[Перевод] Как мы решаем проблему неинициализированной стековой памяти в Windows
В этой заметке я расскажу в общих чертах о том, как в Microsoft устраняют уязвимости, связанные с неинициализированной стековой памятью, и почему мы вообще этим занимаемся.
Для удобства навигации заметка разбита на разделы:
- Работа с неинициализированной памятью: история проблемы
- Способы устранения уязвимостей, связанных с неинициализированной памятью
- InitAll — автоматическая инициализация
- Интересные наблюдения, связанные с применением InitAll
- Оптимизации производительности
- Значение для пользователей
- Планы на будущее
Эта работа была бы невозможной без тесного сотрудничества между подразделениями Visual Studio, Windows и MSRC.
Работа с неинициализированной памятью: история проблемы
При создании языков программирования C и C++ упор делался на высокую скорость работы и гибкий контроль со стороны разработчика. По этой причине в этих языках не применяется принудительная инициализация переменных. Работа с неинициализированными переменными ведёт к неопределённому поведению, поэтому они должны быть инициализированы перед использованием, и ответственность за соблюдение этого правила целиком лежит на разработчике.
Уязвимости, связанные с неинициализированной памятью, сводятся к двум типам:
- Раскрытие содержимого: данные, хранящиеся в неинициализированных участках памяти, копируются за пределы доверенной области и становятся известны лицам, не имеющим соответствующих полномочий.
- Непосредственное использование неинициализированной памяти. Пример: запись по неинициализированному указателю.
Важно понимать, что проблемы могут появиться независимо от того, выделяется память на стеке или в куче. Эта заметка посвящена стековой памяти, а в следующей поговорим о куче.
Пример использования неинициализированной памяти
int size;
GetSize(&size); // что если эта функция забудет задать размер?
memcpy(dest, src, size); // в memcpy передаётся
// неинициализированный размер
Проблема здесь в том, что если функция GetSize не присвоит значение переменной 'size' во всех ветках программы, то в вызов memcpy будет передан неинициализированный размер. Из-за этого может возникнуть ошибка чтения или записи за пределами буфера, если значение 'size' окажется больше, чем размер буфера 'src' или 'dest'.
Пример раскрытия содержимого неинициализированной памяти
struct mystruct {
uint8_t field1;
uint64_t field2;
};
mystruct s {1, 5};
memcpy(dest, &s, sizeof(s));
Допустим, что функция memcpy копирует структуру за пределы доверенной области (т.е. из режима ядра в режим пользователя). На первый взгляд кажется, что структура инициализирована полностью, однако между 'field1' и 'field2' компилятор вставил байты-заполнители, которые не были инициализированы явным образом.
В результате вызова memcpy байты-заполнители будут скопированы за пределы доверенной области вместе со своим неинициализированным содержимым, записанным ранее по этим виртуальным адресам. Им может оказаться, например, кусок секретного ключа шифрования (который станет виден в пользовательском режиме), указатель (из-за чего сломается ASLR) или что-нибудь ещё. В одних случаях можно легко доказать, что никакие особенно критические данные не передаются, в других это будет очень непросто. Но в любом случае выяснять, насколько серьёзна проблема с неинициализированной памятью, — неблагодарный труд, и мы охотно занялись бы чем-нибудь другим.
Статистика по ошибкам, связанным с неинициализированной памятью
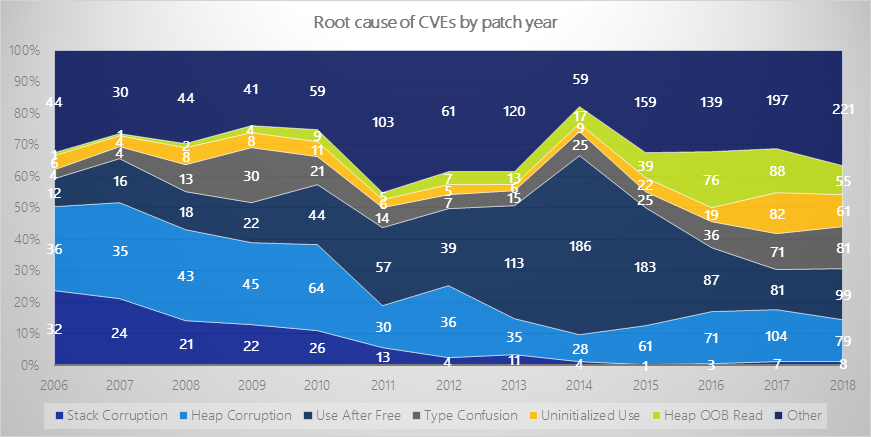
Примечание: на этом рисунке под использованием неинициализированной памяти понимаются оба типа проблем: непосредственное использование и раскрытие содержимого.
