[Перевод] Как выбирать алгоритмы для машинного обучения Microsoft Azure

Ответ на вопрос «Какой алгоритм машинного обучения использовать?» всегда звучит так: «Смотря по обстоятельствам». Выбор алгоритма зависит от объема, качества и природы данных. Он зависит от того, как вы распорядитесь результатом. Он зависит от того, как из алгоритма были созданы инструкции для реализующего его компьютера, а еще от того, сколько у вас времени. Даже самые опытные специалисты по анализу данных не скажут вам, какой алгоритм лучше, пока сами не попробуют.
Шпаргалка по алгоритмам машинного обучения Microsoft Azure
Скачать шпаргалку по алгоритмам машинного обучения Microsoft Azure можно здесь.
Она создана для начинающих специалистов по анализу данных с достаточным опытом в сфере машинного обучения, которые хотят выбрать алгоритм для использования в Студии машинного обучения Azure. Это означает, что информация в шпаргалке обобщена и упрощена, но она покажет вам нужное направление дальнейших действий. Также в ней представлены далеко не все алгоритмы. По мере того как машинное обучение Azure будет развиваться и предлагать больше методов, алгоритмы будут дополняться.
Эти рекомендации созданы на основе отзывов и советов множества специалистов по анализу данных и экспертов по машинному обучению. Мы не во всем согласны друг с другом, но постарались обобщить наши мнения и достичь консенсуса. Большинство спорных моментов начинаются со слов «Смотря по обстоятельствам…» :)
Как использовать шрагалку
Читать метки пути и алгоритма на схеме нужно так: «Для <метка пути> использовать <алгоритм>». Например, «Для speed использовать two class logistic regression». Иногда можно использовать несколько ветвей. Иногда ни одна из них не будет идеальным выбором. Это всего лишь рекомендации, поэтому не беспокойтесь о неточностях. Некоторые специалисты по анализу данных, с которыми мне удалось пообщаться, говорят, что единственный верный способ найти лучший алгоритм — попробовать их все.
Вот пример эксперимента из Cortana Intelligence Gallery, в котором пробуются несколько алгоритмов с одними и теми же данными и сравниваются результаты.
Скачать и распечатать диаграмму с обзором возможностей Студии машинного обучения можно в этой статье.
Разновидности машинного обучения
Обучение с учителем
Алгоритмы обучения с учителем делают прогнозы на основе набора примеров. Так, чтобы предсказать цены в будущем, можно использовать курс акций в прошлом. Каждый пример, используемый для обучения, получает свою отличительную метку значения, в данном случае это курс акций. Алгоритм обучения с учителем ищет закономерности в этих метках значений. Алгоритм может использовать любую важную информацию — день недели, время года, финансовые данные компании, вид отрасли, наличие серьезных геополитических событий, и каждый алгоритм ищет разные виды закономерностей. После того как алгоритм находит подходящую закономерность, с ее помощью он делает прогнозы по неразмеченным тестовым данным, чтобы предугадать цены в будущем.
Это популярный и полезный тип машинного обучения. За одним исключением все модули машинного обучения Azure являются алгоритмами обучения с учителем. В службах машинного обучения Azure представлено несколько конкретных видов машинного обучения с учителем: классификация, регрессия и выявление аномалий.
- Классификация. Когда данные используются для прогнозирования категории, обучение с учителем называется классификацией. В этом случае происходит назначение изображения, например «кот» или «собака». Когда есть только два варианта выбора, это называется двухклассовой классификацией. Когда категорий больше, например, при прогнозировании победителя турнира NCAA March Madness, это называется многоклассовой классификацией.
- Регрессия. Когда прогнозируется значение, например, в случае с курсом акций, обучение с учителем называется регрессией.
- Фильтрация выбросов. Иногда нужно определить необычные точки данных. Например, при обнаружении мошенничества под подозрение попадают любые странные закономерности трат средств с кредитной карты. Возможных вариантов так много, а примеров для обучения так мало, что практически невозможно узнать, как будет выглядеть мошенническая деятельность. При фильтрации выбросов просто изучается нормальная активность (с помощью архива допустимых транзакций) и находятся все операции с заметными отличиями.
