[Перевод] Как GPU-вычисления буквально спасли меня на работе. Пример на Python
Привет, Хабр!
Сегодня мы затрагиваем актуальнейшую тему — Python для работы с GPU. Автор рассматривает пример, тривиальный в своей монструозности, и демонстрирует решение, сопровождая его обширными листингами. Приятного чтения!

Никого из нас в той или иной форме не обошел хайп вокруг GPU-вычислений, развернувшийся в последнее время. Прежде, чем вы станете читать далее, поясню: я не эксперт по GPU. Мой путь в мире GPU только начинается. Но эта технология сегодня достигла такой мощи, что, вооружившись ею, можно решать целую уйму задач. Мне на работе поручили задачу, на выполнение которой машина тратила целые часы, а прогресса так и не было видно. Но, стоило мне взяться за GPU — и проблема стала решаться за секунды. Задачу, на выполнение которой ориентировочно требовалось 2 суток, я смог решить всего за 20 секунд.
В следующих разделах я детально опишу эту задачу. Также мы обсудим, как и когда использовать GPU для решения любых подобных задач. Итак, читаем внимательно — поверьте, вы не пожалеете. Сначала мы вникнем в детали задачи, затем освоимся с GPU и, наконец, воспользуемся GPU для решения этой задачи. Я буду пользоваться библиотекой Python Numba и графическим процессором Nvidia Volta V100 16GB GPU.
1. Подробное описание задачи
В сфере розничной торговли часто приходится искать похожие или наиболее близкие объекты. Мне дали список позиций, каждая из которых была представлена k латентными атрибутами. Итак, мне было поручено найти топ-3 наиболее схожих позиций к каждой из позиций списка. Метрикой схожести в данной задаче было выбрано косинусное сходство. Вот как выглядели мои данные.
Список позиций данных с 64-латентными признаками
Сложность задачи
Мне дали список, в котором было около 10⁵ позиций. Поиск 3 наиболее схожих позиций для каждой из них потребовал бы проверить косинусное сходство с каждым без исключения элементов в списке. Получалось бы n * k операций, где n — количество позиций, а k — атрибуты на каждую позицию. Потребовалось бы получить скалярное произведение данной позиции с каждой из остальных позиций в списке.
def top_3_similar_items(X,mindex): # X это список позиций, нам требуется найти топ-3 позиций, наиболее похожих на позицию с индексом 'mindex'
SMALL = -9999.0 # Просто для инициализации, поскольку нам нужно найти позицию с максимальным уровнем сходства(косинусный показатель)
first_best_val = SMALL # индекс первой по схожести позиции будет храниться здесь
first_best_index = -1 # косинусное сходство с первой по схожести позицией
second_best_val = SMALL # индекс второй по схожести позиции будет храниться здесь
second_best_index = -1 # косинусное сходство со второй по схожести позицией
third_best_val = SMALL # индекс третьей по схожести позиции будет храниться здесь
third_best_index = -1 # косинусное сходство с третьей по схожести позицией
for j in range(n): # Всего n-позиций в списке
if(mindex==j):
continue
tmp = np.dot(X[mindex],X[j])/(np.sqrt(np.sum(np.square(X[mindex]))) * np.sqrt(np.sum(np.square(X[j])))) # вычисление скалярного произведения
if(tmp>=first_best_val):
third_best_val = second_best_val
third_best_index = second_best_index
second_best_val = first_best_val
second_best_index = first_best_index
first_best_val = tmp
first_best_index = j
elif(tmp>=second_best_val):
third_best_val = second_best_val
third_best_index = second_best_index
second_best_val = tmp
second_best_index = j
elif(tmp>third_best_val):
third_best_val = tmp
third_best_index = j
return first_best_val,first_best_index,second_best_val,second_best_index,third_best_val,third_best_index # Возврат всех значений
Код для нахождения трех позиций, максимально подобных заданной
Теперь, при нахождении топ-3 схожих для всех позиций в списке, сложность умножается еще на n. Окончательная сложность оказывается равна O (n*n*k) = O (n²k).
