[Перевод] Как мы устранили редкую ошибку, из-за которой пришлось разлогинить всех пользователей Github
8 марта мы рассказали о том, что из соображений безопасности разлогинили всех пользователей GitHub.com из-за редкой уязвимости защиты. Мы считаем, что прозрачность — ключевой фактор сохранения доверия со стороны пользователей, поэтому решили рассказать об этом баге подробнее. В этом посте мы изложим технические детали данной уязвимости и объясним, как она возникла, как мы на неё отреагировали и какие мы предприняли шаги для того, чтобы подобное не повторилось.
Отчёты пользователей
2 марта 2021 через службу технической поддержки мы получили отчёт пользователя, который войдя на GitHub.com под собственными идентификационными данными, внезапно авторизировался как другой пользователь. Он немедленно вышел из аккаунта, но сообщил о проблеме нам, поскольку она обеспокоила его, и на то были все основания.
Мы привели в действие свои процедуры реагирования на инциденты с безопасностью и немедленно изучили этот отчёт, призвав на помощь специалистов компании из отделов безопасности, разработки и поддержки пользователей. Спустя несколько часов после первого отчёта мы получили второй отчёт от другого пользователя с очень похожей ситуацией. После анализа логов запросов и аудита мы смогли подтвердить истинность полученных внешних отчётов — сессия пользователя действительно внезапно оказалась общей для двух IP-адресов примерно во время отправления отчётов.
Исследование недавних изменений в инфраструктуре
Учитывая то, что этот баг был новым поведением, мы сразу же заподозрили, что он связан с недавним изменением в нашей инфраструктуре, и начали поиск решения с анализа изменений. Недавно мы обновили компоненты на уровне системы, занимающемся балансировкой нагрузки и маршрутизацией. Мы выяснили, что устранили проблему с keepalive-сообщениями HTTP, которая, по нашему мнению, могла быть связана с указанной в отчётах проблемой.
После исследования этих изменений мы выяснили, что первопричиной были не они. Запросы пользователей, которые отправили нам отчёты, на уровне балансировки нагрузки следовали по совершенно другому пути, задействуя другие машины. Мы исключили возможность того, что ответы заменялись на этом уровне. Исключив из возможных первопричин недавние инфраструктурные изменения и будучи уверенными, что проблема присутствует не в слоях связи и протоколов, мы перешли к другим потенциальным причинам.
Исследование недавних изменений в коде
Благодаря тому, что мы начали расследование с недавних изменений в инфраструктуре, нам удалось выяснить, что запросы, приводившие к возврату неправильной сессии, обрабатывались на одной и той же машине и в одном процессе. Мы используем многопроцессную схему с веб-сервером Unicorn Rack, выполняющим наше основное Rails-приложение. обрабатывающее такие задачи, как отображение issues и пул-реквестов.
После изучения логов мы выяснили, что тело HTTP-объекта в передаваемом нами ответе клиенту было правильным, ошибочным были только куки в ответе пользователю. Отправившие отчёты об ошибке пользователи получили куки сессии пользователя, запрос которого совсем незадолго до них обрабатывался внутри того же процесса. В одном из случаев два запроса обрабатывались последовательно, один за другим. Во втором случае между ними было ещё два запроса.
У нас появилась рабочая теория о том, что нечто каким-то образом приводило к утечке состояния между запросами, которые обрабатывались в одном процессе Ruby. Нам нужно было выяснить, как такое может происходить.
Исследовав недавно внедрённые функции, мы выявили потенциальную проблему с безопасностью потоков, которая могла возникать из-за функциональности с недавно изменённой ради повышения производительности архитектурой. Одно из таких улучшений производительности заключалось в переносе логики включенных для пользователя функций в фоновый поток, который обновлялся с определённым интервалом вместо проверки их состояния во время обработки запроса. Нам показалось, что это изменение затронуло изучаемые нами области и теперь основной целью нашего исследования стало неопределённое поведение этой проблемы с безопасностью потоков.