Обучение без учителя
В рамках обучения без учителя у объектов данных нет меток. Вместо этого алгоритм обучения без учителя должен организовать данные или описать их структуру. Для этого их можно сгруппировать в кластеры, чтобы они стали более структурированными, или найти другие способы упростить сложные данные.
Обучение с подкреплением
В рамках обучения с подкреплением алгоритм выбирает действие в ответ на каждый входящий объект данных. Через некоторое время алгоритм обучения получает сигнал вознаграждения, который указывает, насколько правильным было решение. На этом основании алгоритм меняет свою стратегию, чтобы получить наивысшую награду. В настоящее время в машинном обучении Azure нет модулей обучения с подкреплением. Обучение с подкреплением распространено в роботехнике, где набор показаний датчика в определенный момент времени является объектом, и алгоритм должен выбрать следующее действие робота. Кроме того, этот алгоритм подходит для приложений в Интернете вещей.
Советы по выбору алгоритма
Точность
Не всегда нужен самый точный ответ. В зависимости от цели иногда достаточно получить примерный ответ. Если так, то вы можете значительно сократить время отработки, выбирая приближенные методы. Еще одно преимущество приближенных методов заключается в том, что они исключают переобучение.
Время обучения
Количество минут или часов, необходимых для обучения модели, сильно зависит от алгоритмов. Зачастую время обучения тесно связано с точностью — они определяют друг друга. Кроме того, некоторые алгоритмы более чувствительны к объему обучающей выборки, чем другие. Ограничение по времени помогает выбрать алгоритм, особенно если используется обучающая выборка большого объема.
Линейность
Во многих алгоритмах машинного обучения используется линейность. Алгоритмы линейной классификации предполагают, что классы можно разделить прямой линией (или ее более многомерным аналогом). Здесь речь идет о логистической регрессии и метод опорных векторов (в машинном обучении Azure). Алгоритмы линейной регрессии предполагают, что распределение данных описывается прямой линией. Эти предположения подходят для решения ряда задач, но в некоторых случаях снижают точность.
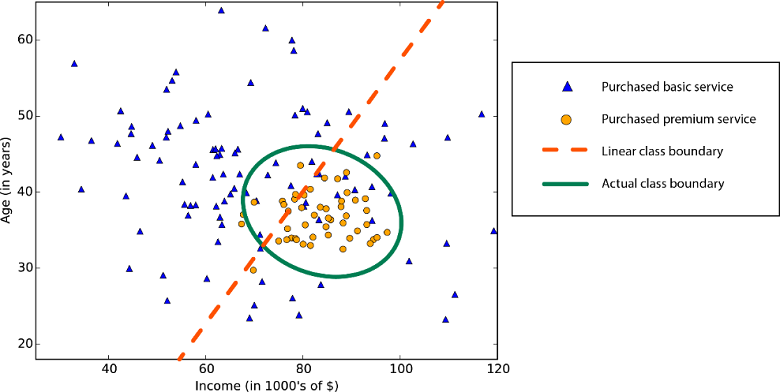
Ограничение нелинейных классов — использование алгоритма линейной классификации снижает точность

Данные с нелинейной закономерностью — при использовании метода линейной регрессии возникают более серьезные ошибки, чем это допустимо
Несмотря на недостатки, к линейным алгоритмам обычно обращаются в первую очередь. Они просты с алгоритмической точкой зрения, а обучение проходит быстро.
Количество параметров
Параметры — это рычаги, с помощью которых специалисты по данным настраивают алгоритм. Это числа, которые влияют на поведение алгоритма, например устойчивость к ошибкам или количество итераций, либо различия в вариантах поведения алгоритма. Иногда время обучения и точность алгоритма могут меняться в зависимости от тех или иных параметров. Как правило, найти хорошую комбинацию параметров для алгоритмов можно путем проб и ошибок.
Также в машинном обучении Azure есть модульный блок подбора параметров, который автоматически пробует все комбинации параметров с указанной вами степенью детализации. Хоть этот способ и позволяет опробовать множество вариантов, однако чем больше параметров, тем больше времени уходит на обучение модели.
