[Перевод] Как сравнивать распределения. От визуализации до статистических тестов
В подробном лонгриде к старту курса по анализу данных вы найдёте авторские визуализации, пояснения и комментарии об искусстве сравнивать распределения и делать выводы.
Сравнение эмпирического распределения переменной по разным группам — распространённая задача Data Science. Эта задача часто возникает при поиске причинно-следственных связей, когда нужно оценить качество рандомизации.
Золотой стандарт в выявлении причинно-следственных связей при оценке любой стратегии (функции UX, рекламной кампании, препарата и т. д.) — это рандомизированные контрольные испытания, известные как A/B-тесты. На практике выборка отбирается для исследования и случайным образом делится на группы — контрольную и экспериментальную, затем результаты этих групп сравниваются. Рандомизация гарантирует, что единственное различие двух группами — это выбранная независимая переменная, такая, что различия результатов можно объяснить именно её эффектом.
Несмотря на рандомизацию, эти группы никогда не бывают идентичными, а иногда их нельзя назвать даже «похожими». У нас может быть больше мужчин или пожилых людей в одной группе и т. д. (эти признаки обычно называются ковариатами — контрольными переменными). Когда такое случается, нельзя быть уверенным, что разница в результатах связана только с варьируемым нами эффектом и её нельзя приписать несбалансированным ковариатам. Поэтому после рандомизации всегда важно проверить сбалансированность всех наблюдаемых переменных между группами, а также проверить, нет ли систематических различий. Другой вариант, который позволяет заранее быть уверенным, что определённые ковариаты сбалансированы, — стратифицированная выборка.
Рассмотрим способы сравнения двух и более распределений, а также оценки величины и значимости их различий — визуальный и статистический. Эти подходы обычно сочетают интуицию и математическую точность: по диаграммам можно быстро оценить и изучить различия, но трудно сказать, систематические они или вызваны шумом.
Пример
Предположим, нужно провести эксперимент на группе людей, и мы случайным образом распределили их в экспериментальную (получает лечение) и контрольную группы (не получает его). Хотелось бы добиться наибольшей сопоставимости групп, чтобы объяснить любые различия между ними только эффектом от лекарства, который варьируется нами. Мы также разделили экспериментальную группу на разные группы для тестирования небольших вариаций одного и того же препарата.
Я смоделировал набор данных на 1000 человек, для которых мы наблюдаем набор характеристик, импортировал процесс генерации данных dgp_rnd_assignment () из src.dgp и некоторые графические функции и библиотеки из src.utils.
from src.utils import *
from src.dgp import dgp_rnd_assignment
df = dgp_rnd_assignment().generate_data()
df.head()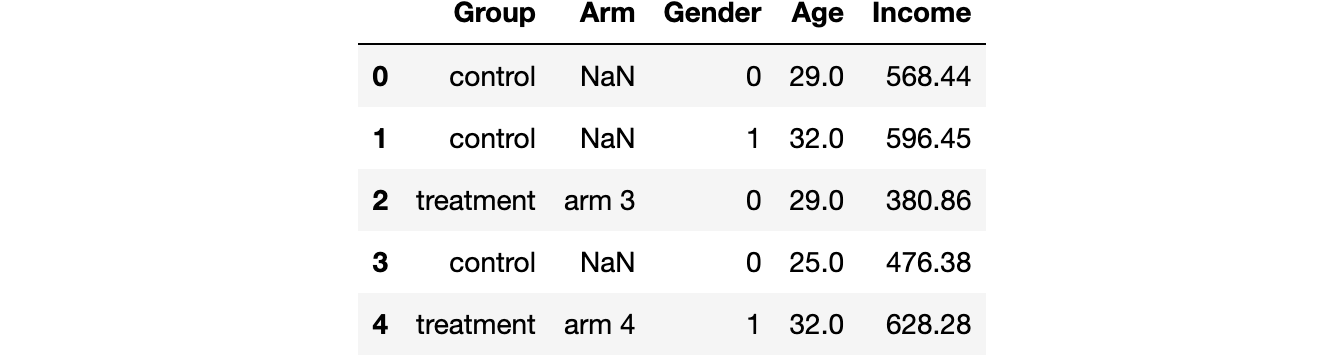 Скриншот данных
Скриншот данных
У нас есть информация о 1000 человек, для которых мы наблюдаем переменные gender (пол), age (возраст) и income (доход за неделю). Каждый человек назначается либо в группу лечения, либо в контрольную группу (переменная group), и люди, получающие лечение, распределяются по четырём типам лечения (переменная arm).
Две группы — диаграммы
Начнём с самого простого: сравним распределение доходов в экспериментальной и контрольной группах. Сначала мы изучаем визуальные подходы, а затем статистические подходы. Преимущество первого — интуитивность, второго — математическая точность.
Для большинства визуализаций я буду использовать библиотеку Python seaborn.
Диаграмма размаха («ящик с усами»)
Первый визуальный подход — это диаграмма размаха. Такая диаграмма — это хороший компромисс между сводной статистикой и визуализацией данных. Центр «ящика» — медиана, а границы — первый (Q1) и третий квартиль (Q3) соответственно. «Усы» распространяются на первые точки данных, более чем в 1,5 раза превышающие межквартильный диапазон (Q3–Q1) вне «ящика». Точки за пределами «усов» наносятся на диаграмму отдельно и обычно считаются выбросами.
Эта диаграмма предоставляет сводную статистику (ящик и «усы»), а также прямую визуализацию данных — выбросы:
sns.boxplot(data=df, x='Group', y='Income');
plt.title("Boxplot");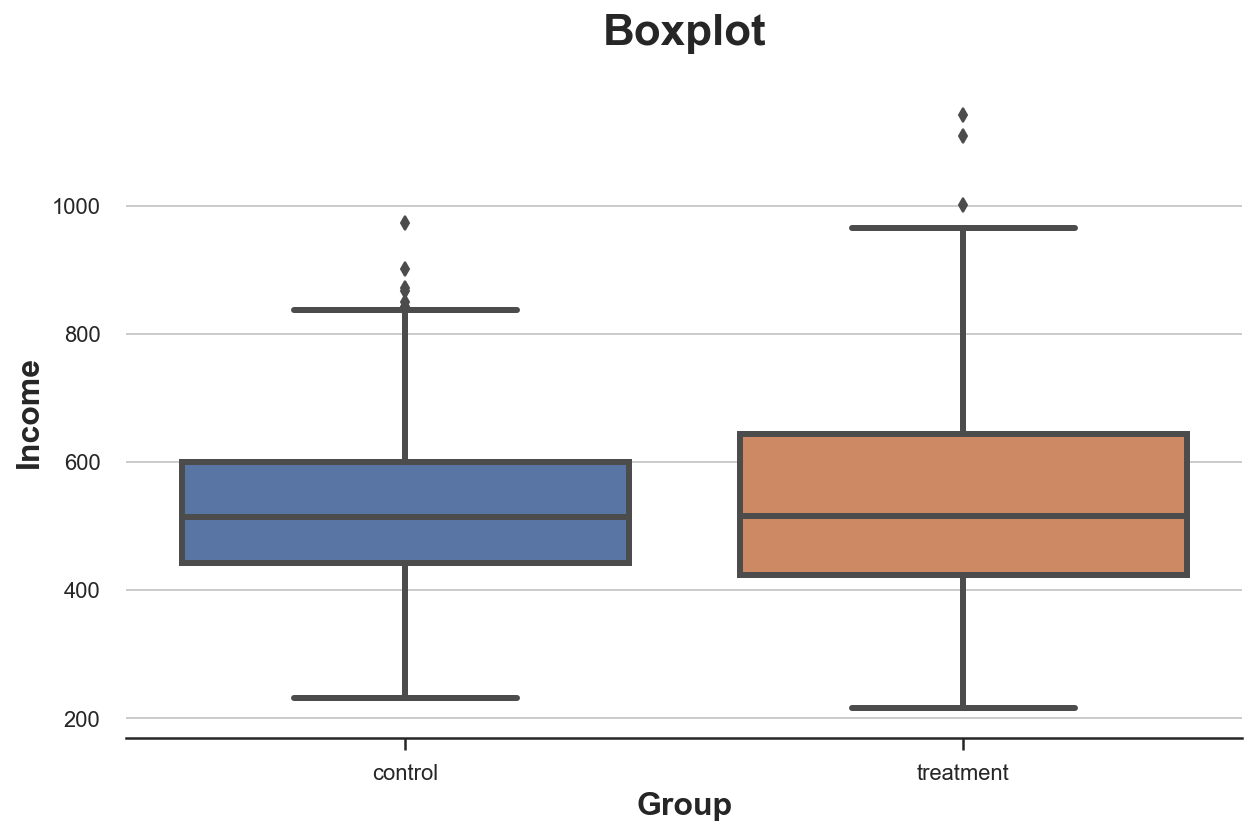 Распределение доходов по экспериментальной и контрольной группам
Распределение доходов по экспериментальной и контрольной группам
Кажется, распределение доходов в экспериментальной группе немного более рассеяно: оранжевый прямоугольник больше, а его «усы» охватывают более широкий диапазон. Но проблема ящика с усами в том, что он скрывает форму данных и сообщает некоторую сводную статистику, но не показывает фактическое распределение данных.