В последние годы число таких ошибок растёт. Вероятно, отчасти это объясняется ростом интереса к ним со стороны исследователей и, как следствие, появлением эффективных инструментов для их поиска.
Более подробная классификация этих ошибок выявляет ещё несколько интересных тенденций.
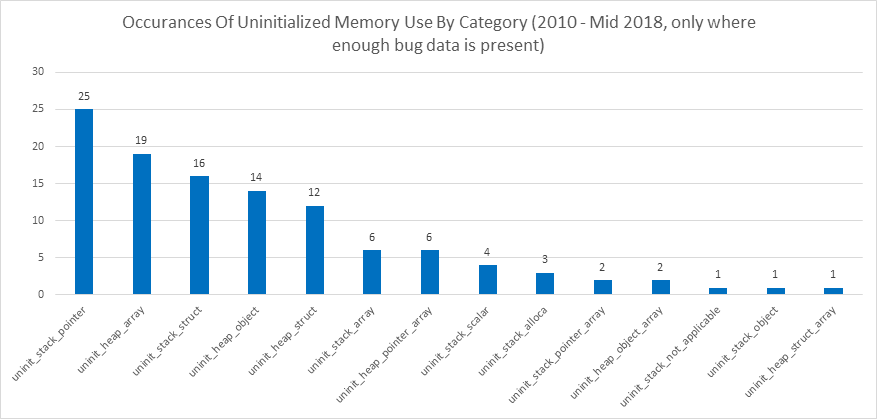
Примечание: на этой диаграмме использование неинициализированной памяти НЕ включает в себя раскрытие её содержимого.
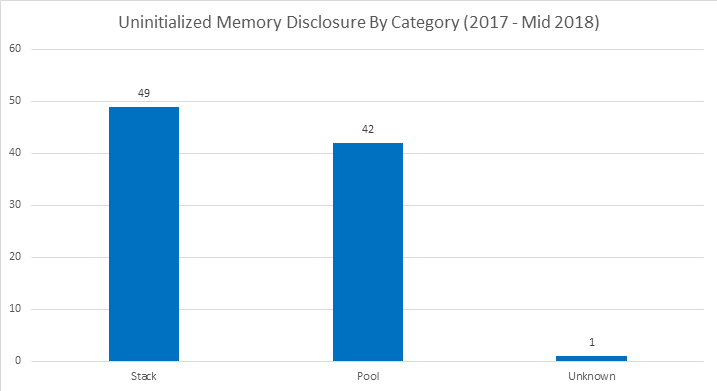
Глядя на эти диаграммы, можно сделать следующие выводы:
- Между 2017 и 2018 годами уязвимости, связанные с неинициализированной памятью, составили примерно 5–10% всех уязвимостей в отчётах Microsoft.
- Уязвимостей, связанных с выделением памяти на стеке, и уязвимостей, связанных с выделением памяти в куче/пуле, оказалось почти поровну.
- Случаев раскрытия содержимого неинициализированной памяти больше, чем случаев использования неинициализированной памяти.
Дополнительная литература
Для более полного ознакомления с темой см. следующие ресурсы:
Способы устранения уязвимостей, связанных с неинициализированной памятью
Описанные проблемы пытались решить несколькими способами.
- Статический анализ (как во время компиляции, так и после)
- Фаззинг
- Обзор кода
- Автоматическая инициализация
Статический анализ
В Microsoft используются многочисленные предупреждения статического анализатора для отлова неинициализированных переменных (в том числе C4700, C4701, C4703, C6001, C26494 и C26495). Эти диагностики консервативны, т.е. в целях снижения шума они игнорируют некоторые паттерны, которые могут привести к работе с неинициализированной памятью.
Также был написан ряд жёстких правил для статического анализатора Semmle, которые прогоняются на некоторых кодовых базах Windows. Но эти диагностики дают много шума и ими тяжело проверять большие объёмы кода. К тому же соблюдение этих правил и исправление ошибок весьма трудоёмко. В итоге оказалось, что применять их затруднительно и дорого.