К счастью, если параметров много, это означает, что алгоритм отличается высокой гибкостью. И при таком способе можно добиться отличной точности. Но при условии, что вам удастся найти подходящую комбинацию параметров.
Количество признаков
В некоторых типах данных признаков может быть гораздо больше, чем объектов. Это обычно происходит с данными из области генетики или с текстовыми данными. Большое количество признаков препятствует работе некоторых алгоритмов обучения, из-за чего время обучения невероятно растягивается. Для подобных случаев хорошо подходит метод опорных векторов (см. ниже).
Особые случаи
Некоторые алгоритмы обучения делают допущения о структуре данных или желаемых результатах. Если вам удастся найти подходящий вариант для своих целей, он принесет вам отличные результаты, более точные прогнозы или сократит время обучения.
Свойства алгоритма:
• — демонстрирует отличную точность, короткое время обучения и использование линейности.
○ — демонстрирует отличную точность и среднее время обучения.
| Алгоритм | Точность | Время обучения | Линейность | Параметры | Примечание |
|---|---|---|---|---|---|
| Двухклассовая классификация | |||||
| Логистическая регрессия | • | • | 5 | ||
| Лес деревьев решений | • | ○ | 6 | ||
| Джунгли деревьев решений | • | ○ | 6 | Низкие требования к памяти | |
| Улучшенное дерево принятия решений | • | ○ | 6 | Высокие требования к памяти | |
| Нейронная сеть | • | 9 | Возможна дополнительная настройка | ||
| Однослойный перцептрон | ○ | ○ | • | 4 | |
| Метод опорных векторов | ○ | • | 5 | Хорошо подходит для больших наборов признаков | |
| Локальные глубинные методы опорных векторов | ○ | 8 | Хорошо подходит для больших наборов признаков | ||
| Байесовские методы | ○ | • | 3 | ||
| Многоклассовая классификация | |||||
| Логистическая регрессия | • | • | 5 | ||
| Лес деревьев решений | • | ○ | 6 | ||
| Джунгли деревьев решений | • | ○ | 6 | Низкие требования к памяти | |
| Нейронная сеть | • | 9 | Возможна дополнительная настройка | ||
| Один против всех | – | – | – | – | См. свойства выбранного двухклассового метода |
| Многоклассовая классификация | |||||
| Регрессия | |||||
| Линейная | • | • | 4 | ||
| Байесова линейная | ○ | • | 2 | ||
| Лес деревьев решений | • | ○ | 6 | ||
| Улучшенное дерево принятия решений | • | ○ | 5 | Высокие требования к памяти | |
| Быстрые квантильные регрессионные леса | • | ○ | 9 | Прогнозирование распределений, а не точечных значений | |
| Нейронная сеть | • | 9 | Возможна дополнительная настройка | ||
| Пуассона | • | 5 | Технически логарифмический. Для подсчета прогнозов | ||
| Порядковая | 0 | Для прогнозирования рейтинга | |||
| Фильтрация выбросов | |||||
| Методы опорных векторов | ○ | ○ | 2 | Отлично подходит для больших наборов признаков | |
| Фильтрация выбросов на основе метода главных компонент | ○ | • | 3 | Отлично подходит для больших наборов признаков | |
| Метод k-средних | ○ | • | 4 | Алгоритм кластеризации |
Примечания к алгоритму
Линейная регрессия
Как мы уже говорили, линейная регрессия рассматривает данные линейно (или в плоскости, или в гиперплоскости). Это удобная и быстрая «рабочая лошадка», но для некоторых проблем она может быть чересчур простой. Здесь вы найдете руководство по линейной регрессии.

Данные с линейным трендом
Логистическая регрессия
Пусть слово «регрессия» в названии не вводит вас в заблуждение. Логистическая регрессия — это очень мощный инструмент для двухклассовой и многоклассовой классификации. Это быстро и просто. Поскольку вместо прямой линии здесь используется кривая в форме буквы S, этот алгоритм прекрасно подходит для разделения данных на группы. Логистическая регрессия ограничивает линейный класс, поэтому вам придется смириться с линейной аппроксимацией.
