[Перевод] Как с помощью ML удалять объекты из видео

В новом исследовании, проведённом в Китае, сообщается о высоких результатах и впечатляющем росте эффективности новой системы ретуширования, позволяющей легко удалять объекты на видео. Подробности рассказываем к старту флагманского курса по Data Science.
Посмотрите демонстрацию:

Подвеска параплана закрашивается по новой методике. Смотрите видео (в конце статьи): там лучше разрешение и есть примеры.
Эта многоцелевая технология потоконаправленного ретуширования видео E2FGVI способна также удалять из видеоконтента различные затемнения и водяные знаки.
 Для скрытого за затемнениями контента в E2FGVI вычисляются прогнозы, позволяющие удалять даже заметные водяные знаки и те, что не удаляются никаким иным способом. Источник: https://github.com/MCG-NKU/E2FGVI
Для скрытого за затемнениями контента в E2FGVI вычисляются прогнозы, позволяющие удалять даже заметные водяные знаки и те, что не удаляются никаким иным способом. Источник: https://github.com/MCG-NKU/E2FGVI
Хотя модель из опубликованной работы обучалась на видео с размерами 432×240 пикселей (обычно с входными данными небольших размеров, ограниченными доступным пространством графического процессора в сравнении с оптимальными размерами пакетов и другими факторами). С тех пор авторы выпустили E2FGVI-HQ, способную обрабатывать видео произвольного разрешения.
Код текущей версии решения доступен на GitHub, а версию HQ можно загрузить с Google Drive и Baidu Disk.
 Ребёнок остаётся в кадре
Ребёнок остаётся в кадре
E2FGVI способна обрабатывать видео размером 432×240 со скоростью 0,12 с за кадр на графическом процессоре Titan XP (12 Гб видеопамяти). По словам авторов, система работает в 15 раз быстрее предыдущих передовых методов, основанных на оптическом потоке.
 Теннисист внезапно исчезает
Теннисист внезапно исчезает
Новый метод протестирован на стандартных наборах данных для этого вида исследований синтеза изображений. Он обошёл конкурентов и по качественной, и по количественной оценке.
 Сравнение с предыдущими подходами. Источник: https://arxiv.org/pdf/2204.02663.pdf
Сравнение с предыдущими подходами. Источник: https://arxiv.org/pdf/2204.02663.pdf
Работа называется Towards An End-to-End Framework for Flow-Guided Video Inpainting («Многоцелевая технология потоконаправленного ретуширования видео»). Её авторы — четыре исследователя из Нанькайского университета и ещё один из компании Hisilicon Technologies.
Чего не хватает на этой картинке
Кроме очевидного применения в визуальных эффектах, высококачественное ретуширование видео должно стать главным, определяющим функционалом новых, основанных на ИИ технологий синтеза и изменения изображений.
Особенно это относится к фэшн-приложениям, связанным с изменением тела, и другим фреймворкам, нацеленным на «похудение» или какое-то иное изменение сцен на изображениях и видео. В таких случаях необходимо «заполнить» обнаруживаемый при синтезе дополнительный фон так, чтобы заполнение выглядело правдоподобно.
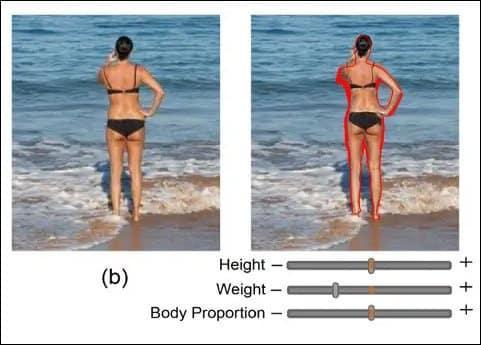 В одной из последних работ алгоритму изменения формы тела поручено заретушировать фон, который появился при изменении размера объекта. Здесь он обозначен красным как часть фигуры реальной девушки на изображении слева. На основе первоисточника из https://arxiv.org/pdf/2203.10496.pdf
В одной из последних работ алгоритму изменения формы тела поручено заретушировать фон, который появился при изменении размера объекта. Здесь он обозначен красным как часть фигуры реальной девушки на изображении слева. На основе первоисточника из https://arxiv.org/pdf/2203.10496.pdf
Когерентный оптический поток
Оптический поток стал основной технологией при работе над удалением объектов из видео. Как и в atlas, здесь используется покадровая карта временнóй последовательности. Оптический поток часто применяется для измерения скорости в проектах по компьютерному зрению. И он может обеспечить последовательное во времени ретуширование, когда общий итог задачи может быть рассмотрен за один проход, а не со вниманием к каждому кадру (как в диснеевском стиле), что неизбежно приводит к временнóй неоднородности.