Фаззинг
Фаззинг, как известно, плохо поддаётся масштабированию. Хорошие фаззеры затратны в сопровождении и требуют настройки под конкретные задачи. С кодовой базой таких размеров, как у Microsoft, весьма непросто обеспечить полное её покрытие фаззингом.
Даже если бы удалось идеально покрыть ими весь код, фаззеры не умеют обнаруживать раскрытие содержимого неинициализированной памяти, так как оно не приводит к падению программы. Чтобы обнаруживать такие дефекты с помощью фаззинга, требуется одно из двух решений:
- Фаззер, который понимает протокол и способен обнаруживать возврат в него неинициализированной памяти (а точнее, непредвиденных данных).
- Динамический анализатор, способный обнаруживать доступ к неинициализированной памяти.
Обзор кода
Обзор кода не масштабируется и чрезвычайно подвержен ошибкам. Код с уязвимостями проходит обзор, однако они настолько хорошо замаскированы, что программисты их не замечают.
Часть кода, в которой мы столкнулись с раскрытием содержимого неинициализированной памяти, была написана ещё во времена 32-битной Windows, и этих ошибок тогда не было. Когда же произошёл переход на 64-битные архитектуры, размер указателей вырос с 32 до 64 бит, из-за чего у некоторых структур появились неинициализированные поля-заполнители.
InitAll — Автоматическая инициализация
Помимо упомянутых подходов, Microsoft с некоторых пор использует механизм под названием InitAll — он автоматически инициализирует стековые переменные на этапе компиляции.
В этом разделе я расскажу, как данная технология применяется в Windows и почему именно таким образом.
Текущие настройки Windows:
Автоматически инициализируются следующие типы:
- Скалярные (массивы, указатели, числа с плавающей запятой)
- Массивы указателей
- Структуры (простые структуры данных — POD)
Автоматической инициализации не подвергаются следующие типы:
- volatile-переменные
- Массивы других типов, кроме указателей (т.е. массивы целых, массивы структур и т.д.)
- Классы, которые не являются POD
В оптимизированных розничных (retail) сборках переменные инициализируются значением 0. Для чисел с плавающей запятой используется значение 0.0.
В отладочных (CHK) сборках или сборках для разработчиков (т.е. неоптимизированных розничных) используется значение 0xE2; числа с плавающей запятой инициализируются значением 1.0.
InitAll применяется к следующим компонентам:
- Весь код из репозитория Windows, исполняющийся в режиме ядра (т.е. весь код, компилирующийся с ключом /KERNEL)
- Весь код, относящийся к технологии Hyper-V (гипервизор, компоненты режима ядра, компоненты пользовательского режима)
- Ряд других проектов, например сетевые службы пользовательского режима
InitAll реализован на стороне фронтэнда компилятора. Все переменные, отвечающие перечисленным выше критериям и не инициализированные программистом, будут инициализированы фронтэндом при объявлении. Один из плюсов этого подхода — в том, что с точки зрения оптимизатора, автоматическая инициализация ничем не отличается от инициализации разработчиком. Из этого следует, что оптимизации, которые мы добавляем для ускорения работы с InitAll, не привязаны только к этой функции и будут работать и в тех случаях, когда вы сами инициализируете переменные при объявлении (или перед использованием).
Как мы избегаем проблемы «разветвления языка»
С автоматической инициализацией нулём есть одна загвоздка: ноль — это особое значение в языке программирования, особенно для указателей. А ещё это, пожалуй, самое распространённое значение, которым инициализируются отдельные переменные.
При инициализации нулём указатель, который не был корректно инициализирован программистом, может попасть в ветку NULL pointer. В результате вы можете получить программу, которая не падает, но и не выдаёт нужные результаты. Если же инициализировать указатель мусорным значением, он не попадёт в ветку NULL pointer и при попытке использовать его приведёт к падению программы.
Эту проблему мы решаем использованием ненулевого значения инициализации (0xE2) в CHK-сборках и так называемых сборках для разработчиков, которые зачастую представляют собой неоптимизированные релизные сборки. За счёт этого, с одной стороны, удаётся сохранить высокую производительность кода, поставляемого клиентам, а с другой — получить в сборках, находящихся на тестировании, такое поведение, при котором легче заметить пропущенные инициализации.
Замечу, что C++ и так требует автоматической инициализации нулём всех статических членов. Эта семантика помогает разработчикам. Например, увидев статическую переменную с нулевым значением, вы будете знать, что необходимо инициализировать её, так как это первое её использование. InitAll вводит похожую семантику для автоматических (стековых) переменных с одной важной оговоркой: мы стараемся не привязывать разработчиков к конкретным начальным значениям.
