[Перевод] Как Discord хранит миллиарды сообщений

Discord продолжает расти быстрее, чем мы ожидали, как и пользовательский контент. Чем больше пользователей — тем больше сообщений в чате. В июле мы объявили о 40 млн сообщений в день, в декабре объявили о 100 млн, а в середине января преодолели 120 млн. Мы сразу решили хранить историю чатов вечно, так что пользователи могут вернуться в любой момент и получить доступ к своим данным с любого устройства. Это много данных, поток и объём которых нарастает, и все они должны быть доступными. Как мы это делаем? Cassandra!
Изначальную версию Discord написали быстрее чем за два месяца в начале 2015 года. Возможно, одной из лучших СУБД для быстрого выполнения итераций является MongoDB. Всё в Discord специально хранилось в едином реплисете (replica set) MongoDB, но мы также готовили всё для простой миграции в новую СУБД (мы знали, что не собираемся использовать шардинг MongoDB из-за его сложности и неизвестной стабильности). На самом деле это часть нашей корпоративной культуры: разрабатывай быстро, чтобы испытать новую функцию продукта, но всегда с курсом на более надёжное решение.
Сообщения хранились в коллекции MongoDB с единым составным индексом на channel_id и created_at. Примерно в ноябре 2015 года мы вышли на рубеж 100 млн сообщений в базе, и тогда начали понимать проблемы, которые нас ждут: данные и индекс больше не помещаются в ОЗУ, а задержки становятся непредсказуемыми. Пришло время мигрировать в более подходящую СУБД.
Перед выбором новой СУБД нам требовалось понять имеющиеся шаблоны чтения/записи и почему возникли проблемы с текущим решением.
- Быстро стало понятно, что операции чтения исключительно случайны, а соотношения чтение/запись примерно 50/50.
- Тяжёлые серверы голосовых чатов Discord практически не присылали сообщений. То есть они присылали одно или два сообщения каждые несколько дней. За год сервер такого типа вряд ли достигнет рубежа в 1000 сообщений. Проблема в том, что даже несмотря на такое малое количество сообщений, эти данные труднее доставлять пользователям. Просто возвращение пользователю 50-ти сообщений может привести к многим случайным операциям поиска на диске, что приводит к вытеснению дискового кэша.
- Тяжёлые серверы приватных текстовых чатов Discord отправляют приличное количество сообщений, легко попадая в диапазон между 100 тыс. и 1 млн сообщений в год. Запрашивают они обычно только самые последние данные. Проблема в том, что на этих серверах обычно менее 100 участников, так что скорость запроса данных низкая и вряд ли они будут в дисковом кэше.
- Большие публичные серверы Discord отправляют очень много сообщений. Там тысячи участников, отправляющих тысячи сообщений в день. Легко набираются миллионы сообщений в год. Они почти всегда запрашивают сообщения, отправленные в последний час, и это происходит часто. Поэтому данные обычно находятся в дисковом кэше.
- Мы знали, что в наступающем году у пользователей появится ещё больше способов генерировать случайные чтения: это возможность просматривать свои упоминания за последние 30 дней и затем перескакивать в тот момент истории, просмотр и переход к прикреплённым сообщениям и полнотекстовый поиск. Всё это означает ещё больше случайных чтений!
Затем мы определили наши требования:
- Линейная масштабируемость — Мы не хотим пересматривать решение позже или вручную переносить данные в другой шард.
- Автоматическая отказоустойчивость — Нам нравится спать по ночам и делать Discord настолько самоисцеляющимся, насколько это возможно.
- Небольшая поддержка — Она должна работать сразу же, как мы её установим. От нас требуется только добавлять больше нод по мере увеличения данных.
- Доказано в работе — Мы любим пробовать новые технологии, но не слишком новые.
- Предсказуемая производительность — Нам отправляются сообщения, если время отклика API в 95% случаев превышает 80 мс. Мы также не хотим сталкиваться с необходимостью кэшировать сообщения в Redis или Memcached.
- Не хранилище блобов — Запись тысяч сообщений в секунду не будет отлично работать, если нам придётся непрерывно десериализировать блобы и присоединять к ним данные.
- Open source — Мы верим, что управляем собственной судьбой, и не хотим зависеть от сторонней компании.
