[Перевод] Искусственный интеллект в Wolfram Language: проект по идентификации изображений
Перевод поста Стивена Вольфрама (Stephen Wolfram) «Wolfram Language Artificial Intelligence: The Image Identification Project».Выражаю огромную благодарность Кириллу Гузенко за помощь в переводе. «Что изображено на этой картинке?» Люди практически сразу могут ответить на этот вопрос, и раньше казалось, что это непосильная задача для компьютеров. Последние 40 лет я знал, что компьютеры научатся решать подобные задачи, но не знал, когда это произойдёт.Я создавал системы, которые дают компьютерам разные составляющие интеллекта, и эти составляющие зачастую далеко за пределами человеческих возможностей. С давних про мы интегрируем разработки по искусственному интеллекту в Wolfram Language.
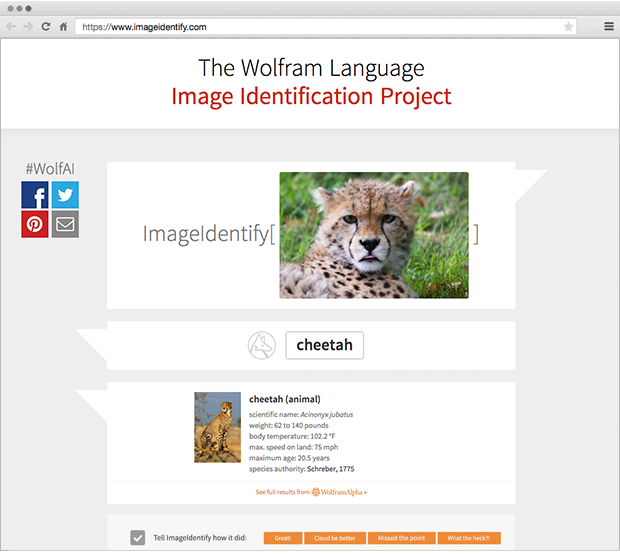
И сейчас я весьма рад сообщить о том, что мы перешли новый рубеж: вышла новая функция Wolfram Language — ImageIdentify, которую можно спросить — «что изображено на картинке?» и получить ответ.
Сегодня мы запускаем Wolfram Language Image Identification Project — проект по идентификации изображений, который работает через интернет. Можно отправить туда изображение с камеры телефона, с браузера, или перетащить его посредством drag&drop в соответствующую форму, или просто загрузить файл. После этого ImageIdentify выдаст свой результат:
 Содержание
Теперь в Wolfram LanguageЛичная предысторияМашинное обучениеВсе это связано с аттракторамиАвтоматически созданные программыПочему сейчас? Вижу только шляпуМы потеряли муравьедов! Назад к природеКонечно, ответ не всегда будет правильный, но в большинстве случаев функция работает очень даже хорошо. И примечателен тот факт, что если функция и допускает какие-то ошибки, то они похожи на те, которые допустил бы человек.Это хороший практический пример искусственного интеллекта. Однако для меня более важный момент состоит в том, что подобное взаимодействие с искусственным интеллектом мы встраиваем напрямую в Wolfram Language — ещё один мощный камень фундамента парадигмы программирования, основанной на знаниях.
Содержание
Теперь в Wolfram LanguageЛичная предысторияМашинное обучениеВсе это связано с аттракторамиАвтоматически созданные программыПочему сейчас? Вижу только шляпуМы потеряли муравьедов! Назад к природеКонечно, ответ не всегда будет правильный, но в большинстве случаев функция работает очень даже хорошо. И примечателен тот факт, что если функция и допускает какие-то ошибки, то они похожи на те, которые допустил бы человек.Это хороший практический пример искусственного интеллекта. Однако для меня более важный момент состоит в том, что подобное взаимодействие с искусственным интеллектом мы встраиваем напрямую в Wolfram Language — ещё один мощный камень фундамента парадигмы программирования, основанной на знаниях.