Гистограмма
Наиболее интуитивно понятным способом построения диаграммы распределения является гистограмма. Гистограмма группирует данные в интервалы («бины») одинаковой ширины и отображает количество наблюдений в каждом интервале.
sns.histplot(data=df, x='Income', hue='Group', bins=50);
plt.title("Histogram");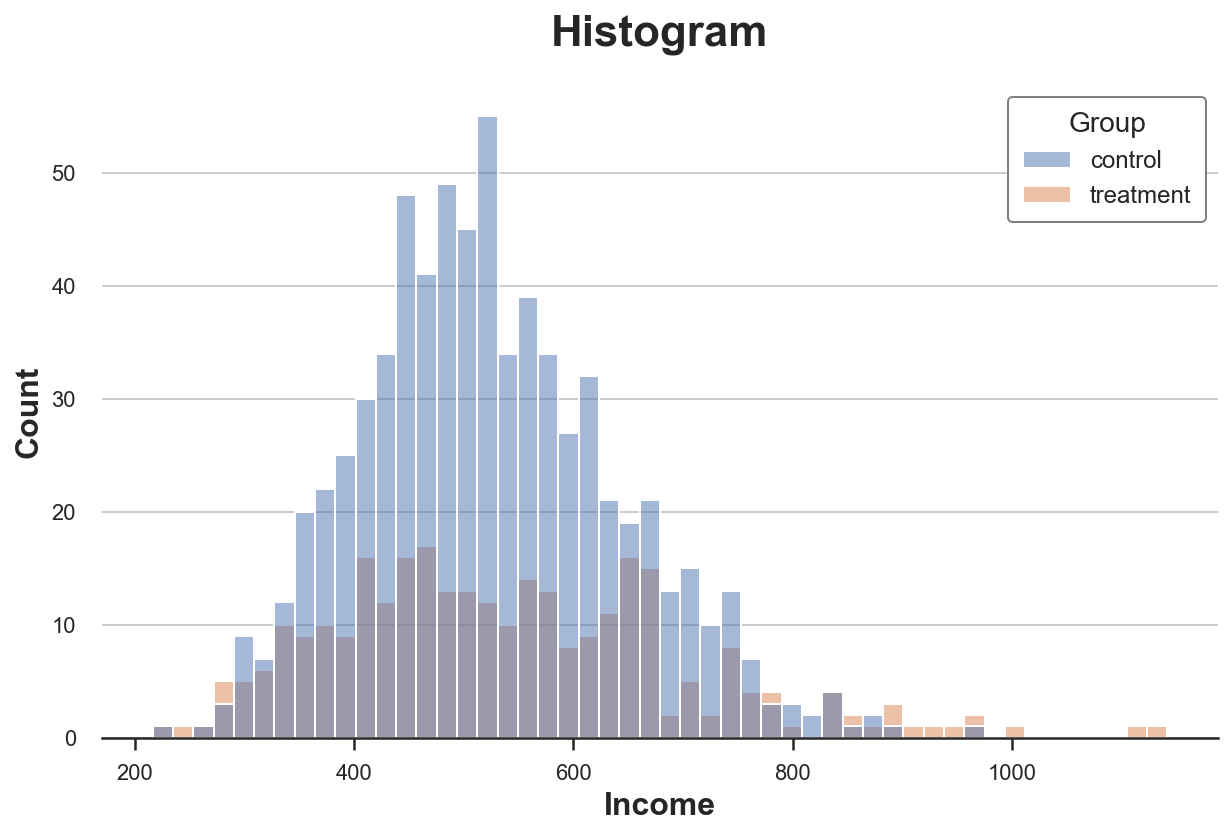 Распределение доходов по экспериментальной и контрольной группам
Распределение доходов по экспериментальной и контрольной группам
С этими диаграммами есть несколько проблем:
Количество наблюдений в группах разное, поэтому гистограммы несопоставимы.
Количество бинов произвольное.
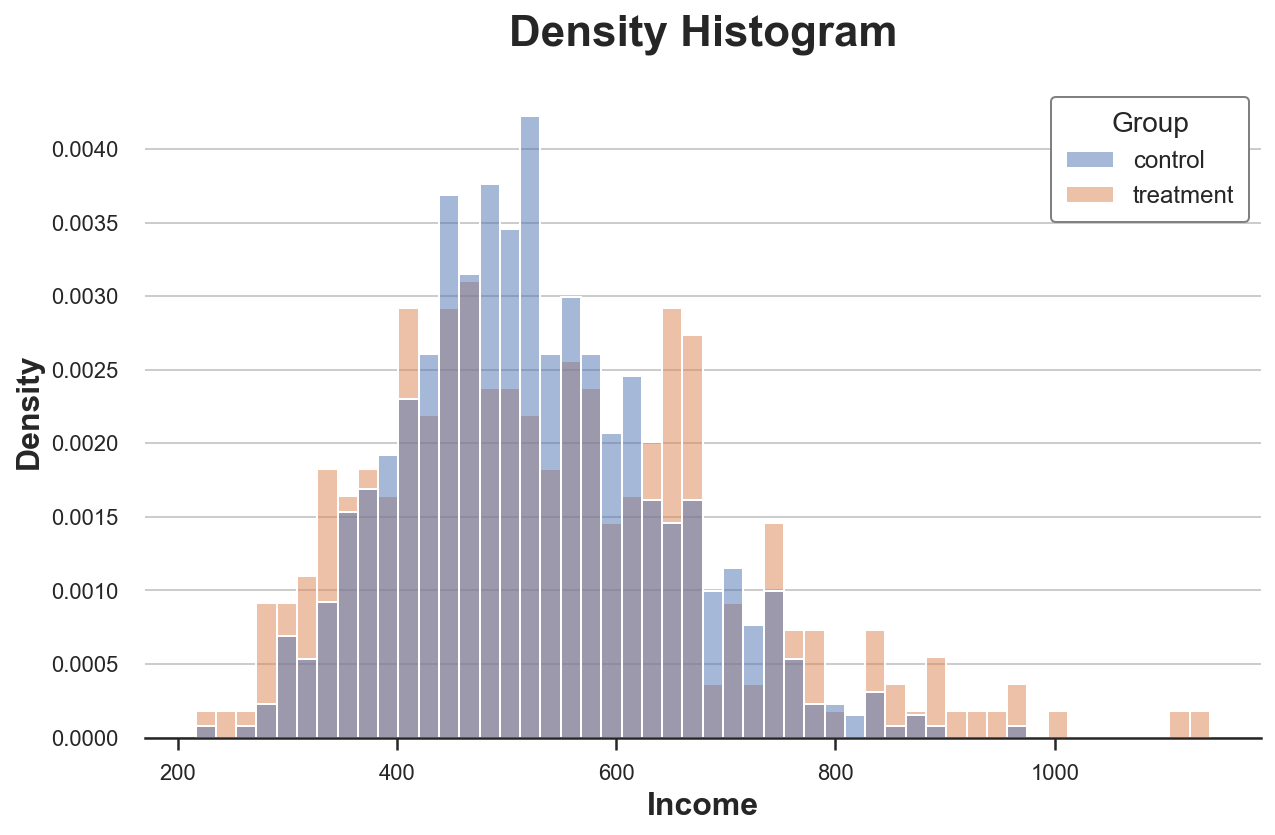
Решить первую проблему можно через параметр stat для построения диаграммы плотности вместо количества и установив для параметра common_norm значение False, чтобы нормализовать каждую гистограмму отдельно.