Безопасность потоков и отчёты об ошибках
Для понимания проблемы с безопасностью потоков необходим контекст. Основное приложение, обрабатывающее большинство браузерных взаимодействий на GitHub.com — это приложение Ruby on Rails, известное тем, что оно имело компоненты, написанные без учёта возможности в нескольких потоках (т.е. они были непотокобезопасны). Обычно в прошлом непотокобезопасное поведение могло приводить к неправильному значению во внутренних отчётах об исключениях системы, но при этом пользователи не сталкивались с изменением поведения системы.
Потоки уже использовались в других частях этого приложения, однако новый фоновый поток создал новое и непредусмотренное взаимодействие с нашими процедурами обработки исключений. Когда исключения (например, истечение срока запроса) передавал фоновый поток, лог ошибок содержал информацию и от фонового потока, и от текущего выполняемого запроса, и это доказывало, что данные передаются между потоками.
Изначально мы думали, что это только внутренняя проблема отчётности, и что мы будем наблюдать в логах данные, зафиксированные от не относящегося к делу запроса в фоновом потоке. Несмотря на противоречивость, мы посчитали такое поведение безопасным, поскольку каждый запрос имел собственные данные запроса, а Rails-приложение создавало новый экземпляр объекта-контроллера для каждого запроса. Нам по-прежнему было непонятно, как это могло вызывать проблемы, с которыми мы столкнулись.
Многократно используемый объект
Наша команда совершила прорыв, обнаружив, что HTTP-сервер Unicorn Rack, используемый в нашем Rails-приложении, не создаёт новый и отдельный объект
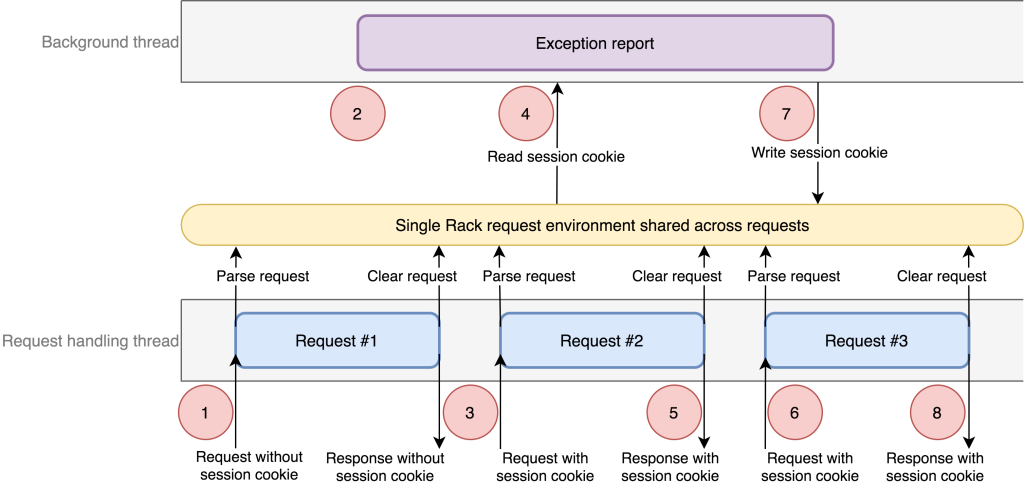
env для каждого запроса. Вместо этого он выделяет единственный Ruby Hash, который очищается (с помощью Hash#clear) между запросами, которые он обрабатывает. Благодаря этому мы поняли, что проблема с потокобезопасностью в логгинге исключений может привести не только к неправильности фиксируемых в исключениях данных, но и к передаче данных запросов на GitHub.com.Первоначальный анализ привёл к созданию гипотезы о том, что для возникновения условия гонки необходимо два запроса, происходящих за короткий промежуток времени. Получив эту информацию, мы попытались воспроизвести проблему в среде разработки. Когда мы попробовали выполнить последовательность определённых запросов, то обнаружили, что требуется ещё одно дополнительное условие, а именно анонимный запрос, с которого начинается вся последовательность. Вот полный список необходимых шагов:
- В потоке обработки запросов запускается анонимный запрос (назовём его Request #1). Он регистрирует обратный вызов в текущем контексте для внутренней библиотеки отчётности об исключениях. Обратные вызовы содержат ссылки на текущий объект контроллера Rails, имеющий доступ к единому объекту среды запроса Rack, предоставляемого сервером Unicorn.