Методы ретуширования видео сегодня основаны на процессе из трёх этапов:
Завершение потока, когда видео фактически сопоставляется с дискретной и доступной для изучения сущностью;
Распространение пикселей, когда дыры в «повреждённых» видео заполняются пикселями, которые распространяются двунаправленно;
Галлюцинация контента («изобретение» пикселей, знакомое большинству из нас по deepfakes и фреймворкам преобразования текста в изображение, например серии DALL-E), когда предположительно «недостающий» контент придумывается и вставляется в видео.
Центральное новшество E2FGVI — объединение этих трёх этапов в многоцелевую систему, которая избавляет от необходимости выполнения ручных операций в контенте или процессе.
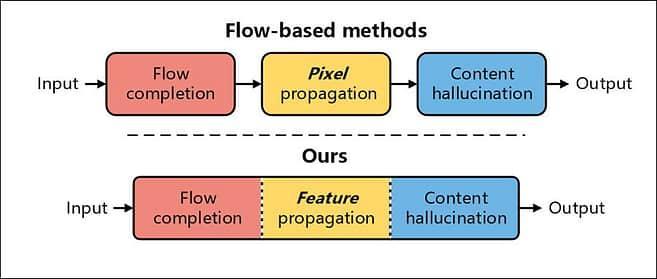 В работе отмечается, что необходимость ручного вмешательства подразумевает неиспользование в более старых процессах графического процессора, что делает их довольно времязатратными.
В работе отмечается, что необходимость ручного вмешательства подразумевает неиспользование в более старых процессах графического процессора, что делает их довольно времязатратными.
Цитата из работы:
«Возьмём в качестве примера DFVI. На завершение одного видео размером 432 × 240 из DAVIS, которое содержит около 70 кадров, требуется около четырёх минут. В большинстве реальных приложений это неприемлемо. Помимо вышеупомянутых недостатков, при использовании предобученной сети ретуширования изображений только на этапе галлюцинации контента взаимосвязи контента между соседями по времени не учитываются. Это приводит к генерации непоследовательного контента».
Объединяя три этапа ретуширования видео, E2FGVI способна второй этап — распространение пикселей — заменить распространением признаков. В более сегментированных процессах предыдущих работ признаки не настолько доступны, поскольку каждый этап относительно герметичен, а рабочий процесс автоматизирован лишь наполовину.
В дополнение к этому исследователи создали для этапа галлюцинации контента временной фокальный трансформер, в котором учитываются не только ближайшие пиксели в текущем кадре (то есть то, что происходит в той части кадра на предыдущем или следующем изображении), но и те, что отделены от них множеством кадров, но всё же повлияет на целостный эффект любых операций, выполняемых во всём видео.
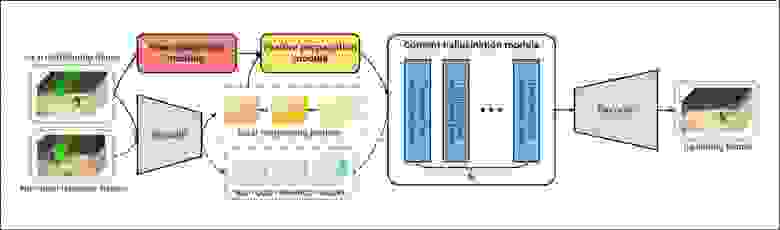 Архитектура E2FGVI
Архитектура E2FGVI
Центральная часть рабочего процесса на основе признаков способна использовать преимущества процессов уровня признаков и обучаемых смещений выборки, а в новом фокальном трансформере проекта размерность фокальных окон увеличивается, по словам авторов, с »2D до 3D».
Тесты и данные
Чтобы протестировать E2FGVI, исследователи проанализировали систему по двум популярным наборам данных для сегментации объектов на видео: YouTube-VOS и DAVIS. В YouTube-VOS содержится 3741 обучающий видеоклип, 474 клипа валидации и 508 тестовых клипов, а в DAVIS — 60 обучающих видеоклипов и 90 тестовых клипов.
