[Перевод] Как работает JS: сетевая подсистема браузеров, оптимизация её производительности и безопасности
В переводе двенадцатой части серии материалов о JavaScript и его экосистеме, который мы сегодня публикуем, речь пойдёт о сетевой подсистеме браузеров и об оптимизации производительности и безопасности сетевых операций. Автор материала говорит, что разница между хорошим и отличным JS-разработчиком заключается не только в уровне освоения языка, но и в том, насколько хорошо он разбирается в механизмах, не входящих в язык, но используемых им. Собственно говоря, работа с сетью — это один из таких механизмов.

Немного истории
49 лет назад была создана компьютерная сеть ARPAnet, объединяющая несколько научных учреждений. Это была одна из первых сетей с коммутацией пакетов, и первая сеть, в который была реализована модель TCP/IP. Двадцатью годами позже Тим Бернес-Ли предложил проект известный как Всемирная паутина. За годы, которые прошли с запуска ARPAnet, интернет прошёл долгий путь — от пары компьютеров, обменивающихся пакетами данных, до более чем 75 миллионов серверов, примерно 1.3 миллиарда веб-сайтов и 3.8 миллиарда пользователей.

Количество пользователей интернета в мире
В этом материале мы поговорим о том, какие механизмы используют браузеры для того, чтобы повысить производительность работы с сетью (эти механизмы скрыты в их недрах, вероятно, вы о них, работая с сетью в JS, даже и не думаете). Кроме того, мы обратим особое внимание на сетевой уровень браузеров и приведём здесь несколько рекомендаций, касающихся того, как разработчик может помочь браузеру повысить производительность сетевой подсистемы, которую задействуют веб-приложения.
Обзор
При разработке современных веб-браузеров особое внимание уделяется быстрой, эффективной и безопасной загрузке в них страниц веб-сайтов и веб-приложений. Работу браузеров обеспечивают сотни компонентов, выполняющихся на различных уровнях и решающих широкий спектр задач, среди которых — управление процессами, безопасное выполнение кода, декодирование и воспроизведение аудио и видео, взаимодействие с видеоподсистемой компьютера и многое другое. Всё это делает браузеры больше похожими на операционные системы, а не на обычные приложения.
Общая производительность браузера зависит от целого ряда компонентов, среди которых, если рассмотреть их укрупнённо, можно отметить подсистемы, решающие задачи разбора загружаемого кода, формирования макетов страниц, применения стилей, выполнения JavaScript и WebAssembly-кода. Конечно же, сюда входят и система визуализации информации, и реализованный в браузере сетевой стек.
Программисты часто думают, что узким местом браузера является именно его сетевая подсистема. Часто так и бывает, так как все ресурсы, прежде чем с ними можно будет что-то сделать, сначала должны быть загружены из сети. Для того чтобы сетевой уровень браузера был эффективным, ему нужны возможности, позволяющие играть роль чего-то большего, нежели роль простого средства для работы с сокетами. Сетевой уровень даёт нам очень простой механизм загрузки данных, но, на самом деле, за этой внешней простотой скрывается целая платформа с собственными критериями оптимизации, API и службами.
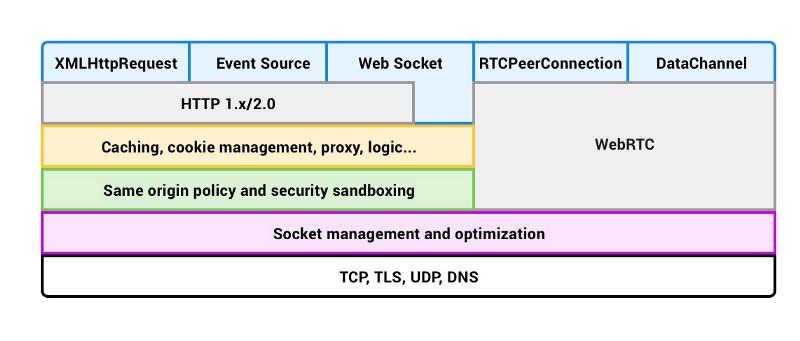
Сетевая подсистема браузера
Занимаясь веб-разработкой, мы можем не беспокоиться об отдельных TCP или UDP-пакетах, о форматировании запросов, о кэшировании, и обо всём остальном, что происходит в ходе взаимодействия браузера с сервером. Решением всех этих сложных задач занимается браузер, что даёт нам возможность сосредоточиться на разработке приложений. Однако, знание того, что происходит в недрах браузера, может помочь нам в деле создания более быстрых и безопасных программ.