def top_3_similar_all_items(X): # X это список позиций, из которого мы должны выбрать 3 наиболее схожих с каждой позицией
SMALL = -9999.99 # Просто для инициализации, поскольку нам нужно найти позицию с максимальным уровнем сходства(косинусный показатель)
first_best_index = np.zeros(n,dtype=int) # индекс первой по схожести позиции будет храниться здесь
first_best_val = np.zeros(n,dtype=float) # косинусное сходство с первой по схожести позицией
second_best_index = np.zeros(n,dtype=int) # индекс второй по схожести позиции будет храниться здесь
second_best_val = np.zeros(n,dtype=float) # косинусное сходство со второй по схожести позицией
third_best_index = np.zeros(n,dtype=int) # индекс третьей по схожести позиции будет храниться здесь
third_best_val = np.zeros(n,dtype=float) # косинусное сходство с третьей по схожести позицией
for i in range(n):
# Initialisation
first_best_val[i] = SMALL
first_best_index[i] = -1
second_best_val[i] = SMALL
second_best_index[i] = -1
third_best_val[i] = SMALL
third_best_index[i] = -1
for j in range(n):
if(i==j):
continue
tmp = np.dot(X[i],X[j])/(np.sqrt(np.sum(np.square(X[i]))) * np.sqrt(np.sum(np.square(X[j])))) # вычисление скалярного произведения
if(tmp>=first_best_val[i]):
third_best_val[i] = second_best_val[i]
third_best_index[i] = second_best_index[i]
second_best_val[i] = first_best_val[i]
second_best_index[i] = first_best_index[i]
first_best_val[i] = tmp
first_best_index[i] = j
elif(tmp>=second_best_val[i]):
third_best_val[i] = second_best_val[i]
third_best_index[i] = second_best_index[i]
second_best_val[i] = tmp
second_best_index[i] = j
elif(tmp>third_best_val[i]):
third_best_val[i] = tmp
third_best_index[i] = j
return first_best_val,first_best_index,second_best_val,second_best_index,third_best_val,third_best_index # Возврат всех значений
Код для нахождения трех наиболее схожих позиций для каждой позиции в списке
Тестовый прогон и оценка времени
Я запустил код, попробовав найти 3 наиболее похожие позиции из подмножества, содержащего n = 10³ позиций с k = 64. На выполнение этой задачи при помощи Python потребовалось около 17 секунд со средней скоростью 3.7×10⁶ операций в секунду. Код был хорошо оптимизирован с применением операций и массивов Numpy. Отмечу, что все эти операции последовательно выполняются на CPU.
%time first_best_val,first_best_index,second_best_val,second_best_index,third_best_val,third_best_index = top_3_similar_all_items(X)Прогон для n = 10³ позиций

Вывод: время, потребовавшееся для n = 10³ позиций
Далее я увеличил тестовое подмножество до n =10⁴ позиций. Поскольку сложность равна O (n²k), длительность выполнения возросла в 100 раз (поскольку n возросла в 10 раз). На выполнение кода ушло 1700 секунд = 28,33 минуты.

Вывод: время, потребовавшееся на обработку n = 10⁴ позиций
Далее подходим к самому важному: оценке времени, которое потребуется на обработку полноценного списка из 10⁵ позиций. Посчитав, увидим, что временная сложность вновь возрастет в 100 раз, поскольку временная сложность алгоритма равна O (n²k).
Ориентировочное время = 1700×100 секунд = 2834 минуты = 47,2 часа ~ 2 дня.
О, Господи! Так долго!!!
Вероятно, вы уже догадываетесь, что на самом деле мне удалось все сделать очень быстро, воспользовавшись силой GPU. На самом деле, выигрыш во времени при использовании GPU просто шокирует. Цифры я оставлю на закуску, а пока предлагаю вам познакомиться с миром GPU.
2. Сравнение CPU и GPU
Центральный процессор (CPU), в сущности, является мозгом любого вычислительного устройства: он выполняет записанные в программе инструкции, осуществляя управляющие, логические операции, а также операции ввода/вывода.
Правда, у современных CPU по-прежнему не так много ядер, и базовая структура и назначение CPU — обработка сложных вычислений — в сущности, не изменились. На самом деле, CPU лучше всего подходит для решения задач, заключающихся в разборе или интерпретации сложной логики, содержащейся в коде.
В свою очередь, графический процессор (GPU) обладает более мелкими логическими ядрами, которых, однако, гораздо больше (речь идет об арифметико-логических устройствах (АЛУ), управляющих элементах и кэш-памяти), которые спроектированы с расчетом на параллельную обработку в целом идентичных и сравнительно простых операций.