sns.histplot(data=df, x='Income', hue='Group', bins=50, stat='density', common_norm=False);
plt.title("Density Histogram");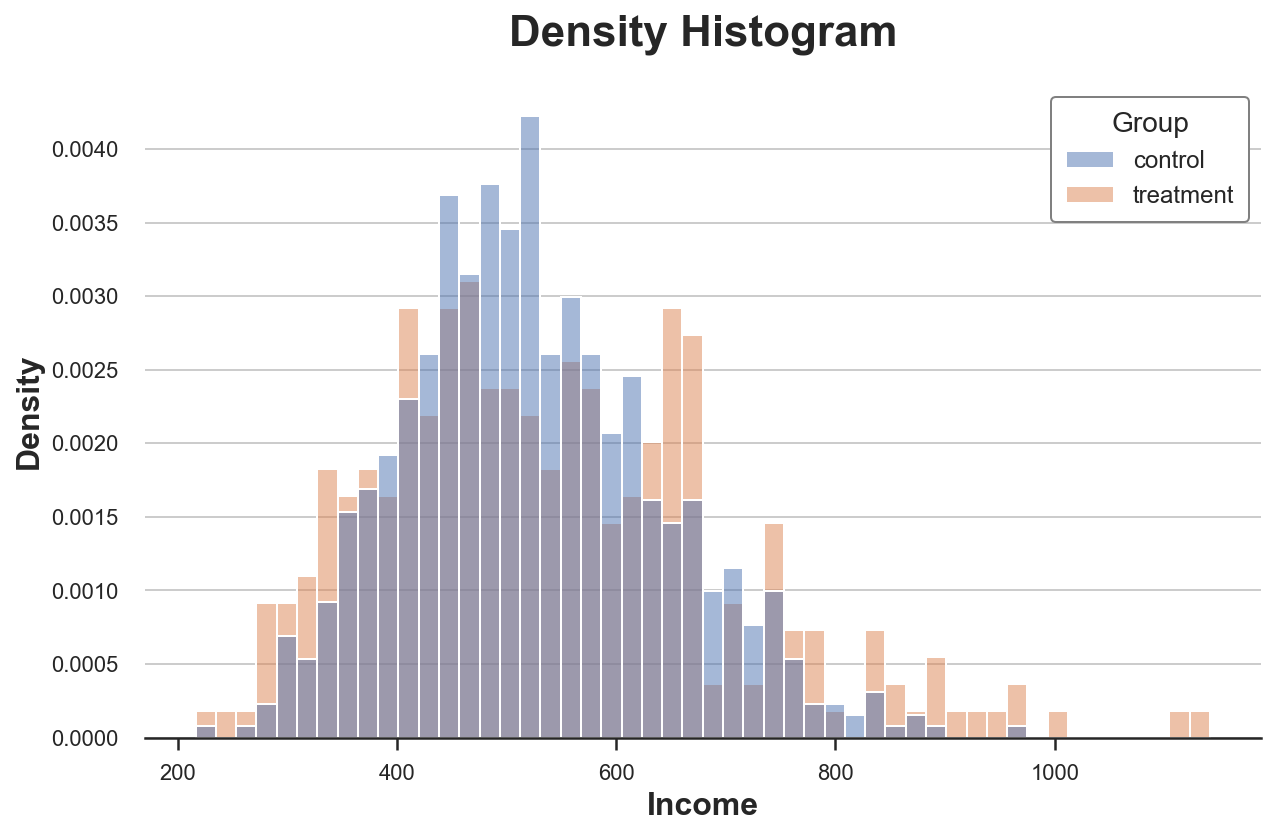 Распределение доходов по экспериментальной и контрольной группам
Распределение доходов по экспериментальной и контрольной группам
Теперь гистограммы сопоставимы!
Однако размер бинов по-прежнему произвольный. В крайнем случае, если сгруппировать меньше данных, мы получим бины не более чем с одним наблюдением, а если сгруппируем больше данных, то получим один бин. Так или иначе, если утрировать, диаграмма теряет информативность. Это — классический компромисс смещения и дисперсии.
Ядерная оценка плотности
Одно из возможных решений — использовать метод ядерной оценки плотности, который пытается аппроксимировать гистограмму непрерывной функцией при помощи ядерной оценки плотности (KDE).
sns.kdeplot(x='Income', data=df, hue='Group', common_norm=False);
plt.title("Kernel Density Function"); Распределение доходов по экспериментальной и контрольной группам
Распределение доходов по экспериментальной и контрольной группам
Выше видно, что ядерная оценка плотности дохода имеет «более толстые хвосты» (т. е. более высокую дисперсию) в экспериментальной группе, тогда как среднее значение по группам кажется одинаковым.
Проблема с ядерной оценкой плотности в том, что метод является чем-то вроде чёрного ящика, он может скрыть важные особенности данных.
Кумулятивное распределение
Более прозрачное представление двух распределений — кумулятивная функция их распределения. В каждой точке оси x (доход) наносится процент точек данных, имеющих равное или меньшее значение. Основные преимущества кумулятивной функции распределения заключаются в том, что:
не нужно выбирать произвольно (например, количество бинов);
не нужна никакая аппроксимация (как с ядерной оценкой плотности), но мы представляем все точки данных.
sns.histplot(x='Income', data=df, hue='Group', bins=len(df), stat="density",
element="step", fill=False, cumulative=True, common_norm=False);
plt.title("Cumulative distribution function");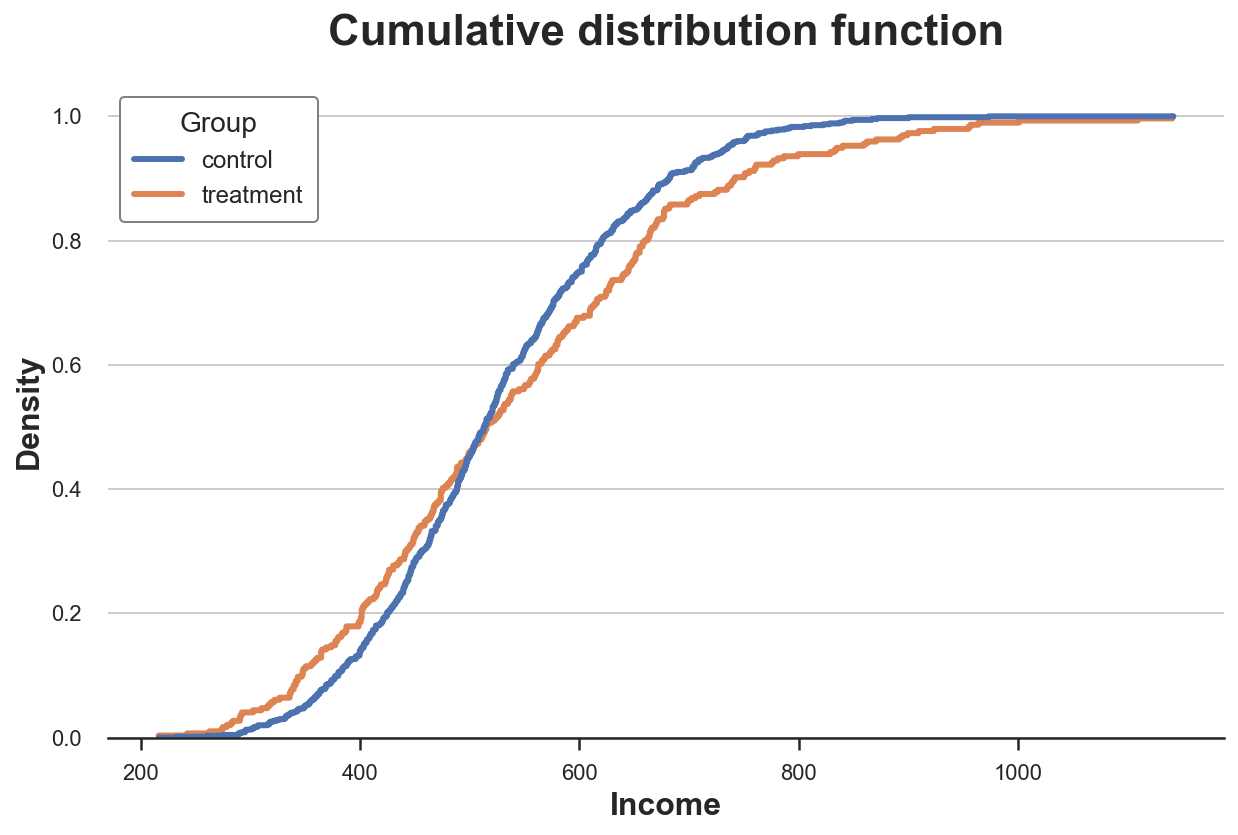 Кумулятивное распределение доходов между экспериментальной и контрольной группами
Кумулятивное распределение доходов между экспериментальной и контрольной группами
Как же интерпретировать график?
Две линии пересекаются примерно в точке 0,5 (ось Y), а значит, их медианы cхожи.
Оранжевая линия выше синей линии слева и ниже этой линии справа: распределение экспериментальной группы имеет более толстые хвосты.
График квантиль-квантиль
Родственный метод — график квантиль-квантиль. Этот график отображает квантили двух распределений друг против друга. Если распределения совпадают, мы должны получить линию под углом в 45 градусов.
В Python нет встроенной функции графика квантиль–квантиль, и, хотя пакет statsmodels предоставляет функцию qqplot, он довольно громоздкий. Сделаем этот график вручную.