Поговорим о том, как выглядит обычный сеанс взаимодействия пользователя с браузером. В целом, он состоит из следующих операций:
- Пользователь вводит URL в адресную строку браузера.
- Браузер, получив этот URL, ведущий на какой-либо веб-ресурс, начинает с того, что проверяет собственные кэши, локальный кэш и кэш приложения, для того, чтобы, если там есть то, что нужно пользователю, выполнить запрос, опираясь на локальные копии ресурсов.
- Если кэш использовать не удаётся, браузер берёт доменное имя из URL и запрашивает IP-адрес сервера, обращаясь к DNS. В то же время, если сведения об IP-адресе домена уже есть в кэше браузера, к DNS ему обращаться не придётся.
- Браузер формирует HTTP-пакет, который нужен для того, чтобы запросить страницу с удалённого сервера.
- HTTP-пакет отправляется на уровень TCP, который добавляет в него собственные сведения, необходимые для управления сессией.
- Затем получившийся пакет уходит на уровень IP, основная задача которого заключается в том, чтобы найти способ отправки пакета с компьютера пользователя на удалённый сервер. На этом уровне к пакету так же добавляются дополнительные сведения, обеспечивающие передачу пакета.
- Пакет отправляется на удалённый сервер.
- После того как сервер получает пакет запроса, ответ на этот запрос отправляется в браузер, проходя похожий путь.
Существует браузерное API, так называемое Navigation Timing API, в основе которого лежит спецификация Navigation Timing, подготовленная W3C. Оно позволяет получать сведения о том, сколько времени занимает выполнение различных операций в процессе жизненного цикла запросов. Рассмотрим компоненты жизненного цикла запроса, так как каждый из них серьёзно влияет на то, насколько пользователю будет удобно работать с веб-ресурсом.
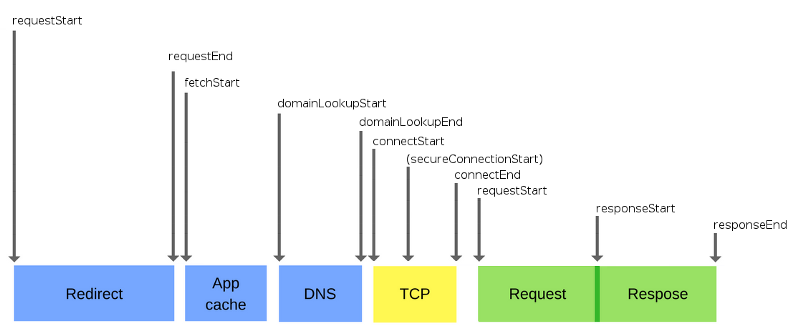
Жизненный цикл запроса
Весь процесс обмена данными по сети очень сложен, он представлен множеством уровней, каждый из которых может стать узким местом. Именно поэтому браузеры стремятся к тому, чтобы улучшить производительность на своей стороне, используя различные подходы. Это помогает снизить, до минимально возможных значений, воздействие особенностей сетей на производительность сайтов.
Управление сокетами
Прежде чем говорить об управлении сокетами, рассмотрим некоторые важные понятия:
- Источник (origin) — это набор данных, описывающий источник информации, состоящий из трёх частей: протокол, доменное имя и номер порта. Например: https, www.example.com, 443.
- Пул сокетов (socket pool) — это группа сокетов, принадлежащих одному и тому же источнику (все основные браузеры ограничивают максимальный размер пула шестью сокетами).