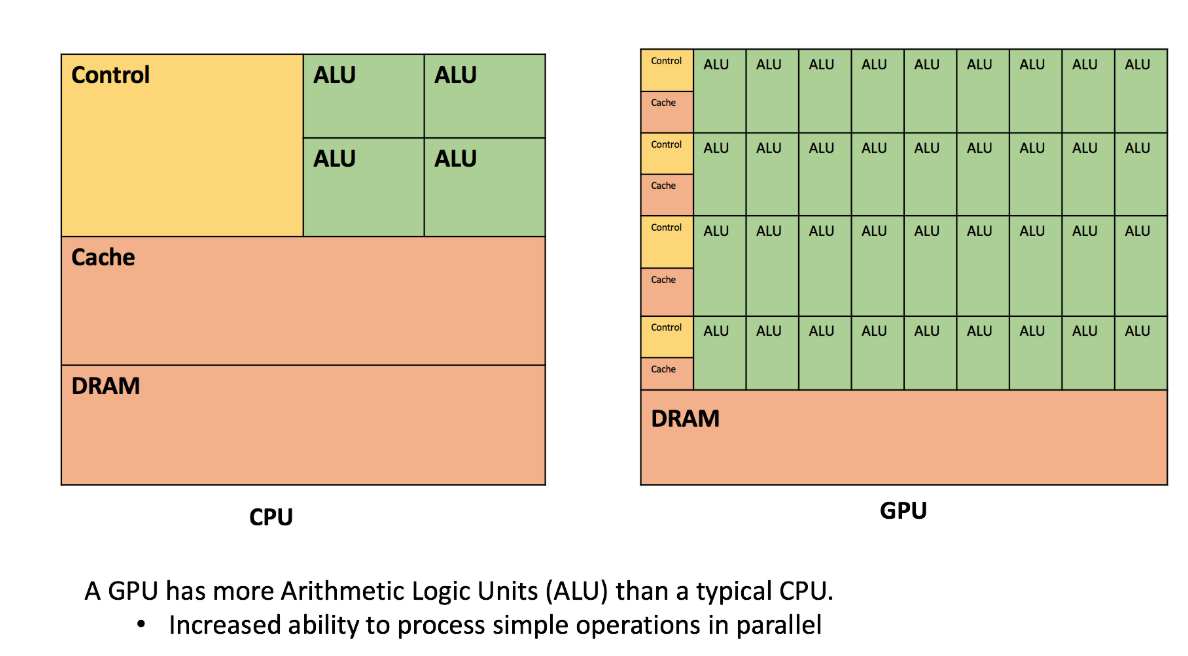
У GPU больше арифметических логических устройств (ALU), чем у типичного CPU, поэтому повышена способность параллельной обработки простых операций
Рисунок: сравнение CPU и GPU ~ Источник изображения
3. Когда использовать вычисления на GPU
CPU лучше подходит для выполнения сложных линейных задач. Несмотря на то, что ядра CPU мощнее, GPU позволяют эффективнее и быстрее обрабатывать задачи, связанные с ИИ, машинным и глубоким обучением. GPU справляется с рабочими нагрузками, распараллеливая схожие операции.
Представление об операциях с точки зрения GPU: возьмем, к примеру, операцию поиска слова в документе. Ее можно выполнить последовательно, перебрав одно за другим все слова в документе, либо параллельно, то есть, построчно, либо с поиском по конкретному слову.
Представление об операциях с точки зрения CPU — есть такие операции, например, расчет ряда Фибоначчи, которые нельзя распараллелить. Ведь найти очередное число можно лишь после того, как вычислишь предыдущие два. Такие операции лучше всего подходят для CPU.
В свою очередь, такие операции, как сложение и перемножение матриц, легко выполняются с применением GPU, поскольку большинство из этих операций в матричных ячейках являются независимыми друг от друга, схожи по природе, и поэтому могут быть распараллелены.
4. Кратко о CUDA
CUDA — это платформа для параллельных вычислений и модель API, созданная компанией Nvidia. С помощью этого API можно использовать процессор с поддержкой CUDA-графики для широкого спектра вычислений. Такой подход получил название GPGPU (неспециализированные вычисления на графических процессорах). Здесь о них рассказано подробнеe.
NUMBA
Numba — это свободно распространяемый JIT-компилятор, транслирующий подмножество Python и NumPy в быстрый машинный код при помощи LLVM, это делается средствами пакета llvmlite на Python. В этом пакете предлагается ряд вариантов по распараллеливанию кода на Python для CPU и GPU, в самом коде при этом зачастую достаточно минимальных изменений. См. подробнеe.
Работая с процессором Nvidia Volta V100 16GB GPU, я пользовался библиотекой Numba.
Детали архитектуры ~ потоки, блоки и гриды
CUDA организует параллельные вычисления при помощи таких абстракций как потоки, блоки и гриды.
Поток: поток CUDA — это назначенная цепочка инструкций, поступающих/текущих в ядро CUDA (на самом деле, это просто конвейер). На лету на одном и том же ядре CUDA может существовать до 32 потоков (в таком случае заполняются все звенья этого конвейера). Это выполнение ядра с заданным индексом. Каждый поток использует свой индекс для доступа элементов в массиве таким образом, что вся совокупность имеющихся потоков совместно обрабатывает все множество данных.