Теперь в Wolfram Language
Для того, чтобы распознать какое-то изображение при работе с Wolfram Language, Вам нужно просто применить функцию ImageIdentify к этому изображению: ![In[1]:= ImageIdentify[image:giant anteater]](http://habrastorage.org/getpro/habr/post_images/a15/ec9/a68/a15ec9a689f0db2f132ff7d962dd601c.png)
На выходе Вы получаете некоторый символьный объект, с которым можно и дальше работать в Wolfram Language. Как в данном примере — выяснить, что это именно животное, млекопитающее и так далее. Или просто спросить определение:
![In[2]:= giant anteater ["Definition"]](http://habrastorage.org/getpro/habr/post_images/374/b9b/fd6/374b9bfd6d298d9fbf8c1693519e21f3.png)
Или, к примеру, сгенерировать облако из тех слов, что встречаются в статье Википедии, посвященной объекту на картинке:
![In[3]:= WordCloud[DeleteStopwords[WikipediaData[giant anteater]]]](http://habrastorage.org/getpro/habr/post_images/723/9ff/c2a/7239ffc2a8002c8cbe51e9fe46876097.png)
Если у Вас есть какой-то массив фотографий, то Вы можете почти моментально написать программу на Wolfram Language, которая бы, к примеру, выдавала бы статистику о том, какие животные, устройства, платы — не важно что — насколько часто встречаются в этом массиве.
С помощью функции ImageIdentify, встроенной непосредственно в Wolfram Language, очень легко создавать какие-то API, приложения, в которых это используется. А с помощью Wolfram Cloud очень легко создавать сайты — как, к примеру, сайт Wolfram Language Image Identification Project.
Личная предыстория Лично я очень долго ждал ImageIdentify. Где-то 40 лет назад я читал книгу под названием The Computer and the Brain, которую пронизывала мысль — рано или поздно мы создадим искусственный интеллект, скорее всего эмулируя электрические связи в мозге. И в 1980-м году, после того, как я достиг некоторых успехов с моим первым компьютерным языком, я начал размышлять о том, что нужно сделать для того, чтобы создать полноценный искусственный интеллект.Я был воодушевлён теми идеями, которые впоследствии были реализованы в Wolfram Language — идея в символьном сопоставлении с образцами, которая, как мне представлялось, может отразить некоторые аспекты человеческого мышления. Но я знал, что если распознавание изображений и основано на сопоставлении с образцом, то тут нужно кое-что другое — нечёткое сопоставление.
Я пытался создать алгоритмы нечёткого кеширования. И не переставал думать о том, как мозг реализует всё это. Мы должны позаимствовать принципы его работы. И это сподвигло меня начать изучение идеализированных нейронных сетей и их поведения.
Тем временем я так же размышлял о некоторых фундаментальных вопросах в естественных науках — о космологии, о том, как масштабные структуры возникают в нашей вселенной, как частицы самоорганизуются.
И в какой-то момент я осознал, что как нейронные сети, так и самопритягивающиеся скопления частиц являются примерами систем, которые хоть и имели простые базовые компоненты, но почему-то добились сложного коллективного поведения. Копая глубже, я дошёл до клеточных автоматов, что привело меня ко всем тем идеям и открытиям, которые вылились в книгу A New Kind of Science.
Так что насчёт нейронных сетей? Они не были моими любимыми системами — казались слишком произвольными и сложными в своей структуре по сравнению с другими системами, которые я исследовал в вычислительном мире. Однако я продолжал размышлять о них снова и снова, проводил моделирования, чтобы лучше понять основы их поведения, пытался использовать их для каких-то конкретных задач, как, к примеру, нечеткое сопоставление с образцом:
 История нейронных сетей была сопряжена с чередой взлётов и падений. Сети внезапно появляются в 1940-е. Однако к 60-м годам интерес к ним снизился, и ходило мнение о том, что они довольно-таки бесполезны и с их помощью мало чего можно сделать.