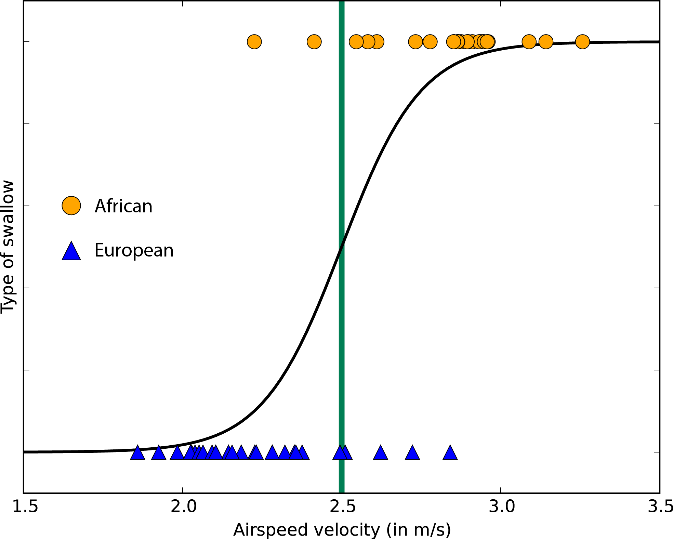
Логистическая регрессия для двухклассовых данных всего с одним признаком — граница класса находится в точке, где логистическая кривая близка к обоим классам
Деревья, леса и джунгли
Леса решающих деревьев (регрессия, двухклассовые и многоклассовые), джунгли решающих деревьев (двухклассовые и многоклассовые) и улучшенные деревья принятия решений (регрессия и двухклассовые) основаны на деревьях принятия решений, базовой концепции машинного обучения. Существует много вариантов деревьев принятия решений, но все они выполняют одну функцию — подразделяют пространство признаков на области с одной и той же меткой. Это могут быть области одной категории или постоянного значения, в зависимости от того, используете ли вы классификацию или регрессию.

Дерево принятия решений подразделяет пространство признаков на области с примерно одинаковыми значениями
Поскольку пространство признаков можно разделить на небольшие области, это можно сделать так, чтобы в одной области был один объект — это грубый пример ложной связи. Чтобы избежать этого, крупные наборы деревьев создаются таким образом, чтобы деревья не были связаны друг с другом. Таким образом, «дерево принятия решений» не должно выдавать ложных связей. Деревья принятия решений могут потреблять большие объемы памяти. Джунгли решающих деревьев потребляют меньше памяти, но при этом обучение займет немного больше времени.
Улучшенные деревья принятия решений ограничивают количество разделений и распределение точек данных в каждой области, чтобы избежать ложных связей. Алгоритм создает последовательность деревьев, каждое из которых исправляет допущенные ранее ошибки. В результате мы получаем высокую степень точности без больших затрат памяти. Полное техническое описание смотрите в научной работе Фридмана.
Быстрые квантильные регрессионные леса — это вариант деревьев принятия решений для тех случаев, когда вы хотите знать не только типичное (среднее) значение данных в области, но и их распределение в форме квантилей.
Нейронные сети и восприятие
Нейронные сети — это алгоритмы обучения, которые созданы на основе модели человеческого мозга и направлены на решение многоклассовой, двухклассовой и регрессионной задач. Их существует огромное множество, но в машинном обучении Azure нейронные сети принимают форму направленного ациклического графика. Это означает, что входные признаки передаются вперед через последовательность уровней и превращаются в выходные данные. На каждом уровне входные данные измеряются в различных комбинациях, суммируются и передаются на следующий уровень. Эта комбинация простых расчетов позволяет изучать сложные границы классов и тенденции данных будто по волшебству. Подобные многоуровневые сети выполняют «глубокое обучение», которое служит источником вдохновения для технических отчетов и научной фантастики.
Но такая производительность обходится не бесплатно. Обучение нейронных сетей занимает много времени, особенно для крупных наборов данных с множеством признаков. В них больше параметров, чем в большинстве алгоритмов, и поэтому подбор параметров значительно увеличивает время обучения. А для перфекционистов, которые хотят указать собственную структуру сети, возможности практически не ограничены.