Во-первых, вычислим квартили двух групп функцией percentile.
income = df['Income'].values
income_t = df.loc[df.Group=='treatment', 'Income'].values
income_c = df.loc[df.Group=='control', 'Income'].values
df_pct = pd.DataFrame()
df_pct['q_treatment'] = np.percentile(income_t, range(100))
df_pct['q_control'] = np.percentile(income_c, range(100))Теперь можно построить два распределения квантилей относительно друг друга, а как эталон взять линию под углом в 45 градусов:
plt.figure(figsize=(8, 8))
plt.scatter(x='q_control', y='q_treatment', data=df_pct, label='Actual fit');
sns.lineplot(x='q_control', y='q_control', data=df_pct, color='r', label='Line of perfect fit');
plt.xlabel('Quantile of income, control group')
plt.ylabel('Quantile of income, treatment group')
plt.legend()
plt.title("QQ plot");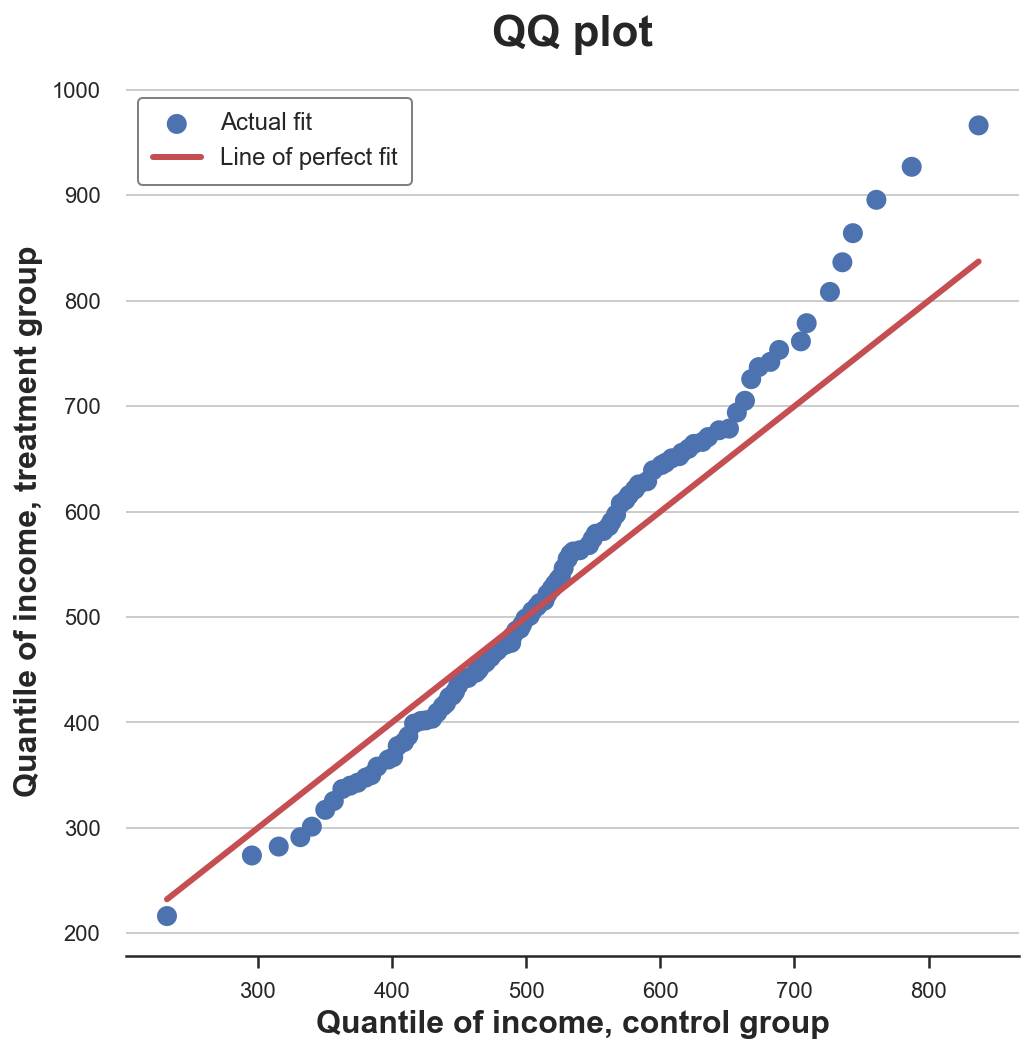 График квантиль-квантиль
График квантиль-квантиль
График даёт представление, очень похожее на график кумулятивного распределения: доход в экспериментальной группе имеет ту же медиану (линии пересекаются в центре), но хвосты шире: точки ниже линии на левом конце и выше на правом.
Две группы — тесты
Итак, мы рассмотрели разные способы визуализации различий между распределениями. Главное преимущество визуализации — интуитивность.
Однако мы могли бы захотеть быть более точными и попытаться оценить статистическую значимость различия между распределениями, т. е. ответить на вопрос, «является ли наблюдаемое различие систематическим, или оно связано с шумом выборки?»
Проанализируем различные тесты, позволяющие сравнить два распределения.
T-тест
Первый и самый распространённый тест — t-критерий Стьюдента. T-тесты обычно используются для сравнения средних значений. Здесь хочется проверить, одинаковы ли средние значения распределения доходов в двух группах. Статистика теста для теста сравнения двух средних определяется таким образом:
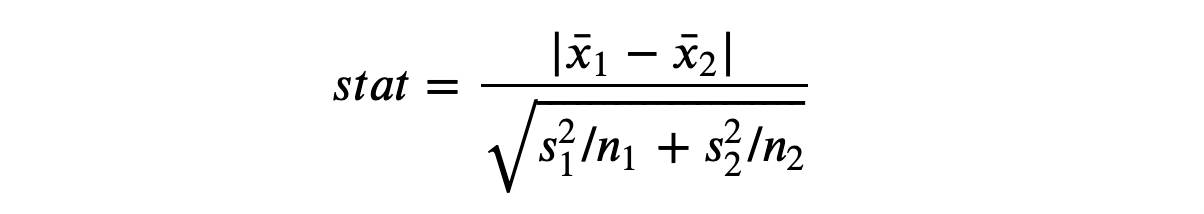 Т-статистика
Т-статистика
x̅ — среднее значение выборки, s — стандартное отклонение выборки. В мягких условиях тестовая статистика асимптотически распределяется как t-распределение Стьюдента. Для выполнения t-теста воспользуемся функцией ttest_ind из scipy. Она возвращает тестовую статистику и предполагаемое p-значение.
from scipy.stats import ttest_ind
stat, p_value = ttest_ind(income_c, income_t)
print(f"t-test: statistic={stat:.4f}, p-value={p_value:.4f}")
t-test: statistic=-1.5549, p-value=0.1203Наше p-значение составляет 0,12, поэтому не отвергаем нулевую гипотезу об отсутствии различий в средних значениях в обеих группах.
Стандартизированная разность средних (SMD)
Как правило, при A/B-тестировании рекомендуется всегда проводить тест на различия средних значений всех переменных в экспериментальной и контрольной группах.
Однако знаменатель статистики t-критерия зависит от размера выборки, поэтому t-критерий критиковали из-за затруднения сравнения p-значений в разных исследованиях. На самом деле, мы можем получить значимый результат в эксперименте с очень малой величиной различия, но с большим размером выборки, в то время как получить незначимый результат можно в эксперименте с большой величиной различия, но с небольшим размером выборки.
Одно из предложенных решений — стандартизация разности средних (SMD). Как следует из названия метода, это не строго тестовая статистика, а просто стандартизированная разница, вычислить которую можно так:
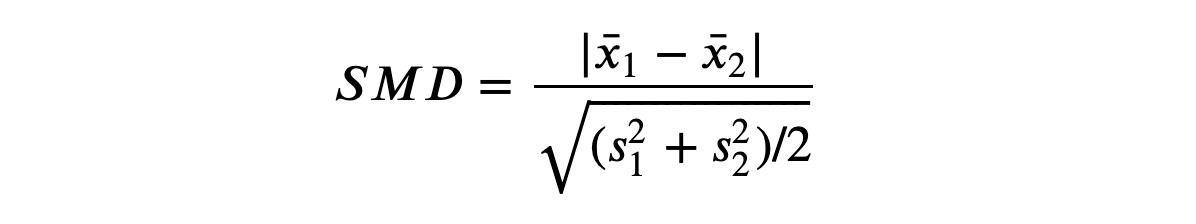 Стандартизированная разность средних
Стандартизированная разность средних
Обычно значение ниже 0,1 считается «небольшой» разницей.
Хорошая практика — собрать средние значения всех переменных в экспериментальной и контрольной группах, а также измерить расстояния между ними — либо t-критерий, либо SMD — и занести в так называемую балансовую таблицу, для создания которой можно воспользоваться функцией create_table_one из библиотеки causalml. Как следует из названия функции, балансовая таблица всегда должна быть первой таблицей, которую вы представляете при выполнении A/B-тестирования.
from causalml.match import create_table_one
df['treatment'] = df['Group']=='treatment'
create_table_one(df, 'treatment', ['Gender', 'Age', 'Income'])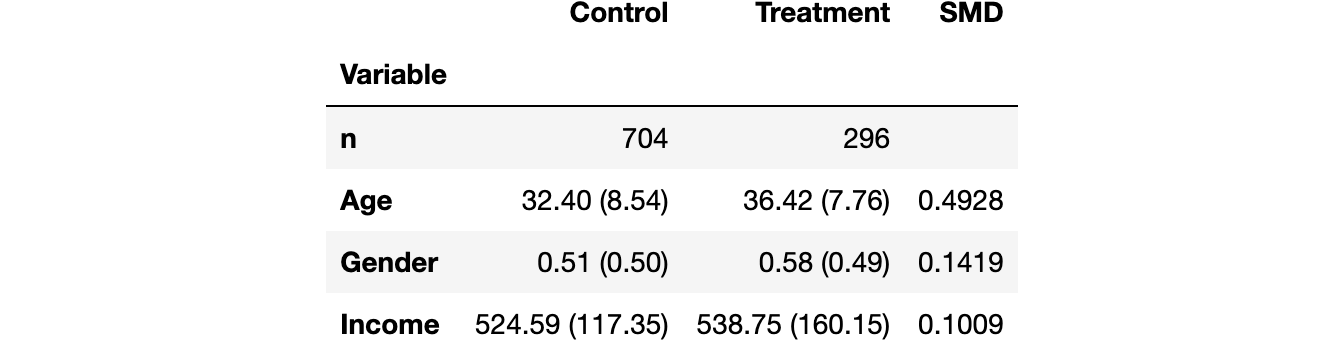 Балансовая таблица
Балансовая таблица
В первых двух столбцах мы видим среднее значение различных переменных в экспериментальной и контрольной группах со стандартными ошибками в скобках. В последнем столбце значение SMD указывает на стандартизированную разницу более 0,1 для всех переменных, что позволяет предположить, что две группы, вероятно, различаются.