Как мы выбираем, для каких компонентов задействовать InitAll
Изначально InitAll планировали использовать на двух компонентах:
- Код режима ядра — прежде всего из-за большого числа наблюдаемых уязвимостей, связанных с неинициализированной памятью ядра.
- Код Hyper-V — прежде всего из-за его важности для Azure и из-за неутешительной свежей статистики по случаям раскрытия содержимого неинициализированной стековой памяти.
Кое-кто в Microsoft узнал о InitAll и начал активно применять его на своих компонентах.
Причина, по которой мы не развёртываем InitAll сразу на всём коде, заключается в том, что мы хотим сначала сделать хорошо хоть что-то, а не потерпеть неудачу, пытаясь сделать всё сразу. Чем больше кода мы обрабатываем InitAll за раз, тем труднее отлаживать падения производительности, решать проблемы совместимости и т.д. Теперь, когда мы успешно развернули технологию на самых важных компонентах, можно заняться остальным кодом.
Ломает ли InitAll статический анализ?
Статический анализ чрезвычайно полезен тем, что напоминает разработчикам о переменных, которые они забыли инициализировать перед использованием.
InitAll уведомляет как анализатор PREfast, так и бэкэнд компилятора (оба выдают предупреждения о неинициализированных переменных) о добавленных им инициализациях. Благодаря этому статические анализаторы могут игнорировать такие места и по-прежнему выдавать свои предупреждения. При включённом InitAll вы всё равно будете получать сообщения статического анализатора о неинициализированных переменных — даже если InitAll инициализировал их за вас.
Почему мы инициализируем не все типы
Во время предварительных тестов мы принудительно инициализировали все типы данных, выделяемых на стеке, и наблюдали падения производительности более чем на 10% в нескольких важных сценариях.
Если инициализировать только POD-структуры, производительность падала не так сильно, а оптимизации компилятора, направленные на сокращение числа лишних операций записи (как внутри базовых блоков, так и между ними), позволили дополнительно снизить замедление со сколько-нибудь заметного уровня до уровня погрешности в большинстве тестов.
Мы планируем вернуться к идее инициализации всех типов (особенно теперь, когда у нас появились более мощные оптимизации), просто ещё не дошли до этого.
Почему мы инициализируем переменные нулём
Инициализация нулём даёт наилучшие результаты с точки зрения производительности (как по скорости работы, так и по размеру двоичного кода), а также с точки зрения безопасности.
С позиции безопасности
Инициализация нулём имеет следующие преимущества:
- Нулевой указатель будет выбрасывать SEH-исключение при разыменовывании под Windows (т.е. в худшем случае это грозит ошибкой denial-of-service, но удалённое исполнение кода будет невозможно), что обычно заканчивается падением программы.
- Переменная, задающая размер или индекс, получит нулевое значение. Это должно свести к минимуму риск при передаче неинициализированного размера функциям вроде memcpy, работающим с буфером, чей размер задаётся значением переданной переменной.
- После проверки нулевого указателя программа исполнит соответствующую ветку и не будет пытаться использовать его. Так, по крайней мере, удастся корректно обработать указатели, которые разработчик забыл инициализировать (поскольку попытка обратиться к памяти по автоматически инициализированному указателю будет всегда приводить к падению).
- Переменные булева типа со значением 0 означают «ложь», что в проверках может обозначать состояние ошибки.
У инициализации нулём также есть пара недостатков:
- Переменная NTSTATUS будет иметь значение STATUS_SUCCESS
- Переменная HRESULT будет иметь значение S_OK
Но возвращаемые значения могут быть самыми разными, и не существует единого универсального значения, которым можно было бы инициализировать их все, особенно учитывая, что его же надо использовать для размеров, индексов, указателей и т.д.
С позиции производительности
От выбранного значения инициализации также зависят скорость работы программы и размер кода. Мы не измеряли, насколько хуже результаты при использовании ненулевого значения, так как нас в первую очередь интересовали преимущества в безопасности, которые даёт инициализация нулём, и мы знали, что заодно она положительно скажется на производительности (как скорости работы, так и размере кода). Наши коллеги из Google провели измерения и показали, что на Clang инициализация нулём на данный момент заметно выгоднее, чем инициализация ненулевым значением.