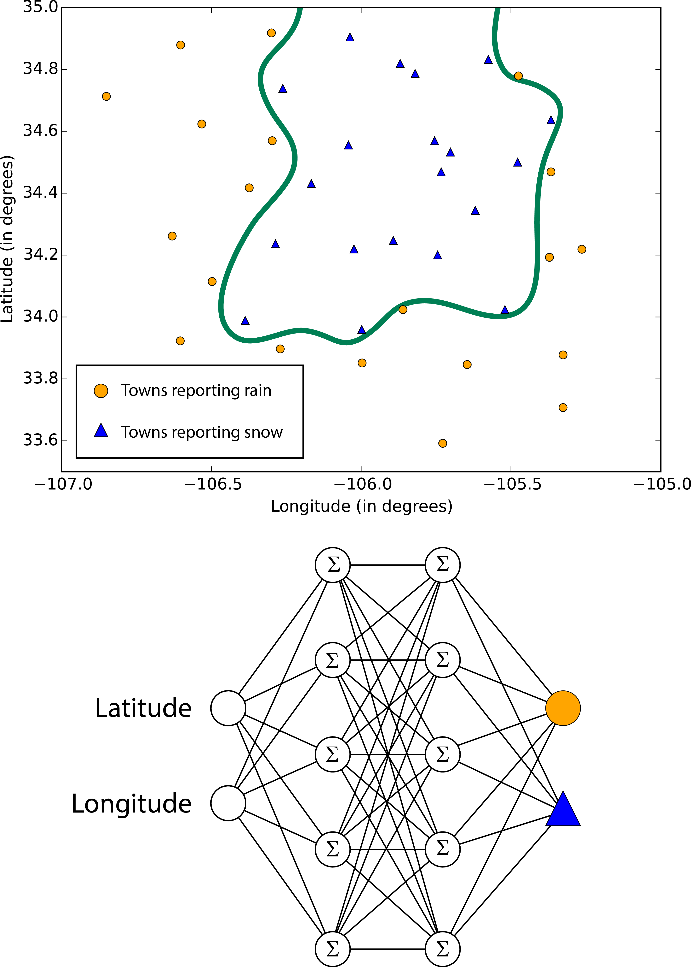
Границы, изучаемые нейронными сетями, бывают сложными и хаотичными
Однослойный перцептрон — это ответ нейронных сетей на увеличение времени обучения. В нем используется сетевая структура, которая создает линейные классовые границы. По современным стандартам звучит примитивно, но этот алгоритм давно проверен на деле и быстро обучается.
Методы опорных векторов
Методы опорных векторов находят границу, которая разделяет классы настолько широко, насколько это возможно. Когда невозможно четко разделить два класса, алгоритмы находят наилучшую границу. Согласно машинному обучению Azure, двухклассовый метод опорных векторов делает это с помощью прямой линии (говоря на языке методов опорных векторов, использует линейное ядро). Благодаря линейной аппроксимации обучение выполняется достаточно быстро. Особенно интересна функция работы с объектами с множеством признаков, например, текстом или геномом. В таких случаях опорные векторные машины могут быстрее разделить классы и отличаются минимальной вероятностью создания ложной связи, а также не требуют больших объемов памяти.

Стандартная граница класса опорной векторной машины увеличивает поле между двумя классами
Еще один продукт от Microsoft Research — двухклассовые локальные глубинные методы опорных векторов. Это нелинейный вариант методов опорных векторов, который отличается скоростью и эффективностью памяти, присущей линейной версии. Он идеально подходит для случаев, когда линейный подход не дает достаточно точных ответов. Чтобы обеспечить высокую скорость, разработчики разбивают проблему на несколько небольших задач линейного метода опорных векторов. Подробнее об этом читайте в полном описании.
С помощью расширения нелинейных методов опорных векторов одноклассовая машина опорных векторов создает границу для всего набора данных. Это особенно полезно для фильтрации выбросов. Все новые объекты, которые не входят в пределы границы, считаются необычными и поэтому внимательно изучаются.
