[Перевод] Как помочь pandas в обработке больших объёмов данных?
Библиотека pandas — это один из лучших инструментов для разведочного анализа данных. Но это не означает, что pandas — это универсальное средство, подходящее для решения любых задач. В частности, речь идёт об обработке больших объемов данных. Мне довелось провести очень и очень много времени, ожидая, пока pandas прочтёт множество файлов, или обработает их, вычислив на основе находящихся в них сведений какие-то интересующие меня показатели. Дело в том, что pandas не поддерживает механизмы параллельной обработки данных. В результате этому пакету не удаётся на полную мощность воспользоваться возможностями современных многоядерных процессоров. Большие наборы данных в pandas обрабатываются медленно.

Недавно я задался целью найти что-то такое, что позволит помочь мне в деле обработки больших данных. Мне удалось найти то, что я искал, я встроил найденный инструмент в свой конвейер обработки данных. Я использую его для работы с большими объёмами данных. Например — для чтения файлов, содержащих 10 гигабайт данных, для их фильтрации и агрегирования. Когда я справляюсь с решением подобных задач, я сохраняю то, что у меня получилось, в CSV-файле меньшего размера, который подходит для pandas, после чего приступаю к работе с полученными данными с помощью pandas.
Вот блокнот Jupyter, содержащий примеры к этому материалу, с которыми можно поэкспериментировать.
Dask
Тем инструментом, который я использую для обработки больших объёмов данных, стала библиотека Dask. Она поддерживает параллельную обработку данных, позволяя ускорить работу существующих инструментов. Сюда входят numpy, pandas и sklearn. Dask — это бесплатный опенсорсный проект. В нём применяются API и структуры данных Python, что облегчает интеграцию Dask в существующие проекты. Если в двух словах описать Dask, то можно сказать, что эта библиотека упрощает решение обычных задач и делает возможным решение задач огромной сложности.
Сравнение pandas и Dask
Я могу тут описывать возможности Dask, так как эта библиотека умеет очень много всего интересного, но я, вместо этого, просто рассмотрю один практический пример. Я, в ходе работы, обычно сталкиваюсь с наборами файлов большого объёма, данные, хранящиеся в которых, нужно проанализировать. Давайте воспроизведём одну из моих типичных задач и создадим 10 файлов, в каждом из которых содержится 100000 записей. Каждый такой файл имеет размер 196 Мб.
from sklearn.datasets import make_classification
import pandas as pd
for i in range(1, 11):
print('Generating trainset %d' % i)
x, y = make_classification(n_samples=100_000, n_features=100)
df = pd.DataFrame(data=x)
df['y'] = y
df.to_csv('trainset_%d.csv' % i, index=False)
Теперь прочитаем эти файлы с помощью pandas и замерим время, необходимое на их чтение. В pandas нет встроенной поддержки glob, поэтому нам придётся читать файлы в цикле:
%%time
import glob
df_list = []
for filename in glob.glob('trainset_*.csv'):
df_ = pd.read_csv(filename)
df_list.append(df_)
df = pd.concat(df_list)
df.shape
На то, чтобы прочитать эти файлы, pandas потребовалось 16 секунд:
CPU times: user 14.6 s, sys: 1.29 s, total: 15.9 s
Wall time: 16 s
Если говорить о Dask, то можно отметить, что эта библиотека позволяет обрабатывать файлы, которые не помещаются в памяти. Делается это с помощью разбивки их на блоки и с помощью составления цепочек задач. Измерим время, необходимое Dask на чтение этих файлов:
import dask.dataframe as dd
%%time
df = dd.read_csv('trainset_*.csv')
CPU times: user 154 ms, sys: 58.6 ms, total: 212 ms
Wall time: 212 ms
Dask потребовалось 154 мс! Как такое вообще возможно? На самом деле, это невозможно. В Dask реализована парадигма отложенного выполнения задач. Вычисления выполняются только тогда, когда нужны их результаты. Мы описываем граф выполнения, что даёт Dask возможность оптимизировать выполнение задач. Повторим эксперимент. Обратите внимание на то, что функция read_csv из Dask имеет встроенную поддержку работы с glob:
%%time
df = dd.read_csv('trainset_*.csv').compute()
CPU times: user 39.5 s, sys: 5.3 s, total: 44.8 s
Wall time: 8.21 s
Применение функции compute заставляет Dask вернуть результат, для чего нужно по-настоящему прочитать файлы. В результате оказывается, что Dask читает файлы в два раза быстрее чем pandas.
Можно сказать, что Dask позволяет оснащать Python-проекты средствами масштабирования вычислений.
Сравнение использования процессора в Pandas и в Dask
Пользуется ли Dask всеми процессорными ядрами, имеющимися в системе? Сравним использование ресурсов процессора в pandas и в Dask при чтении файлов. Здесь применяется тот же код, который мы рассматривали выше.