E2FGVI обучили на YouTube-VOS и проанализировали на обоих наборах данных. Чтобы смоделировать завершение видео, во время обучения генерировались маски объектов (зелёные области на представленных выше изображениях и на видео в конце статьи).
В качестве метрик исследователи использовали пиковое отношение сигнал/шум (PSNR), индекс структурного сходства (SSIM), расстояние Фреше по видео (VFID) и ошибку искажения потока — последнее для измерения временнóй стабильности в видео.
Вот предыдущие архитектуры, на которых тестировалась система: VINet, DFVI, LGTSM, CAP, FGVC, STTN и FuseFormer.
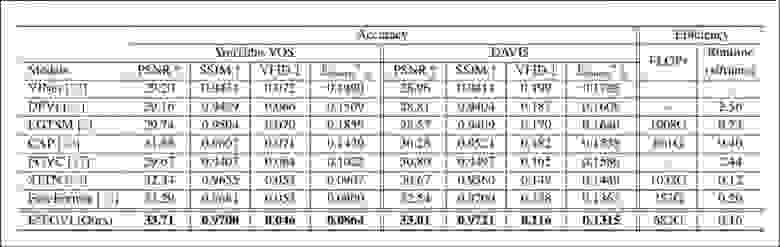 Из раздела работы, посвящённого количественным результатам. Стрелками вверх и вниз показано, что лучше соответственно бóльшие или меньшие числа. В E2FGVI лучшие результаты достигаются везде. Методы оцениваются по FuseFormer, хотя DFVI, VINet и FGVC не являются многоцелевыми системами, поэтому оценка их операций с плавающей точкой в секунду невозможна
Из раздела работы, посвящённого количественным результатам. Стрелками вверх и вниз показано, что лучше соответственно бóльшие или меньшие числа. В E2FGVI лучшие результаты достигаются везде. Методы оцениваются по FuseFormer, хотя DFVI, VINet и FGVC не являются многоцелевыми системами, поэтому оценка их операций с плавающей точкой в секунду невозможна
Получив лучшие по сравнению со всеми конкурирующими системами результаты, учёные провели качественное исследование пользователей. Видео, преобразованные с помощью пяти представленных методов, продемонстрировали каждому из 20 добровольцев, которых попросили оценить их визуальное качество.
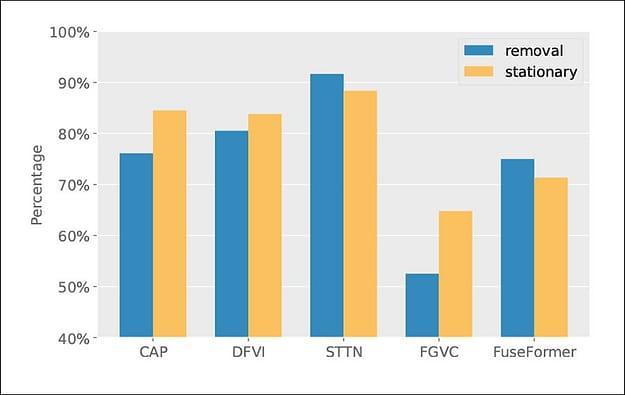 На вертикальной оси показан процент участников, которые предпочли результат E2FGVI
На вертикальной оси показан процент участников, которые предпочли результат E2FGVI
Авторы отмечают, что, несмотря на единодушное предпочтение их метода респондентами, один из результатов (FGVC) количественно выбивается из общей картины. По их мнению, это указывает на то, что в E2FGVI, предположительно, могут генерироваться «результаты визуально приятнее».
Что касается эффективности, авторы отмечают, что в их системе значительно уменьшается количество операции с плавающей точкой в секунду (FLOPs) и время вывода на одном графическом процессоре Titan в наборе данных DAVIS. Они также отмечают, что E2FGVI в 15 раз быстрее потоковых методов.
Вот их комментарий:
»[E2FGVI] выполняет наименьшее число операций с плавающей точкой в секунду по сравнению со всеми остальными методами. Это указывает на то, что предлагаемый метод высокоэффективен для ретуширования видео».
А мы поможем вам прокачать навыки или с самого начала освоить профессию, актуальную в любое время:
Выбрать другую востребованную профессию.