История нейронных сетей была сопряжена с чередой взлётов и падений. Сети внезапно появляются в 1940-е. Однако к 60-м годам интерес к ним снизился, и ходило мнение о том, что они довольно-таки бесполезны и с их помощью мало чего можно сделать.
Однако это было верно лишь для перцептрона с одним слоем (одна из первых моделей нейронной сети). Возрождение интереса пришлось на начало восьмидесятых — появились модели нейронных сетей со скрытым слоем. И несмотря на то, что я знаю многих передовиков этого направления, всё же я оставался в некотором роде скептиком. Меня не покидало впечатление, что те задачи, которые решаются с помощью нейронных сетей, могут быть гораздо проще решены множеством других способов.
И мне казалось, что нейронные сети — слишком сложные формальные системы; как-то я даже попытался разработать свою собственную альтернативу. Однако я всё ещё поддерживал людей в научном центре по исследованию нейронных сетей и включал их статьи в свой журнал Complex Systems.
Действительно, были некоторые практические применения для нейронных сетей — к примеру, визуальное распознавание символов — однако их было мало и они были разрознены. Шли годы и, казалось, почти ничего нового в этой сфере не появляется.
Машинное обучение Тем временем мы занимались разработкой множества мощных прикладных алгоритмов анализа данных в Mathematica и в том, что потом превратилось в Wolfram Language. И несколько лет назад мы пришли к тому, что настало время двигаться дальше и попытаться интегрировать в систему высокоавтоматизированное машинное обучение. Идея заключалась в том, чтобы создавать очень мощные и общие функции; к примеру, функция Classify, которая будет классифицировать вещи любого вида: скажем, на какой фотографии день, а на какой — ночь, звуки различных музыкальных инструментов, важность сообщений электронной почты и так далее.Мы применяем большое количество современных методов. Но, что важнее, мы попытались добиться полной автоматизации, чтобы пользователи могли вообще ничего не знать о машинном обучении: достаточно просто вызвать Classify.
Я вначале не был уверен, что это будет работать. Но всё работает, и очень хорошо.
В качестве данных для обучения Вы можете использовать практически всё, что угодно, а Wolfram Language будет работать с классификаторами в автоматическом режиме. Так же мы внедряем всё больше и больше различных уже встроенных классификаторов: скажем, для языков, флагов стран:
![In[4]:= Classify["Language", {"欢迎光临", "Welcome", "Bienvenue", "Добро пожаловать", "Bienvenidos"}]](http://habrastorage.org/getpro/habr/post_images/d19/8e2/cfc/d198e2cfc0ed5b3636293646831d5fd2.png)
![In[5]:= Classify["CountryFlag", {images:flags}]](http://habrastorage.org/getpro/habr/post_images/6bb/57a/fdd/6bb57afddf560c433f94bd162cf161b9.png)
И некоторое время назад мы пришли к тому, что пора взяться за масштабную проблему классификации — распознавание изображений. И вот наш результат — ImageIdentify.
Все это связано с аттракторами В чём заключается распознавание изображений? В мире существует большое количество самых разнообразных вещей, которым люди дали имя. Суть распознавания — определить, какие из этих вещей представлены на этом изображении. Если более формально — отобразить все возможные изображения в некоторое множество имён объектов в символьной форме.То есть мы не имеем никакого способа описать, к примеру, стул. Но мы можем привести множество примеров того, как выглядит стул, как бы говоря: «всё, что похоже на вот это вот, пусть определяется системой как стул». То есть мы хотим, чтобы все изображения, в которых содержится нечто, похожее на стул, имели соответствие со словом стул, а другие изображения не имели бы такого соответствия.
