[Перевод] Информатика за индексами в Постгресе
Все мы знаем, что индексы — одна из самых мощных и важных функций серверов реляционных баз данных. Как быстро найти значение? Создать индекс. Что нужно не забыть сделать при объединении двух таблиц? Создать индекс. Как ускорить SQL запрос, который начал медленно работать? Создать индекс.

Но что такое эти индексы? И как они ускоряют поиск по базе данных? Чтобы выяснить это, я решил прочитать исходный код сервера базы данных PostgreSQL на C и проследить за тем, как он ищет индекс для простого текстового значения. Я ожидал найти сложные алгоритмы и эффективные структуры данных. И я их нашёл. Сегодня я покажу вам, как выглядят индексы внутри Постгреса, и объясню, как они работают.
Что я не ожидал найти — что я впервые обнаружил, читая исходный код Постгреса — так это теорию информатики в основе того, что он делает. Чтение исходного кода Постгреса превратилось в возвращение в школу и изучение того предмета, на который у меня никогда не хватало времени в молодости. Комментарии на C внутри Постгреса объясняют не только, что он делает, но и почему.
Последовательные сканирования: бездумный поиск
Когда мы покинули команду Наутилуса, они были измучены и почти падали в обморок: алгоритм последовательного сканирования Постгреса бездумно петлял по всем записям в таблице пользователей! Вспомните мой предыдущий пост, в котором мы выполнили этот простой SQL запрос, чтобы найти Капитана Немо:

Постгрес обработал, проанализировал и спланировал запрос. Затем ExecSeqScan, функция C внутри Постгреса, которая выполняет узел плана Последовательное сканирование (SEQSCAN), быстро нашла Капитана Немо:
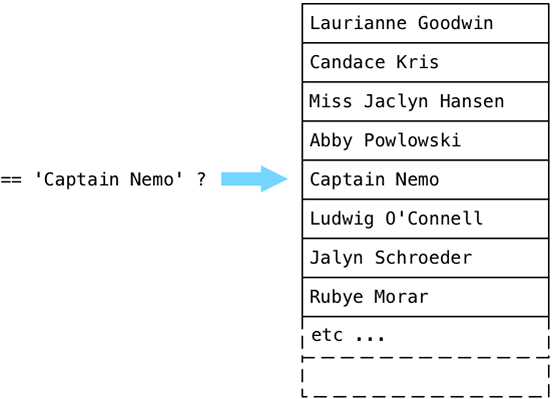
Но потом Постгрес необъяснимым образом продолжил выполнять цикл по всей таблице пользователей, сравнивая каждое имя с «Captain Nemo», хотя мы уже нашли то, что искали!
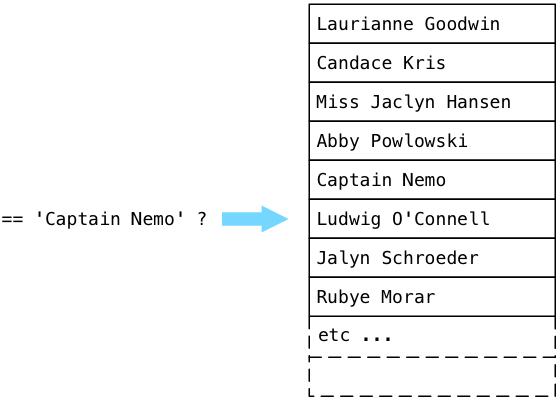
Представьте, что в нашей таблице были бы миллионы записей, — процесс занял бы очень много времени. Конечно, мы могли бы избежать этого, удалив sort и переписав наш запрос так, чтобы принималось только первое найденное имя, но более глубокая проблема заключается в неэффективности способа, которым Постгрес ищет нашу целевую строку. Использовать последовательное сканирование для сравнения каждого значения в таблице пользователей с «Captain Nemo» — это медленно, неэффективно и зависит от случайного порядка, в котором имена появляются в таблице. Что мы делаем не так? Должен быть лучший способ!
Ответ прост: мы забыли создать индекс. Давайте сделаем это сейчас.
Создание индекса
Создать индекс очень просто — нужно всего лишь запустить эту команду:
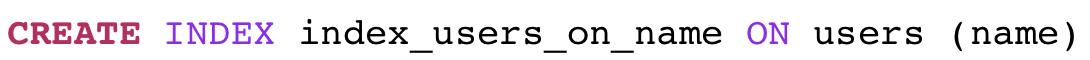
Как разработчики Ruby, мы, конечно же, использовали бы вместо этого миграцию ActiveRecord add_index, которая выполнит ту же команду CREATE INDEX «под капотом». Когда мы снова запустим наш запрос select, Постгрес, как обычно, создаст дерево плана, но на этот раз оно будет немного другим:
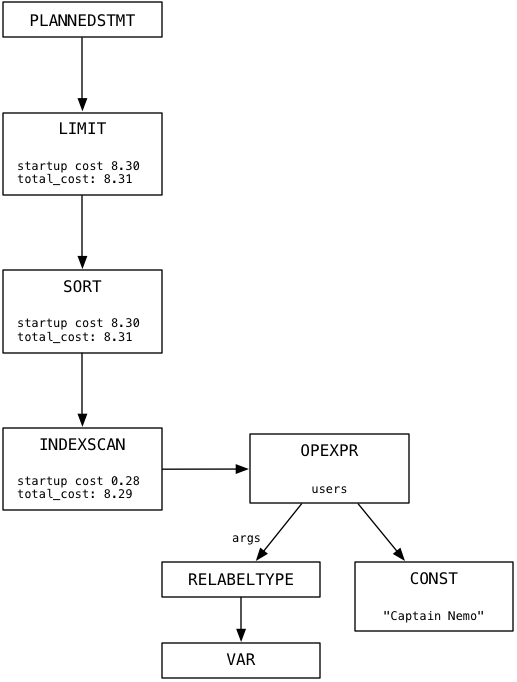
Обратите внимание, что внизу Постгрес теперь использует INDEXSCAN вместо SEQSCAN. В отличие от SEQSCAN, INDEXSCAN не будет проводить сканирование по всей таблице пользователей. Вместо этого оно использует тот индекс, который мы только что создали, чтобы найти и вернуть записи про Капитана Немо быстро и эффективно.
Создание индекса решило нашу проблему с производительностью, но оставило нас с множеством интересных неотвеченных вопросов:
- Что именно представляет из себя индекс в Постгресе?
- Если бы я мог залезть в базу данных Постгреса и получше рассмотреть индекс, на что бы он был похож?
- Каким образом индекс ускоряет поиск?
Давайте попробуем ответить на эти вопросы, изучая исходный код Постгреса.
Что же такое индекс в Постгресе?
Мы можем начать с изучения документации для команды CREATE INDEX.
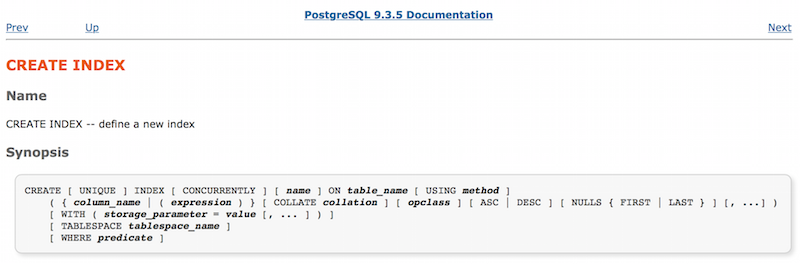
Здесь вы видите все опции, которые мы можем использовать для создания индекса, например, UNIQUE и CONCURRENTLY. Обратите внимание, что есть такая опция, как метод USING. Он сообщает Постгресу, какой именно индекс нам нужен. Ниже на той же странице есть информация о method — аргументе к ключевому слову USING:

Оказывается, Постгрес имплементирует четыре разных типа индексов [прим. пер.: теперь уже больше, статья была написана раньше, чем появился BRIN и другие новые варианты индексов]. Вы можете использовать их для разных типов данных и в разных ситуациях. Поскольку мы никак не уточняли USING, наш индекс index_users_on_name является «btree» (или B-Дерево) индексом, типом по умолчанию.
Это наша первая подсказка: индекс Постгреса — это B-Дерево. Но что такое B-Дерево? Где мы можем его найти? Внутри Постгреса, конечно же! Давайте поищем в исходном коде Постгреса на C файлы, содержащие «btree:»
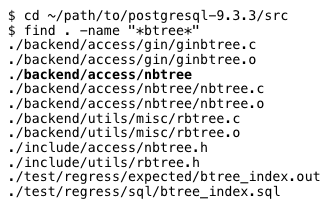
Ключевой результат выделен жирным шрифтом:»./backend/access/nbtree.» Внутри этой директории есть файл README. Давайте его прочитаем:

Удивительным образом этот README файл оказался подробным документом на 12 страниц! Исходный код Постгреса содержит не только полезные и интересные комментарии к коду C, но и документацию о теории и реализации сервера БД. Прочитать и понять код в проектах с открытым исходным кодом часто бывает трудно и страшно, но не в PostgreSQL. Разработчики, стоящие за Постгресом, приложили огромные усилия, чтобы мы с вами могли понять их работу.
Название документа README — «Btree Indexing» — подтверждает, что директория содержит код C, который реализует B-Tree индексы в Постгресе. Но первое предложение представляет ещё больший интерес: это отсылка к научной работе, которая объясняет, что такое B-Дерево, и как работают индексы в Постгресе: Efficient Locking for Concurrent Operations on B-Trees, за авторством Лемана (Lehman) и Яо (Yao).
Мы постараемся разобраться с тем, что такое B-Tree с помощью этой научной работы.
Как выглядит B-Tree индекс?
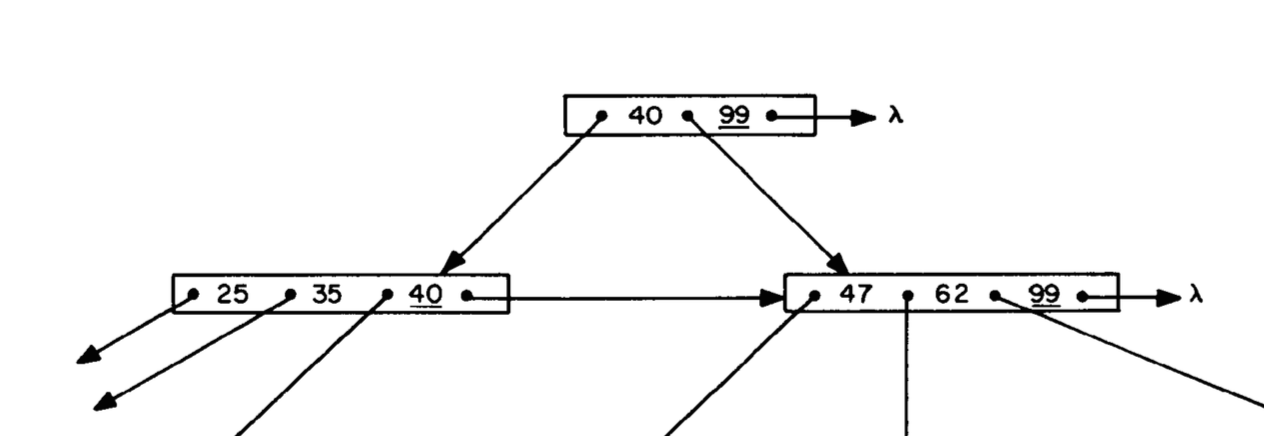
Работа Лемана и Яо объясняет инновационные изменения, которые они внесли в алгоритм B-Tree в 1981 году. Поговорим об этом чуть позже. Но они начинают с простого введения в структуру данных B-Tree, которая была изобретена на 9 лет раньше — в 1972 году. Одна из их диаграмм показывает пример простого B-Tree:

Термин B-Tree является сокращением от английского «balanced tree» — «сбалансированное дерево». Алгоритм делает поиск простым и быстрым. Например, если бы мы хотели найти значение 53 в этом примере, мы бы начали с корневого узла, содержащего значение 40:

Мы сравниваем наше искомое значение 53 со значением, которое мы нашли в узле дерева. 53 — это больше или меньше, чем 40? Поскольку 53 больше 40, мы следуем за указателем вниз и направо. Если бы мы искали 29, мы бы пошли вниз налево. Указатели справа ведут к большим значениям, а слева — к меньшим.
Следуя вниз за указателем к следующему дочернему узлу дерева, мы встречаем узел, содержащий 2 значения:

На этот раз мы сравниваем 53 сразу с 47 и 62 и обнаруживаем, что 47 < 53 < 62. Обратите внимание, что значения в узле дерева отсортированы, поэтому сделать это будет просто. Теперь мы следуем вниз по центральному указателю.
Здесь у нас ещё один узел дерева, уже с тремя значениями:
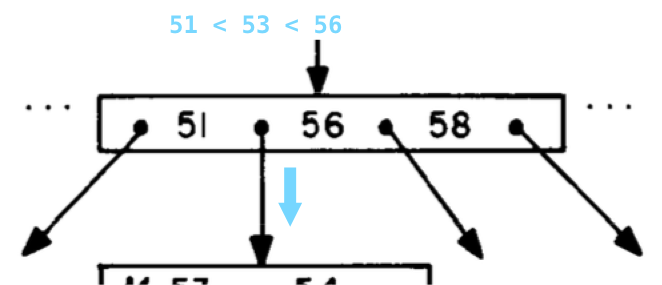
Просмотрев отсортированный список чисел, мы находим 51 < 53 < 56 и следуем вниз по второму из четырех указателей.
Наконец, мы приходим к узлу-листику дерева:
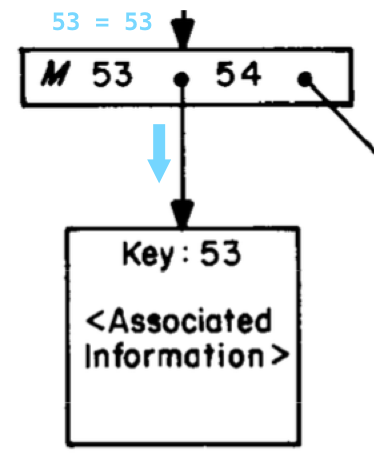
И вот оно, наше искомое значение 53!
Алгоритм B-Tree ускоряет поиск, потому что:
- он сортирует значения (называемые ключами) внутри каждого узла;
- он сбалансирован: ключи равномерно распределяются между узлами, минимизируя количество переходов от одного узла к другому. Каждый указатель ведет к дочернему узлу, который содержит примерно такое же количество ключей, как и каждый последующий дочерний узел.
Как выглядит индекс Постгреса?
Леман и Яо нарисовали эту диаграмму более 30 лет назад. Какое отношение она имеет к тому, как Постгрес работает сегодня? Поразительно, но индекс index_users_on_name, который мы создали ранее, очень похож на эту самую диаграмму из научной работы: мы создали в 2014 году индекс, который выглядит точно так же, как диаграмма из 1981-го!
Когда мы выполнили команду CREATE INDEX, Постгрес сохранил все имена из нашей таблицы пользователей в B-Tree. Они стали ключами дерева. Вот как выглядит узел внутри B-Tree индекса в Постгресе:

Каждая запись в индексе состоит из структуры на языке C под названием IndexTupleData, за которой следует битовая карта (bitmap) и значение. Постгрес использует битовую карту, чтобы записывать, принимают ли какие-либо атрибуты индекса в ключе значение NULL, для экономии места. Фактические значения находятся в индексе после битовой карты.
Давайте подробнее рассмотрим структуру IndexTupleData:

На рисунке выше видно, что каждая структура IndexTupleData содержит:
- t_tid: это указатель либо на другой index tuple, либо на запись в базе данных. Заметьте, что это не указатель на физическую память на языке С. Вместо этого он содержит числа, которые Постгрес может использовать, чтобы найти искомое значение на страницах памяти.
- t_info: тут содержится информация об элементах индекса, например, сколько в нём значений и равны ли они null.
Чтобы лучше это понять, давайте покажем несколько записей из нашего индекса index_users_on_name:
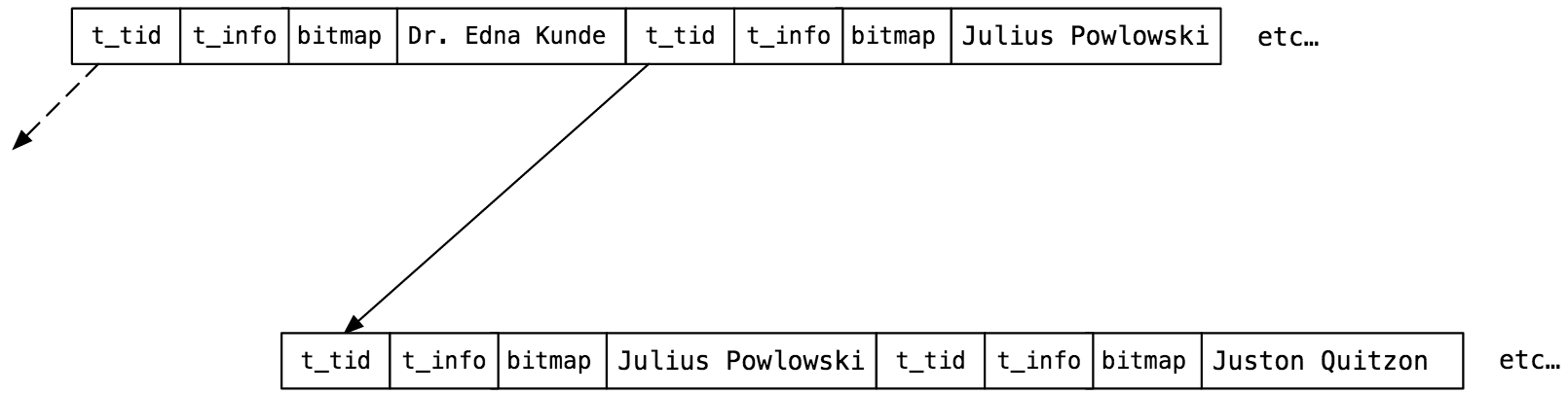
Я заменил value какими-то именами из моей таблицы пользователей. Верхний узел дерева содержит ключи «Dr. Edna Kunde» и «Julius Powlowski», а нижний — «Julius Powlowski» и «Juston Quitzon». Обратите внимание, что в отличие от диаграммы Лемана и Яо, Постгрес повторяет родительский ключ в каждом дочернем узле. Здесь «Julius Powlowski» является ключом в верхнем и дочернем узлах. Указатель t_tid в верхнем узле отсылает к тому же имени Julius в нижнем узле.
Чтобы узнать больше о том, как именно Постгрес сохраняет ключевые значения в узел B-Tree, обратитесь к заголовочному файлу itup.h:

IndexTupleDataview on postgresql.org

Поиск узла B-Tree, содержащего Капитана Немо
Давайте вернемся к нашему изначальному запросу SELECT:

Как именно Постгрес ищет в нашем индексе index_users_on_name значение «Captain Nemo»? Почему использовать индекс быстрее, чем последовательное сканирование, которое мы рассматривали в предыдущем посте? Чтобы это выяснить, давайте немного уменьшим масштаб и посмотрим на некоторые имена пользователей в нашем индексе:
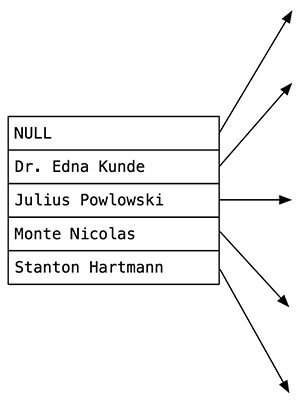
Это корневой узел B-Tree index_users_on_name. Я положил дерево на бок, чтобы имена влезли. Вы можете увидеть 4 имени и одно значение NULL. Постгрес создал этот корневой узел, когда я создал index_users_on_name. Заметьте, что помимо первого значения NULL, которое обозначает начало индекса, остальные 4 значения более-менее равномерно распределены в алфавитном порядке.
Напомню, что B-Tree — это сбалансированное дерево. В этом примере в B-Tree есть 5 дочерних узлов:
- имена, расположенные по алфавиту до Dr. Edna Kunde;
- имена, расположенные между Dr. Edna Kunde и Julius Powlowski;
- имена, расположенные между Julius Powlowski и Monte Nicolas;
- и т.д.
Поскольку мы ищем имя Captain Nemo, Постгрес переходит по первой верхней стрелке направо. Это обусловлено тем, что Captain Nemo по алфавиту идёт перед Dr. Edna Kunde:
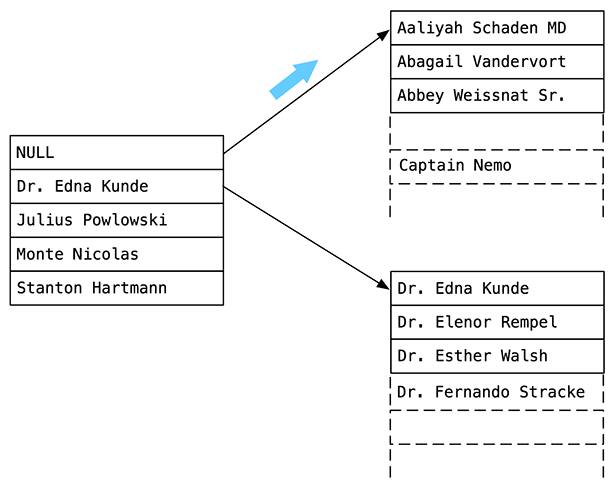
Как видите, справа Постгрес нашел узел B-Tree, в котором содержится Captain Nemo. Для своего теста я добавил в таблицу пользователей 1000 имен. Этот дочерний узел B-Tree включает около 200 имен (240, если быть точным). Так что алгоритм B-Tree существенно сузил нам поиск в Постгресе.
Чтобы узнать больше о конкретном алгоритме, используемом Постгресом для поиска целевого узла B-Tree среди всех его узлов, почитайте функцию _bt_search.
_bt_searchview on postgresql.org

Поиск Капитана Немо внутри конкретного узла B-Tree
Теперь, когда Постгрес сузил пространство для поиска до узла B-Tree, содержащего около 200 имен, ему всё ещё нужно найти среди них Капитана Немо. Как же он это сделает? Применит ли он последовательное сканирование к этому укороченному списку?

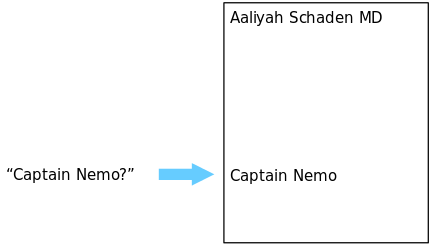
Нет. Для поиска ключевого значения внутри узла дерева Постгрес переключается на использование бинарного алгоритма поиска. Он начинает сравнивать ключ, расположенный на 50% позиции в узле дерева с «Captain Nemo»:

Поскольку Captain Nemo по алфавиту идёт после Breana Witting, Постгрес перескакивает к позиции 75% и проводит еще одно сравнение:

На этот раз Captain Nemo идёт до Curtis Wolf, так что Постгрес возвращается немного назад. Сделав ещё несколько итераций (Постгресу потребовалось 8 сравнений, чтобы найти Капитана Немо в моём примере), Постгрес наконец находит то, что мы искали.
Чтобы узнать больше о том, как Постгрес ищет значение в конкретном узле B-Tree, почитайте функцию _bt_binsrch:
_bt_binsrchview on postgresql.org

Ещё многое предстоит узнать
Мне не хватит места в этом посте, чтобы рассказать обо всех захватывающих деталях, касающихся B-Tree, индексов баз данных или внутренностях Постгреса… возможно, мне стоит написать книгу Постгрес под микроскопом:) А пока вот вам несколько интересных фактов из теории, которые вы можете прочитать в Efficient Locking for Concurrent Operations on B-Trees или в другой научной работе, на которую она ссылается.
- Вставки в B-Tree: самая прекрасная часть алгоритма B-Tree — добавление новых ключей в дерево. Они добавляются в отсортированном порядке в подходящий узел дерева, но что происходит, когда места для новых ключей не остаётся? В этом случае, Постгрес делит узел на два, вставляет в один из них новый ключ и добавляет ключ из разделенного узла в родительский узел вместе с указателем на новый дочерний узел. Конечно, есть вероятность, что родительский узел тоже придется разделить, чтобы добавить новый ключ, что приведет к сложной рекурсивной операции.
- Удаление из B-Tree: обратная операция также интересна. Когда ключ удаляется из узла, Постгрес объединяет одноуровневые узлы, если это возможно, удаляя ключ из их родительского узла. Эта операция также может быть рекурсивной.
- B-Link- Tree: Работа Лемана и Яо рассказывает об инновации, которую они исследовали, в отношении параллелизма и блокировки, когда несколько потоков используют одно и то же B-Дерево. Как вы помните, код и алгоритмы Постгреса должны быть мультипоточными, потому что много клиентов могут одновременно искать и модифицировать один и тот же индекс. Добавляя еще один указатель из каждого узла B-Tree в следующий дочерний узел — так называемая «правая стрелка» — один поток может искать в дереве, даже если второй поток делит узлы, не блокируя при этом весь индекс:
Не бойтесь исследовать невидимую часть айсберга
Профессор Ароннакс рисковал своей жизнью и карьерой, чтобы найти неуловимый Наутилус и присоединиться к Капитану Немо в длинной череде потрясающих подводных приключений. Нам стоит сделать так же: не бояться нырнуть под воду — вглубь инструментов, языков и технологий, которые вы используете каждый день. Вы можете многое знать о Постгресе, но знаете ли вы, как он работает изнутри? Загляните внутрь, и не успеете оглянуться, как сами окажетесь в подводном приключении.
Изучение на работе информатики, стоящей за нашими приложениями, — это не просто развлечение, а важная составляющая процесса развития разработчика. Инструменты для разработки программного обеспечения совершенствуются с каждым годом, написание веб-сайтов и мобильных приложений упрощается, но мы не должны упускать из виду фундаментальную информатику, от которой мы зависим. Мы все стоим на плечах гигантов — таких людей, как Леман и Яо, а также разработчиков открытого исходного кода, использовавших их теории для создания Постгреса. Не воспринимайте инструменты, которые вы используете каждый день, как должное, — изучайте их устройство. Вы станете мудрее как разработчик и найдёте идеи и знания, о которых даже не подозревали.
Комментарии (2)
29 августа 2016 в 15:40
0↑
↓
Скажите, пожалуйста, планируется ли сделать команду reindex с опцией CONCURRENTLY?29 августа 2016 в 15:51
0↑
↓
Не могу дать точного ответа. Знаю лишь, что разработка патча, добавляющего поддержку, велась, но вроде как подзаглохла. В сети имеется некоторое количество всяких workaround’ов на эту тему, использующих drop + create concurrentlyНасколько могу судить из этой дискуссии http://www.sql.ru/forum/941407/reindex-bazy-pod-nagruzkoy, вопрос внедрения фичи не стоит остро и народ, в целом, обходится вышеупомянутым обходным путем.