U-критерий Манна — Уитни
Альтернативный тест — U-критерий Манна — Уитни, который сравнивает медиану двух распределений. В частности, нулевая гипотеза для этого теста состоит в том, что две группы имеют одинаковое распределение, тогда как альтернативная гипотеза — в том, что одна группа имеет большие (или меньшие) значения, чем другая.
В отличие от тестов, которые мы видели до сих пор, U-критерий Манна — Уитни не зависит от выбросов и концентрируется на центре распределения.
И вот процедура расчёта критерия:
Объедините все точки данных и ранжируйте их в порядке возрастания или убывания.
Вычислите U₁ = R₁ − n₁(n₁ + 1)/2, где R₁ — сумма рангов точек данных в первой группе, а n₁ — количество точек в первой группе.
Аналогично вычислите U₂ для второй группы.
Тестовая статистика рассчитывается как stat = min (U₁, U₂).
При нулевой гипотезе об отсутствии систематических ранговых различий между двумя распределениями (т. е. об одинаковой медиане) тестовая статистика имеет асимптотическое нормальное распределение с известным средним значением и дисперсией.
Логика за вычислением R и U такова: если все значения в первой выборке больше, чем значения во второй выборке, то R₁ = n₁(n₁ + 1)/2 и, как следствие, U₁ будет тогда равным нулю (минимально достижимое значение). В противном случае, если бы две выборки были похожи, U₁ и U₂ были бы очень близки к n₁ n₂/2 (максимально достижимое значение).
Мы проводим тест при помощи mannwhitneyu из scipy:
from scipy.stats import mannwhitneyu
stat, p_value = mannwhitneyu(income_t, income_c)
print(f" Mann–Whitney U Test: statistic={stat:.4f}, p-value={p_value:.4f}")
Mann–Whitney U Test: statistic=106371.5000, p-value=0.6012Мы получаем p-значение 0,6, что означает, что мы не отвергаем нулевую гипотезу об отсутствии различий в медианах между экспериментальной и контрольной группами.
Пермутационные тесты
Непараметрическая альтернатива критерию Манна — Уитни — пермутационное (перестановочное) тестирование. Идея состоит в том, что при нулевой гипотезе два распределения должны быть одинаковыми, поэтому перетасовка меток групп не должна существенно изменить какую-либо статистику.
Мы можем выбрать любую статистику и проверить, как её значение в исходной выборке соотносится с её распределением по перестановкам групповых меток. Например, давайте использовать в качестве тестовой статистики разницу в выборочных средних между экспериментальной и контрольной группами.
sample_stat = np.mean(income_t) - np.mean(income_c)
stats = np.zeros(1000)
for k in range(1000):
labels = np.random.permutation((df['Group'] == 'treatment').values)
stats[k] = np.mean(income[labels]) - np.mean(income[labels==False])
p_value = np.mean(stats > sample_stat)
print(f"Permutation test: p-value={p_value:.4f}")
Permutation test: p-value=0.0530Пермутационный тест даёт нам p-значение 0,053, а это подразумевает слабое отклонение нулевой гипотезы на уровне 5%.
Как интерпретировать p-значение? Оно означает, что разница в средних значениях данных превышает 1 — 0,0560 = 94,4% различий в средних значениях по переставленным выборкам.
Тест можно визуализировать: построить диаграмму распределения статистики теста по перестановкам в зависимости от его выборочного значения.
plt.hist(stats, label='Permutation Statistics', bins=30);
plt.axvline(x=sample_stat, c='r', ls='--', label='Sample Statistic');
plt.legend();
plt.xlabel('Income difference between treatment and control group')
plt.title('Permutation Test');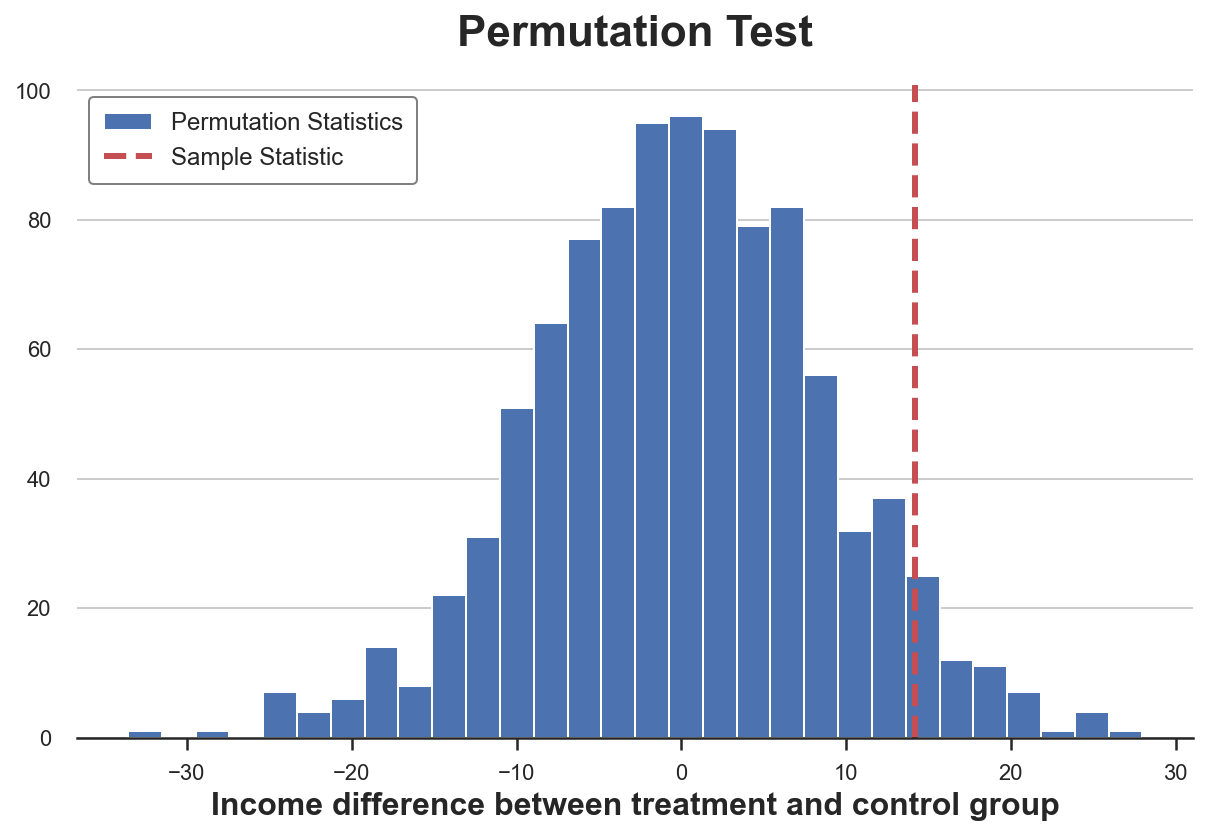 Распределение средней разницы по перестановкам
Распределение средней разницы по перестановкам
Как видим, выборочная статистика достаточно экстремальна по отношению к значениям в переставленных выборках, но не слишком.
Тест хи-квадрат
Тест хи-квадрат — это очень мощный тест, который в основном используется для проверки различий в частотах.
Одно из наименее известных применений критерия хи-квадрат — проверка сходства между двумя распределениями. Идея здесь — объединить наблюдения двух групп. Если бы два распределения были одинаковыми, можно было бы ожидать одинаковую частоту наблюдений в каждом бине. Важно отметить: чтобы тест был действительным, в каждом бине необходимо достаточное количество наблюдений.
Я генерирую ячейки, соответствующие децилям распределения дохода в контрольной группе, а затем вычисляю ожидаемое количество наблюдений в каждой ячейке в экспериментальной группе, если два распределения были одинаковыми.