Есть множество различных систем с подобным «аттракторным» поведением. В качестве примера из физического мира можно привести склон горы. Капли дождя могут упасть на какую угодно часть горы, однако (по крайней мере, в идеальной модели) они будут стекать вниз к максимально низкорасположенным точкам. Капли, которые находятся рядом, будут стремиться к одним и тем же точкам. Далеко расположенные друг от друга капли будут течь к разным точкам.
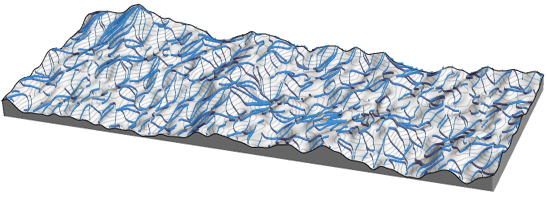 Капли дождя — они как изображения, а точки подножья горы — как виды объектов. Под каплями дождя мы подразумеваем некоторые физические объекты, которые движутся под действием гравитации. Однако изображения состоят из пикселей. И вместо физического движения мы должны думать о том, как эти цифровые значения должны быть обработаны программой.
Капли дождя — они как изображения, а точки подножья горы — как виды объектов. Под каплями дождя мы подразумеваем некоторые физические объекты, которые движутся под действием гравитации. Однако изображения состоят из пикселей. И вместо физического движения мы должны думать о том, как эти цифровые значения должны быть обработаны программой.
И точно такое же аттракторное поведение происходит и здесь. К примеру, есть множество клеточных автоматов, в котором каждый автомат может менять цвета нескольких соседних клеток, но всё в любом случае закончится некоторым устойчивым состоянием (большинство клеточных автоматов, на самом деле, имеют более интересное поведение, которое не имеет какого-то конечного состояния, однако тогда бы у нас не получилось провести аналогию к задачам распознавания).
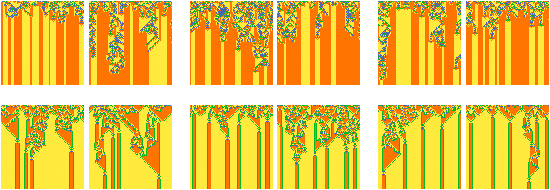 Так что же произойдёт, если мы возьмём изображение и применим к нему алгоритмы клеточных автоматов? В действительности, когда мы обрабатываем изображения, то некоторые обычные операции (на компьютерах или с помощью визуального осмотра человеком) есть просто алгоритмы двумерных клеточных автоматов.
Так что же произойдёт, если мы возьмём изображение и применим к нему алгоритмы клеточных автоматов? В действительности, когда мы обрабатываем изображения, то некоторые обычные операции (на компьютерах или с помощью визуального осмотра человеком) есть просто алгоритмы двумерных клеточных автоматов.
 Легко заставить клеточные автоматы различить некоторые особенности изображения наподобие тёмных пятен, например. Однако для распознавания изображений требуется нечто большее. Если опять применить ту аналогию с горой, то нам нужно создать склон горы со всеми его свойствами, чтобы капли с соответствующей части горы стекали на соответствующую часть её подножия.
Легко заставить клеточные автоматы различить некоторые особенности изображения наподобие тёмных пятен, например. Однако для распознавания изображений требуется нечто большее. Если опять применить ту аналогию с горой, то нам нужно создать склон горы со всеми его свойствами, чтобы капли с соответствующей части горы стекали на соответствующую часть её подножия.
Автоматически созданные программы Так как мы это сделаем? В случае таких цифровых данных, как изображения — никто не знает, как это сделать одним махом. Это итеративный процесс. Вначале мы имеем некоторую заготовку, а затем постоянно меняем её форму, вылепливая то, что нам нужно.Многие вещи в этом процессе скрыты от нас. Я усердно размышлял об этом, как всё это соотносится с дискретными программами наподобие клеточных автоматов, машиной Тьюринга и подобным. И я уверен, что тут можно получить очень интересные результаты. Но я никогда не понимал —, а как именно?