Ниже я на примерах покажу, почему при инициализации нулём получается меньше кода.
Пример 1: Инициализация с использованием регистров общего назначения
Инициализация нулём:
31 c0 xor eax,eax
48 89 01 mov QWORD PTR [rcx],rax
Инициализация ненулевым значением:
48 b8 e2 e2 e2 e2 e2 e2 e2 e2 movabs rax,0xe2e2e2e2e2e2e2e2
48 89 01 mov QWORD PTR [rcx],rax
В этом примере нас интересуют два момента:
Во-первых, установка регистра RAX в ноль занимает 2 байта кода против 10 байт при установке в ненулевое значение. Получается выигрыш как по размеру кода, так и по скорости работы. Многие процессоры считывают команды по 16 байт за раз, поэтому запись в регистр фиксированной константы с помощью команды размером 10 байт препятствует выдаче следующих команд, которые могли бы выполняться параллельно.
Во-вторых, прежде чем станет возможным записать значение в регистр RCX, придётся дождаться завершения записи в RAX, что может привести к простаиванию процессора. Последовательности вроде «xor eax, eax» распознаются на самых ранних участках конвейера, и реального выполнения команды XOR не требуется — процессоры просто обнуляют регистр RAX. В результате конвейер простаивает меньше времени и программа работает быстрее.
Пример 2: Инициализация с использованием XMM-регистров
Для записи более крупных значений компилятор, как правило, использует XMM-регистры (а также YMM или ZMM в зависимости от того, включена ли поддержка наборов инструкций AVX или AVX512). Как правило, за один такт процессоры могут завершить не более одной команды записи, поэтому будет разумно использовать такие команды, которые устанавливают как можно больше байт.
Инициализация нулём:
0f 57 c0 xorps xmm0,xmm0
f3 0f 7f 01 movdqu XMMWORD PTR [rcx],xmm0
Инициализация ненулевым значением (загружается из глобальной переменной, что компиляторы обычно и делают):
66 0f 6f 04 25 00 00 00 00 movdqa xmm0,XMMWORD PTR ds:0x0
f3 0f 7f 01 movdqu XMMWORD PTR [rcx],xmm0
Инициализация ненулевым значением (загружается из фиксированной константы в коде, чего компиляторы не делают):
48 ba e2 e2 e2 e2 e2 e2 e2 e2 movabs rdx,0xe2e2e2e2e2e2e2e2
66 48 0f 6e c2 movq xmm0,rdx
0f 16 c0 movlhps xmm0,xmm0
f3 0f 7f 01 movdqu XMMWORD PTR [rcx],xmm0
Как видим, в случае XMM-регистров наблюдается та же картина. При инициализации нулём код получается совсем небольшим.
Записать фиксированную константу напрямую в XMM-регистр невозможно. Придётся сначала сохранить его в регистр общего назначения, оттуда переместить в XMM-регистр, а потом скопировать младшие 64 бита XMM-регистра в его же старшие 64 бита. В результате получаем длинный код и три команды, каждая из которых должна дожидаться завершения предыдущей.
Чтобы избежать этого, компиляторы, как правило, сохраняют фиксированную константу в виде глобальной переменной, из которой могут потом считать значение, — так получается гораздо меньше кода. К сожалению, придётся дождаться окончания записи в XMM-регистр, прежде чем он станет доступен для использования. Если глобальная переменная будет выгружена из памяти, операция может занять несколько тысяч тактов. На операцию чтения уходит несколько тактов даже при самом хорошем сценарии, когда данные хранятся в кэше L1. И даже в этом случае код получается намного длиннее, чем если просто обнулить регистр.
Тут обнаруживается ещё одно преимущество инициализации нулём: более детерминированные результаты. Время инициализации не зависит от того, находится ли глобальная переменная в кэше L1, L2 или L3, выгружается ли из памяти, и т.д.
Интересные наблюдения, связанные с применением InitAll
Производительность
Windows 10 1903 (выпущена весной 2019 года) стала первой версией, в которой InitAll был включён по умолчанию. До сих пор никаких жалоб на снижение производительности из-за него мы не получали.
Совместимость
Античиты
Вскоре после включения InitAll в Windows нам стали поступать жалобы на падения ядра, вызванные некоторыми античит-программами. Изучив проблему, мы выяснили, что эти программы содержали драйверы режима ядра, которые сканировали образ ядра NT в памяти и искали определённые байтовые последовательности, указывающие на начало недокументированных функций.