# Init dataframe
df_bins = pd.DataFrame()
# Generate bins from control group
_, bins = pd.qcut(income_c, q=10, retbins=True)
df_bins['bin'] = pd.cut(income_c, bins=bins).value_counts().index
# Apply bins to both groups
df_bins['income_c_observed'] = pd.cut(income_c, bins=bins).value_counts().values
df_bins['income_t_observed'] = pd.cut(income_t, bins=bins).value_counts().values
# Compute expected frequency in the treatment group
df_bins['income_t_expected'] = df_bins['income_c_observed'] / np.sum(df_bins['income_c_observed']) * np.sum(df_bins['income_t_observed'])
df_bins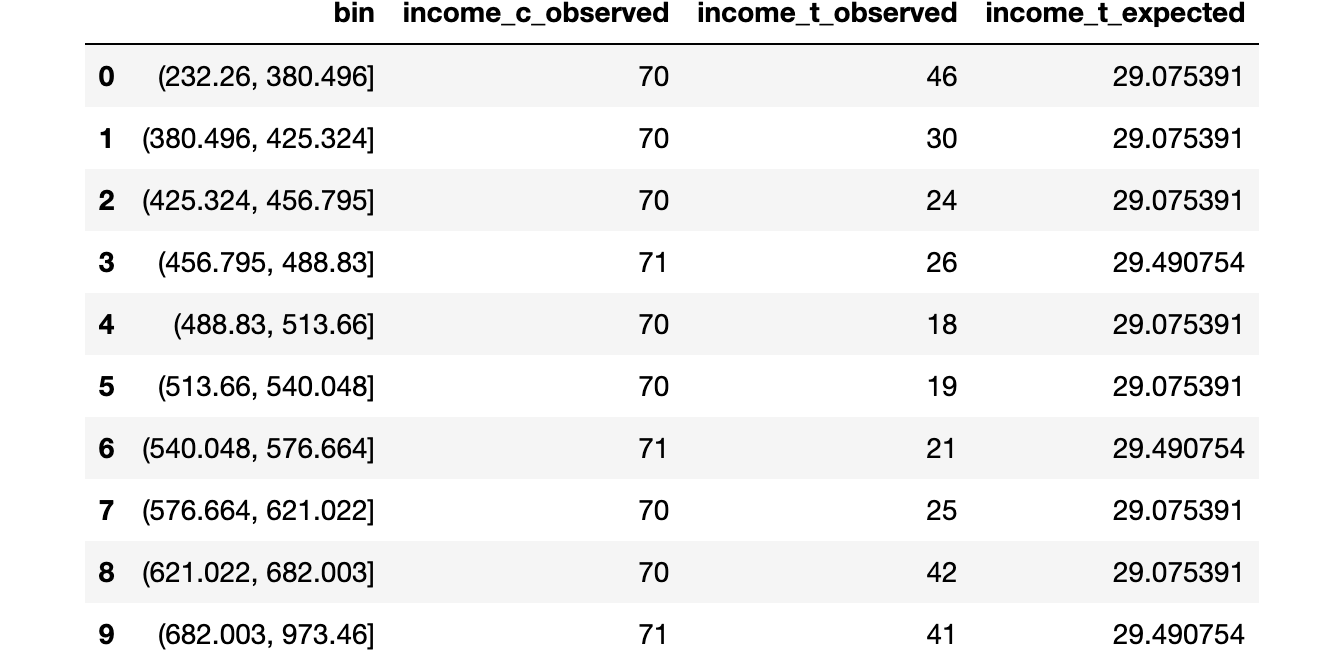 Бины и частоты
Бины и частоты
Теперь мы можем выполнить тест, сравнив ожидаемое (E) и наблюдаемое (O) количество наблюдений в экспериментальной группе по бинам. Тестовая статистика задаётся следующим образом:
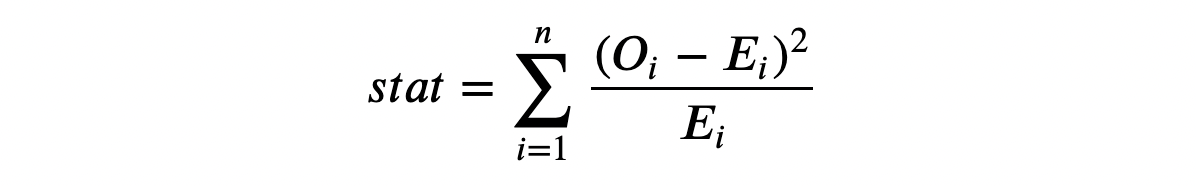 Статистика критерия хи-квадрат
Статистика критерия хи-квадрат
Бины индексируются как i, а O — наблюдаемое количество точек данных в бине i; E — ожидаемое количество точек данных бина i. Мы сгенерировали бины, используя децили распределения дохода в контрольной группе, поэтому ожидаем, что количество наблюдений на бин в экспериментальной группе будет одинаковым для всех бинов. Статистика теста асимптотически распределяется как распределение хи-квадрат.
Чтобы вычислить статистику теста и p-значение теста, воспользуемся функцией chisquare из scipy:
from scipy.stats import chisquare
stat, p_value = chisquare(df_bins['income_t_observed'], df_bins['income_t_expected'])
print(f"Chi-squared Test: statistic={stat:.4f}, p-value={p_value:.4f}")
Chi-squared Test: statistic=32.1432, p-value=0.0002В отличие от других тестов тест хи-квадрат решительно отвергает нулевую гипотезу об одинаковости двух распределений. Почему? Два распределения имеют похожий центр, но разные хвосты, и критерий хи-квадрат проверяет сходство по всему распределению, не только в центре, как в предыдущих тестах.
И этот результат предостерегает: прежде чем делать слепые выводы из p-значения, очень важно понять, что вы тестируете на самом деле!
Критерий Колмогорова — Смирнова
Идея критерия Колмогорова — Смирнова — сравнить кумулятивные распределения двух групп. В частности, статистика теста Колмогорова — Смирнова представляет собой максимальную абсолютную разницу между двумя кумулятивными распределениями.
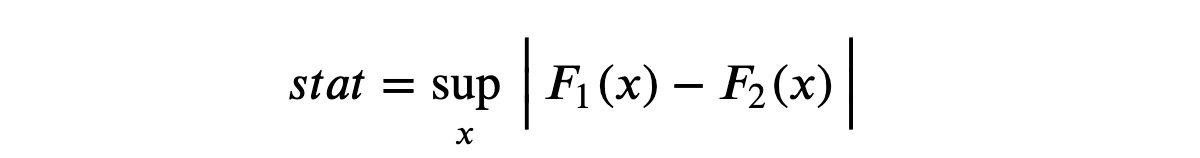 Статистика критерия Колмогорова — Смирнова
Статистика критерия Колмогорова — Смирнова
Где F₁ и F₂ — две кумулятивные функции распределения, а x — значения базовой переменной. Асимптотическое распределение критерия Колмогорова — Смирнова имеет распределение Колмогорова.
Чтобы лучше понять тест, построим кумулятивные функции распределения и статистику теста. Во-первых, вычислим кумулятивные функции распределения.
df_ks = pd.DataFrame()
df_ks['Income'] = np.sort(df['Income'].unique())
df_ks['F_control'] = df_ks['Income'].apply(lambda x: np.mean(income_c<=x))
df_ks['F_treatment'] = df_ks['Income'].apply(lambda x: np.mean(income_t<=x))
df_ks.head() Скриншот кумулятивного набора данных о распределении
Скриншот кумулятивного набора данных о распределении
Теперь нужно найти точку, где абсолютное расстояние между кумулятивными функциями распределения наибольшее.
k = np.argmax( np.abs(df_ks['F_control'] - df_ks['F_treatment']))
ks_stat = np.abs(df_ks['F_treatment'][k] - df_ks['F_control'][k])Можно также визуализировать значение тестовой статистики: построить две кумулятивные функции распределения и значение тестовой статистики.
y = (df_ks['F_treatment'][k] + df_ks['F_control'][k])/2
plt.plot('Income', 'F_control', data=df_ks, label='Control')
plt.plot('Income', 'F_treatment', data=df_ks, label='Treatment')
plt.errorbar(x=df_ks['Income'][k], y=y, yerr=ks_stat/2, color='k',
capsize=5, mew=3, label=f"Test statistic: {ks_stat:.4f}")
plt.legend(loc='center right');
plt.title("Kolmogorov-Smirnov Test");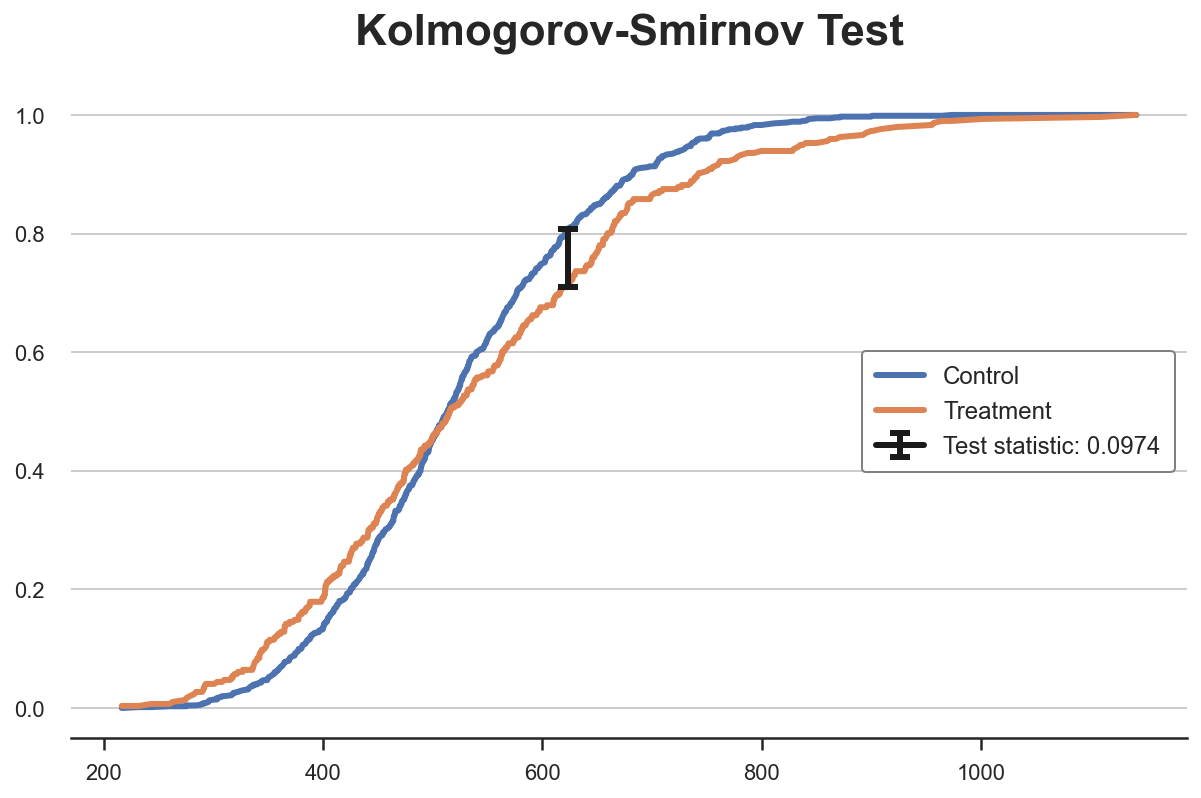 Статистика критерия Колмогорова — Смирнова
Статистика критерия Колмогорова — Смирнова
Видно, что значение тестовой статистики соответствует расстоянию между двумя кумулятивными распределениями при доходе ~650. Для этого значения дохода у нас самый большой дисбаланс между двумя группами.