Cassandra оказалась единственной СУБД, которая удовлетворила всем нашим требованиям. Мы можем просто добавлять ноды при масштабировании, а она справляется с потерей нод без всякого влияния на приложение. В больших компаниях вроде Netflix и Apple — тысячи нод Cassandra. Связанные данные хранятся рядом на диске, обеспечивая минимум операций поиска и лёгкое распределение по кластеру. Она поддерживается компанией DataStax, но распространяется с открытым исходным кодом и силами сообщества.
Сделав выбор, нужно было доказать, что он действительно оправдан.
Моделирование данныхЛучший способ описать новичку Cassandra — это аббревиатура KKV. Две буквы «K» содержат в себе первичный ключ. Первая «K» — это ключ раздела. Он помогает определить, в какой ноде живут данные и где их найти на диске. Внутри раздела множество строк, и конкретную строку внутри раздела определяет вторая «K» — ключ кластеризации. Он работает как первичный ключ внутри раздела и определяет способ сортировки строк. Можете представить раздел как упорядоченный словарь. Все эти качества вместе взятые позволяют очень мощное моделирование данных.
Помните, что сообщения в MongoDB индексировались с использованием channel_id и created_at? channel_id стал ключом раздела, поскольку все сообщения работают в канале, но created_at не даёт хорошего ключа кластеризации, потому что два сообщения могут быть созданы в одно время. К счастью, каждый ID в Discord на самом деле создан в Snowflake, то есть хронологически сортируется. Так что можно было использовать именно их. Первичный ключ превратился в (channel_id, message_id), где message_id — это Snowflake. Это значит, что при загрузке канала мы можем сказать Cassandra точный диапазон, где искать сообщения.
Вот упрощённая схема для нашей таблицы сообщений (она пропускает примерно 10 колонок).
CREATE TABLE messages (
channel_id bigint,
message_id bigint,
author_id bigint,
content text,
PRIMARY KEY (channel_id, message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);Хотя схемы Cassandra не являются её отличием от реляционных СУБД, их легко изменять, что не оказывает какого-либо временного влияния на производительность. Мы взяли лучшее от хранилища блобов и реляционного хранилища.
Как только начался импорт существующих сообщений в Cassandra, мы сразу увидели в логах предупреждения, что найдены разделы размером более 100 МБ. Да ну?! Ведь Cassandra заявляет о поддержке разделов 2 ГБ! По всей видимости, сама возможность не означает, что так нужно делать. Большие разделы накладывают сильную нагрузку на сборщик мусора в Cassandra при уплотнении, расширении кластера и т.д. Наличие большого раздела также означает, что данные в нём нельзя распределить по кластеру. Стало ясно, что нам придётся как-то ограничить размеры разделов, потому что некоторые каналы Discord могут существовать годами и постоянно увеличиваться в размере.
Мы решили распределить наши сообщения блоками (buckets) по времени. Мы посмотрели на самые большие каналы в Discord и определили, что если хранить сообщения блоками примерно по 10 дней, то комфортно вложимся в лимит 100 МБ. Блоки нужно получать из message_id или метки времени.
DISCORD_EPOCH = 1420070400000
BUCKET_SIZE = 1000 * 60 * 60 * 24 * 10
def make_bucket(snowflake):
if snowflake is None:
timestamp = int(time.time() * 1000) - DISCORD_EPOCH
else:
# When a Snowflake is created it contains the number of
# seconds since the DISCORD_EPOCH.
timestamp = snowflake_id >> 22
return int(timestamp / BUCKET_SIZE)
def make_buckets(start_id, end_id=None):
return range(make_bucket(start_id), make_bucket(end_id) + 1)Ключи разделов Cassandra могут быть составными, так что нашим новым первичным ключом стал
((channel_id, bucket), message_id).CREATE TABLE messages (
channel_id bigint,
bucket int,
message_id bigint,
author_id bigint,
content text,
PRIMARY KEY ((channel_id, bucket), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);Для запроса недавних сообщений в канале мы сгенерировали диапазон блоков от текущего времени до
channel_id (он тоже хронологически сортируется как Snowflake и должен быть старше, чем первое сообщение). Затем мы последовательно опрашиваем разделы до тех пор, пока не соберём достаточно сообщений. Обратная сторона такого метода в том, что изредка активным инстансам Discord придётся опрашивать много разных блоков, чтобы собрать достаточно сообщений со временем. На практике оказалось, что всё в порядке, потому что для активного инстанса Discord обычно находится достаточно сообщений в первом разделе, и таких большинство.Импорт сообщений в Cassandra прошёл без помех, и мы были готовы опробовать её в производстве.