 Для систем с конечным действительным числом параметров есть отличный метод под названием «обратное распространение» (back propagation), который основан на вычислениях. Он является, по сути, вариантом очень простого метода — метода наследования градиента, в котором вычисляются производные, а затем используются для определения того, как изменить параметры, чтобы система обладала желаемым поведением.
Для систем с конечным действительным числом параметров есть отличный метод под названием «обратное распространение» (back propagation), который основан на вычислениях. Он является, по сути, вариантом очень простого метода — метода наследования градиента, в котором вычисляются производные, а затем используются для определения того, как изменить параметры, чтобы система обладала желаемым поведением.
Итак, систему какого типа нам нужно использовать? Несколько неожиданно, но основной вариант — нейронные сети. Название навевает мысли о мозгах и о чём-то биологическом. Однако в нашем случае нейронные сети — формальные вычислительные системы, которые состоят из некоторых композиций функций от многих аргументов с непрерывными параметрами и дискретными пороговыми величинами.
Насколько легко заставить подобную нейронную сеть выполнять какие-то интересные задачи? Сложно сказать, на самом деле. По крайней мере последние 20 лет я считал, что нейронные сети могут делать только те вещи, которые и без них можно реализовать какими-то другими, более простыми способами.
Но несколько лет назад всё начало меняться. И теперь часто можно услышать о каком-нибудь ещё одном успешном применении нейронных сетей для решения каких-то прикладных задач как, скажем, распознавание изображений.
Как это произошло? Компьютеры (и особенно линейная алгебра в графических процессорах) стали достаточно быстрыми, чтобы справляться с различными алгоритмическими хитростями, в том числе и с клеточными автоматами — стало возможно создавать нейронные сети с миллионами нейронов (и да, теперь это глубокие нейронные сети с множеством уровней). И всё это породило множество различных новых сфер применений.
Почему сейчас? Я не думаю, что это совпадение, что это произошло как раз тогда, когда число искусственных нейронов стало сравнимо с числом нейронов в соответствующих частях нашего мозга.И дело не в том, что количество само по себе что-то значит. Скорее дело в том, что, если мы решаем какие-то задачи наподобие распознавания изображений, — те задачи, которые решает человеческий мозг — неудивительно, что нам нужна система соответствующего масштаба.
Люди легко могут распознавать тысячи самых разных объектов — примерно столько, сколько в языке имеется существительных, которые можно как-то изобразить. Другие животные различают гораздо меньше объектов. Но если мы попытаемся распознавать образы так, как это делает человек, эффективно отображая их в слова, которые есть в человеческих языках, то тогда мы столкнёмся со всем масштабом проблемы. Ключ к её решению — нейронная сеть масштаба человеческого мозга.
Несомненно, есть различия между вычислительными и биологическими нейронными сетями, хотя после того, как сеть обучена, процесс получения результата из образа оказывается весьма схож. Но методы, используемые для обучения вычислительных нейронных сетей, существенно отличаются от тех, которые должны были бы использоваться в биологических сетях.
Тем не менее, при разработке ImageIdentify я был по-настоящему поражён, насколько её поведение похоже на биологическую нейронную сеть. Прежде всего, количество образов для обучения — несколько десятков миллионов — сопоставимо с числом объектов, с которыми люди сталкиваются в первые пару лет своей жизни.
Вижу только шляпу
Были и особенности в обучении, которые очень похожи на те, что возникают для биологических нейронных сетей. К примеру, как-то мы допустили ошибку, не поместив изображения лиц людей в обучающую подборку. И когда мы показали картинку, на которой был Индиана Джонс, то система вообще не поняла, что здесь есть какое-то лицо и выдала, что на картинке изображена шляпа. Возможно, в этом нет ничего удивительного, но как это напоминает классический эксперимент с котятами, которые всю свою жизнь наблюдали только вертикальные полосы, после чего не могли видеть горизонтальные.