JavaScript и WebAssembly не позволяют программисту управлять жизненным циклом отдельного сетевого сокета, и, надо сказать, это хорошо. Это не только избавляет разработчика от необходимости работы с низкоуровневыми сетевыми механизмами, но и позволяют браузеру автоматически применять множество оптимизаций производительности, среди которых — повторное использование сокета, приоритизация запросов и позднее связывание, согласование протоколов, принудительное задание ограничений соединений и многие другие.
На самом деле, современные браузеры не жалеют сил на раздельное управление запросами и сокетами. Сокеты организованы в пулы, которые сгруппированы по источнику. В каждом пуле применяются собственные лимиты соединений и ограничения, касающиеся безопасности. Запросы, выполняемые к источнику, ставятся в очередь, приоритизируются, а затем привязываются к конкретным сокетам в пуле. Если только сервер не закроет соединение намеренно, один и тот же сокет может быть автоматически переиспользован для выполнения многих запросов.
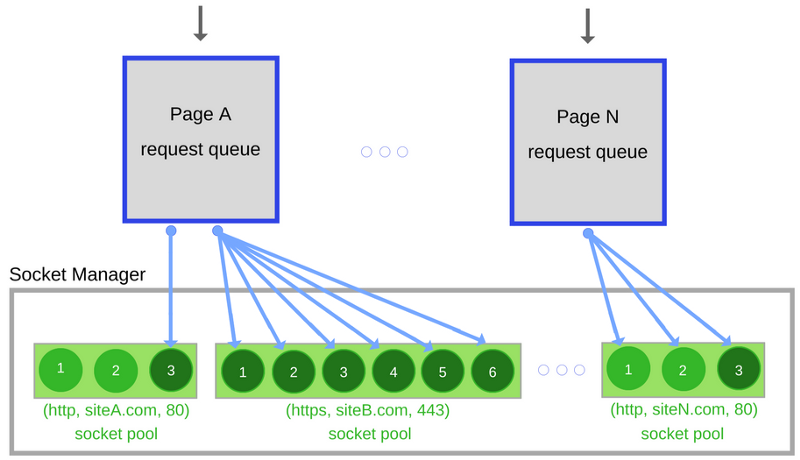
Очереди запросов и система управления сокетами
Так как открытие нового TCP-соединения требует определённых затрат системных ресурсов и некоторого времени, переиспользование соединений, само по себе, является отличным средством повышения производительности. По умолчанию браузер использует так называемый механизм «keepalive», который позволяет экономить время на открытии соединения к серверу при выполнении нового запроса. Вот средние показатели времени, необходимого для открытия нового TCP-соединения:
- Локальные запросы: 23 мс.
- Трансконтинентальные запросы: 120 мс.
- Интерконтинентальные запросы: 225 мс.
Такая архитектура открывает возможности для множества других оптимизаций. Например, запросы могут быть выполнены в порядке, зависящем от их приоритета. Браузер может оптимизировать выделение полосы пропускания, распределив её между всеми сокетами, или он может заблаговременно открывать сокеты в ожидании очередного запроса.
Как уже было сказано, всё это управляется браузером и не требует усилий со стороны программиста. Однако это не означает, что программист не может сделать ничего для того, чтобы помочь браузеру. Так, например, выбор подходящих шаблонов сетевого взаимодействия, частоты передачи данных, выбор протокола, настройка и оптимизация серверного стека, могут сыграть значительную роль в повышении общей производительности приложения.
Некоторые браузеры в деле оптимизации сетевых соединений идут ещё дальше. Например, Chrome может «самообучаться» по мере его использования, что ускоряет работу с веб-ресурсами. Он анализирует посещённые сайты и типичные шаблоны работы в интернете, что даёт ему возможность прогнозировать поведение пользователя и предпринимать какие-то меры ещё до того, как пользователь что-либо сделает. Самый простой пример — это предварительный рендеринг страницы в тот момент, когда пользователь наводит указатель мыши на ссылку. Если вам интересны внутренние механизмы оптимизации, применяемые в Chrome, вот — полезный материал на эту тему.