InitAll добавил в начало этих функций дополнительные инициализации (избыточность которых нельзя было доказать), из-за чего их сигнатуры изменились. Мы связались с компаниями-разработчиками этих античитов, и они по нашей просьбе обновили свои драйверы, чтобы те больше не вызывали падений ядра.
Использование освобождённой памяти в FAT32
Вскоре после включения InitAll для скалярных типов данных (т.е. целых чисел, чисел с плавающей запятой и т.д.) мы столкнулись с интересной проблемой в драйвере файловой системы FAT, которая не давала обновлять внутренние сборки Windows с загрузочных USB-флешек.
Код, в котором возникла проблема, выглядел примерно так:
for(int i = 0; i < size; i++)
{
int tmp;
DoStuff(&tmp, i);
}
Имеется цикл, внутри которого объявляется переменная. На первой итерации цикла функция DoStuff инициализирует переменную 'tmp', адрес которой передаётся ей в качестве аргумента. На каждой последующей итерации переменная 'tmp' используется как входной/выходной параметр. Другими словами, её значение сначала считывается, а затем обновляется.
Проблема в том, что рассматриваемая переменная в начале каждой итерации цикла входит в его область видимости, а в конце итерации покидает её. InitAll инициализирует эту переменную нулём перед каждой итерацией. Фактически мы получаем уязвимость, связанную с использованием освобождённой памяти (use-after-free). Для нормальной работы кода требуется, чтобы переменная 'tmp' сохраняла своё значение на каждой итерации, даже если в конце итерации она выходит из области видимости. К сожалению, эта проблема приводила не к падению драйвера, а к некорректной логике его работы и, как следствие, непредсказуемому поведению файловой системы. В ходе отладки команда, занимающаяся ядром, определила причину проблемы и исправила её, вынеся объявление переменной за пределы цикла.
Этот случай — наглядный пример того, как улучшения безопасности могут сломать код, в который не заглядывали годами.
Оптимизации производительности
Оптимизации производительности, осуществляемые InitAll, преследуют три цели:
- Предоставить разработчикам возможность отключать InitAll для критического кода
- По возможности убрать лишние операции записи
- Максимально ускорить оставшиеся операции записи
Отключение InitAll для критического кода
Самые очевидные оптимизации заключаются в том, чтобы позволить коду:
- Полностью отключить InitAll
- Отключить InitAll для конкретного типа (т.е. typedef структуры)
- Отключить InitAll для всех операций выделения памяти в функции
- Отключить InitAll для конкретного объявления переменной в функции
На сегодняшний момент InitAll отключён (ради повышения производительности) для одного-единственного типа — структуры _CONTEXT, которая хранит значения всех регистров. Принудительная её инициализация приводила к снижению производительности в тестах.
Структура _CONTEXT имеет размер более 1000 байт, и этого достаточно, чтобы хранить значения всех регистров. С включённым ETW-логированием для отслеживания переключений контекста каждый раз при смене контекста значения всех регистров заносятся в лог. Структура _CONTEXT в этом случае будет выделяться на стеке, заполняться ассемблерной функцией и затем передаваться в ETW. Из-за того, что структура инициализируется ассемблерной функцией, компилятор не может убрать инициализацию, сделанную InitAll. Поскольку эта структура и так содержит критические данные (состояние каждого регистра), имеет большой размер и используется в чрезвычайно требовательных к производительности ветках, мы решили не применять к ней InitAll.
Для всех остальных типов, переменных и функций InitAll не отключалась.
Удаление лишних операций записи
Удаление лишних операций записи — это оптимизация, выполняемая компилятором Visual Studio, при которой убираются такие операции записи, избыточность которых может быть доказана.
Ниже приводятся примеры разных видов оптимизации, применяемых Visual Studio.
Удаление нескольких memset
Ссылка на Godbolt: https://msvc.godbolt.org/z/Ldu7AP
Следующий паттерн кода (с разными вариациями) чрезвычайно распространён. Первоначальные правила программирования под NT требуют, чтобы все переменные объявлялись в начале функции, а инициализировались как можно позже. В результате мы имеем случаи, когда переменная объявляется в начале функции, а инициализируется только в какой-нибудь одной ветке непосредственно перед использованием.
InitAll добавляет свою инициализацию переменной в начале функции. Компилятор может удалить дубликат, но это не всегда легко сделать.