- В фоновом потоке возникает исключение. Сообщение об исключении копирует текущий контекст, чтобы включить его в отчёт. Этот контекст содержит обратные вызовы, зарегистрированные запросом Request #1, в том числе и ссылку на единую среду Rack.
- В основном потоке запускается новый запрос залогиненного пользователя (Request #2).
- В фоновом потоке система отчётности об исключениях обрабатывает обратные вызовы контекста. Один из обратных вызовов считывает идентификатор сессии пользователя, но поскольку запрос на момент контекста не имеет авторизации, эти данные ещё не считываются, и, следовательно, запускают новый вызов к системе авторизации через контроллер Rails из запроса Request #1. Этот контроллер пытается выполнить авторизацию и получает куки сессии из общей среды Rack. Так как среда Rack — это общий объект для всех запросов, контроллер находит куки сессии запроса Request #2.
- В основном потоке запрос Request #2 завершается.
- Запускается ещё один запрос залогиненного пользователя (Request #3). В этот момент Request #3 завершает свой этап авторизации.
- В фоновом потоке контроллер завершает этап авторизации, записывая куки сессии в cookie jar, находящийся в среде Rack. На данном этапе это cookie jar для Request #3!
- Пользователь получает ответ на запрос Request #3. Но cookie jar был обновлён данными куки сессии Request #2, то есть пользователь теперь авторизован как пользователь из Request #2.
Подведём итог: если исключение возникло именно в нужный момент и если параллельная обработка запросов происходит именно в нужном порядке среди серии запросов, то в результате сессия одного запроса заменяется сессией более раннего запроса. Возврат неправильного куки происходит только для заголовка куки сессии, и, как говорилось выше, остальная часть тела ответа, например HTML, по-прежнему была связана с ранее авторизованным пользователем. Это поведение соответствовало с тем, что мы видели в логах запросов и мы смогли чётко идентифицировать все элементы, составлявшие первопричину состояния гонки.
Для возникновения этого бага требовались очень конкретные условия: фоновый поток, общий контекст исключения между основным потоком и фоновым потоком, обратные вызовы в контексте исключения, многократное использование объекта env между запросами и наша система авторизации. Подобная сложность является напоминанием о многих из пунктов, представленных в статье How Complex Systems Fail, и демонстрирует, что для возникновения подобного бага требуется множество различных сбоев.
Предпринимаем действия
Выявив первопричину, мы немедленно сделали основным приоритетом устранение двух условий, критически важных для появления этого бага. Во-первых, мы избавились от нового фонового потока, появившегося после вышеупомянутой модернизации архитектуры, призванной повысить производительность. Благодаря тому, что мы точно знали, что было добавлено в процессе этой работы, изменения легко можно было откатить. Изменение, в котором был удалён этот поток, вывели в продакшен 5 марта. После этого изменения мы знали, что условия, требуемые для возникновения условия гонки, больше не будут удовлетворяться, и что наша непосредственный риск возврата неверных сессий снижен.
После выпуска изменения с удалением фонового потока, мы создали патч для Unicorn, удаляющий возможность создания общей среды. Этот патч был выпущен 8 марта и ещё больше усилил изоляцию между запросами, даже на случай возникновения проблем с потокобезопасностью.
Кроме устранения бага мы предприняли действия для определения пользовательских сессий, на которые он повлиял. Мы изучили данные логгинга на предмет паттернов, соответствующих неправильно возвращаемых сессий. Затем мы вручную просмотрели соответствующие паттерну логи, чтобы определить, на самом ли деле сессия была неверно возвращена от одного пользователя другому.