Байесовские методы
Байесовские методы отличаются очень нужным качеством: они избегают ложных связей. Для этого они заранее делают предположения о возможном распределении ответа. Также для них не нужно настраивать много параметров. Машинное обучение Azure предлагает Байесовские методы как для классификации (двухклассовая классификация Байеса), так и для регрессии (Байесова линейная регрессия). При этом предполагается, что данные можно разделить или расположить вдоль прямой линии.
Кстати, точечные машины Байеса были разработаны в Microsoft Research. В их фундаменте лежит великолепная теоретическая работа. Если вас заинтересует эта тема, читайте статью в MLR и блог Криса Бишопа (Chris Bishop).
Особые алгоритмы
Если вы преследуете конкретную цель, вам повезло. В коллекции машинного обучения Azure есть алгоритмы, которые специализируются в прогнозировании рейтингов (порядковая регрессия), прогнозирование количества (регрессия Пуассона) и выявлении аномалий (один из них основан на анализе главных компонентов, а другой — на методах опорных векторов). А еще есть алгоритм кластеризации (метод k-средних).

Выявление аномалий на основе PCA — огромное множество данных попадает под стереотипное распределение; под подозрение попадают точки, которые сильно отклоняются от этого распределения
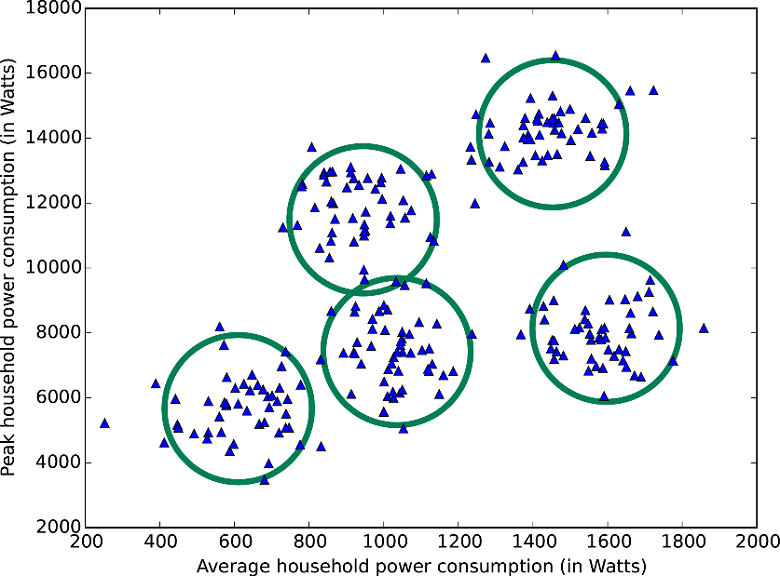
Набор данных разделяется на пять кластеров по методу k-средних
Также есть многоклассовый классификатор «один против всех», который разбивает проблему классификации N-класса на двухклассовые проблемы класса N-1. Точность, время обучения и свойства линейности зависят от используемых двухклассовых классификаторов.

Два двухклассовых классификатора формируют трехклассовый классификатор
Кроме того, Azure предлагает доступ к мощной платформе машинного обучения под названием Vowpal Wabbit. VW отказывается от категоризации, поскольку может изучить проблемы классификации и регрессии и даже обучаться от частично помеченных данных. Вы можете выбрать любой из алгоритмов обучения, функций потерь и алгоритмов оптимизации. Эта платформа отличается эффективностью, возможностью параллельного выполнения и непревзойденной скоростью. Она без труда справляется с большими наборами данных. VW была запущена Джоном Лэнгфордом (John Langford), специалистом из Microsoft Research, и является болидом «Формулы-1» в океане серийных автомобилей. Не каждая проблема подходит для VW, но если вы считаете, что это верный для вас вариант, то затраченные усилия обязательно окупятся. Также платформа доступна в виде автономного открытого исходного кода на нескольких языках.
Если вы увидели неточность перевода, сообщите пожалуйста об этом в личные сообщения.