А теперь можно выполнить сам тест, используя функцию kstest из scipy.
from scipy.stats import kstest
stat, p_value = kstest(income_t, income_c)
print(f" Kolmogorov-Smirnov Test: statistic={stat:.4f}, p-value={p_value:.4f}")
Kolmogorov-Smirnov Test: statistic=0.0974, p-value=0.0355Наше p-значение ниже 5%, поэтому с достоверностью 95% отвергаем нулевую гипотезу об одинаковости двух распределений.
Несколько групп — диаграммы
До сих пор рассматривался только случай двух групп: лечения и контроля. Но что, если групп несколько? Тогда некоторые методы выше масштабируются хорошо, а другие — нет. В качестве рабочего примера проверим, является ли распределение дохода одинаковым по типам лечения.
Диаграмма размаха («ящик с усами»)
Диаграмма размаха масштабируется очень хорошо, когда у нас есть несколько групп из однозначных чисел: разные блоки можно расположить рядом.
sns.boxplot(x='Arm', y='Income', data=df.sort_values('Arm'));
plt.title("Boxplot, multiple groups");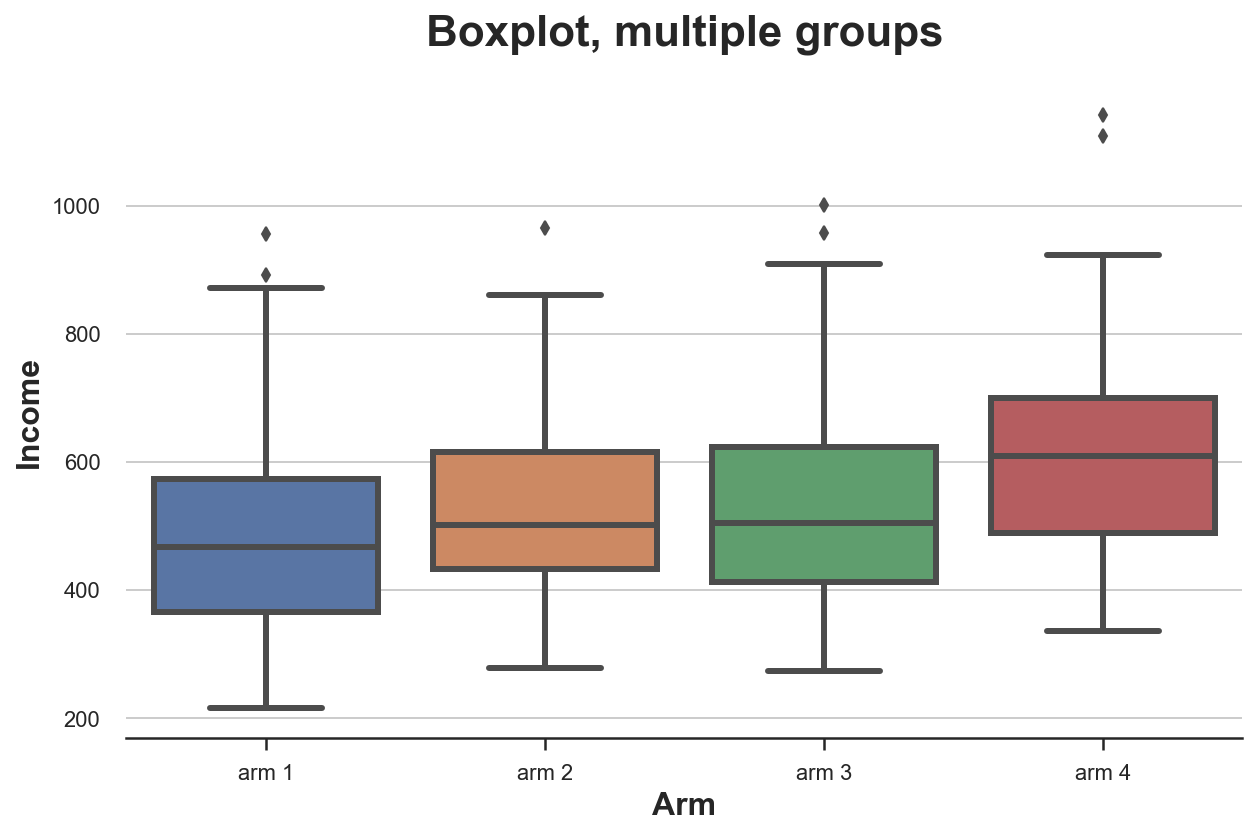 Распределение доходов по типам лечения
Распределение доходов по типам лечения
Распределение доходов по типам лечения отличается: группы с более высокими номерами имеют более высокий средний доход.
Скрипичная диаграмма
Очень хорошее расширение для диаграмм вида «ящик с усами», который сочетает в себе сводную статистику и ядерную оценку плотности, — скрипичная диаграмма. Она отображает отдельные плотности по оси Y так, что они не перекрываются. По умолчанию внутри добавляется миниатюрная диаграмма.
sns.violinplot(x='Arm', y='Income', data=df.sort_values('Arm'));
plt.title("Violin Plot, multiple groups");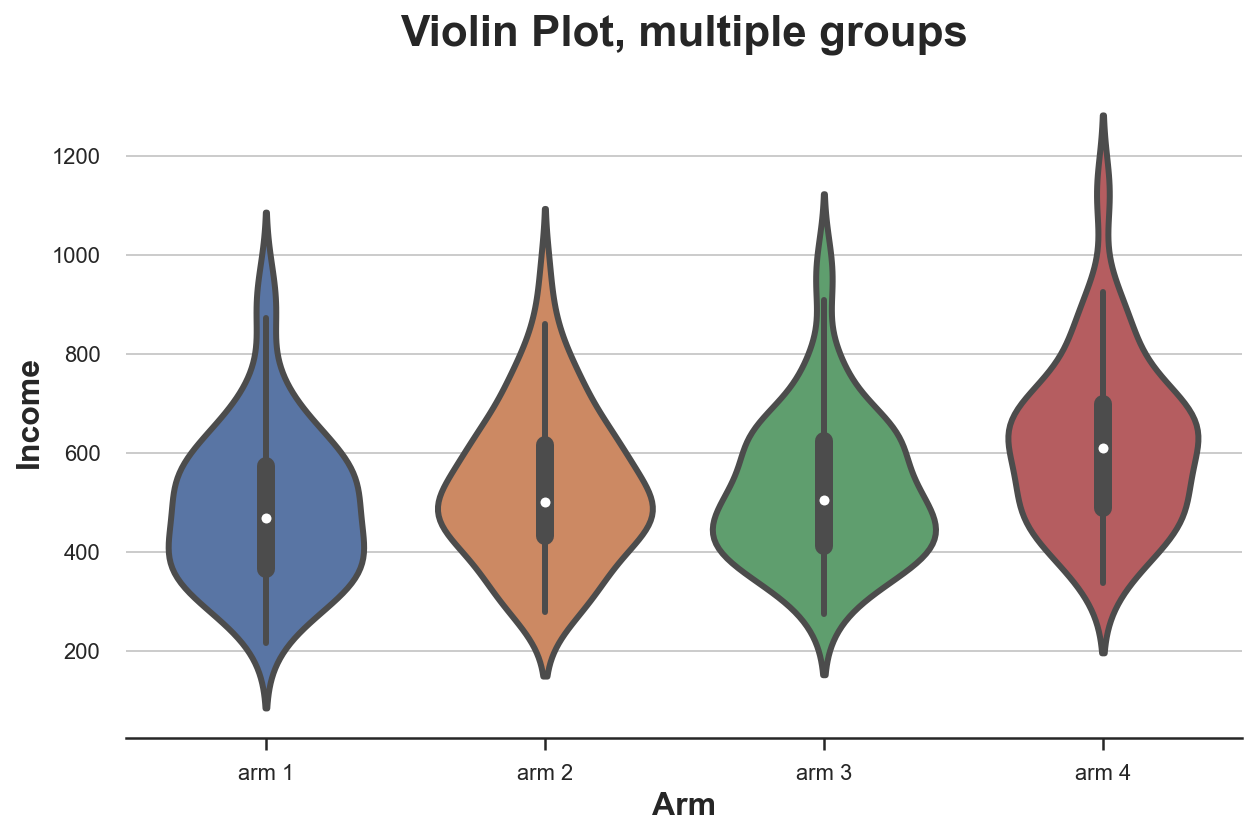 Распределение доходов по типам лечения
Распределение доходов по типам лечения
Как и «ящик с усами», скрипичная диаграмма предполагает, что в группах с разным типом лечения доход различается.