#include
#include
struct MyStruct
{
int array[160];
};
void Dummy()
{
printf("dummy");
return;
}
void DoStuff(MyStruct* s)
{
printf("hi", (int*)&s); // Передаём указатель "s"
// в сложную функцию,
// чтобы компилятор не cмог полностью
// убрать все операции записи в "s"
return;
}
volatile bool b = true;
void f()
{
MyStruct s;
// Этот вызов memset, по сути, идентичен вызову memset, добавленному InitAll
memset(&s, 0x0, sizeof(s));
if (b) // Проверяем volatile-переменную,
// чтобы не дать компилятору убрать эту ветку
// (что он сделал бы, если бы мы написали обычную переменную)
{
Dummy();
memset(&s, 0x1, sizeof(s));
DoStuff(&s);
}
return;
} 
Кажется, что этот простой пример должен легко оптимизироваться, однако GCC 9.3 и Clang 10.0.0 (самые свежие версии, доступные на Godbolt) неспособны в этом случае убрать лишний вызов memset. Я говорю об этом не для того, чтобы покритиковать эти компиляторы, — они оба очень хорошо оптимизируют код. Я просто хочу показать, что некоторые паттерны могут вызвать трудности даже у самых мощных компиляторов. До появления InitAll и связанных с ним оптимизаций Visual Studio не мог убрать лишний вызов.
Ещё более простой пример:
Между двумя вызовами memset находится всего один вызов функции без аргументов. Этот паттерн, как и предыдущий, очень часто встречается в коде Microsoft.
Ссылка на Godbolt: https://msvc.godbolt.org/z/HqFMx_
#include
#include
struct MyStruct
{
int array[160];
};
void Dummy()
{
printf("dummy");
return;
}
void DoStuff(MyStruct* s)
{
printf("hi", (int*)&s); // Передаём указатель "s"
// в сложную функцию,
// чтобы компилятор не cмог полностью
// убрать все операции записи в "s"
return;
}
void f()
{
MyStruct s;
// Этот вызов memset, по сути, идентичен вызову memset, добавленному InitAll
memset(&s, 0x0, sizeof(s));
Dummy();
memset(&s, 0x1, sizeof(s));
DoStuff(&s);
return;
} 
MSVC убирает лишний memset в этом примере. Clang 10.0.0 — тоже, а вот у GCC 9.3 по-прежнему не получается. Казалось бы, этот код можно легко оптимизировать, однако для этого компилятору приходится проводить нетривиальный анализ.
Проблема здесь (в MSVC) в том, что компилятор применяет анализ достижимости объекта, не зависящий от ветвления или потока исполнения. С точки зрения компилятора, переменная 's' «убегает» из текущей функции (другими словами, её адрес передаётся куда-то за пределы этой функции), так как её адрес передаётся в функцию 'DoStuff'. Компилятор также видит вызов memset 's', затем — вызов 'Dummy', после чего — ещё один вызов memset 's'.
С точки зрения компилятора, поскольку переменная 's' «убежала» из функции, функция 'Dummy' теоретически может считывать содержимое 's' или изменять его до вызова функции 'DoStuff'. А значит, вызов memset ни до, ни после 'Dummy' не может быть удалён.
Мы-то видим, что, хотя переменная 's' и «убегает» из текущей функции, происходит это не раньше, чем вызывается функция 'DoStuff'. Компилятор MSVC теперь тоже понимает это (в той или иной степени) и может убрать первый вызов memset.
Уменьшение размера memset
Ссылка на Godbolt: https://msvc.godbolt.org/z/fyLVUF
Следующий паттерн тоже нередок. Структура частично инициализируется, а затем передаётся другой функции. Вероятно, эта вторая функция инициализирует остальные данные структуры (или по крайней мере не считывает их), однако доказать это компилятор не может.
#include
#include
struct MyStruct
{
int array[320];
};
void Dummy()
{
printf("dummy");
return;
}
void DoStuff(MyStruct* s)
{
printf("hi", (int*)&s); // Передаём указатель "s"
// в сложную функцию,
// чтобы компилятор не cмог полностью
// убрать все операции записи в "s"
return;
}
volatile bool b = true;
void f()
{
MyStruct s;
// Этот вызов memset, по сути, идентичен вызову memset, добавленному InitAll
memset(&s, 0x0, sizeof(s));
if (b) // Проверяем volatile-переменную,
// чтобы не дать компилятору убрать эту ветку
// (что он сделал бы, если бы мы написали обычную переменную)
{
Dummy();
memset(&s, 0x0, sizeof(s)-0x160);
DoStuff(&s);
}
return;
} 
MSVC теперь может урезать размер первой memset, чтобы она инициализировала только те элементы в структуре, которые не инициализирует вторая memset. И снова GCC 9.3 и Clang 10.0.0 пока что не умеют проводить такую оптимизацию в этом примере.