Сетевая безопасность и ограничения
У того, что браузеру позволено управлять отдельными сокетами, есть, помимо оптимизации производительности, ещё одна важная цель: благодаря такому подходу браузер может применять единообразный набор ограничений и правил, касающихся безопасности, при работе с недоверенными ресурсами приложений. Например, браузер не даёт прямого доступа к сокетам, так как это позволило бы любому потенциально опасному приложению выполнять произвольные соединения с любыми сетевыми системами. Браузер, кроме того, применяет ограничение на число соединений, что защищает сервер и клиент от чрезмерного использования сетевых ресурсов.
Браузер форматирует все исходящие запросы для защиты сервера от запросов, которые могут быть сформированы неправильно. Точно так же браузер относится и к ответам серверов, автоматически декодируя их и принимая меры для защиты пользователя от возможных угроз, исходящих со стороны сервера.
Процедура TLS-согласования
TLS (Transport Layer Security, протокол защиты транспортного уровня), это криптографический протокол, который обеспечивает безопасность передачи данных по компьютерным сетям. Он нашёл широкое использование во множестве областей, одна из которых — работа с веб-сайтами. Веб-сайты могут использовать TLS для защиты всех сеансов взаимодействия между серверами и веб-браузерами.
Вот как, в общих чертах, выглядит процедура TLS-рукопожатия:
- Клиент посылает серверу сообщение ClientHello, указывая, кроме прочего, список поддерживаемых методов шифрование и случайное число.
- Сервер отвечает клиенту, отправляя сообщение ServerHello, где, кроме прочего, имеется случайное число, сгенерированное сервером.
- Сервер отправляет клиенту свой сертификат, используемый для целей аутентификации, и может запросить подобный сертификат у клиента. Далее, сервер отправляет клиенту сообщение ServerHelloDone.
- Если сервер запросил сертификат у клиента, клиент отправляет ему сертификат.
- Клиент создаёт случайный ключ, PreMasterSecret, и шифрует его открытым ключом из сертификата сервера, отправляя серверу зашифрованный ключ.
- Сервер принимает ключ PreMasterSecret. На его основе сервер и клиент генерируют ключ MasterSecret и сессионные ключи.
- Клиент отправляет серверу сообщение ChangeCipherSpec, указывающее на то, что клиент начнёт использовать новые сессионные ключи для хэширования и шифрования сообщений. Кроме того, клиент отправляет серверу сообщение ClientFinished.
- Сервер принимает сообщение ChangeCipherSpec и переключает систему безопасности своего уровня записей на симметричное шифрование, используя сессионный ключ. Сервер отправляет клиенту сообщение ServerFinished.
- Теперь клиент и сервер могут обмениваться данными приложения по установленному ими защищённому каналу связи. Все эти сообщения будут зашифрованы с использованием сессионного ключа.
Пользователь будет предупреждён в том случае, если верификация окажется неудачной, то есть, например, если сервер использует самоподписанный сертификат.
Принцип одного источника
В соответствии с принципом одного источника (Same-origin policy), две страницы имеют один и тот же источник, если их протокол, порт (если задан) и хост совпадают.
Вот несколько примеров ресурсов, которые могут быть встроены в страницу с несоблюдением принципа одного источника:
- JS-код, подключённый к странице с использованием конструкции
. Сообщения о синтаксических ошибках доступны только для скриптов, имеющих тот же источник, что и страница. - CSS-стили, подключённые к странице с помощью тега
. Благодаря менее строгим синтаксическим правилам, при получении CSS из другого источника, требуется наличие правильного заголовкаContent-Type. Ограничения в данном случае зависят от браузера. - Изображения (тег
- Медиа-файлы (теги
и). - Плагины (теги
,и). - Шрифты, использующие
@font-face. Некоторые браузеры позволяют использование шрифтов из источников, отличающихся от источника страницы, некоторые — нет. - Всё, что загружается в теги
и