буфера приема, для простоты. Вот как это выглядит на проводе:

Захват пакетов показывает несколько вещей. Во-первых, мы видим два пакета с данными, каждый длиной 576 байт. Оба они были немедленно подтверждены. Второй ACK содержит уведомление «win 0»: отправителю было сказано прекратить отправку данных.
Но отправитель жаждет отправить еще! Последние два пакета показывают первый «зонд окна»: отправитель будет периодически посылать пакеты «ack» без полезной нагрузки, чтобы проверить, не изменился ли размер окна. До тех пор, пока получатель продолжает отвечать, отправитель будет посылать такие запросы вечно. Информация о сокете показывает три важные вещи:
Буфер чтения считывателя заполнен — таким образом, ожидается регулирование «нулевого окна».
Буфер записи отправителя заполнен — у нас есть больше данных для отправки.
У отправителя запущен таймер «persist», отсчитывающий время до следующего «оконного зонда».
В этой статье блога нас интересуют таймауты — что произойдет, если зонды окна будут потеряны? Заметит ли это отправитель?
По умолчанию оконный зонд повторяется 15 раз — в соответствии с обычной настройкой tcp_retries2.
Таймер tcp находится в состоянии persist, поэтому TCP keepalives не будет запущен. Настройки SO_KEEPALIVE не имеют никакого значения, если задействовано оконное зондирование.
Как и ожидалось, тумблер TCP_USER_TIMEOUT продолжает работать. Небольшое отличие заключается в том, что аналогично user-timeout для keepalives, он включается только при срабатывании таймера повторной передачи. Во время такого события, если с момента последнего хорошего пакета прошло более чем user-timeout секунд, соединение будет прервано.
Примечание об использовании тайм-аутов приложений
В прошлом мы делились интересной военной историей:
Наш HTTP-сервер прекращал соединение после истечения тайм-аута, управляемого приложением. Это была ошибка — медленное соединение могло правильно медленно опустошать буфер отправки, но сервер приложения этого не замечал.
Мы резко прекратили медленную загрузку, хотя это не входило в наши намерения. Мы просто хотели убедиться, что клиентское соединение все еще исправно. Было бы лучше использовать TCP_USER_TIMEOUT, чем полагаться на таймауты, управляемые приложением.
Но этого недостаточно. Мы также хотели защититься от ситуации, когда клиентский поток действителен, но завис и не разрывает соединение. Единственный способ добиться этого — периодически проверять количество не отправленных данных в буфере отправки и смотреть, уменьшается ли оно с нужной скоростью.
Для типичных приложений, отправляющих данные в Интернет, я бы рекомендовал:
Включите TCP keepalives. Это необходимо для поддержания потока некоторых данных в случае бездействующего соединения.
Установите TCP_USER_TIMEOUT равным:
TCP_KEEPIDLE + TCP_KEEPINTVL * TCP_KEEPCNT
Будьте осторожны при использовании тайм-аутов, управляемых приложением. Для обнаружения сбоев TCP используйте TCP keepalives и user-timeout. Если вы хотите сэкономить ресурсы и убедиться, что сокеты не работают слишком долго, подумайте о том, чтобы периодически проверять, истощается ли сокет с желаемой скоростью. Для этого вы можете использовать ioctl (SIOCOUTQ), но он учитывает как данные, буферизованные (не отправленные) в сокете, так и байты в полете (неподтвержденные). Лучший способ — использовать параметр TCP_INFO tcpi_notsent_bytes, который сообщает только о первом счетчике.
Пример проверки темпа слива:
 pace_in_bytes_per_second
pace_in_bytes_per_second
Есть способы еще больше улучшить эту логику. Мы могли бы использовать TCP_NOTSENT_LOWFAT, хотя обычно это полезно только в ситуациях, когда буфер отправки относительно пуст. Тогда мы могли бы использовать интерфейс SO_TIMESTAMPING для уведомлений о том, когда данные будут доставлены. Наконец, если мы закончили отправку данных в сокет, можно просто вызвать close () и отложить обработку сокета для операционной системы. Такой сокет будет застрять в состоянии FIN-WAIT-1 или LAST-ACK до тех пор, пока он правильно не опустеет.
Выводы
В этом посте мы обсудили пять случаев, когда TCP-соединение может заметить, что другая сторона уходит:
SYN-SENT: продолжительность этого состояния можно контролировать с помощью TCP_SYNCNT или tcp_syn_retries.
SYN-RECV: обычно это скрыто от приложения. Он настраивается с помощью tcp_synack_retries.
Простаивающее ESTABLISHED соединение, никогда не заметит никаких проблем. Решением является использование TCP keepalives.
Зависшее ESTABLISHED соединение, придерживается настройки tcp_retries2 и игнорирует TCP keepalives.
Соединение ESTABLISHED с нулевым окном, придерживается настройки tcp_retries2 и игнорирует TCP keepalives.
В частности, два последних случая ESTABLISHED, могут быть настроены с помощью TCP_USER_TIMEOUT, но, эта настройка влияет и на другие ситуации. Вообще говоря, его можно рассматривать как подсказку ядру прервать соединение через столько-то секунд после последнего хорошего пакета.
Однако это опасная настройка, и если она используется в сочетании с TCP keepalives, ее следует устанавливать на значение немного меньше, чем TCP_KEEPIDLE + TCP_KEEPINTVL * TCP_KEEPCNT. В противном случае оно будет влиять на значение TCP_KEEPCNT и потенциально аннулировать его.
В этом посте мы представили сценарии, демонстрирующие влияние опций сокетов, связанных с таймаутом, в различных сетевых условиях. Чередование захвата пакетов tcpdump с выводом ss -o — отличный способ понять работу сетевого стека. Мы смогли создать воспроизводимые тестовые примеры, демонстрирующие таймеры «on», «keepalive» и «persist» в действии. Это очень полезная основа для дальнейших экспериментов.
Наконец, удивительно трудно настроить TCP-соединение так, чтобы быть уверенным, что удаленный узел действительно работает. Во время отладки мы обнаружили, что просмотр размера буфера отправки и текущего активного таймера TCP может быть очень полезен для понимания того, действительно ли сокет здоров. Ошибка в нашем приложении Spectrum оказалась в неправильной настройке TCP_USER_TIMEOUT — без нее сокеты с большими буферами отправки задерживались гораздо дольше, чем мы предполагали.
Скрипты, использованные в этой статье, можно найти на нашем Github.
Для решения этой задачи пришлось сотрудничать с тремя офисами Cloudflare. Спасибо Хирену Панчасаре из Сан-Хосе, Уоррену Нельсону из Остина и Якубу Ситницки из Варшавы.
Автор оригинальной статьи: Марек Майковски.
Ссылка на оригинальный пост: link