Вероятно, как и у мозга, у нейронной сети ImageIdentify имеется множество слоёв, которые содержат нейроны разных типов (общая структура, конечно, хорошо описана символьным представлением Wolfram Language).
Трудно сказать что-то осмысленное о том, что-же происходит внутри сети. Но если заглянуть в верхние слои, то можно будет выделить какие-то черты, которые различает система. И, пожалуй, они весьма схожи с теми чертами, которые различаются настоящими нейронами в первичной зрительной коре.
Я сам давно интересовался такими вещами, как визуальное текстурное распознавание, (определение каких-то текстурных примитивов, наподобие основного цвета) и полагаю, что мы сейчас сможем многое понять из этого. Так же, думаю, было бы очень интересно заглянуть в глубокие слои нейронной сети и посмотреть, что же там происходит. Мы бы смогли там обнаружить некоторые концепции, которые и в самом деле описывают классы объектов, в том числе и те, для которых пока что нет слов на естественных человеческих языках.
Мы потеряли муравьедов! Как и во множества других проектов для Wolfram Language, при создании ImageIdentify нам потребовалось заниматься множеством разных вещей. Работа с большим количеством обучающих изображений. Разработка онтологии визуализируемых объектов и перенос её на Wolfram Language. Анализ динамики нейронных сетей с использованием методов, которые применяются в физике. Кропотливая оптимизация параллельного кода. Даже некоторые исследования в стиле A New Kind of Science для программ вычислительного мира. И множество субъективных мнений о том, как привносить функциональность, которая была бы полезной на практике.В самом начале я не был уверен, будет-ли ImageIdentify работать. И в самом начале количество абсолютно неправильно распознанных образов было очень высоким. Однако шаг за шагом мы постепенно приблизились к тому моменту, когда с помощью ImageIdentify уже можно было получить что-то полезное.
Но осталось ещё большое количество нерешенных проблем. Система хорошо справлялась с одними вещами, но серьезно буксовала в других. Мы что-то меняли, что-то настраивали, а потом были новые неудачи и шквал сообщений в стиле «мы опять потеряли муравьеда!» (о том, как те изображения, которые ImageIdentify использовал для корректного распознавания муравьедов, распознавались почему-то как что-то совершенно другое).
Отладка ImageIdentify была весьма увлекательным процессом. Что можно считать осмысленными входными данными? А что есть осмысленные данные на выходе? Как выбрать — более общий и надёжный результат, или более конкретный, но менее надёжный (просто собака, или охотничья собака, или бигль)?
Бывали и вещи, которые на первый взгляд казались абсолютно сумасшедшими. Свинья, которая идентифицировалась как упряжь. Кусок каменной кладки определялся как мопед. Но хорошая новость состояла в том, что мы всегда находили причину — к примеру то, что некоторые нерелевантные объекты постоянно оказывались на обучающих изображениях (единственные каменные кладки, которые видел ImageIdentify — азиатские, на фоне которых постоянно были мопеды).
Чтобы испытать систему, я часто пробовал нестандартные изображения:
 И меня поразило то, что я обнаружил. Да, ImageIdentify может ошибаться. Но почему-то ошибки казались очень понятными и в каком-то смысле человеческими. Казалось, что ImageIdentify весьма успешно копирует какие-то аспекты того, как сам человек распознаёт изображения.
И меня поразило то, что я обнаружил. Да, ImageIdentify может ошибаться. Но почему-то ошибки казались очень понятными и в каком-то смысле человеческими. Казалось, что ImageIdentify весьма успешно копирует какие-то аспекты того, как сам человек распознаёт изображения.
Что насчёт абстрактного искусства? Это нечто вроде теста Роршака как для машин, так и для людей — весьма интересное представление о чертах ImageIdentify.