Тяжёлый запускВыводить новую систему в производство всегда страшно, так что хорошей идеей будет проверить её, не затрагивая пользователей. Мы настроили систему на дублирование операций чтения/записи в MongoDB и Cassandra.
Немедленно после запуска в баг-трекере появились ошибки, что author_id равен нулю. Как он может быть нулевым? Это обязательное поле!
Cassandra — система типа AP, то есть гарантированная целостность здесь приносится в жертву доступности, что мы и хотели, в общем. В Cassandra противопоказано чтение перед записью (операции чтения более дорогие) и поэтому всё, что делает Cassandra, — это обновление и вставку (upsert), даже если предоставить только определённые колонки. Вы также можете писать в любую ноду, и она автоматически разрешит конфликты, используя семантику «последняя запись выигрывает» по каждой колонке. Так как это нас коснулось?

Пример состояния гонки редактирование/удаление
В случае, если пользователь редактировал сообщение, в то время как другой пользователь удалял то же самое сообщение, у нас появлялась строка с полностью отсутствующими данными, за исключением первичного ключа и текста, потому что Cassandra записывает только обновления и вставки. Для этой проблемы есть два возможных решения:
- Записывать обратно целое сообщение во время редактирования сообщения. Тогда есть возможность воскрешения удалённых сообщений и добавляются шансы конфликтов для одновременных записей в другие колонки.
- Выявить повреждённое сообщение и удалить его из базы.
Мы выбрали второй вариант, определив требуемую колонку (в этом случае
author_id) и удаляя сообщение, если оно пустое.Решая эту проблему, мы заметили, что были весьма неэффективны с операциями записи. Поскольку Cassandra согласована в конечном счёте, то она не может вот так взять и немедленно удалить данные. Ей нужно реплицировать удаления на другие ноды, и это следует сделать даже если ноды временно недоступны. Cassandra справляется с этим, приравнивая удаление к своеобразной форме записи под названием «tombstone» («надгробие»). Во время операция чтения она просто проскакивает через «надгробия», которые встречаются по пути. Время жизни «надгробий» настраивается (по умолчанию, 10 дней), и они навсегда удаляются во время уплотнения базы, если срок вышел.
Удаление колонки и запись нуля в колонку — это абсолютно одно и то же. В обоих случаях создаётся «надгробие». Поскольку все записи в Cassandra являются обновлениями и вставками, то вы создаёте «надгробие» даже если изначально записываете нуль. На практике, наша полная схема сообщения состояла из 16 колонок, но среднее сообщение имело только 4 установленных значения. Мы записывали 12 «надгробий» в Cassandra, обычно без всякой причины. Решение проблемы было простым: записывать в базу только ненулевые значения.
ПроизводительностьИзвестно, что Cassandra быстрее выполняет операции записи, чем чтения, и мы наблюдали в точности это. Операции записи происходили в интервале менее миллисекунды, а операции чтения — менее 5 миллисекунд. Такие показатели наблюдались независимо от типа данных, к которым осуществлялся доступ. Производительность сохранялась неизменной в течение недели тестирования. Ничего удивительного, мы получили в точности то, чего ожидали.
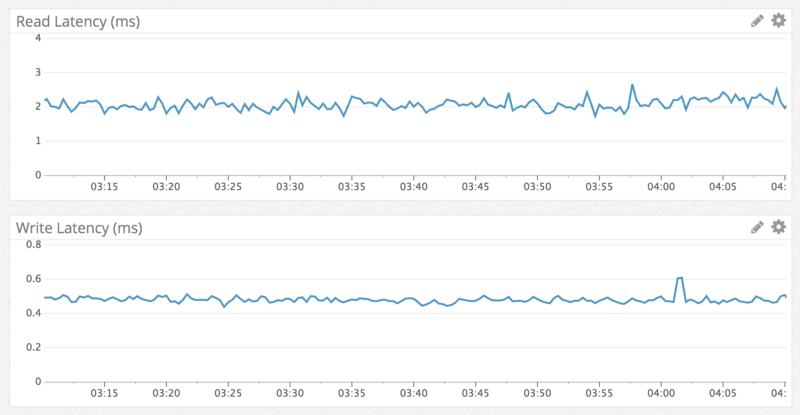
Задержка чтения/записи, по данным из лога
В соответствии с быстрой, надёжной производительностью чтения, вот пример перехода к сообщению годичной давности в канале с миллионами сообщений:
Всё прошло гладко, так что мы выкатили Cassandra как нашу основную базу данных и вывели из строя MongoDB в течение недели. Она продолжала безукоризненно работать… примерно 6 месяцев, пока однажды не перестала реагировать.