Блок: это группа потоков. Не так много можно рассказать о выполнении потоков внутри блока: они могут выполняться как последовательно, так и параллельно, так и без какого-либо определенного порядка. Можно координировать потоки, например, при помощи функции _syncthreads(), заставляющей поток остановиться в определенной точке в ядре и дождаться, пока все остальные потоки в том же блоке также достигнут этой же точки.
Грид: Это группа блоков. Между блоками отсутствует всякая синхронизация.

CUDA: потоки, блоки, гриды ~ Источник
Но где же именно выполняются потоки, блоки и гриды? В случае архитектуры G80 GPU от Nvidia, вычисления, по-видимому, распределены следующим образом:
Грид → GPU: Весь грид обрабатывается единственным GPU-процессором.
Блок → МП: Процессор GPU организован как коллекция мультипроцессоров, где каждый мультипроцессор отвечает за обработку одного или более блоков в гриде. Один блок никогда не делится между несколькими МП.
Поток → ПП: Каждый МП далее подразделяется на процессоры потоков (ПП), и каждый ПП обрабатывает один или более потоков в блоке.
Я позаимствовал некоторый материал из этой отлично написанной статьи. Рекомендую почитать ее внимательно.
5. Простая программа для сложения массивов на Python, использующая GPU
Как я уже говорил в самом начале, суть данной статьи — помочь широкой аудитории понять силу GPU и приобрести интуитивное представление, как применять GPU для решения повседневных задач. Перед тем, как начинать писать код для GPU, возможно, придется провести некоторые предварительные исследования. Для этого давайте разберем в качестве примера программу для сложения массивов.
Допустим, у нас есть два массива, «a» и «b» размера «n». Мы хотим сгенерировать массив «c», такой, чтобы каждый элемент массива c являлся суммой элементов с теми же индексами из массивов «a» и «b». Но в данном случае для решения задачи мы применим не последовательные вычисления, а параллельные, которые делаются при помощи GPU.
Мы запустим n потоков/ядер. Индекс, под которым работает каждый конкретный поток, можно вывести из следующей формулы:
index = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
В случае с двумерной матрицей в индексе присутствует два компонента, означающих строку и столбец, которые можно вывести следующим образом:
row = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
col = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
Также нам придется определить количество потоков на блок, скажем, tpb и блоков на грид, допустим bpg. Воспользуемся стандартными числами для них.
Здесь важно отметить еще одну важную концепцию: когда какие-либо вычисления должны быть выполнены на GPU, соответствующие данные должны быть перенесены в глобальную память GPU, а результаты вычислений после этого могут быть перенесены обратно на хост. Эти операции выполняются при помощи функций cuda.to_device() и copy_to_host(), предоставляемых в библиотеке Numba на Python.
Ниже приведены реализации данного решения как для CPU, так и для GPU. Посмотрите оба листинга, чтобы уловить разницу.
c = np.zeroes(n)
for i in range(n):
c[i] = a[i] + b[i]
return c
Последовательная реализация для CPU.
from numba import cuda # Библиотека Nvidia для работы с GPU
import numpy as np
@cuda.jit('void(float32[:], float32[:], float32[:])') #Динамический компилятор Cuda
def cuda_addition(a,b,c):
"""Поток будет выполнять эту функцию ядра."""
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x # Отображение потока на индекс массива
if i > c.size:
return
c[i] = a[i]+b[i] #Perform the addition
# Подробности об устройстве
device = cuda.get_current_device()
# Перенос с хоста на устройство
d_a = cuda.to_device(a) # Перенос данных в глобальную память GPU
d_b = cuda.to_device(b) # Перенос данных в глобальную память GPU
d_c = cuda.device_array_like(a)
tpb = device.WARP_SIZE #blocksize или количество потоков на блок, стандартное значение = 32
bpg = int(np.ceil((n)/tpb)) # блоков на грид
cuda_addition[bpg, tpb](d_a, d_b, d_c) # вызов ядра
# Перенос вывода с устройства на хост
c = d_c.copy_to_host()
print(c)
Параллельная реализация для GPU
6. Нахождение 3 наиболее похожих позиций для каждой позиции в списке при помощи GPU
Хорошенько вникнув в теорию и практику, возвращаемся к исходно поставленной задаче: найти топ-3 похожих позиции для каждой позиции в списке при помощи вычислений на GPU.