Более эффективная развёртка memset
Ссылка на Godbolt: https://msvc.godbolt.org/z/ZSuY_j
В следующем примере вызов memset нельзя убрать. Значит, его следует выполнить как можно эффективнее.
#include
#include
struct MyStruct
{
int array[12];
};
void DoStuff(MyStruct* s)
{
printf("hi", (int*)&s); // Передаём указатель "s"
// в сложную функцию,
// чтобы компилятор не cмог полностью
// убрать все операции записи в "s"
return;
}
void f()
{
MyStruct s;
memset(&s, 0x0, sizeof(s));
DoStuff(&s);
return;
} 
MSVC (как и большинство компиляторов) может «разворачивать» небольшие вызовы memset со статически определяемым размером и значением заполнения. То есть вызов memset заменяется последовательностью команд записи непосредственно в память. Благодаря этой оптимизации время выполнения небольших вызовов memset (до 128 байт) сокращается до одной четверти от обычного при меньшем объёме кода (нет необходимости сохранять значения регистров в стек, вызывать memset, а затем восстанавливать состояние регистров).
Раньше MSVC разворачивал memset на AMD64, используя регистры общего назначения. Теперь он использует векторные регистры, что позволяет разворачивать вызовы вдвое большего размера. В результате мы получаем более быстрые memset и не даём коду разрастаться.
Более производительные реализации memset
Этот пункт мы подробно разберём в другой раз.
Значение для пользователей
С тех пор как мы выпустили InitAll, многие из уязвимостей, о которых пользователи сообщали в MSRC, перестали воспроизводиться на свежих версиях Windows. Благодаря InitAll эти уязвимости из «проблем безопасности» превратились в «дефекты кода, на данный момент не имеющие негативных последствий». А значит, нам больше не нужно поставлять обновления безопасности для уже выпущенных операционных систем с установленным InitAll, что избавляет пользователей от головной боли, сопровождающей установку патчей, а Microsoft — от головной боли, сопровождающей их разработку.
У себя в активных ветках репозитория мы по-прежнему улучшаем код и исправляем ошибки, а также вносим правки в уже выпущенные операционные системы, в которых InitAll отсутствует и которые поэтому по-прежнему уязвимы. Со временем версии без InitAll перестанут поддерживаться. Когда это произойдёт, ошибки, нейтрализованные с помощью InitAll, будут правиться только в активных ветках разработки, а на текущих системах этот тип дефектов больше не придётся исправлять.
Планы на будущее
На данный момент мы планируем заняться двумя главными задачами в контексте проблем с неинициализированными стековыми переменными:
- Изучить и использовать возможность применения InitAll ко всем типам выделяемых данных (т.е. массивам всех типов и всем классам, а не только POD)
- Развернуть InitAll на всём коде Windows.
В дальнейшем мы планируем выяснить, возможно ли стандартизировать процесс устранения описанных типов проблем в языке C и C++. Необязательно по умолчанию оставлять переменные неинициализированными ради производительности (особенно если компилятор умеет хорошо оптимизировать избыточные операции записи). Вместо этого было бы лучше требовать от разработчика инициализировать переменные перед использованием, «если такая необходимость доказана», и позволять нарушать это правило, только если применяется специальное ключевое слово для неинициализированных переменных. Такое решение позволило бы сохранить высокую производительность и при этом уберечь программистов от лишних ошибок.
Мы планируем опубликовать ещё одну заметку о текущей работе по нейтрализации уязвимостей, связанных с неинициализированной памятью, в механизме выделения пула памяти в ядре Windows.
Комментарий переводчика
Статья почти не связана с моей родной тематикой статического анализа кода, но мне она показалась интересной и я захотел поделиться переводом с русскоязычной аудиторией. От себя хочу добавить, что проблемы безопасности, связанные с «утечкой» приватных данных, обычно складываются из двух составляющих. Первое: есть место, где приватные данные должны затираться, но этого не происходит (V597). Второе: неочищенные приватные данные как часть неинициализированной памяти, могут быть куда-то переданы (пример).