Мы заметили, что Cassandra непрерывно останавливается на 10 секунд во время сборки мусора, но совершенно не могли понять, почему. Начали копать — и нашли канал Discord, который требовал 20 секунд для загрузки. Виновником был публичный Discord-сервер подреддита Puzzles & Dragons. Поскольку он публичный, мы присоединились посмотреть. К нашему удивлению, на канале было только одно сообщение. В тот момент стало очевидно, что они удалили миллионы сообщений через наши API, оставив только одно сообщение на канале.
Если вы внимательно читали, то помните, как Cassandra обрабатывает удаления при помощи «надгробий» (упомянуто в главе «Согласованность в конечном счёте»). Когда пользователь загружает этот канал, хоть там одно сообщение, Cassandra приходится эффективно сканировать миллионы «надгробий» сообщений. Тогда она генерирует мусор быстрее, чем JVM может собрать его.
Мы решили эту проблему следующим образом:
- Уменьшили время жизни надгробий с 10 дней до 2 дней, потому что мы каждый вечер запускаем починку Cassandra (противоэнтропийный процесс) на нашем кластере сообщений.
- Изменили код запросов, чтобы отслеживать пустые блоки на канале и избегать их в будущем. Это значит, что если пользователь снова инициировал этот запрос, то в худшем случае Cassandra будет сканировать только самый последний блок.
Будущее
В данный момент у нас работает кластер из 12 нодов с коэффициентом репликации 3, и мы продолжим добавлять новые ноды Cassandra по мере надобности. Мы верим, что этот подход работоспособен в долговременной перспективе, но по мере роста Discord просматривается отдалённое будущее, когда придётся сохранять миллиарды сообщений в день. У Netflix и Apple работают кластеры с сотнями нодов, поэтому пока что нам не о чем волноваться. Однако хочется иметь пару идей про запас.
Ближайшее будущее
- Обновить наш кластер сообщений с Cassandra 2 на Cassandra 3. Новый формат хранения в Cassandra 3 может сократить объём хранения более чем на 50%.
- Более новые версии Cassandra лучше справляются с обработкой большего количества данных в каждом ноде. Мы сейчас храним примерно 1 ТБ сжатых данных в каждом из них. Думаем, что можно безопасно сократить количество нодов в кластере, увеличив этот лимит до 2 ТБ.
Отдалённое будущее
- Изучить Scylla — это СУБД, совместимая с Cassandra и написанная на C++. В нормальной работе наши ноды Cassandra в реальности потребляют немного ресурсов CPU, однако в непиковые часы во время починки Cassandra (противоэнтропийный процесс) они довольно зависят от CPU, а время починки возрастает в зависимости от количества данных, записанных с момента прошлой починки. Scylla обещает значительно увеличить скорость починки.
- Создать систему для архивации неиспользуемых каналов в Google Cloud Storage и загрузки их обратно по требованию. Мы хотим избежать этого и не думаем, что такое придётся делать.
Заключение
Прошло уже больше года с момента перехода на Cassandra, и несмотря на «большой сюрприз», это было спокойное плавание. Мы вышли с более 100 миллионов общего количества сообщений на более чем 120 миллионов сообщений в день, сохранив производительность и стабильность.
Благодаря успеху этого проекта, с тех пор мы перенесли все остальные наши данные в производстве на Cassandra, и тоже успешно.
В продолжении этой статьи мы исследуем, как мы осуществляем полнотекстовый поиск по миллиардам сообщений.
У нас до сих пор нет специализированных инженеров DevOps (только четыре инженера бэкенда), так что очень классно иметь систему, о которой не приходится волноваться. Мы набираем сотрудников, так что обращайтесь, если подобные задачки щекочут ваше воображение.
Комментарии (1)
11 марта 2017 в 17:19 (комментарий был изменён)
+1↑
↓
Изначальную версию Discord написали быстрее чем за два месяца в начале 2015 года
Интересно как много человек участвовало в этом процессе. Production-ready приложение быстрее чем за два месяца — звучит вызывающе.