 Назад к природе
Такие проекты, как создание ImageIdentify, никогда не заканчиваются. Но пару месяцев назад (см. статью на Хабрахабре «Стивен Вольфрам: Рубежи вычислительного мышления (отчёт с фестиваля SXSW)») мы выпустили предварительную версию на Wolfram Language. И сегодня мы выпустили новую версию и использовали её как основу для Wolfram Language Image Identification Project.Мы продолжим обучение и разработку ImageIdentify, особенно сосредоточившись на обратной связи и статистике с сайта. Как для Wolfram|Alpha в сфере понимания естественного языка, без активного использования людьми нет никакой возможности реально оценить прогресс, или даже определить, каковы должны быть цели для распознавания реальных изображений.
Назад к природе
Такие проекты, как создание ImageIdentify, никогда не заканчиваются. Но пару месяцев назад (см. статью на Хабрахабре «Стивен Вольфрам: Рубежи вычислительного мышления (отчёт с фестиваля SXSW)») мы выпустили предварительную версию на Wolfram Language. И сегодня мы выпустили новую версию и использовали её как основу для Wolfram Language Image Identification Project.Мы продолжим обучение и разработку ImageIdentify, особенно сосредоточившись на обратной связи и статистике с сайта. Как для Wolfram|Alpha в сфере понимания естественного языка, без активного использования людьми нет никакой возможности реально оценить прогресс, или даже определить, каковы должны быть цели для распознавания реальных изображений.
Должен сказать, что я нахожу весёлым занятием даже просто поиграть с Wolfram Language Image Identification Project. Это будоражит — видеть, как после долгих лет работы получился искусственный интеллект, который и правда работает. Более того, когда Вы видите, что ImageIdentify отвечает на необычное или сложное изображение, возникает такое чувство, как будто это человек делает догадки, или просто шутит.
 Под капотом всего этого, конечно, просто код, с весьма простыми циклами. Этот код почти такой же, как тот, который я, к примеру, писал для своих нейронных сетей в восьмидесятые (конечно, сейчас это код на Wolfram Language, а не на низкоуровневом C).
Под капотом всего этого, конечно, просто код, с весьма простыми циклами. Этот код почти такой же, как тот, который я, к примеру, писал для своих нейронных сетей в восьмидесятые (конечно, сейчас это код на Wolfram Language, а не на низкоуровневом C).
Это очень необычный пример из истории идей — нейронные сети исследуются более семидесяти лет, однако интерес к ним неоднократно угасал. Нейронные сети для нас — то, что привело нас к успеху в решении такой образцовой задачи искусственного интеллекта, как распознавание изображений. Полагаю, что такие передовики в исследовании нейронных сетей, как Уоррен Мак-Каллок и Уолтер Питтс несколько удивились бы тому, что делает ядро Wolfram Language Image Identification Project. Вероятно, они были бы поражены, что для этого потребовалось аж 70 лет.
Но для меня гораздо большее значение имеет то, как могут быть такие вещи, как ImageIdentify, встроены в символьную структуру Wolfram Language. То, что делает ImageIdentify — это то, что делают люди из поколения в поколение. Но символьный язык даёт нам возможность представить весь багаж интеллектуальных достижений человечества. И сделать всё это вычислительным, полагаю, будет чем-то столь масштабным, что я только сейчас начинаю осознавать значимость этого.
Что касается текущего момента, то я надеюсь, что Вам понравится Wolfram Language Image Identification Project. Рассматривайте его как о праздник достижения новых рубежей искусственного интеллекта. Рассматривайте его как отдых для ума, навевающий мысли о будущем искусственного интеллекта. Но не стоит забывать наиболее, на мой взгляд, важное: это так же и прикладная технология, которую Вы можете использовать здесь и сейчас в Wolfram Language и выгружать туда, куда только пожелаете.
Напоследок от команды Блога Wolfram…
Однажды попав на Хабрахабр, заболеваешь им в хорошем смысле этого слова и ImageIdentify кажется знает почему;)