Использование ресурсов процессора при чтении файлов с помощью pandas

Использование ресурсов процессора при чтении файлов с помощью Dask
Пара вышеприведённых анимированных изображений позволяет ясно увидеть то, как pandas и Dask пользуются ресурсами процессора при чтении файлов.
Что происходит в недрах Dask?
Датафрейм Dask состоит из нескольких датафреймов pandas, которые разделены по индексам. Когда мы выполняем функцию read_csv из Dask, выполняется чтение одного и того же файла несколькими процессами.
Мы даже можем визуализировать граф выполнения этой задачи.
exec_graph = dd.read_csv('trainset_*.csv')
exec_graph.visualize()
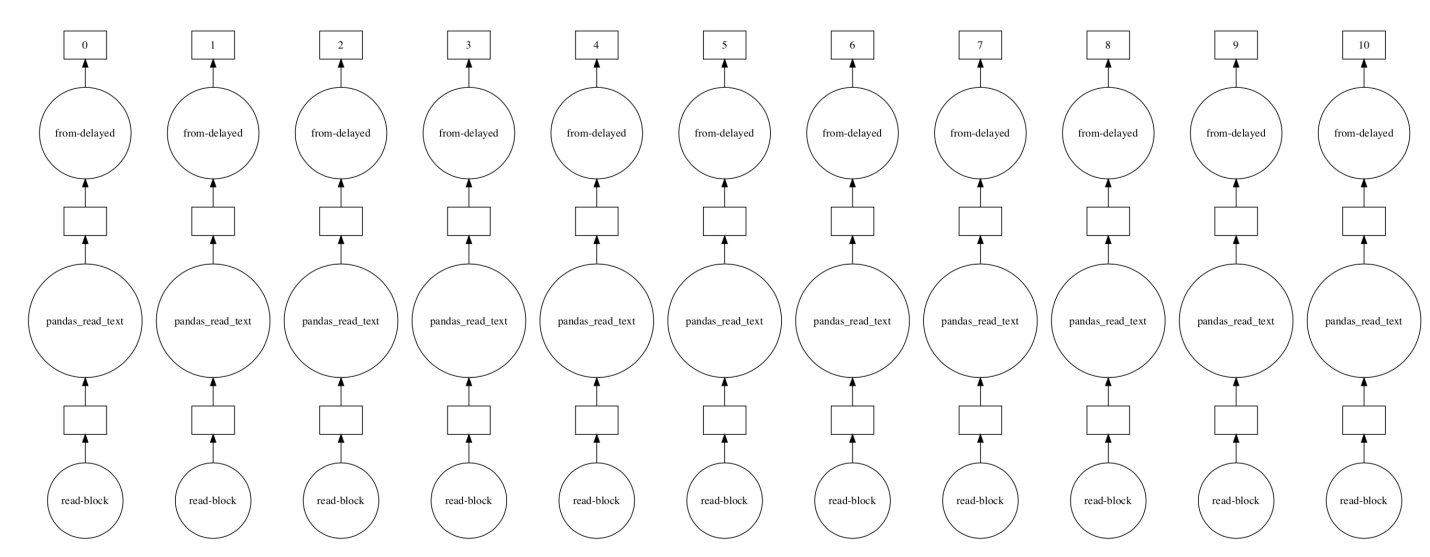
Граф выполнения Dask при чтении нескольких файлов
Недостатки Dask
Возможно, вам сейчас пришла следующая мысль: «Если библиотека Dask так хороша — почему бы просто не использовать её вместо pandas?». Но не всё так просто. В Dask портированы лишь некоторые функции pandas. Дело в том, что определённые задачи сложно распараллелить. Например — это сортировка данных и назначение индексов неотсортированным столбцам. Dask — это не инструмент, решающий абсолютно все задачи анализа и обработки данных. Эту библиотеку рекомендуется использовать только для работы с наборами данных, которые не помещаются в памяти целиком. Так как библиотека Dask основана на pandas, то всё то, что медленно работает в pandas, останется медленным и в Dask. Как я уже говорил, Dask — это полезный инструмент, который можно встроить в конвейер обработки данных, но этот инструмент не заменяет другие библиотеки.
Установка Dask
Для того чтобы установить Dask, можно воспользоваться следующей командой:
python -m pip install "dask[complete]"
Итоги
В этом материале я лишь поверхностно затронул возможности Dask. Если вам данная библиотека интересна — взгляните на эти замечательные учебные руководства по Dask, и на документацию по датафреймам Dask. А если хотите узнать о том, какие функции поддерживают датафреймы Dask — почитайте описание API DataFrame.
А вы воспользовались бы библиотекой Dask?
Напоминаем, что у нас продолжается конкурс прогнозов, в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.