В конце мы решили сделать ещё одно превентивное действие, чтобы гарантировать безопасность данных наших пользователей, и аннулировали все активные сессии пользователей на GitHub.com. Учитывая редкость условий, необходимых для возникновения этого условия гонки, мы знали, что вероятность возникновения бага очень мала. Хотя наш анализ логов, проведённый с 5 по 8 марта, подтвердил, что это была редкая проблема, мы не могли исключить вероятность того, что сессия была неверно возвращена, но никогда не использовалась. Мы не хотели идти на такой риск, учитывая потенциальный ущерб использования даже одной из таких неверно возвращённых сессий.
Реализовав эти два исправления и завершив аннулирование сессий, мы были уверены в том, что больше не может возникнуть новых случаев возврата неправильных сессий, и что влияние бага было снижено.
Продолжаем работу
Несмотря на устранение непосредственной угрозы, мы объединили усилия с мейнтейнером Unicorn, чтобы поднять изменения вверх по потоку и чтобы новые запросы выделяли собственные хэши среды. Если Unicorn будет использовать новые хэши для каждой среды, то это устранить возможность того, что один запрос ошибочно завладеет объектом, который может повлиять на следующий запрос. Это дополнительная защита, позволяющая предотвратить превращение подобных багов потокобезопасности в уязвимости защиты для других пользователей Unicorn. Хотим искренне поблагодарить мейнтейнеров Unicorn за сотрудничество и обсуждение данной проблемы.
Ещё одним предпринятым шагом стало устранение обратных вызовов из контекста логгинга исключений. Эти обратные вызовы были полезны для откладывания времени выполнения и избегания снижения производительности без необходимости. Их недостаток заключается в том, что обратный вызов также усложняет отладку условий гонки и потенциально может сохранять ссылки на уже давно завершённые запросы. Обработка исключений при помощи более простого кода позволяет нам сейчас и в будущем использовать эти процедуры более безопасным способом. Кроме того, мы работаем над упрощением и ограничением путей выполнения кода в частях, где выполняется обработка куки сессий.
Также мы хотим повысить потокобезопасность всей кодовой базы в таких областях, как обработка исключений и оснащение. Мы не хотим просто устранять конкретные баги, а стремимся обеспечить невозможность возникновения подобного класса проблем в будущем.
Подведём итог
Многопоточный код бывает очень сложен в анализе и отладке, особенно в тех кодовых базах, где потоки в прошлом использовались редко. Пока мы решили перестать использовать долгоживущие потоки в наших процессах Rails. Мы воспользуемся этой возможностью, чтобы сделать наш код более надёжным для различных многопотоковых контекстов, а также для обеспечения дополнительной защиты и создания потокобезопасной архитектуры для использования в будущем.
Если взглянуть со стороны, то данный баг не только оказался сложным с технической точки зрения (ведь для его возникновения требуются сложные взаимодействия между несколькими потоками, отложенными обратными вызовами и совместным использованием объектов), но и стал проверкой способности нашей организации реагировать на проблему с неизвестной причиной и уровнем угрозы. Отлаженная работа команды реагирования на инциденты с безопасностью совместно со специалистами из отделов поддержки, безопасности и разработки позволила нам быстро исследовать, оценить и квалифицировать потенциальную опасность этой проблемы, а также повысить приоритет её решения во всей компании. Это повышение приоритета ускорило работу над анализом логов, изучением последних изменений в коде и архитектуре, а в конечном итоге позволило выявить глубинные проблемы, которые привели к возникновению этого бага.
Благодаря чёткому пониманию проблемы мы смогли сосредоточиться на принятии нужных мер для ограничения её воздействия на пользователей. Полученные нами в процессе этой работы знания позволили нам обсудить ситуацию с ответственными лицами из разных отделов компании и принять конфиденциальное решение о необходимости выхода из системы всех пользователей GitHub.com. Мы лучше разобрались в «сложных системах» компании и воспользуемся этой возможностью для создания мер предосторожности, предотвращающих возникновение подобных проблем в будущем.