В данном случае основная идея заключается в том, что у нас n позиций, и мы запустим n потоков. Каждый поток будет работать параллельно с остальными и независимо от них, вычисляя по 3 наиболее похожие позиции для каждой позиции в списке. За каждую позицию будет отвечать один поток.
from numba import cuda # Nvidia's GPU Library
import numpy as np
import math #Выполнение математических вычислений, например, нахождение скалярного произведения, Numpy не поддерживается на GPU
import random
# Определение функции ядра
@cuda.jit('void(float32[:,:],float32[:],int32[:],float32[:],int32[:],float32[:],int32[:])') # CUDA Just-in-time Compiler
def cuda_dist(X,first_best_val,first_best_index,second_best_val,second_best_index,third_best_val,third_best_index):
"""Поток будет выполнять эту функцию ядра."""
# Отображение потока на строку
row = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x;
if ((row >= n)): # Принимать потоки только в границах матриц
return
first_best_val[row] = SMALL # косинусное сходство с первой по схожести позицией
first_best_index[row] = -1 # индекс первой по схожести позиции будет храниться здесь
second_best_val[row] = SMALL # косинусное сходство со второй по схожести позицией
second_best_index[row] = -1 # индекс второй по схожести позиции будет храниться здесь
third_best_val[row] = SMALL # косинусное сходство с третьей по схожести позицией
third_best_index[row] = -1 # индекс третьей по схожести позиции будет храниться здесь
for i in range(n):
if(i==row): # Тот же элемент
continue
# Переменные для вычисления скалярного произведения, так как мы не можем использовать операции numpy в контексте GPU
tmp = 0.0
magnitude1 = 0.0
magnitude2 = 0.0
for j in range(k):
tmp += X[row,j] * X[i,j]
magnitude1 += (X[row,j]* X[row,j])
magnitude2 += (X[i,j]* X[i,j])
tmp /= (math.sqrt(magnitude1)*math.sqrt(magnitude2)) # Значение скалярного произведения Dot_product(a,b) = a.b/(|a|*|b|)
if(tmp>=first_best_val[row]):
third_best_val[row] = second_best_val[row]
third_best_index[row] = second_best_index[row]
second_best_val[row] = first_best_val[row]
second_best_index[row] = first_best_index[row]
first_best_val[row] = tmp
first_best_index[row] = i
elif(tmp>=second_best_val[row]):
third_best_val[row] = second_best_val[row]
third_best_index[row] = second_best_index[row]
second_best_val[row] = tmp
second_best_index[row] = i
elif(tmp>third_best_val[row]):
third_best_val[row] = tmp
third_best_index[row] = i
# Подробности об устройстве
device = cuda.get_current_device()
d_x = cuda.to_device(X)
d_first_val = cuda.device_array_like(first_val)
d_first_index = cuda.device_array_like(first_index)
d_second_val = cuda.device_array_like(second_val)
d_second_index = cuda.device_array_like(second_index)
d_third_val = cuda.device_array_like(third_val)
d_third_index = cuda.device_array_like(third_index)
tpb = device.WARP_SIZE # blocksize или количество потоков на блок
bpg = int(np.ceil((n)/tpb)) # блоков на грид
%time cuda_dist[bpg,tpb](d_x,d_first_val,d_first_index,d_second_val,d_second_index,d_third_val,d_third_index) # вызов ядра
# Перенос вывода с устройства на хост
first_val = d_first_val.copy_to_host()
print (first_val[:10]) # Первые 10 значений
# Перенос вывода с устройства на хост
first_index = d_first_index.copy_to_host()
print (first_index[:10]) # Первые 10 индексов
Реализация для GPU ~ Код для нахождения 3 позиций, наиболее похожих на данную
Затраченное время
Общее время, затраченное GPU для нахождения топ-3 схожих позиций для каждой позиции в списке, составило 481 мс (0,5 секунд). Еще 20 секунд потребовалось для копирования данных с устройства на хост и с хоста на устройство.
7. Вывод
Задача, решение которой на CPU потребовало бы около 2 дней, на GPU была решена за 20,5 секунд. Это оказалось возможно только благодаря природе задачи. Поиск 3 наиболее похожих позиций для «A» не зависит от поиска 3 наиболее похожих позиций для «B». Мы воспользовались этим фактом и применили параллелизм, предоставляемый GPU, для ускорения процесса. Также пример иллюстрирует, задачи какого типа удобнее всего решать при помощи могучего GPU.
8. Благодарности
Данное исследование было выполнено на MLP (платформе машинного обучения) компании Walmart Labs. Спасибо Аюшу Кумару за помощь в оптимизации рабочего процесса.