Ridgeline (групповая хребтовая диаграмма)
Эта диаграмма отображает несколько ядерных распределений плотности вдоль оси X, что делает их понятнее скрипичной диаграммы, но частично перекрывает распределения. К сожалению, ни в matplotlib, ни в seaborn нет групповой хребтовой диаграммы по умолчанию. Импортировать её нужно из joypy.
from joypy import joyplot
joyplot(df, by='Arm', column='Income', colormap=sns.color_palette("crest", as_cmap=True));
plt.xlabel('Income');
plt.title("Ridgeline Plot, multiple groups");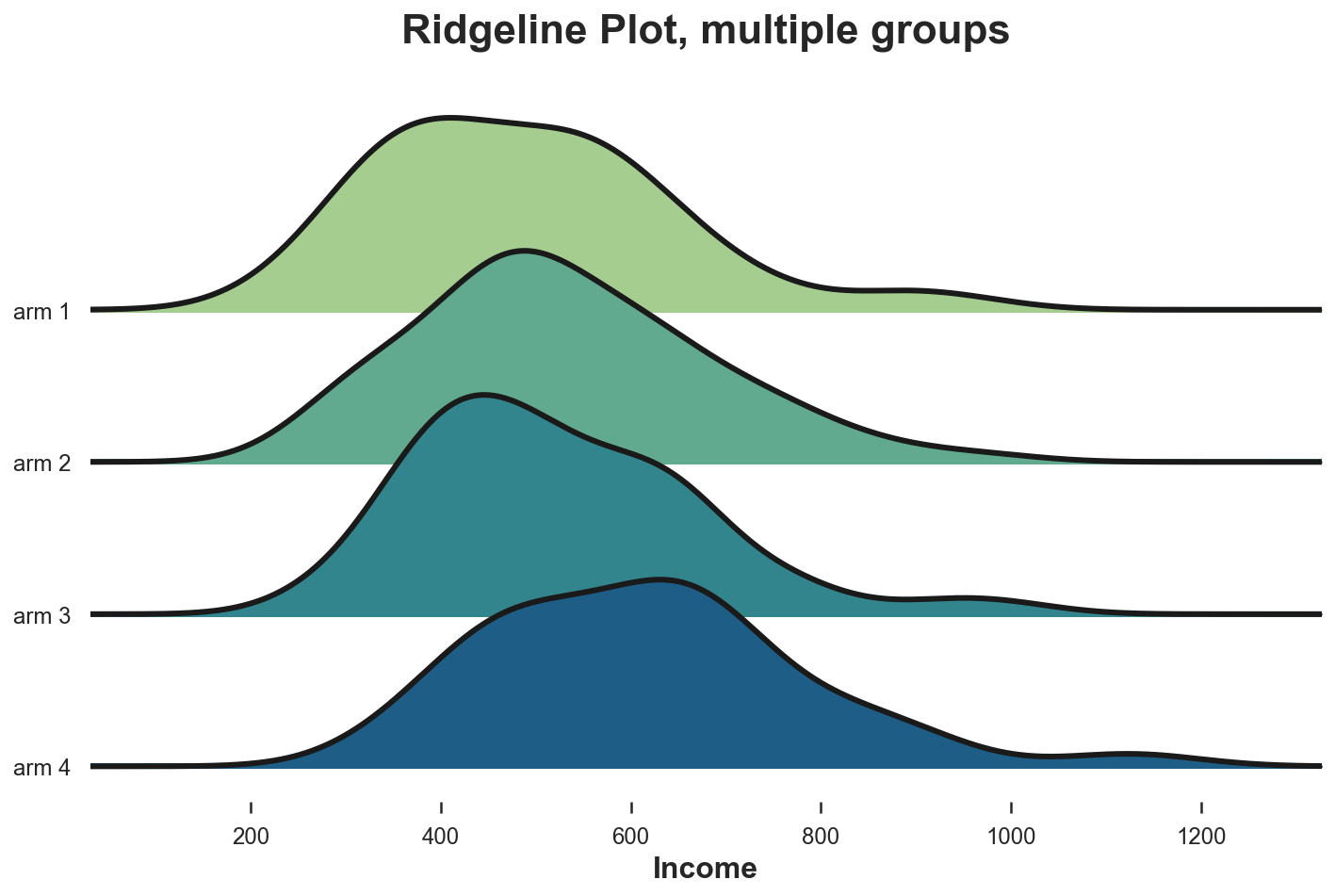 Распределение доходов по типам лечения
Распределение доходов по типам лечения
Опять же, групповая хребтовая диаграмма показывает, что группы лечения с более высокими номерами имеют доход выше остальных. На этой диаграмме легче оценить формы распределений.
Несколько групп — тесты
Рассмотрим проверку гипотез для сравнения нескольких групп. Для упрощения сосредоточимся на самом популярном F-тесте.
F-тест
Этот тест сравнивает дисперсию переменной в разных группах и также называется дисперсионным анализом (ANOVA).
Статистика F-теста определяется как:
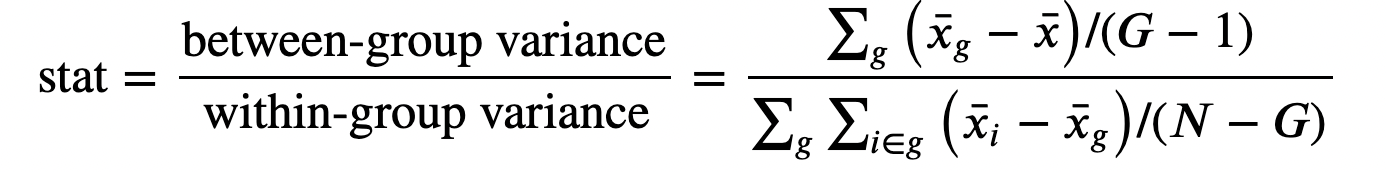 F-тест статистика
F-тест статистика
Здесь G — количество групп, N — количество наблюдений, x̅ — общее среднее, а x̅g — среднее значение в группе g. При нулевой гипотезе о независимости группы f-статистика обладает F-распределением.
from scipy.stats import f_oneway
income_groups = [df.loc[df['Arm']==arm, 'Income'].values for arm in df['Arm'].dropna().unique()]
stat, p_value = f_oneway(*income_groups)
print(f"F Test: statistic={stat:.4f}, p-value={p_value:.4f}")
F Test: statistic=9.0911, p-value=0.0000Тестовое p-значение практически равно нулю, что подразумевает решительное отклонение нулевой гипотезы об отсутствии различий в распределении доходов между типами лечения.
Код
Ссылка на Jupyter Notebook.
А пока вы сравниваете распределения, мы поможем вам прокачать навыки или с самого начала освоить профессию, актуальную в любое время:
Выбрать другую востребованную профессию.

Ссылки
[1] Student, The Probable Error of a Mean (1908), Biometrika.
[2] F. Wilcoxon, Individual Comparisons by Ranking Methods (1945), Biometrics Bulletin.
[3] B.L. Welch, The generalization of «Student«s» problem when several different population variances are involved (1947), Biometrika.
[4] H.B. Mann, D.R. Whitney, On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other (1947), The Annals of Mathematical Statistics.
[5] E. Brunner, U. Munzen, The Nonparametric Behrens-Fisher Problem: Asymptotic Theory and a Small-Sample Approximation (2000), Biometrical Journal.
[6] A.N. Kolmogorov, Sulla determinazione empirica di una legge di distribuzione (1933), Giorn. Ist. Ital. Attuar..
[7] H. Cramér, On the composition of elementary errors (1928), Scandinavian Actuarial Journal.
[8] R. von Mises, Wahrscheinlichkeit statistik und wahrheit (1936), Bulletin of the American Mathematical Society.
[9] T.W. Anderson, D.A. Darling, Asymptotic Theory of Certain «Goodness of Fit» Criteria Based on Stochastic Processes (1953), The Annals of Mathematical Statistics.
